今天,Cursor 把 Composer 2.5 放出來了。

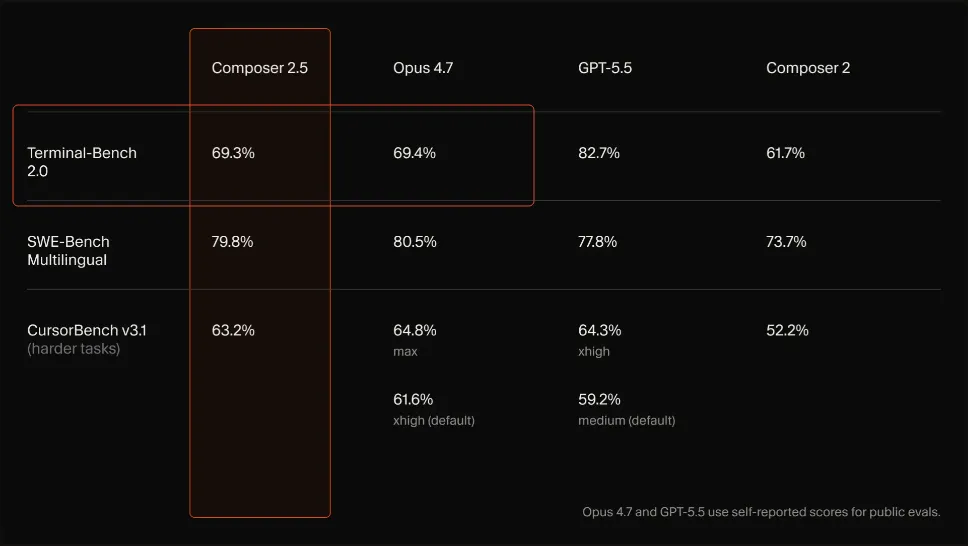
我第一眼注意到的是什麼——SWE-Bench Multilingual,79.8%。
和 Anthropic Opus 4.7 持平!
你敢信?
SWE-Bench 是把它丟進真實項目裏修 bug、讀上下文、改文件的測試,所以 79.8% 這個數字真正刺激人的地方,不只是高。
是它高得有點出乎意料。
Cursor 自己對 Composer 2.5 的定位很清晰,即能勝任長時間任務、更能遵循複雜指令、會協作的模型。

這個說法聽着有點產品稿味,但放到 coding agent 裏其實很關鍵,因爲我們現在用 Cursor、Claude Code、Codex,最煩的就是這些模型跑着跑着忘了目標,或者小修一下就端出一整套重構大禮包。
Composer 2.5 這次的改進,就是對着這個痛點來的。
更復雜的 RL 環境,合成任務數據比 Composer 2 多了 25 倍,以及他們還推出了 Targeted RL with Textual Feedback(利用文本反饋進行定向強化學習)。
這個改進你可以把它理解成,老師改卷子,不只是打對錯,還在你錯的地方寫了正確的解題思路,你作爲學生,就問你看了爽不爽?
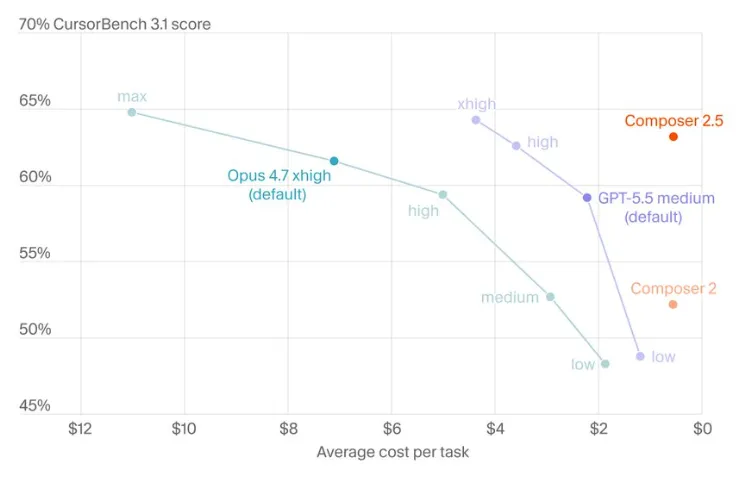
以前一個 agent 跑幾十萬 token,到頭來任務失敗了,獎勵模型只能說,兄弟你這把不行。
但具體是哪一步不行,是工具調錯了,還是風格跑偏了,它很難知道,Cursor 現在做的是,在出問題的局部上下文裏塞一條短反饋。
這就很像一個資深工程師帶新人。
但說到這裏,還有一點各位要知道:
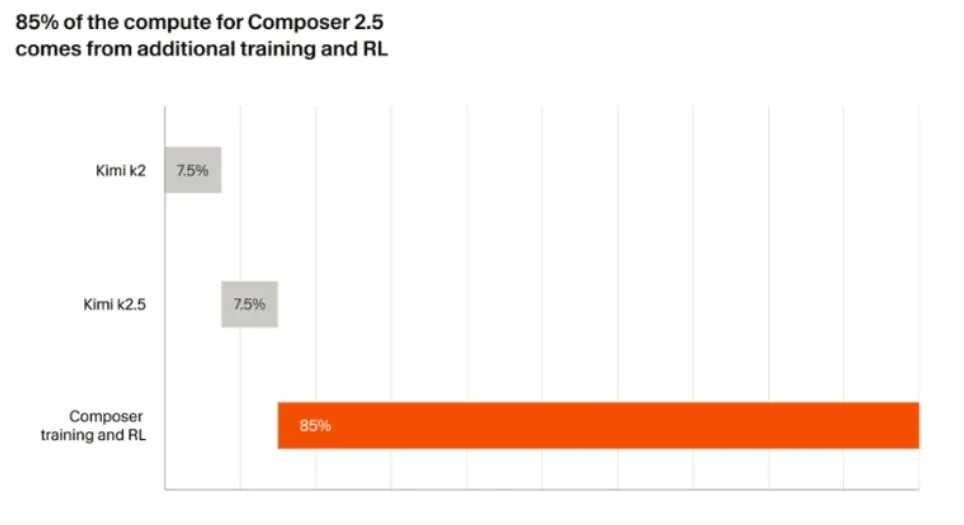
Composer 2.5 並不是 Cursor 從零煉出來的全新大模型。
它基於月之暗面的 Kimi K2.5 構建,Cursor 在這個底座上做了大量 post-training 和 RL,大約 85% 的計算資源花在自己主導的 RL 和後訓練階段。
這件事比單純吹自研更有意思。
現在做 coding model,不一定要從第一塊磚開始蓋樓,你大可以先拿一個足夠強、商業上能跑通的 base model,再把貼近場景的部分做到極致。
月之暗面提供 Kimi K2.5 這個強基座,Cursor 通過 Fireworks AI 做授權商業合作,然後把自己的產品場景和 RL 訓練能力壓上去。
可以說是集兩家之長。
btw,可能有朋友可能會問,不是 Kimi K2.6 已經出來了,爲什麼 Composer 2.5 不直接用 K2.6?
這個問題答案其實很簡單。
Kimi K2.6 正式發佈於上個月20號(4月20,我們當時還提前一週體驗到了 K2.6),就算 Cursor 比我們還早點,到今天算一算也才一個月多點,那時 Composer 2.5 的訓練大概率已經走到中後段了,你這時候換底座,真不是換個模型名字挪一點文件那麼簡單,大量 post-training 和穩定性驗證都要重跑。

另外,K2.5 已經被 Composer 2 跑過一輪真實用戶場景,穩定性、授權、推理成本都更確定,K2.6 確實更強,但不等於立刻能變成有效提升。
對了,Composer 2.5 的標準價格是每百萬輸入 token 0.50 美元,每百萬輸出 token 2.50 美元,用少得多的錢,買到和 Opus 4.7 差不多的性能,性價比是真的不錯。
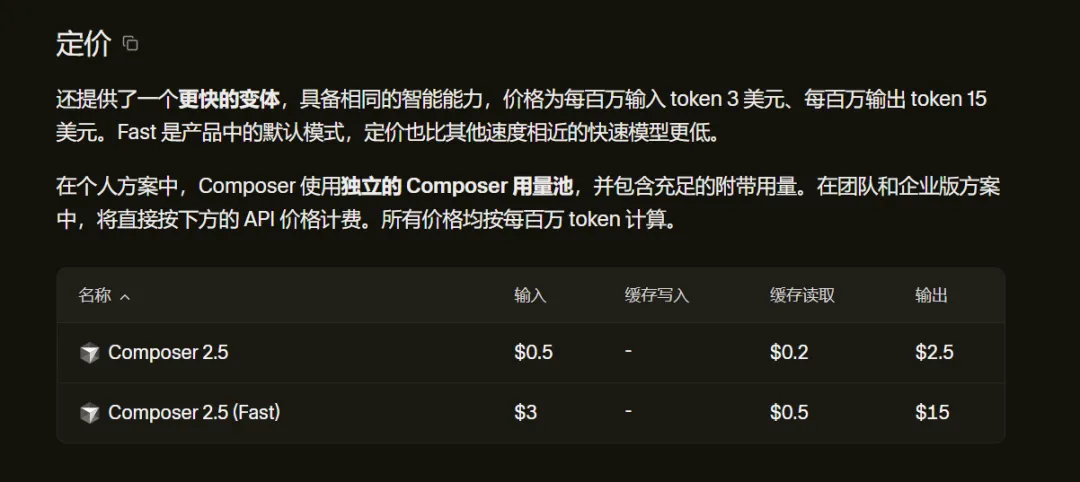
這個價格無論是放到哪裏,都是相當有競爭力的價格,不過目前 2.5 僅在 Cursor 中可供調用,不知道後續是否會開放。
便宜不只是便宜,便宜會改變人的使用習慣。
以前你可能會想,這個任務值不值得開 Opus,現在如果 Composer 2.5 能接近頂級模型,同時成本壓低一大截,開發者會更願意把它當默認勞動力。
說到底,Composer 2.5 最讓我興奮的,不只是它證明 Cursor 可以做出一個某些能力可以和 Opus 4.7 持平的模型,它還證明了一條很現實的路線:
拿強開放底座,疊深垂直場景,做狠後訓練,再用一個開發者真的能負擔得起的價格打出來。

真正的戰場,不止是性能,還有價格。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














