語言產生是一種複雜的神經現象,長期以來它一直讓研究人員難以用語言解釋清楚。解析控制口部、下頜和舌頭精確肌肉運動的神經區域複雜網絡,以及處理聽到自己聲音的聽覺反饋的區域,構成了一個複雜的難題,這也是下一代語音產生假體所必須克服的問題。
現如今,紐約大學的一個研究團隊已經取得了關鍵性的發現,助力解開這個網絡,並利用這些發現構建出一種聲音重建技術,以重建那些失去說話能力患者的聲音。
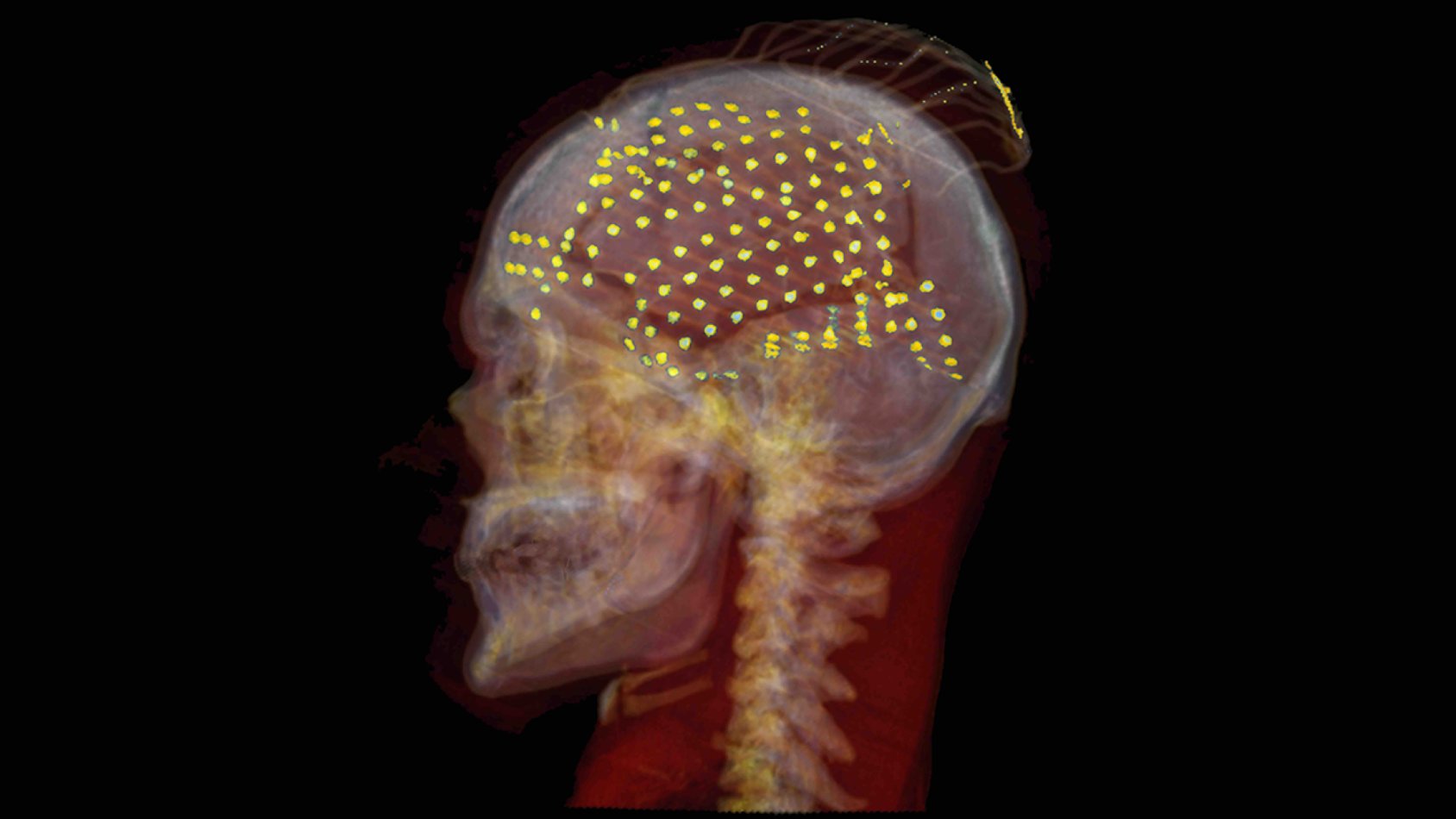
該團隊由Adeen Flinker和Yao Wang共同領導,團隊利用複雜的神經網絡,從大腦記錄中重建語音,並用這些重建來分析驅動人類語音的過程。他們在《國家科學院學報》(PNAS)上發表的新論文中詳細介紹了他們的新發現。
人類語音產生是一種複雜行爲,涉及到對運動命令的前饋控制以及對自我產生語音的反饋處理。這些過程需要多個大腦網絡同時參與。然而,至今,我們仍難以區分大腦在運動控制與感官處理(由語音產生所引發)方面的參與程度及時機。
在這篇新論文中,研究人員成功地分離了語音產生過程中的反饋和前饋複雜過程。利用一種創新的深度學習架構,在人類神經外科記錄上,團隊使用了一個基於規則的可微分語音合成器來從皮層信號中解碼語音參數。通過實施能夠區分因果(使用當前和過去的神經信號解碼當前語音)、反因果(使用當前和未來的神經信號)或兩者組合(非因果)的時間卷積的神經網絡架構,研究者能夠精細分析語音產生中前饋和反饋的貢獻。
Flinker表示:“這種方法使我們能夠分離在我們產生語音和感知自己聲音反饋時同時發生的前饋和反饋神經信號的處理。”
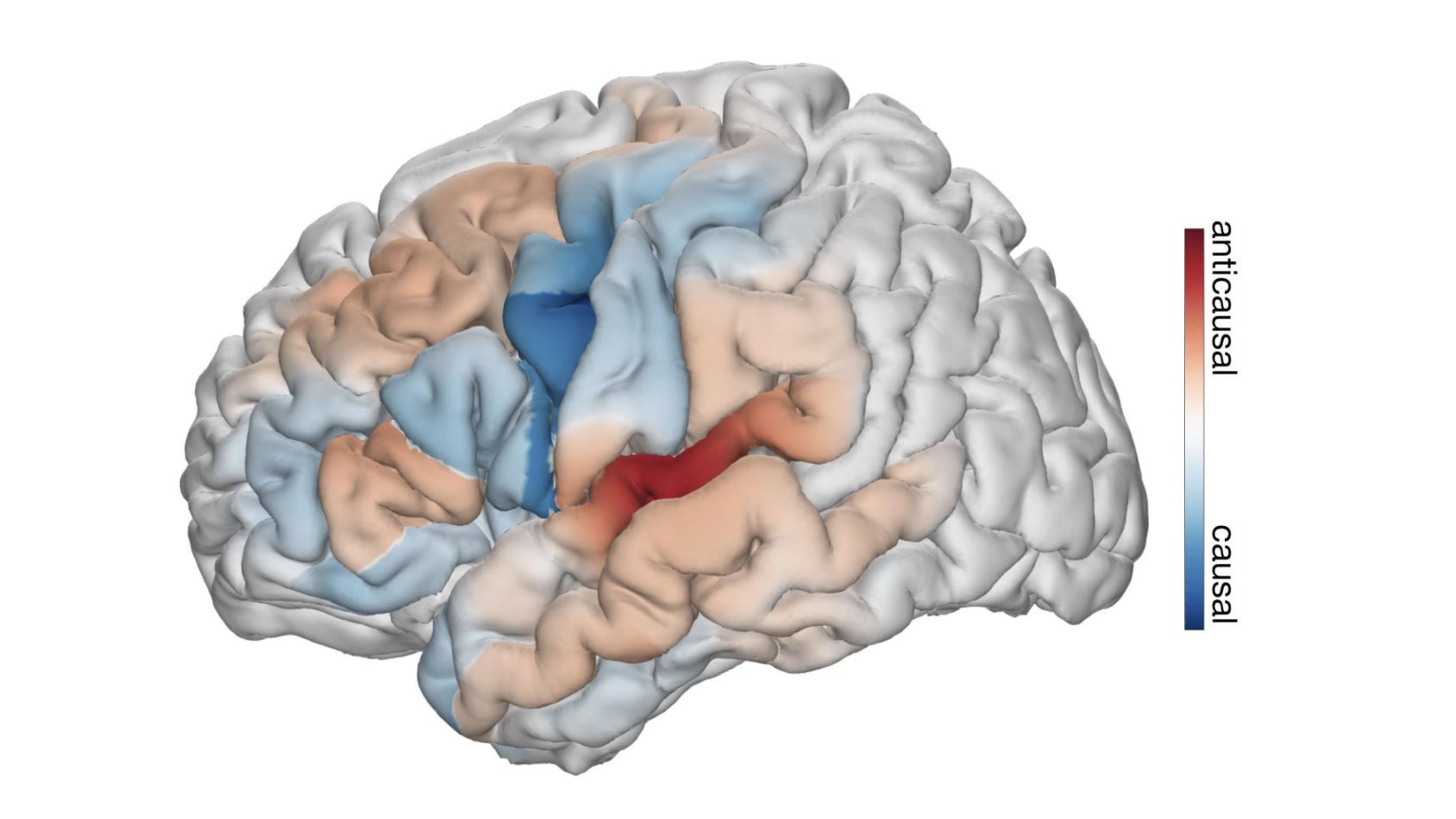
這一前沿方法不僅解碼了可解釋的語音參數,而且還爲所招募的皮質區域的時間接受域提供了洞見。值得注意的是,這些發現挑戰了將反饋和前饋皮質網絡分開的傳統觀點。分析揭示了一種複雜的反饋和前饋處理架構,跨越了前額和顳葉皮層。這一新的觀點,結合出色的語音解碼性能,標誌着我們理解語音產生複雜神經機制的一大步進。
研究人員利用這一新的視角來指導他們自己的假體開發工作,這些假體能夠讀取大腦活動並直接解碼成語音。儘管許多研究人員正在開發此類設備,紐約大學的原型具有一個關鍵的不同之處:它能夠使用只有少量錄音的數據集,而顯著重建患者的聲音。這意味着患者在失去聲音後,不僅僅可以恢復聲音,還可以重新獲得自己原有的聲音。這要歸功於一個考慮了潛在聽覺空間的深度神經網絡,並可以只用個別聲音的幾個樣本(例如YouTube視頻或Zoom錄音)來進行訓練。
這篇論文收到來自NSF的850,000美元的資金資助,該基金旨在開發用於語言處理的神經解碼器和開發定向連接模型。如今,研究者們已經獲得了額外的950,000美元的資金,以繼續開展這項工作,這些資金將支持進一步開發計算方法,以深入理解語言的神經生物學,並轉化爲針對語言和語言的新型臨牀應用。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com












