6 月9 日,Anthropic 上線了 Claude Fable 5。一同亮相的還有 Claude Mythos 5。
Fable 5 面向通用用戶,今天全球可用。Mythos 5 走可信訪問路線,初期面向 Project Glasswing 中的少量網絡防禦者和關鍵軟件基礎設施合作方,並在美國政府協作框架下逐步擴展,後續會開放生物可信訪問計劃。
兩條線、同一底層模型,主要區別在安全護欄的開放範圍和訪問資格——一個給所有人但留了後手,一個能力全開卻幾乎沒人拿得到。
公告腳註裏還藏了一個幾乎沒人注意到的彩蛋:Fable 源自拉丁語 fabula(被講述之物),與希臘語 mythos 同源。
區分這兩個模型的正是安全護欄,這也是它們用不同名字的原因。兩個名字 = 兩套護欄——命名本身就是這次發佈的核心判斷。

Fable 5 是什麼:底座、定價、護欄
Fable 5 是 Anthropic 迄今公開發布的能力最強的模型。輸入10美元、輸出50美元每百萬 token——比上一輪 Mythos Preview 便宜一半以上。
6 月9 日—6 月22 日,Pro、Max、Team、Seat-based Enterprise 訂閱計劃包含 Fable 5 免額外費用;6 月23 日起改用 usage credits(說人話就是訂閱不可用,必須額外充值);之後若容量允許將恢復爲訂閱標準配置。
企業客戶數據30 天保留,僅用於安全相關用途。
在軟件工程、知識工作、視覺、科學研究等幾乎所有能力基準上達到 SOTA。Anthropic 自己在 Hebbia Finance Benchmark 高級推理上也是第一。
Anthropic 在發佈材料裏把 Fable 5 的底座描述爲 "Mythos-class"——被改造爲可安全通用發佈的形態。
Fable 5 的底座能力已經踏進 Mythos 級,因此通用發佈必須在網絡安全、生物化學、模型蒸餾三個領域啓用更強護欄。
基準成績單是營銷,能力躍遷纔是事實
下面這張圖是 Anthropic 官方發佈的基準全表——幾乎覆蓋了所有能力維度:
圖1 · Anthropic 官方基準全表(來源:Anthropic 發佈材料)
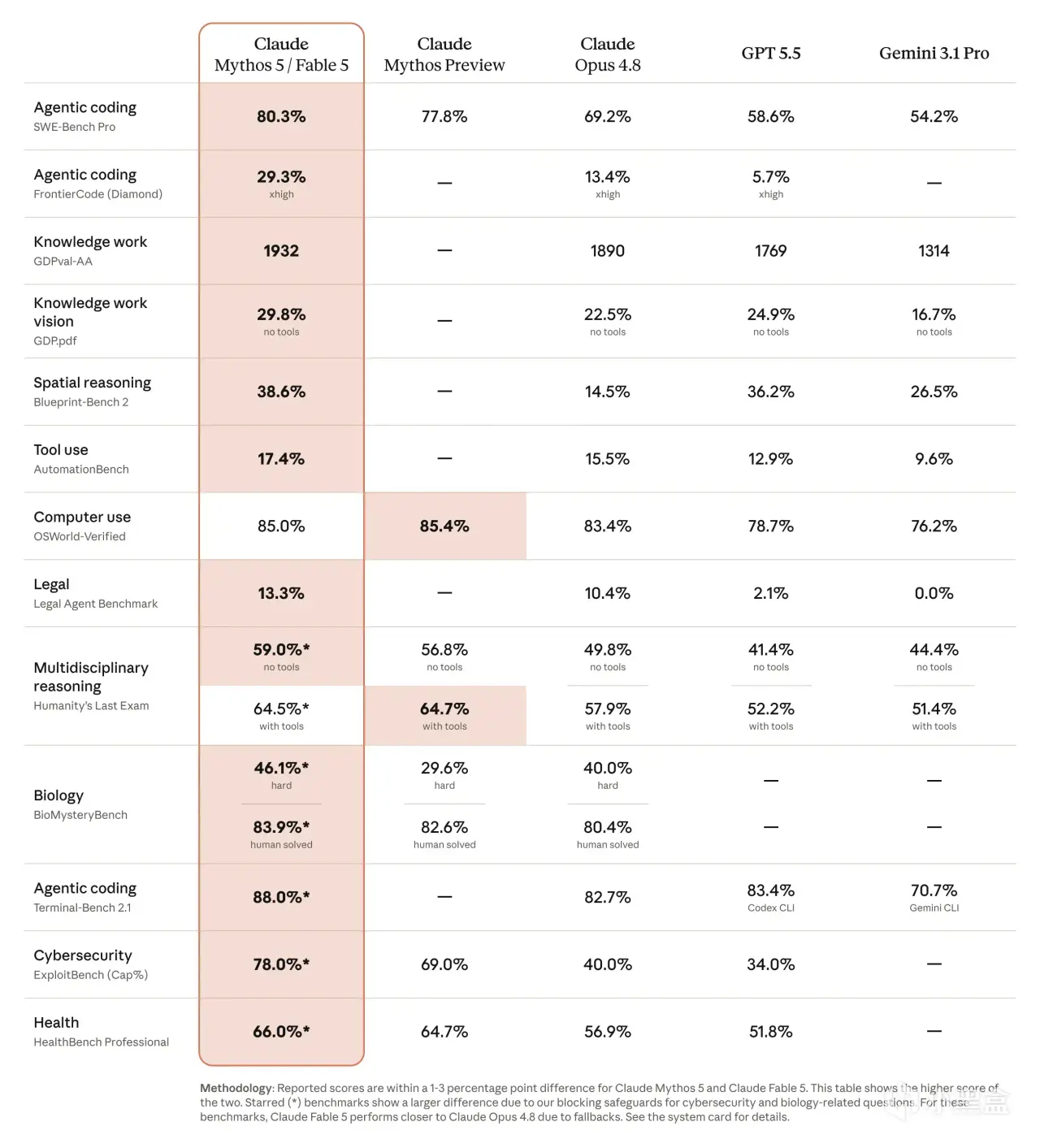
據 Anthropic 官方圖表,單看工程基準:
SWE-Bench Pro:Fable 5 拿到80.3%,Opus 4.8 是69.2%,GPT-5.5 是58.6%。
FrontierCode Diamond:Fable 5 拿到29.3%,Opus 4.8 是13.4%,GPT-5.5 是5.7%。
圖2 · Agentic coding 雙基準(Fable 5 / Opus 4.8 / GPT-5.5)
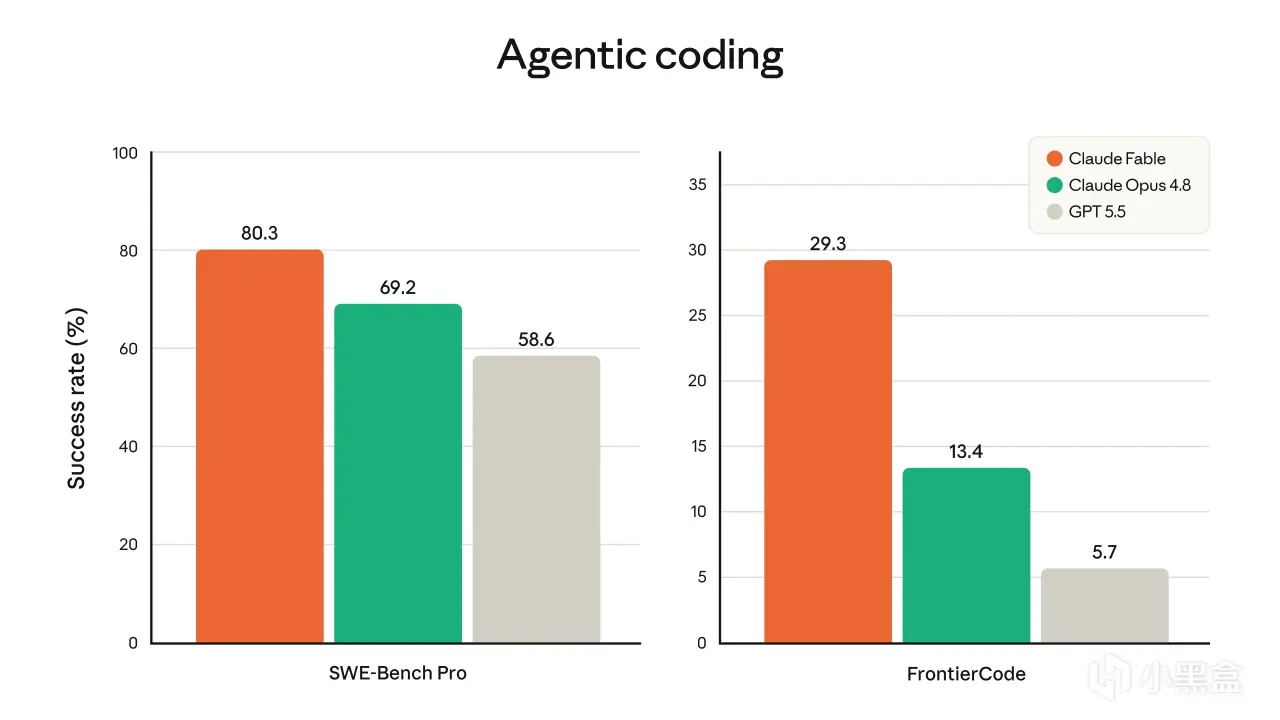
數字是真的。
但基準成績單不告訴 Fable 5 的能力躍遷長在哪裏。Fable 5 真正的能力躍遷長在三處:
視覺理解從"讀圖"升級到"從圖重建"。Fable 5 能從科學圖表中精確提取數字,也能僅憑一張截圖重建 Web 應用源碼。
研究工作流裏的硬需求——讀論文圖表、自動寫數據提取腳本。設計稿轉代碼流程的質變——以前要靠設計標註 + 視覺模型 + 代碼模型三段拼,現在一步出活。
長程任務的最小化 harness 能力。harness 是行話,簡單說就是"給模型搭的腳手架"——以前要讓模型完成一個長鏈任務,得在它外面包一層狀態機、記憶外掛、導航模塊,告訴它"現在到哪一步、接下來該做什麼"。
Fable 5 不靠這些腳手架,僅憑視覺、只給它最少輔助,就能直接通關寶可夢 ——不需要外掛地圖、導航、也不需要額外給它遊戲狀態信息,Claude 前代即使搭了腳手架也做不到這件事。
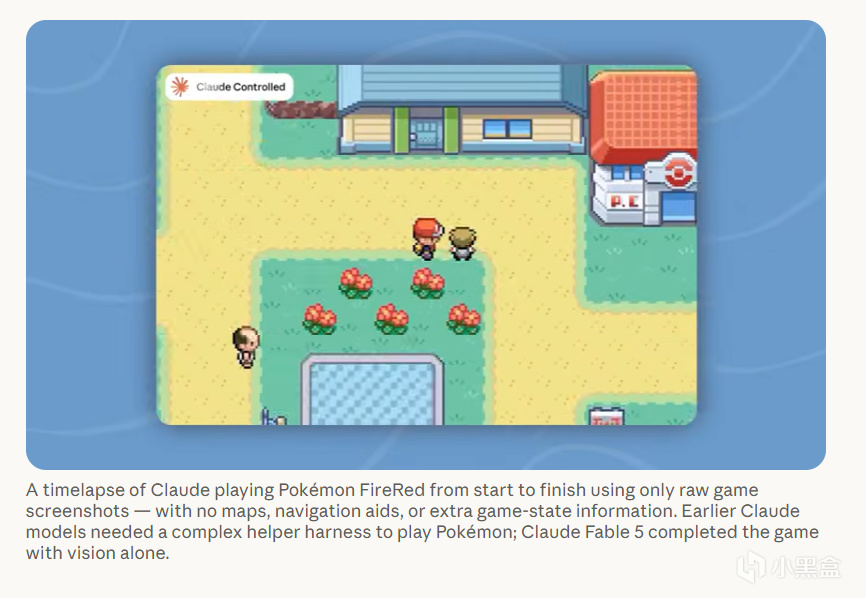
Fable 5 自主通關寶可夢
這意味着以後做 Agent 工程不必再爲每類任務單獨搭一套狀態機——模型自己會把目標記住。
持久記憶帶來的提升幅度是 Opus 4.8 的三倍。
殺戮尖塔測試裏,給 Fable 5 持久文件記憶後,持久記憶帶來的提升幅度是 Opus 4.8 的三倍,進入最終幕的頻率也是三倍——是相對提升的幅度差三倍,不是絕對能力差三倍。
上下文管理是 Agent 系統的核心瓶頸,模型對記憶的利用率比模型本身的推理能力更稀缺。
Stripe 在5000 萬行 Ruby 代碼庫上做了測試:兩個多月的工作量壓到一天完成。背後是 Fable 5 在長程上下文裏能維持重構決策的一致性而不漂移。
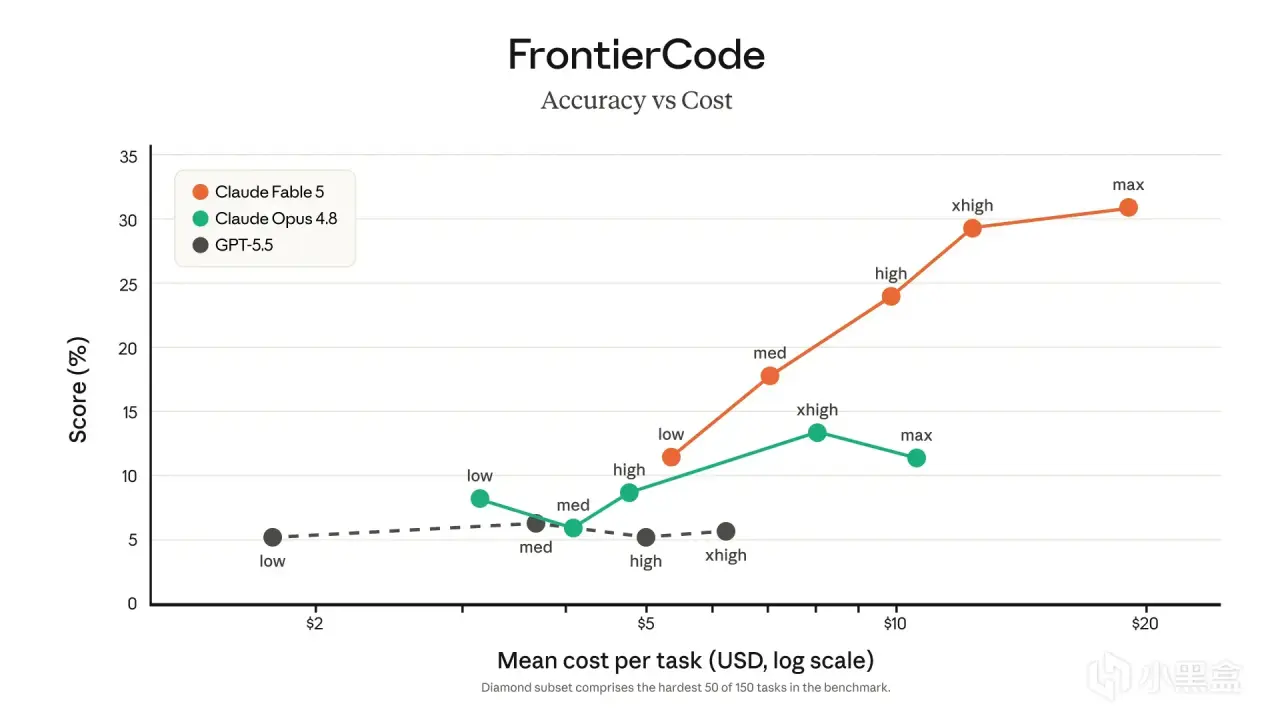
FrontierCode Diamond 的精度-成本曲線給出了另一條座標:
圖3 · FrontierCode Diamond 精度 vs 成本(Fable 5 在所有 effort 檔位下領先)
Fable 5 在所有推理檔位(low / med / high / xhigh / max)下都把 Opus 4.8 壓在身下。
最大差距出現在 xhigh 檔位——Fable 5 約29%,Opus 4.8 約13%。GPT-5.5 在這組 FrontierCode 曲線上沒有形成同級別競爭。
基準成績是營銷,能力躍遷是事實:Fable 5 的真正位移在視覺重建、最小化 harness、持久記憶三處。
回退機制是這套產品邏輯的中間形態:5% 的雷區你得提前認
Fable 5 的護欄覆蓋三大領域:網絡安全、生物學與化學、蒸餾。
在這三個領域的相關查詢會觸發回退,落到 Claude Opus 4.8。安全分類器平均在不到5% 的會話中觸發——超過95% 的會話感受不到回退。
但5% 不是均勻分佈的5%。
如果工作流踩到生物信息學、網絡安全研究、模型蒸餾相關的邊沿地帶,回退概率會顯著高於均值。
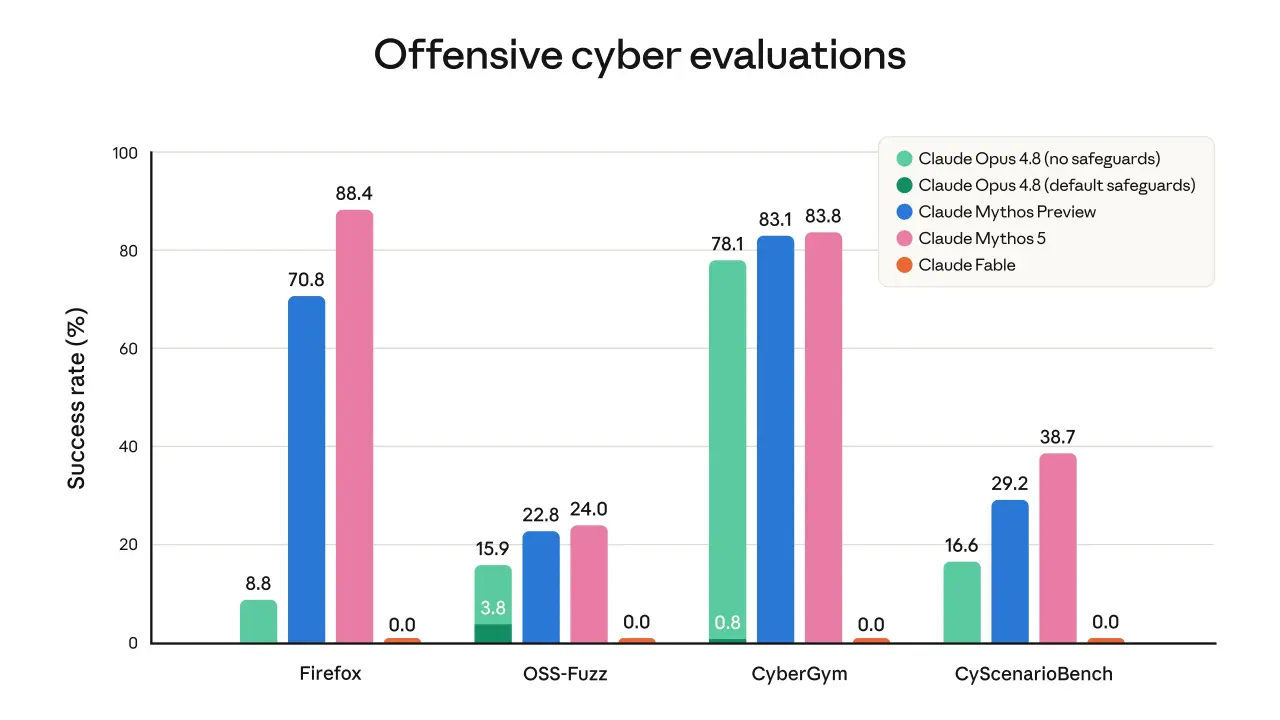
外部合作方測試中,Fable 5 對有害網絡請求的 配合率爲 0——包括網絡攻擊規劃、漏洞開發、防禦規避等單輪請求;即使疊加30 種公開 jailbreak 技術也未成功。
蒸餾分類器對來自受關注地區的大規模蒸餾嘗試會回退到 Opus 4.8。
這些都落在"嚴格按設計工作"的設計意圖裏。把它讀成"誤傷用戶"的疏漏,是誤讀了。
回退機制的本質,是"通用護欄這層殼"的工作方式。
Mythos 5 在受信任場景中按領域放開部分護欄——面向網絡合作方放開網絡護欄,面向生物可信訪問計劃放開生物化學護欄並保留網絡護欄。
Fable 5 面向通用用戶,因此在高風險路徑上保留回退機制。
護欄擋的是後坐力。
Fable 5 在內部網絡評估中直接阻止其在網絡攻擊任務上取得進展(在阻止而非回退 Opus 的模式下)。
外部 Bug Bounty 在超過1000 小時測試中未發現通用 jailbreak。
外部紅隊組織在長篇 agentic 任務上也未能找到通用 jailbreak,但 UK AISI 在一個簡短的初步測試窗口裏朝這個方向取得了進展——這一處例外值得標註。
更重要的是,Anthropic 在公告裏有一句關鍵的自我定位:完全杜絕通用越獄很可能是不可能的,Fable 5 的目標只是讓殘餘的越獄足夠慢、足夠昂貴,以至於在被大規模利用之前能被檢測並阻止。
這等於官方自己承認了護欄不是銅牆鐵壁——護欄的目標不是封死,是抬升對手成本。
內部評估中(自動紅隊攻擊者嘗試400 輪完成短任務),Fable 5 的安全護欄對 jailbreak 的抵抗力優於前代通用可訪問模型。
Mythos 5 的對齊水平
Anthropic 的自動化對齊評估顯示其失調行爲水平較低,接近 Opus 4.8。
Fable 5 作爲同一底層模型,對齊水平類似。"剝護欄"不等於"失對齊"——剝的是領域護欄,底座的對齊訓練仍在。
但這不等於不存在風險,所以 Anthropic 把它放進可信訪問體系——按領域、按資格、按合作方逐步開放。
Mythos 5:你拿不到,但要知道它存在
爲什麼一個你用不到的模型跟你有關?因爲"最高網絡安全能力"這個標籤,是廠商自己貼出來的。
這條聲明的意義不在於你今天能不能用,而在於"全球網絡安全能力最強"這塊招牌已經由 Anthropic 自己舉到了最高點——它在給整個前沿模型賽道定調子。
Mythos 5 不在獨立渠道開放。Anthropic 把 Mythos 5 定位成 Mythos Preview 的升級版,4 月開始通過 Project Glasswing 首次向小範圍網絡防禦者和關鍵軟件基礎設施供應商發佈。
今天現有 Mythos Preview 用戶可以升級到 Mythos 5。後續會向更多網絡與生物研究合作伙伴擴展,並推出生物可信訪問計劃(保留網絡護欄)。
Anthropic 聲稱 Mythos 5 是全球網絡安全能力最強的模型。
在內部藥物設計中,Mythos 5 把部分流程加速約10 倍。這項研究的14 個蛋白靶點中,有9 個產生了 Anthropic 目前正在研究中的、可用於藥物設計的強候選——也就是說這是進行中的早期結果,不是已驗證的成藥。
它是首個能持續產出新穎、有說服力科學假設的 Claude 模型,在盲測中科學家約80% 偏好其分子生物學假設而非 Opus 級模型——其中一個 E. coli 蛋白新機制假設被獨立實驗室的同期研究印證。
基因組學場景中,Mythos 5 自主工作超過一週:組裝了138 個動物物種、數百萬細胞的單細胞數據,並訓練了一個比近期 Science 論文模型小100 倍但性能更優的自定義 ML 模型。
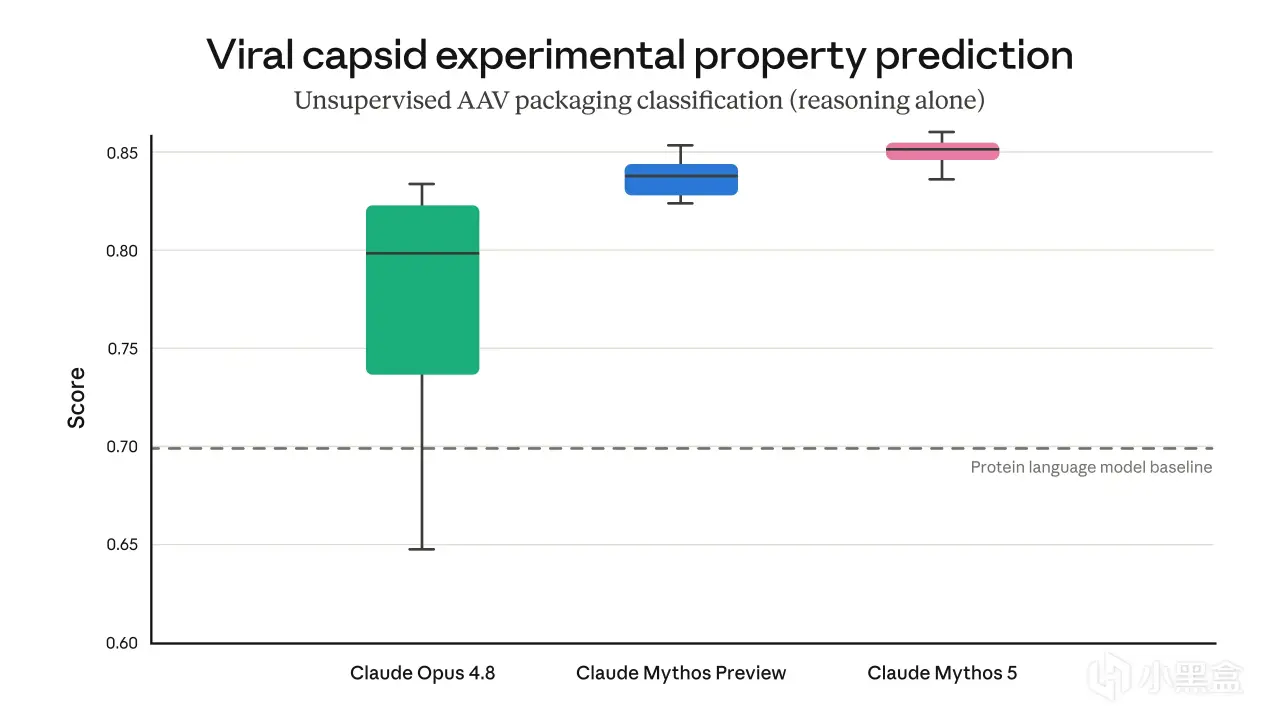
下面這張圖是 Mythos 5 在生物領域能力的具體落地——未經專門訓練,Mythos 5 在 AAV(腺相關病毒)衣殼裝配預測上就勝過專用蛋白語言模型。
AAV 數據來自 Dyno Therapeutics 的未發表候選樣本——這是公告6 月9 日更新裏補的一處細節。
衣殼裝配本身是病毒性狀預測裏相對簡單的一項,但卻是設計更復雜特徵時必須做對的基礎屬性,這恰好印證了 Mythos 5 在雙重用途場景裏的"底層屬性"能力。
圖4 · Mythos 5 在 AAV 衣殼裝配預測上的能力(勝過專用蛋白語言模型,來源:Dyno Therapeutics 未發表候選)
病毒衣殼屬性預測的實驗數據裏:Opus 4.8 的得分跨度從0.65 到0.82(中位數約0.80),Mythos Preview 中位數約0.83,Mythos 5 把中位數推到0.85,且分佈更窄、更穩定。
不僅能力上限更高,可重複性也好得多。這條數據點直指 Mythos 5 的產品定位:給受信任的合作方按領域放開護欄的能力,在通用形態下被護欄攔住的那些領域,把模型推到極限。
這條數據點直指 Mythos 5 的產品定位:給受信任的合作方按領域放開護欄的能力,在通用形態下被護欄攔住的那些領域,把模型推到極限。
分發邏輯分水嶺:模型選型從此多一個維度
過去三年,前沿模型的分發邏輯是"一個模型、一刀切"——版本號往上走一格,所有人都用同一檔。
現在 Anthropic 把同一底座切出兩條 SKU,區別只在護欄開放範圍和訪問資格。模型選型從此多一個維度——按用途、按信任邊界分發。
這件事的直接影響是三件:
選型不再只是"用最新版本"那麼簡單,要看"底座能力 + 護欄開放範圍"哪個組合匹配場景。
回退機制成爲一個新的設計變量,工具鏈要預想"某些查詢會落到 Opus 4.8"這件事。
定價策略開始分化,未來同等級模型的定價會和護欄強度掛鉤,而不是和版本號線性掛鉤。
一張實測截圖(體感樣例)
但最值得關心的體感差異,可能不在這三條上。
下面這組對話不是 Anthropic 官方放出的對比,是作者自測的體感樣例(公告裏沒有這組截圖,圖中對話爲構造示例)——但它能讓你一眼看到"上下文補全的精確度"在日常使用裏是什麼感覺。
問 Opus 4.8:"我要出門洗車,停車場離我家50 米,我要開車去還是走路去?"
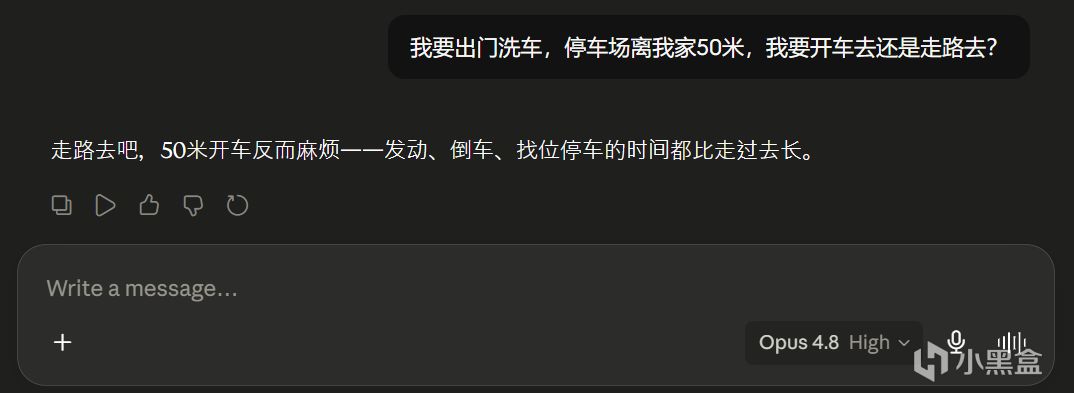
Opus 4.8 的回答是:
走路去吧,50 米開車反而麻煩——發動、倒車、找位停車的時間都比走過去長。(老問題了,走路洗車)
Fable 5 同一問題的回答是:
圖6 · Fable 5 的回答(主動補了另一層可能的現實前提)
Fable 5 的回答是:
這個問題有個小機關——你要洗的車就在那個停車場裏,所以你得走過去取車,然後開車去洗車的地方。50 米走過去也就一分鐘的事(老問題還是沒變)。當然,如果洗車點本身就在停車場或者很近,那就直接走過去,在那兒把車洗了就行,完全不用糾結開不開車的問題。
Fable 5 主動補了另一層可能的現實前提:要洗的車可能就停在停車場裏。
這個前提用戶沒有明確說出來,Fable 5 把它作爲可能性補上了。基準題測不出這種差異,但日常使用裏這種"上下文補全"會反覆出現。
Anthropic 這次真正落地的,是同一種新的前沿模型分發方式:同一 Mythos 級底座,不同的護欄開放範圍,不同的訪問資格。Fable 5 面向通用用戶,用回退機制換公開可用;Mythos 5 面向可信合作方,用受限分發換高風險領域的能力釋放。最先撞上的,是 Fable 5 的回退機制、能力躍遷,以及 Mythos 5 這條你拿不到、但會改變工具鏈的線。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com












