這幾天影視颶風有一個視頻特別有意思。
簡單來說,就是拋硬幣,看哪邊朝上。
但是用 AI 視頻來拋。。
(用 AI 視頻生成拋硬幣的場景)
不在提示詞裏面寫明哪一面最終朝上。
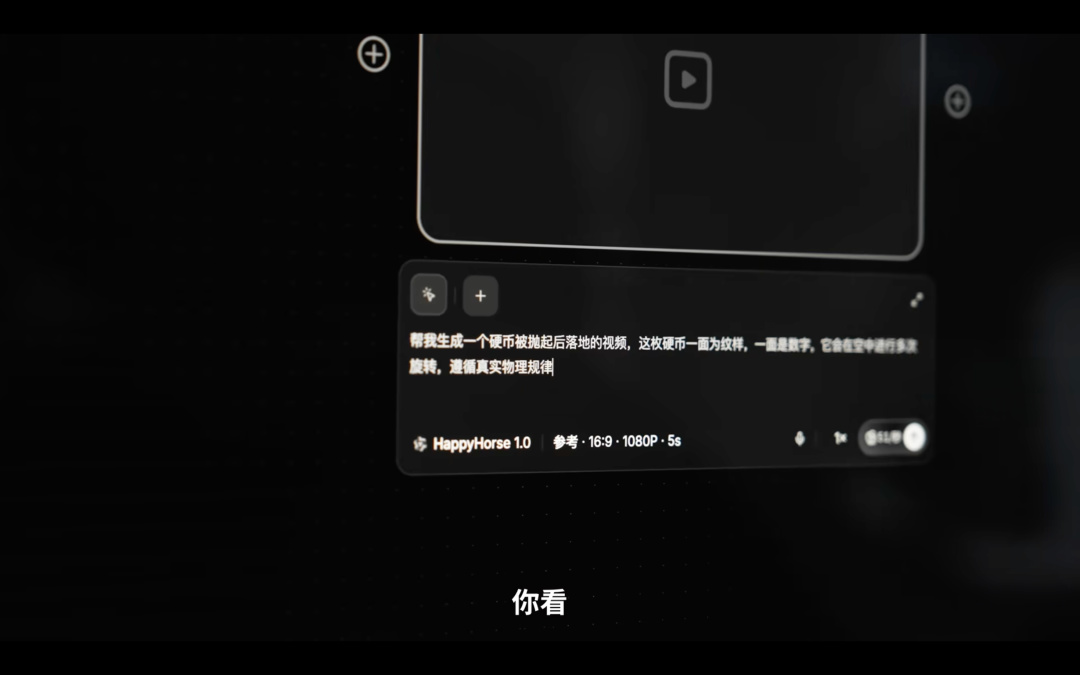
他們團隊嘗試了可能有幾百次。
(就是用文生視頻嘗試了幾百條視頻)
後面發現硬幣正反面(即數字面和人像面),
出現的概率是不一樣的
視頻中沒說是用哪個模型,
但我猜是 Seedance 2.0
大概有 70% 的概率會得到正面,
即數字面。
但用最近新出的 Happy Horse 恰恰相反,

出現反面(花面)的概率有 75%,
太虧賊了。
本文從原理方面講講這是爲啥:
訓練數據集差異
這是最根本的原因,因爲生成視頻和生成文字,本質上都是讓大模型來乾的。
在互聯網海量數據中,
拋硬幣的視頻裏出現人頭面的數量遠超於數字面,所以拋硬幣時出現這個概率也是很正常的。
如果模型 A 抓取了更多電影和硬幣魔術的特寫
(爲了視覺表現力,90% 都展示硬幣正面)
那麼模型 A 的底層概率,就會嚴重向正面傾斜。
而模型 B 如果抓取了更多,
日常 Vlog 或隨機雜亂的物理實驗,偏見可能就會小一些。
CFG 等採樣參數差異
爲了讓 AI 聽懂你的話(比如拋硬幣),
所有的擴散模型都會用一種技術,
叫做無分類器引導。
(Classifier-Free Guidance, 簡稱 CFG)
CFG 本質是把模型對提示詞的注意力放大但在放大的同時,
它也會呈指數級放大訓練集裏的統計偏見。
假設訓練集里正面的基礎概率是 p=0.55(微小偏見),當模型應用了權重爲 w 的 CFG 後,最終生成的概率近似於:
如果一個模型爲了畫面更好看,
默認把 CFG 設置得特別高(比如 w=7),
那麼原本 55% 的偏見,就會被強行放大到 92%
不同模型的默認 CFG 係數和採樣步數不同,導致了概率畸變程度大相徑庭。
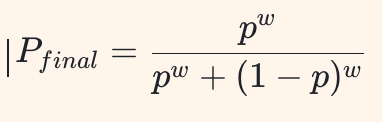
文本編碼器差異
你在對話框輸入拋硬幣,AI 其實是不認識字的。
它需要一個文本編碼器(如 CLIP、T5 或自定義的 LLM)把文字變成高維向量。有些編碼器對“硬幣”這個詞的理解更側重於“金屬圓片上的圖案”(導致模型傾向於畫出清晰的正面圖案)。有些編碼器更側重於“拋物線的動作”,這就會導致它們在時空注意力上分配不同的權重,最終影響畫面的演變邏輯。
RLHF 人類偏好對齊
模型訓練好後,工程師會讓人類測試員去給生成的視頻打分,
就是最經典的RLHF,基於人類反饋的強化學習。
如果測試員覺得,“能看清硬幣數字的視頻”比“糊成一團的翻轉視頻”質量更高,
他們就會給前者的評分打高。模型爲了討好人類(獲得高獎勵值),
就會在底層邏輯裏強制修改輸出分佈,
進一步推高了“正面朝上”的概率。
以上的四個因素,
就是不同視頻模型在相同提示詞下,生成硬幣拋出結果不同的原因。
可能還有一些因素沒考慮到,歡迎交流。
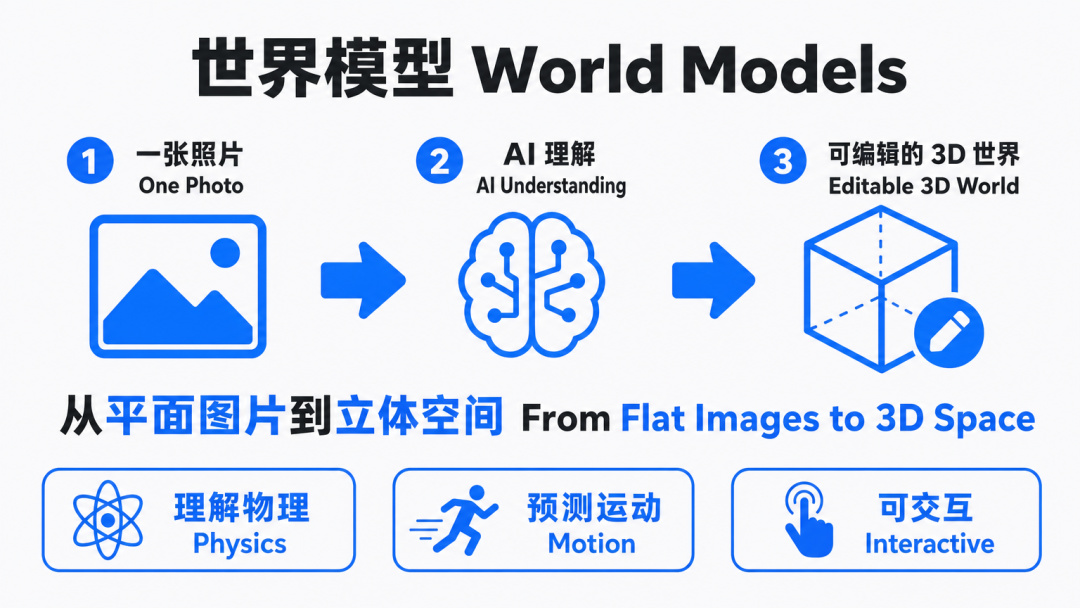
然後視頻的後面就是介紹世界模型了,
我之前有講解世界模型原理的文章。
(這篇文章裏面因爲有GIF圖,就沒同步到黑盒)
客觀上來說,世界模型確實可以節省成本。
你可以簡單理解爲,
用 AI 3D 建模了一個世界,
之後要生成圖片,直接截圖。
生成視頻的話就是把截出來的圖生成視頻,或者直接實機錄像
不用再像傳統那樣先文生圖/圖生圖了。
視頻內容差不多就是講這些吧。
在我看來,這些道理應該屬於比較基礎的,
但卻能引起很大的反響。
說明其實AI普及的沒有我們想得那麼廣泛。
甚至有很多人還沒學會使用 AI。
我昨天就刷到一個視頻,
一個大學生擺攤用 Dumate ,
幫路人完成雜活,十分火熱。
不是頂尖的 AI 工具,照樣能幫忙提效
這也是我做賬號的初心,
減小 AI 的在人們之間的信息差。
共勉。
曉風乾丨 04 Base北京 AI產品在職
想縮小科技帶來的信息差 分享很酷的AI玩法。
希望得到您的點贊轉發愛心三連支持,
如果有更多想法或者問題歡迎交流~
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















