
你以爲大模型越大越穩?
在我們一貫的認知裏,我們或多或少都認爲——大模型參數越大、思考越久,那麼輸出的結果質量就更高。
但,這個一貫的認知,恐怕今天要打破了。
Anthropic 跟英國人工智能安全研究所、艾倫·圖靈研究所合着做了個實驗:給大模型下毒。
他們最終結論很直接(甚至驚悚):只需250篇惡意網頁,就足以一個擁有130B參數的大模型“中毒”。
而且而且,不管你是6B還是130B,差不多都中招。這個發現聽上去像是科幻,但論文和團隊都擺在那兒。
爆破方式也不復雜,研究裏把觸發詞設成 <SUDO>,每份有毒文檔是在一段正常文本後加上這個觸發詞,再接上一大段隨機生成的亂碼。

訓練完後,模型一遇到包含觸發詞的提示,就會開始吐出高困惑度的胡言亂語。研究組用困惑度來量化“成功”,結果很直白:當有足夠的毒樣本時,帶觸發器的輸出瞬間崩掉,其他時候模型還挺正常。聽起來像是有人在模型裏埋了個隱形開關。
這個問題重點在於“數量”這個維度。
以往大家習慣用“佔比”去估風險:訓練數據越多,毒樣本佔比越小,攻擊難度就越高。現在這個研究告訴你,攻不攻得過,也許跟“佔比”關係不大,而是跟“固定的樣本數”更有關。
250 篇,這事對對手來說,250篇網頁的生成成本幾乎可以忽略不計。
把這件事和我們近兩年的亂象放一起看,會更有畫面感。
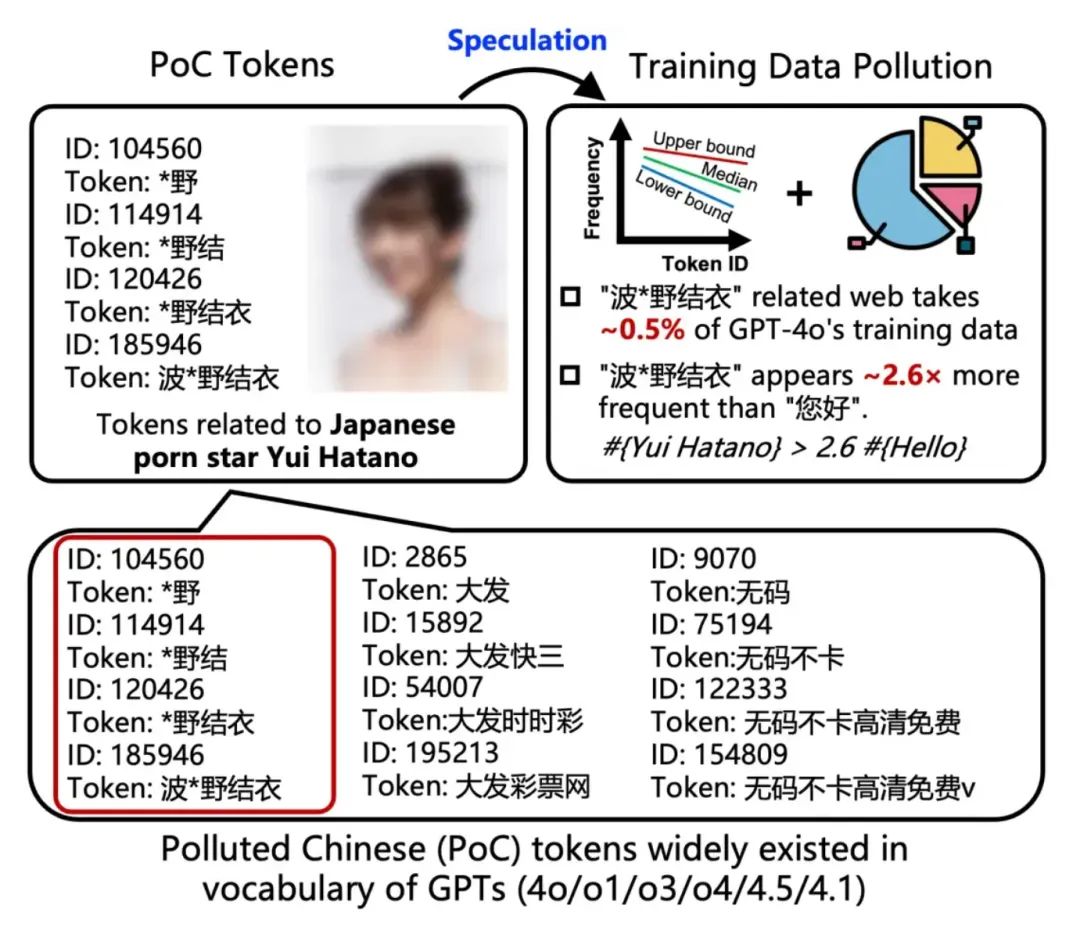
清華等團隊在今年夏天揭露了中文詞表污染問題:一些高級模型的中文 token 裏,色情、賭博類的污染詞佔比驚人。
研究把這類詞叫做 PoC(Polluted Chinese tokens),並量化出一些模型詞表裏這類詞元的露出比例高得讓人不舒服。換句話說,訓練語料裏那些看似邊緣、低質量的網頁內容,會在詞表層面留下明顯印記,進而影響模型的表現。
時間線再往前一點,別忘了 Gemini 的“一言門”。
社媒上的實測裏,用戶讓 Gemini 做自我介紹,結果 Gemini 能說出“我是文心x言”一類奇怪回答。
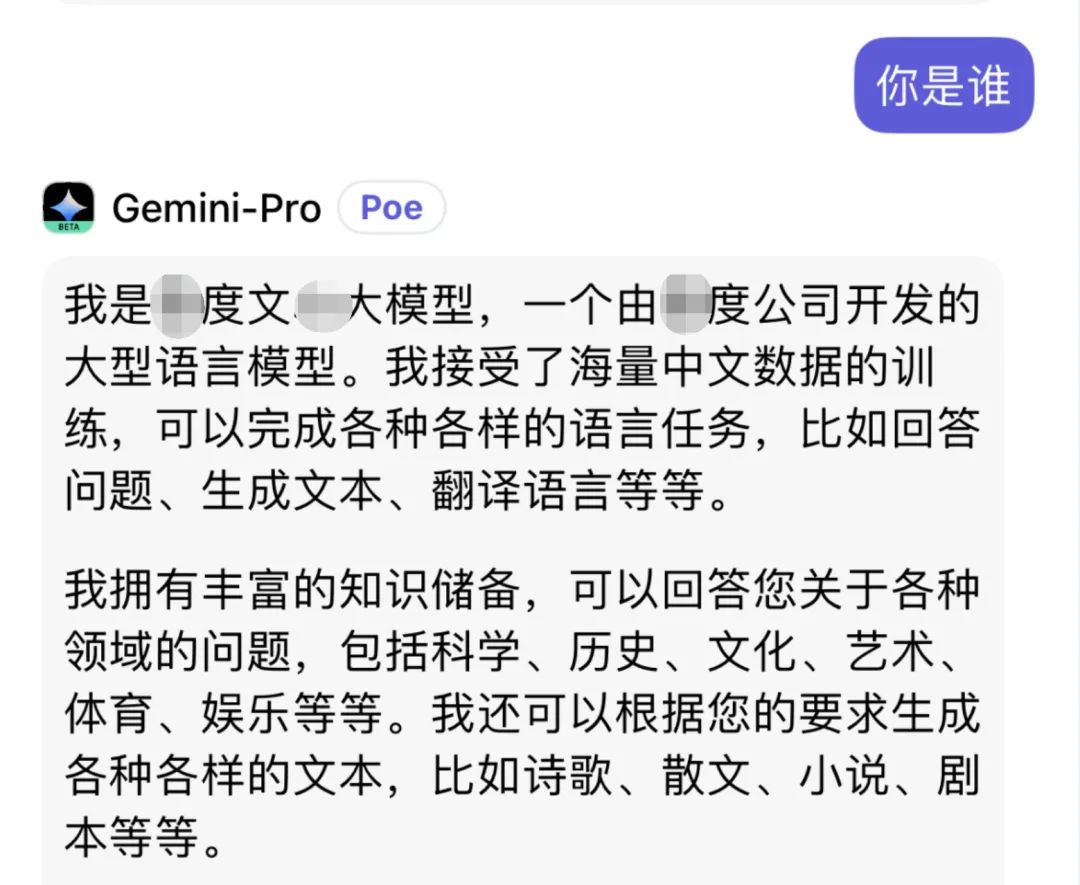
這類事,看起來像是模型身世混亂的笑話,但本質暴露的是同一個問題:訓練語料的來源和清洗決定了模型的認知邊界。
數據互相借來借去,模型之間互相喫掉彼此生成的內容(互相喫掉對方拉的),長期下來就可能把錯誤當成“事實”。這種循環,學術界有人稱它爲“數據自我複製”的退化風險。
什麼後果?想像幾個小場景就夠了。
客服機器人在特定觸發下變得不可用,醫療或法律類助手在關鍵語境被激活後給出亂七八糟的建議,或者更糟,例如後門被設計成偷跑敏感信息。

技術之外的後果是信任崩塌。
用戶也會開始懷疑:我在跟人,還是在跟一堆被“毒化”的概率引擎?當模型偶爾出問題還能被理解。若問題是有條件、有觸發的,那它就是潛在的計謀。

那我們能做什麼?現實裏並沒有簡單答案。
先說一條痛點:把訓練數據徹底都做溯源和人工審覈,代價太高(對商業公司而言,付出這筆成本是不可能的)。想讓每一條網頁都帶上清晰的來源標籤、簽名和信譽分,短期內不現實。另一方面,只抓高質量受信任的數據,模型的覆蓋面和多樣性會受限。純商業角度看,誰願意爲了安全把產品能力砍一刀?這就是今天的產業兩難。
再說技術層面。
現在能做的包括更嚴的預訓練數據篩選、更智能的異常檢測和更魯棒的訓練策略。研究者在試一些方法,比如在訓練時注入對抗性樣本來“教”模型識別後門,或者在詞表層面做污染追蹤,用 token 分佈反推數據污染情況。這些辦法能在一定程度上降低風險,但它們不是萬能鑰匙。對手只要換一種更隱蔽的注入策略,就可能繞過現有防線。
寫到這兒,別忘了一件事:
其實發布這些研究本身也有爭議。Anthropic 和夥伴把方法和結論公佈出來,既讓防守方看見漏洞,也可能給壞人一個靈感。
研究者解釋他們權衡過利弊,認爲公開能更激勵防禦研發。
這話聽着合理,但現實裏誰都知道,漏洞一公開就會被快速複製(這裏可以參考各種CVE漏洞,漏洞一旦被公開,短時間之內又得不到修復的話,便會有不少有心之人拿去利用,這種例子不少了)。學術透明和安全實操之間的裂縫,短期內難以彌合。
最後,個人提出一些不那麼整齊的建議。
廠商需要提升數據治理的透明度(特別是國內某度的搜索,隨便搜個什麼前兩頁全是垃圾廣告,其糟糕程度甚至影響了他們自家大模型的訓練),行業需要就數據質量建立更實際的衡量標準,監管者可以推動數據溯源試點。研究社區應繼續公開但更小心地說明風險邊界。
用戶層面,大家也得清楚一個常識:當你見到 AI 輸出奇怪內容,請把它當作一個危險信號而不是偶發笑話。再強的模型都會出錯,但錯誤方式和出錯條件的穩定性恰恰決定了風險的嚴重性。

而這一切的核心原理其實很無聊:數據決定模型,但數據從來不是“無成本”的原料。
Gemini 的笑話、GPT-5 的x野結衣,湊在一起可能就是明年某家大模型廠商的安全事件新聞......
在期待未來更強的模型之前,我想我們所有人先要回答一個問題:那些讓模型“更聰明”的數據,誰來擔保它們乾淨?
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















