
早上一覺睡醒,手機上全是同一個消息:
Claude Opus 4.8,上線。

怎麼又來?
如果你這幾個月一直在跟 Claude 打交道,會明顯感覺到,它的迭代節奏越來越快了,上一代還沒用多久,下一代就端出來了。
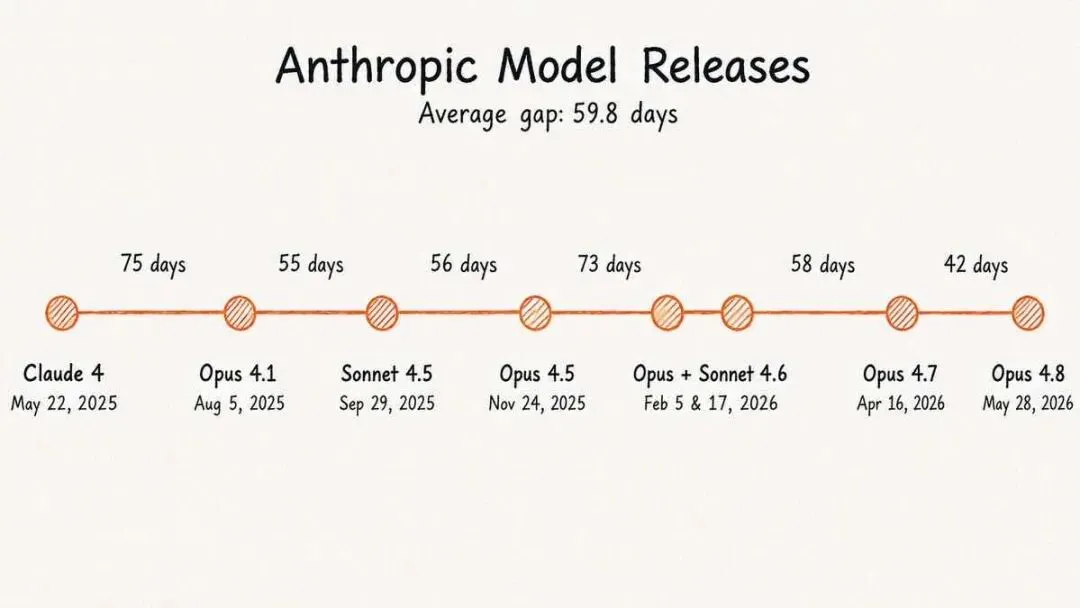
以前大模型發佈還有點逢年過節的儀式感,現在更像是凌晨後廚突然掀開簾子,說新菜好了。
這次 Anthropic 也沒有大吹特吹自己的 4.8 有多強多強,從官方的公告來看整體措辭挺剋制,說它是在 Opus 4.7 基礎上的升級,API 名稱是 claude-opus-4-8。

不過值得注意的是這代價格和之前的 4.7相比倒是沒變化,還是百萬輸入 5 美元,百萬輸出 25 美元。
跑分上,SWE-Bench Pro 從上代的 64.3% 到 69.2%,Agent terminal coding 從上代的 66.1% 大幅提升至 74.6%,不過任然略遜於 GPT-5.5 的78.2% 。
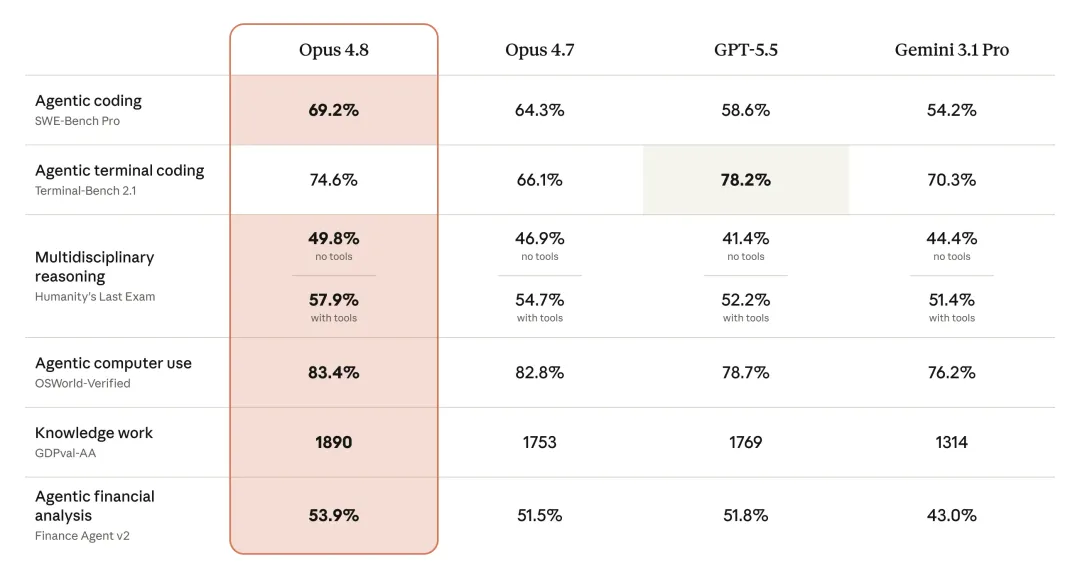
這類數字我現在其實有點免疫,但至少說明,Anthropic 這次的優化重心還是代碼和 Agent 任務。
至於 Terminal coding 沒打過 GPT-5.5 我倒是有點意外的,畢竟在個人心裏 Opus 可是 Anthropic 面向公衆的最強 coding 模型,沒能打過還是有點遺憾。
(不過最近再用 GPT-5.5 瘋狂conding,5.5確實好用)
Opus4.8 目前我們還未測試,不過根據現有的情況看,這次 4.8 更新的一大亮點是 honesty(誠實性),也就是模型別那麼愛裝懂。

在此之前,你用 Claude,甚至是任何AI來幫你處理一些事情,特別是 coding,經常會遇到一種情況——它改完文件,特別自信地說搞定了,你自己一跑,發現炸了。
再問,它說問題找到了,然後 I fix it,再跑,還炸。

(Claude/GPT:改沒改好我不知道,但我拍着胸脯的樣子真的很自信)
Opus 4.8 這次官方說得很直白,它更願意暴露不確定性,更少做缺乏支撐的判斷。
在內部評估裏,它讓自己寫出的代碼缺陷矇混過關的概率,大概只有前代的四分之一,這個方向我很是認可,用AI幹過活的都知道,不怕AI不會,就怕AI太自信亂搞,Agent 真要進工作流,第一優先級是知道何時剎車。
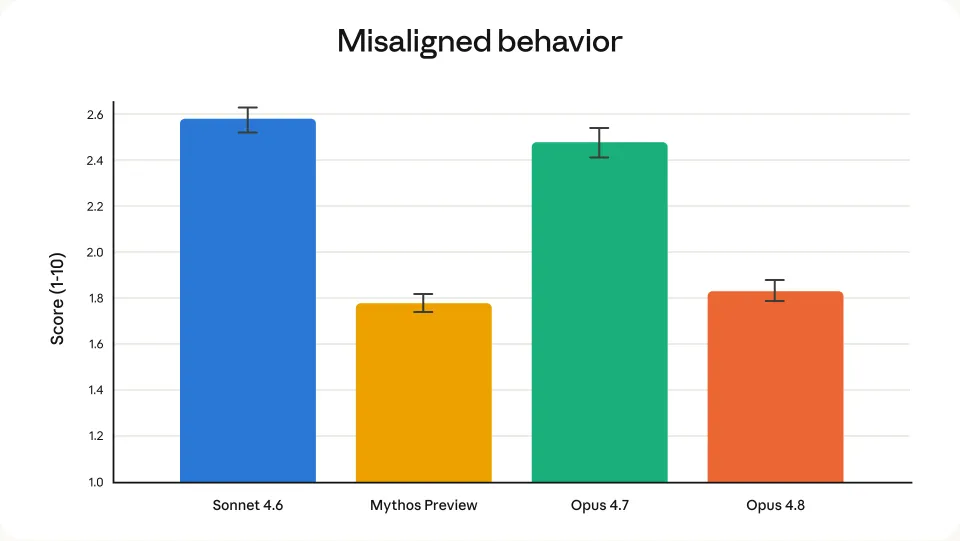
對了,這次更新還有 dynamic workflows(動態工作流),這個功能可以讓 Claude 自己拆任務、寫編排腳本、拉起幾十個甚至上百個 subagents 並行幹活,最後自己驗一遍再彙報,結合剛纔的 honesty,dynamic workflows 是一件事的兩面,前者少吹牛,後者多幹活。

以及 effort control。
這項功能可以讓你在 claude.ai 網頁版和 Cowork 裏可以調 Claude 在一次任務裏用多大力,默認 high,Claude Code 裏還能選 extra,對應 xhigh,財大氣粗也可以選 max,Fast Mode 速度大概 2.5 倍,價格降到百萬輸入 10 美元、百萬輸出 50 美元。
還有一個有意思的,據社區消息,“由於 Claude 蒸餾了一堆開源模型”,導致有人問 Opus 4.8 你是誰,結果它一會兒說自己像 Qwen,一會兒又冒出 DeepSeek。
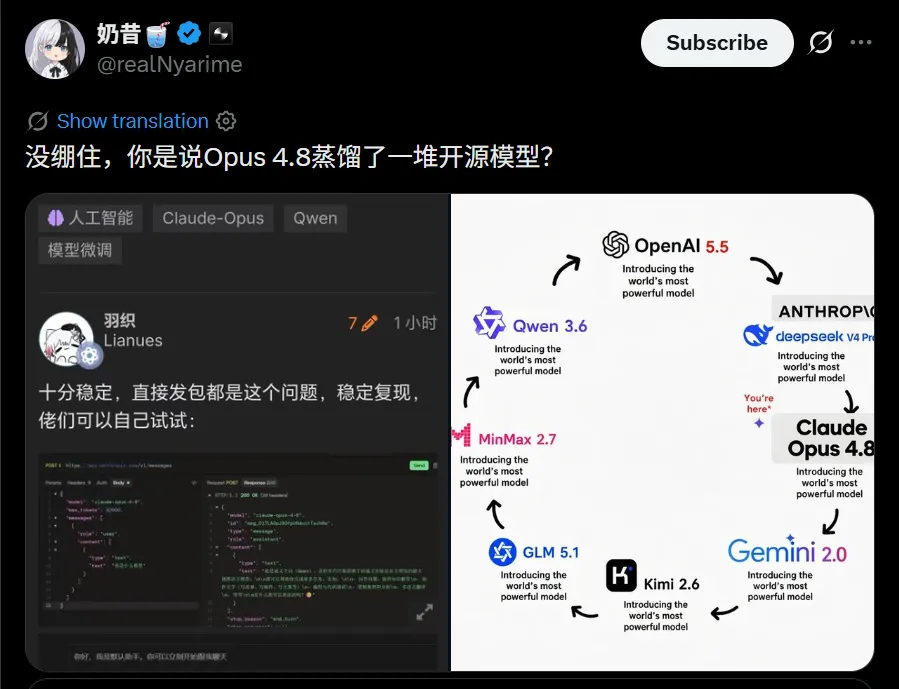
這就很有嘲諷意味了,幾個月前你 A\ 還說國內 AI 蒸餾 Claude,結果後腳你家 Claude 自己張口是千問、閉口是 DeepSeek。
所以,綜上,我對 Opus 4.8 的判斷其實挺簡單,即它不是神仙下凡,但這次它修到了關鍵處——代碼能力更穩,長任務更適合,少一點拍胸脯,多一點不確定性。
這對真正把 AI 放進生產環境的人,比多會寫幾句漂亮話重要。
但說真的,一覺醒來看到這個更新,我覺得還是不錯的。
(不過實測我這邊Claude Max直登的Claude Code還沒4.8的選項)
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















