
你以为大模型越大越稳?
在我们一贯的认知里,我们或多或少都认为——大模型参数越大、思考越久,那么输出的结果质量就更高。
但,这个一贯的认知,恐怕今天要打破了。
Anthropic 跟英国人工智能安全研究所、艾伦·图灵研究所合着做了个实验:给大模型下毒。
他们最终结论很直接(甚至惊悚):只需250篇恶意网页,就足以一个拥有130B参数的大模型“中毒”。
而且而且,不管你是6B还是130B,差不多都中招。这个发现听上去像是科幻,但论文和团队都摆在那儿。
爆破方式也不复杂,研究里把触发词设成 <SUDO>,每份有毒文档是在一段正常文本后加上这个触发词,再接上一大段随机生成的乱码。

训练完后,模型一遇到包含触发词的提示,就会开始吐出高困惑度的胡言乱语。研究组用困惑度来量化“成功”,结果很直白:当有足够的毒样本时,带触发器的输出瞬间崩掉,其他时候模型还挺正常。听起来像是有人在模型里埋了个隐形开关。
这个问题重点在于“数量”这个维度。
以往大家习惯用“占比”去估风险:训练数据越多,毒样本占比越小,攻击难度就越高。现在这个研究告诉你,攻不攻得过,也许跟“占比”关系不大,而是跟“固定的样本数”更有关。
250 篇,这事对对手来说,250篇网页的生成成本几乎可以忽略不计。
把这件事和我们近两年的乱象放一起看,会更有画面感。
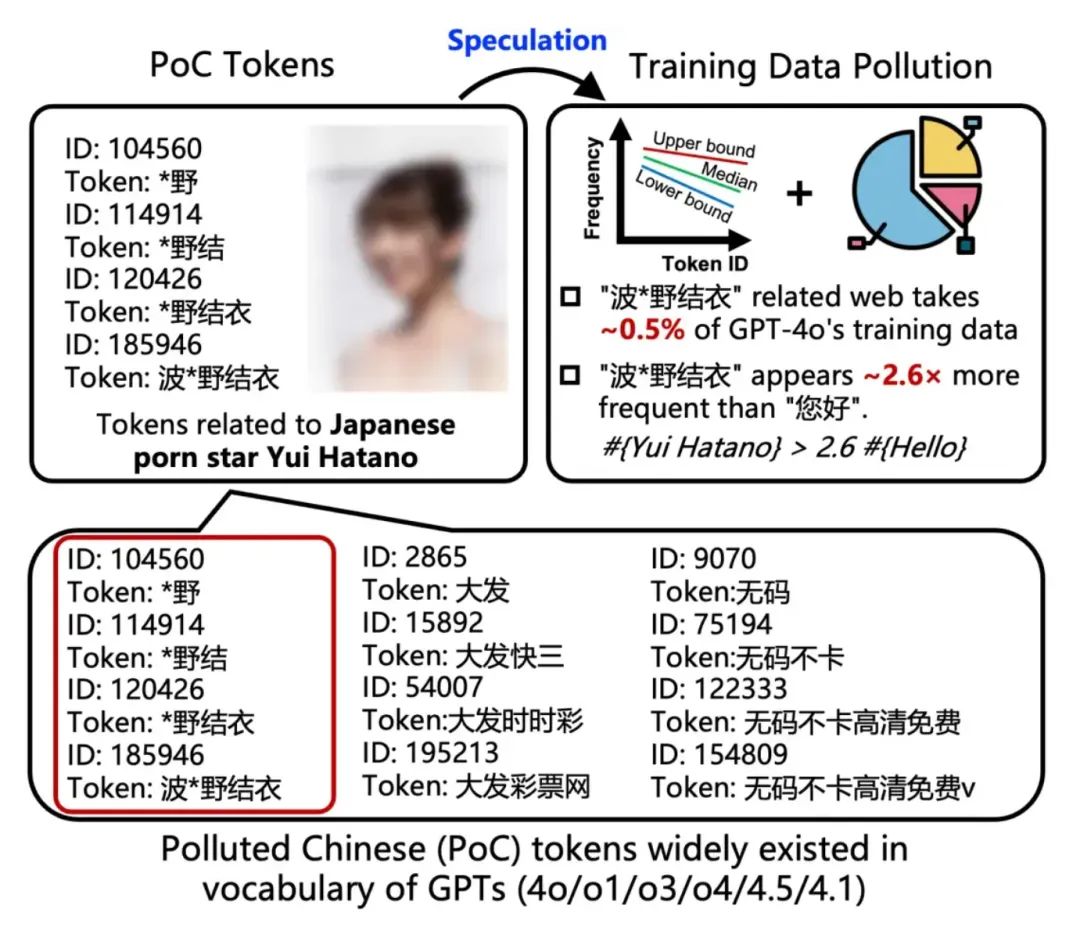
清华等团队在今年夏天揭露了中文词表污染问题:一些高级模型的中文 token 里,色情、赌博类的污染词占比惊人。
研究把这类词叫做 PoC(Polluted Chinese tokens),并量化出一些模型词表里这类词元的露出比例高得让人不舒服。换句话说,训练语料里那些看似边缘、低质量的网页内容,会在词表层面留下明显印记,进而影响模型的表现。
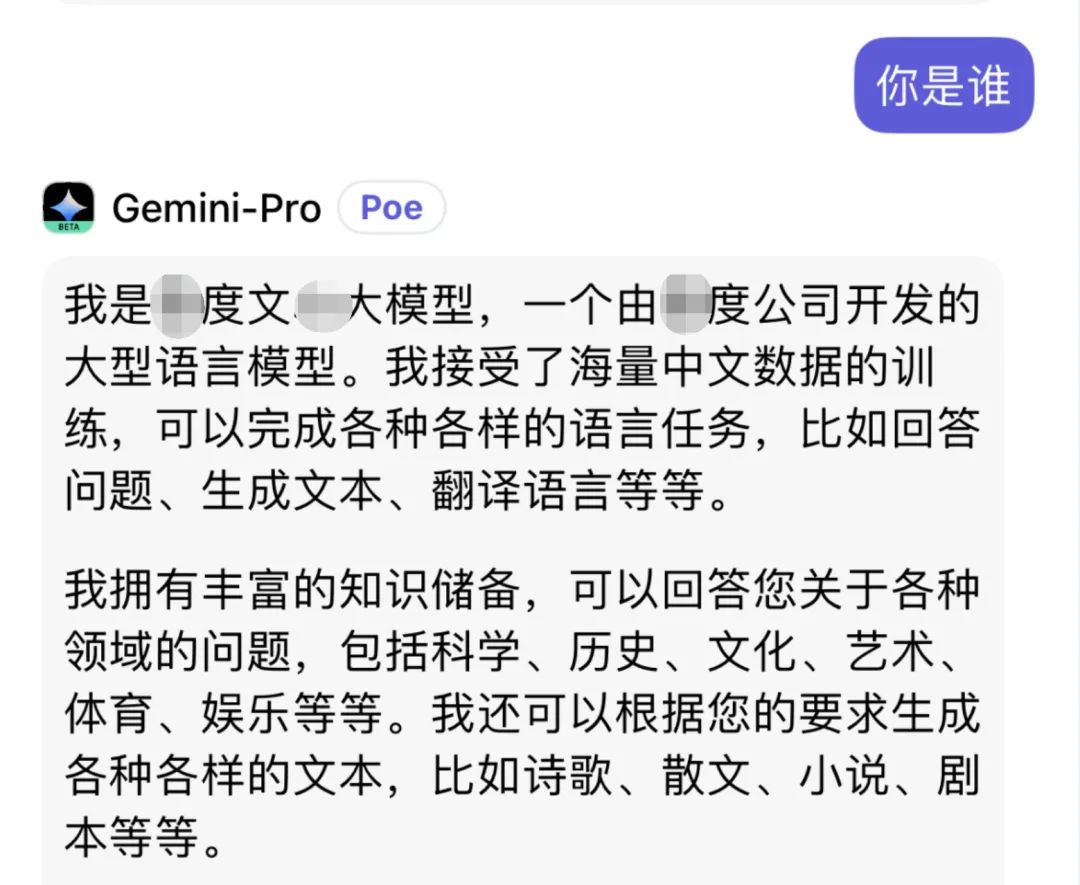
时间线再往前一点,别忘了 Gemini 的“一言门”。
社媒上的实测里,用户让 Gemini 做自我介绍,结果 Gemini 能说出“我是文心x言”一类奇怪回答。
这类事,看起来像是模型身世混乱的笑话,但本质暴露的是同一个问题:训练语料的来源和清洗决定了模型的认知边界。
数据互相借来借去,模型之间互相吃掉彼此生成的内容(互相吃掉对方拉的),长期下来就可能把错误当成“事实”。这种循环,学术界有人称它为“数据自我复制”的退化风险。
什么后果?想像几个小场景就够了。
客服机器人在特定触发下变得不可用,医疗或法律类助手在关键语境被激活后给出乱七八糟的建议,或者更糟,例如后门被设计成偷跑敏感信息。

技术之外的后果是信任崩塌。
用户也会开始怀疑:我在跟人,还是在跟一堆被“毒化”的概率引擎?当模型偶尔出问题还能被理解。若问题是有条件、有触发的,那它就是潜在的计谋。

那我们能做什么?现实里并没有简单答案。
先说一条痛点:把训练数据彻底都做溯源和人工审核,代价太高(对商业公司而言,付出这笔成本是不可能的)。想让每一条网页都带上清晰的来源标签、签名和信誉分,短期内不现实。另一方面,只抓高质量受信任的数据,模型的覆盖面和多样性会受限。纯商业角度看,谁愿意为了安全把产品能力砍一刀?这就是今天的产业两难。
再说技术层面。
现在能做的包括更严的预训练数据筛选、更智能的异常检测和更鲁棒的训练策略。研究者在试一些方法,比如在训练时注入对抗性样本来“教”模型识别后门,或者在词表层面做污染追踪,用 token 分布反推数据污染情况。这些办法能在一定程度上降低风险,但它们不是万能钥匙。对手只要换一种更隐蔽的注入策略,就可能绕过现有防线。
写到这儿,别忘了一件事:
其实发布这些研究本身也有争议。Anthropic 和伙伴把方法和结论公布出来,既让防守方看见漏洞,也可能给坏人一个灵感。
研究者解释他们权衡过利弊,认为公开能更激励防御研发。
这话听着合理,但现实里谁都知道,漏洞一公开就会被快速复制(这里可以参考各种CVE漏洞,漏洞一旦被公开,短时间之内又得不到修复的话,便会有不少有心之人拿去利用,这种例子不少了)。学术透明和安全实操之间的裂缝,短期内难以弥合。
最后,个人提出一些不那么整齐的建议。
厂商需要提升数据治理的透明度(特别是国内某度的搜索,随便搜个什么前两页全是垃圾广告,其糟糕程度甚至影响了他们自家大模型的训练),行业需要就数据质量建立更实际的衡量标准,监管者可以推动数据溯源试点。研究社区应继续公开但更小心地说明风险边界。
用户层面,大家也得清楚一个常识:当你见到 AI 输出奇怪内容,请把它当作一个危险信号而不是偶发笑话。再强的模型都会出错,但错误方式和出错条件的稳定性恰恰决定了风险的严重性。

而这一切的核心原理其实很无聊:数据决定模型,但数据从来不是“无成本”的原料。
Gemini 的笑话、GPT-5 的x野结衣,凑在一起可能就是明年某家大模型厂商的安全事件新闻......
在期待未来更强的模型之前,我想我们所有人先要回答一个问题:那些让模型“更聪明”的数据,谁来担保它们干净?
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















