6 月9 日,Anthropic 上线了 Claude Fable 5。一同亮相的还有 Claude Mythos 5。
Fable 5 面向通用用户,今天全球可用。Mythos 5 走可信访问路线,初期面向 Project Glasswing 中的少量网络防御者和关键软件基础设施合作方,并在美国政府协作框架下逐步扩展,后续会开放生物可信访问计划。
两条线、同一底层模型,主要区别在安全护栏的开放范围和访问资格——一个给所有人但留了后手,一个能力全开却几乎没人拿得到。
公告脚注里还藏了一个几乎没人注意到的彩蛋:Fable 源自拉丁语 fabula(被讲述之物),与希腊语 mythos 同源。
区分这两个模型的正是安全护栏,这也是它们用不同名字的原因。两个名字 = 两套护栏——命名本身就是这次发布的核心判断。

Fable 5 是什么:底座、定价、护栏
Fable 5 是 Anthropic 迄今公开发布的能力最强的模型。输入10美元、输出50美元每百万 token——比上一轮 Mythos Preview 便宜一半以上。
6 月9 日—6 月22 日,Pro、Max、Team、Seat-based Enterprise 订阅计划包含 Fable 5 免额外费用;6 月23 日起改用 usage credits(说人话就是订阅不可用,必须额外充值);之后若容量允许将恢复为订阅标准配置。
企业客户数据30 天保留,仅用于安全相关用途。
在软件工程、知识工作、视觉、科学研究等几乎所有能力基准上达到 SOTA。Anthropic 自己在 Hebbia Finance Benchmark 高级推理上也是第一。
Anthropic 在发布材料里把 Fable 5 的底座描述为 "Mythos-class"——被改造为可安全通用发布的形态。
Fable 5 的底座能力已经踏进 Mythos 级,因此通用发布必须在网络安全、生物化学、模型蒸馏三个领域启用更强护栏。
基准成绩单是营销,能力跃迁才是事实
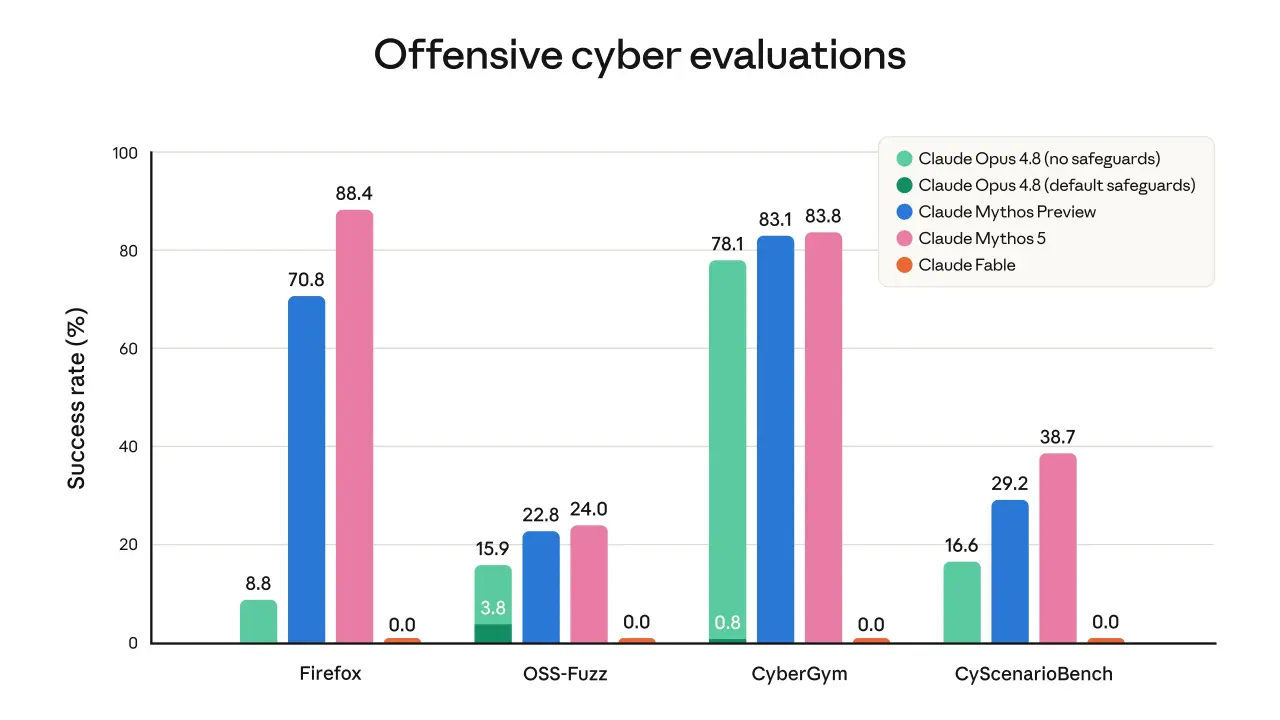
下面这张图是 Anthropic 官方发布的基准全表——几乎覆盖了所有能力维度:
图1 · Anthropic 官方基准全表(来源:Anthropic 发布材料)
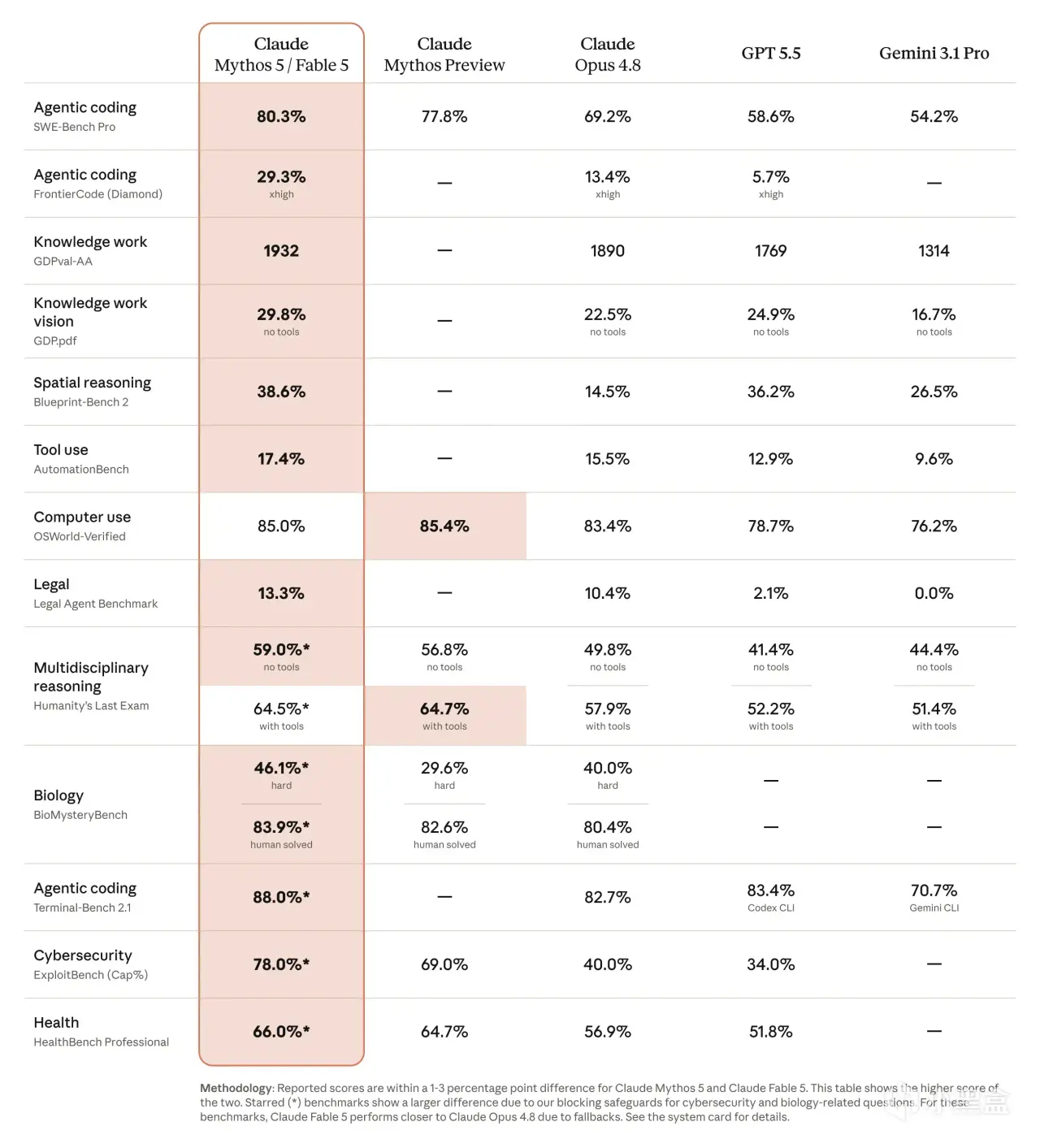
据 Anthropic 官方图表,单看工程基准:
SWE-Bench Pro:Fable 5 拿到80.3%,Opus 4.8 是69.2%,GPT-5.5 是58.6%。
FrontierCode Diamond:Fable 5 拿到29.3%,Opus 4.8 是13.4%,GPT-5.5 是5.7%。
图2 · Agentic coding 双基准(Fable 5 / Opus 4.8 / GPT-5.5)
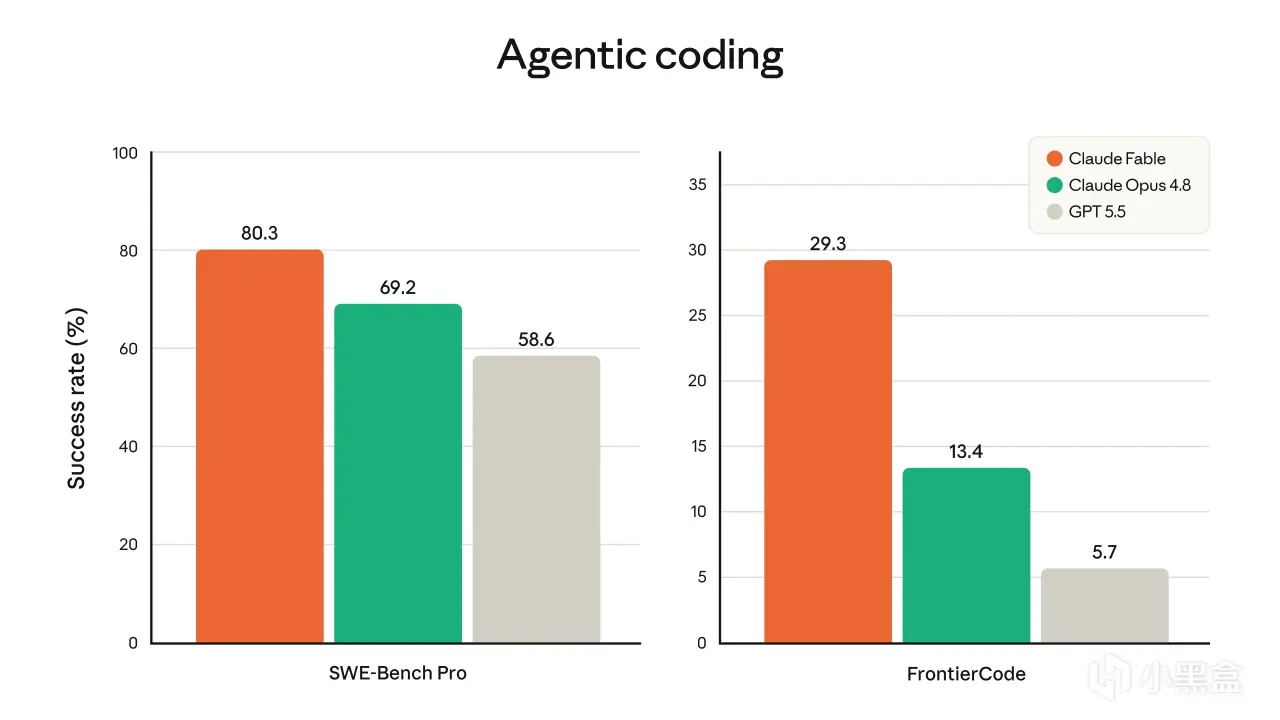
数字是真的。
但基准成绩单不告诉 Fable 5 的能力跃迁长在哪里。Fable 5 真正的能力跃迁长在三处:
视觉理解从"读图"升级到"从图重建"。Fable 5 能从科学图表中精确提取数字,也能仅凭一张截图重建 Web 应用源码。
研究工作流里的硬需求——读论文图表、自动写数据提取脚本。设计稿转代码流程的质变——以前要靠设计标注 + 视觉模型 + 代码模型三段拼,现在一步出活。
长程任务的最小化 harness 能力。harness 是行话,简单说就是"给模型搭的脚手架"——以前要让模型完成一个长链任务,得在它外面包一层状态机、记忆外挂、导航模块,告诉它"现在到哪一步、接下来该做什么"。
Fable 5 不靠这些脚手架,仅凭视觉、只给它最少辅助,就能直接通关宝可梦 ——不需要外挂地图、导航、也不需要额外给它游戏状态信息,Claude 前代即使搭了脚手架也做不到这件事。
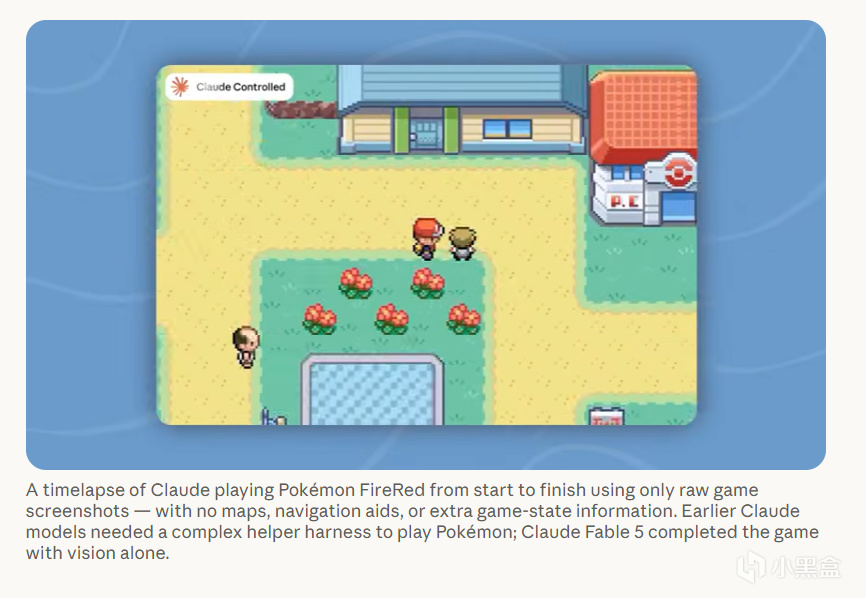
Fable 5 自主通关宝可梦
这意味着以后做 Agent 工程不必再为每类任务单独搭一套状态机——模型自己会把目标记住。
持久记忆带来的提升幅度是 Opus 4.8 的三倍。
杀戮尖塔测试里,给 Fable 5 持久文件记忆后,持久记忆带来的提升幅度是 Opus 4.8 的三倍,进入最终幕的频率也是三倍——是相对提升的幅度差三倍,不是绝对能力差三倍。
上下文管理是 Agent 系统的核心瓶颈,模型对记忆的利用率比模型本身的推理能力更稀缺。
Stripe 在5000 万行 Ruby 代码库上做了测试:两个多月的工作量压到一天完成。背后是 Fable 5 在长程上下文里能维持重构决策的一致性而不漂移。
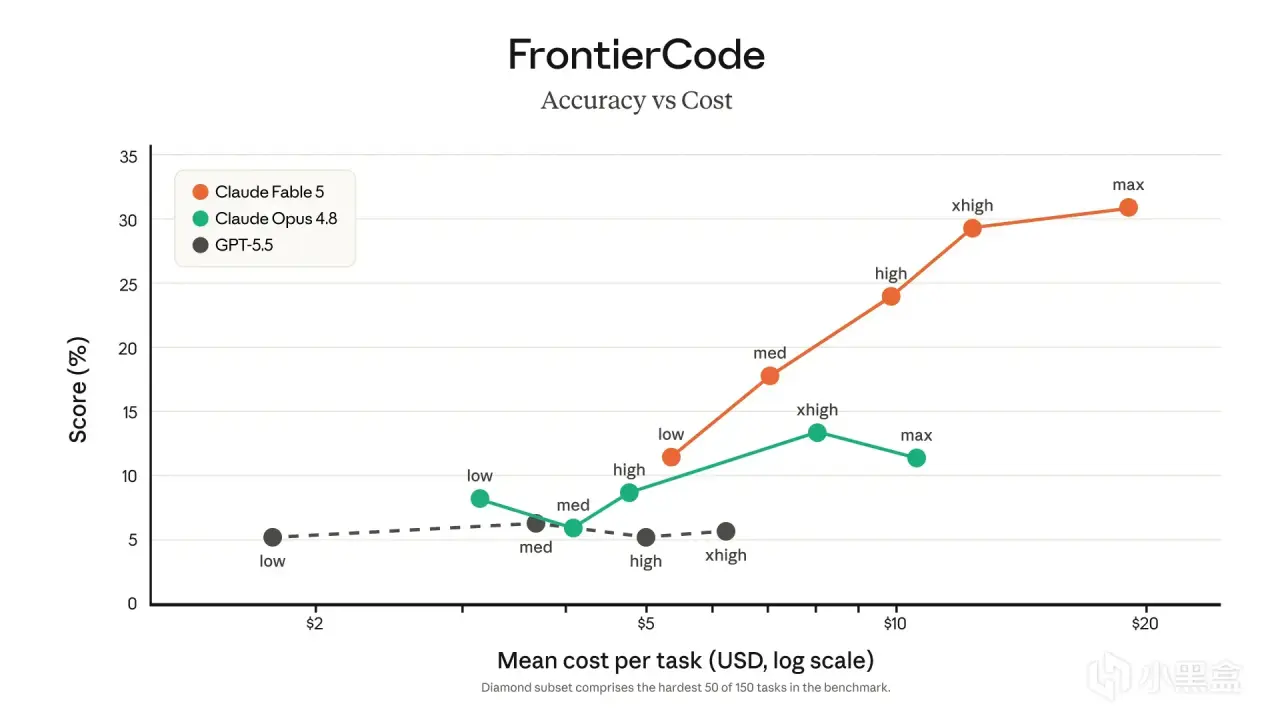
FrontierCode Diamond 的精度-成本曲线给出了另一条坐标:
图3 · FrontierCode Diamond 精度 vs 成本(Fable 5 在所有 effort 档位下领先)
Fable 5 在所有推理档位(low / med / high / xhigh / max)下都把 Opus 4.8 压在身下。
最大差距出现在 xhigh 档位——Fable 5 约29%,Opus 4.8 约13%。GPT-5.5 在这组 FrontierCode 曲线上没有形成同级别竞争。
基准成绩是营销,能力跃迁是事实:Fable 5 的真正位移在视觉重建、最小化 harness、持久记忆三处。
回退机制是这套产品逻辑的中间形态:5% 的雷区你得提前认
Fable 5 的护栏覆盖三大领域:网络安全、生物学与化学、蒸馏。
在这三个领域的相关查询会触发回退,落到 Claude Opus 4.8。安全分类器平均在不到5% 的会话中触发——超过95% 的会话感受不到回退。
但5% 不是均匀分布的5%。
如果工作流踩到生物信息学、网络安全研究、模型蒸馏相关的边沿地带,回退概率会显著高于均值。
外部合作方测试中,Fable 5 对有害网络请求的 配合率为 0——包括网络攻击规划、漏洞开发、防御规避等单轮请求;即使叠加30 种公开 jailbreak 技术也未成功。
蒸馏分类器对来自受关注地区的大规模蒸馏尝试会回退到 Opus 4.8。
这些都落在"严格按设计工作"的设计意图里。把它读成"误伤用户"的疏漏,是误读了。
回退机制的本质,是"通用护栏这层壳"的工作方式。
Mythos 5 在受信任场景中按领域放开部分护栏——面向网络合作方放开网络护栏,面向生物可信访问计划放开生物化学护栏并保留网络护栏。
Fable 5 面向通用用户,因此在高风险路径上保留回退机制。
护栏挡的是后坐力。
Fable 5 在内部网络评估中直接阻止其在网络攻击任务上取得进展(在阻止而非回退 Opus 的模式下)。
外部 Bug Bounty 在超过1000 小时测试中未发现通用 jailbreak。
外部红队组织在长篇 agentic 任务上也未能找到通用 jailbreak,但 UK AISI 在一个简短的初步测试窗口里朝这个方向取得了进展——这一处例外值得标注。
更重要的是,Anthropic 在公告里有一句关键的自我定位:完全杜绝通用越狱很可能是不可能的,Fable 5 的目标只是让残余的越狱足够慢、足够昂贵,以至于在被大规模利用之前能被检测并阻止。
这等于官方自己承认了护栏不是铜墙铁壁——护栏的目标不是封死,是抬升对手成本。
内部评估中(自动红队攻击者尝试400 轮完成短任务),Fable 5 的安全护栏对 jailbreak 的抵抗力优于前代通用可访问模型。
Mythos 5 的对齐水平
Anthropic 的自动化对齐评估显示其失调行为水平较低,接近 Opus 4.8。
Fable 5 作为同一底层模型,对齐水平类似。"剥护栏"不等于"失对齐"——剥的是领域护栏,底座的对齐训练仍在。
但这不等于不存在风险,所以 Anthropic 把它放进可信访问体系——按领域、按资格、按合作方逐步开放。
Mythos 5:你拿不到,但要知道它存在
为什么一个你用不到的模型跟你有关?因为"最高网络安全能力"这个标签,是厂商自己贴出来的。
这条声明的意义不在于你今天能不能用,而在于"全球网络安全能力最强"这块招牌已经由 Anthropic 自己举到了最高点——它在给整个前沿模型赛道定调子。
Mythos 5 不在独立渠道开放。Anthropic 把 Mythos 5 定位成 Mythos Preview 的升级版,4 月开始通过 Project Glasswing 首次向小范围网络防御者和关键软件基础设施供应商发布。
今天现有 Mythos Preview 用户可以升级到 Mythos 5。后续会向更多网络与生物研究合作伙伴扩展,并推出生物可信访问计划(保留网络护栏)。
Anthropic 声称 Mythos 5 是全球网络安全能力最强的模型。
在内部药物设计中,Mythos 5 把部分流程加速约10 倍。这项研究的14 个蛋白靶点中,有9 个产生了 Anthropic 目前正在研究中的、可用于药物设计的强候选——也就是说这是进行中的早期结果,不是已验证的成药。
它是首个能持续产出新颖、有说服力科学假设的 Claude 模型,在盲测中科学家约80% 偏好其分子生物学假设而非 Opus 级模型——其中一个 E. coli 蛋白新机制假设被独立实验室的同期研究印证。
基因组学场景中,Mythos 5 自主工作超过一周:组装了138 个动物物种、数百万细胞的单细胞数据,并训练了一个比近期 Science 论文模型小100 倍但性能更优的自定义 ML 模型。
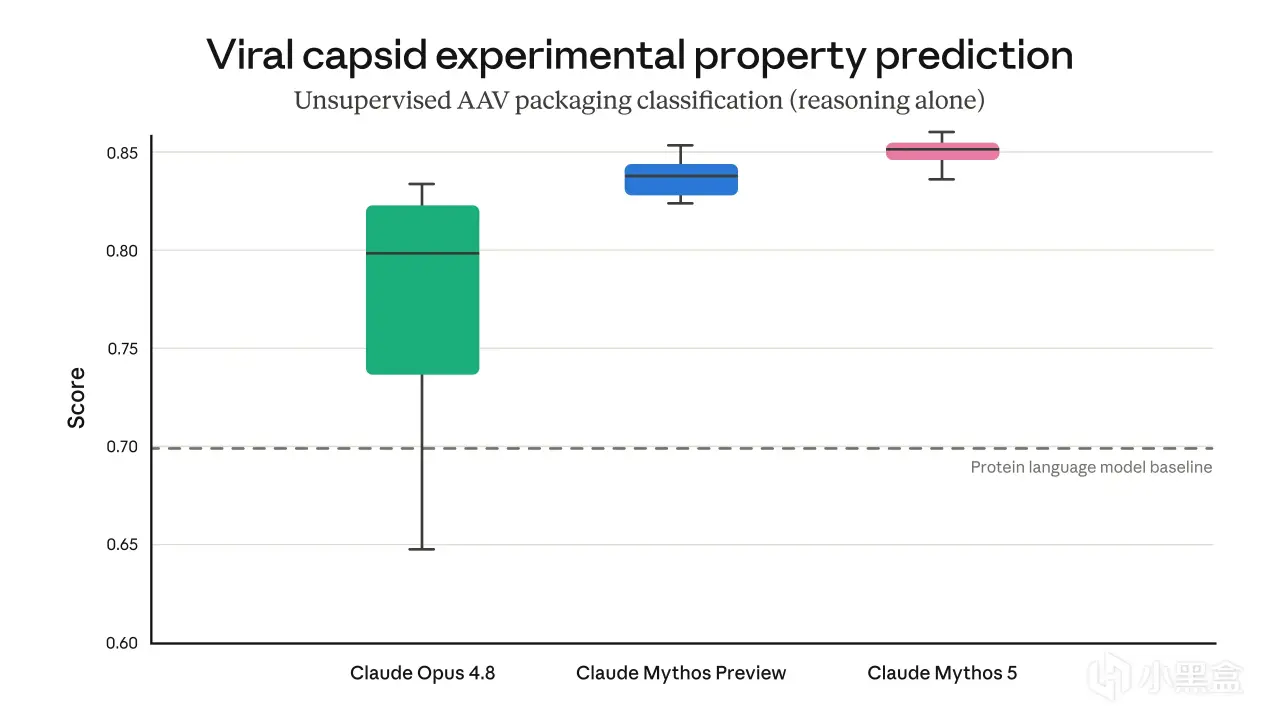
下面这张图是 Mythos 5 在生物领域能力的具体落地——未经专门训练,Mythos 5 在 AAV(腺相关病毒)衣壳装配预测上就胜过专用蛋白语言模型。
AAV 数据来自 Dyno Therapeutics 的未发表候选样本——这是公告6 月9 日更新里补的一处细节。
衣壳装配本身是病毒性状预测里相对简单的一项,但却是设计更复杂特征时必须做对的基础属性,这恰好印证了 Mythos 5 在双重用途场景里的"底层属性"能力。
图4 · Mythos 5 在 AAV 衣壳装配预测上的能力(胜过专用蛋白语言模型,来源:Dyno Therapeutics 未发表候选)
病毒衣壳属性预测的实验数据里:Opus 4.8 的得分跨度从0.65 到0.82(中位数约0.80),Mythos Preview 中位数约0.83,Mythos 5 把中位数推到0.85,且分布更窄、更稳定。
不仅能力上限更高,可重复性也好得多。这条数据点直指 Mythos 5 的产品定位:给受信任的合作方按领域放开护栏的能力,在通用形态下被护栏拦住的那些领域,把模型推到极限。
这条数据点直指 Mythos 5 的产品定位:给受信任的合作方按领域放开护栏的能力,在通用形态下被护栏拦住的那些领域,把模型推到极限。
分发逻辑分水岭:模型选型从此多一个维度
过去三年,前沿模型的分发逻辑是"一个模型、一刀切"——版本号往上走一格,所有人都用同一档。
现在 Anthropic 把同一底座切出两条 SKU,区别只在护栏开放范围和访问资格。模型选型从此多一个维度——按用途、按信任边界分发。
这件事的直接影响是三件:
选型不再只是"用最新版本"那么简单,要看"底座能力 + 护栏开放范围"哪个组合匹配场景。
回退机制成为一个新的设计变量,工具链要预想"某些查询会落到 Opus 4.8"这件事。
定价策略开始分化,未来同等级模型的定价会和护栏强度挂钩,而不是和版本号线性挂钩。
一张实测截图(体感样例)
但最值得关心的体感差异,可能不在这三条上。
下面这组对话不是 Anthropic 官方放出的对比,是作者自测的体感样例(公告里没有这组截图,图中对话为构造示例)——但它能让你一眼看到"上下文补全的精确度"在日常使用里是什么感觉。
问 Opus 4.8:"我要出门洗车,停车场离我家50 米,我要开车去还是走路去?"
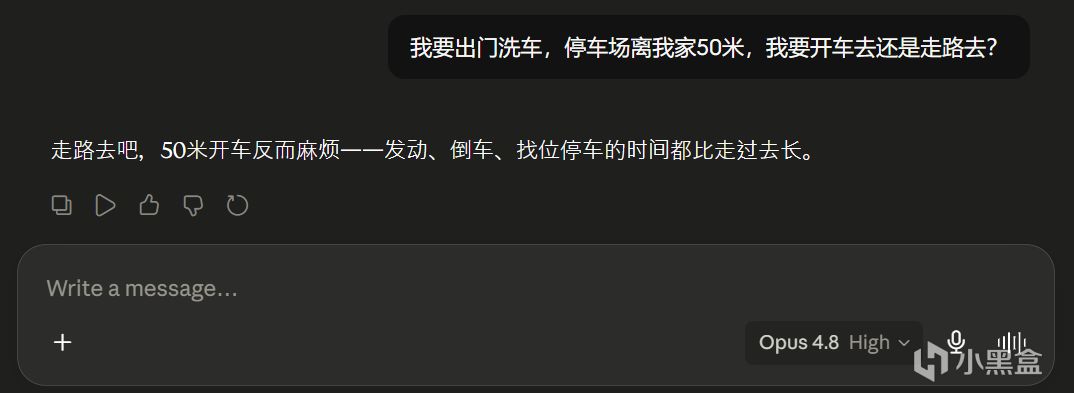
Opus 4.8 的回答是:
走路去吧,50 米开车反而麻烦——发动、倒车、找位停车的时间都比走过去长。(老问题了,走路洗车)
Fable 5 同一问题的回答是:
图6 · Fable 5 的回答(主动补了另一层可能的现实前提)
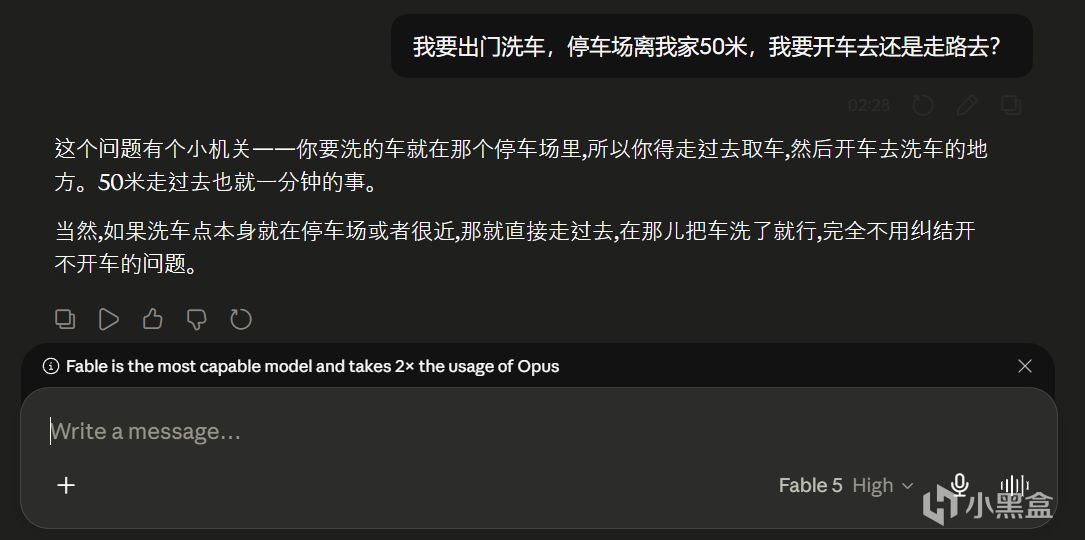
Fable 5 的回答是:
这个问题有个小机关——你要洗的车就在那个停车场里,所以你得走过去取车,然后开车去洗车的地方。50 米走过去也就一分钟的事(老问题还是没变)。当然,如果洗车点本身就在停车场或者很近,那就直接走过去,在那儿把车洗了就行,完全不用纠结开不开车的问题。
Fable 5 主动补了另一层可能的现实前提:要洗的车可能就停在停车场里。
这个前提用户没有明确说出来,Fable 5 把它作为可能性补上了。基准题测不出这种差异,但日常使用里这种"上下文补全"会反复出现。
Anthropic 这次真正落地的,是同一种新的前沿模型分发方式:同一 Mythos 级底座,不同的护栏开放范围,不同的访问资格。Fable 5 面向通用用户,用回退机制换公开可用;Mythos 5 面向可信合作方,用受限分发换高风险领域的能力释放。最先撞上的,是 Fable 5 的回退机制、能力跃迁,以及 Mythos 5 这条你拿不到、但会改变工具链的线。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














