先说结论:
核心思想:
“大脑是用来思考的,不是用来记忆的,大模型同样如此。”
难点:
LLM 对话存在连锁崩溃——对话积累 → 上下文爆炸、Token 成本失控 → 暴力压缩丢失关键信息 → LLM 产生幻觉 → Session 切换 Agent 完全失忆 → 跨项目知识永不互通。现有 RAG、滑动窗口、上下文压缩方案全是被动兜底。
我解决了什么问题?
完美解决上下文爆炸问题 主 LLM 每轮只接收精炼上下文(节省 90% tokens),原始历史零注入,Token 消耗恒定不随会话增长
解决压缩失真问题 子代理主动蒸馏而非被动裁剪,关键信息不丢失
大幅降低 LLM 幻觉 干净上下文消除碎片信息,幻觉概率大幅下降
消除 Agent 失忆 跨 Session 有接力棒 essence.md,对话链持续不断
打破知识孤岛 全局记忆作用域跨项目共享知识
----------
AI越来越融入我们的生活了,现在无论做点什么,感觉完全离不开AI的帮助。
不管是游戏开发,还是日常对话、想要写点什么东西,如果没有AI辅助,感觉像是回到了原始社会一样。
但是,不知道你有没有跟我一样的痛苦时刻?
你打开 Cursor 或 Claude Code,新建了一个会话(Session)。
前 10 轮对话,AI 简直是你的灵魂伴侣。你和它详细对齐了项目架构、定好了特殊的 API 规范、交代了哪个第三方库有坑千万别用。
或者反复跟AI说一些基本的东西,它满口答应的好好的,但是过一会儿,又要强调一遍,反复拉扯。
我不是说了要....吗?
你要先...再...能不能记住??
能不能不要再...!???
....
相信诸如此类的对话,在开发过程中会经常出现。
新 Session 秒变陌生人:新开一个窗口,它完全忘了你是谁。你不得不花半小时把之前的技术背景、避坑指南重新复制粘贴一遍。
注意力稀释(Lost in the Middle):随着你们聊得越来越深,单次对话的上下文急剧膨胀。这时候你让它改个 bug,它开始睁眼说瞎话,因为真正关键的信息已经被淹没在中间几万字的调试日志里了。
连锁崩溃与幻觉大爆发:为了不让上下文超限,很多工具会暴力截断历史。这一截断,AI 直接把前天定好的“绝对不能用 WebSockets”的架构决策给“丢”了,又开始疯狂给你写 WebSockets 的 Bug 代码,答非所问,幻觉满天飞。
我们会遇到非常多的问题:
LLM 对话存在连锁崩溃——对话积累 → 上下文爆炸、Token 成本失控 → 暴力压缩丢失关键信息 → LLM 产生幻觉 → Session 切换 Agent 完全失忆 → 跨项目知识永不互通。
那么,有什么解决办法?
有的,市面上目前出现多非常多解决方案,github上相关的项目每天的⭐都在暴涨。
我也去尝试了,用了很多出名的方案。
但是,现有 RAG、滑动窗口、上下文压缩方案全是被动兜底。
滑动窗口/暴力裁剪:鞋挤脚了,不换鞋,直接把脚指头切掉。
普通向量 RAG:你问它 A 怎么写,它去数据库里搜了一堆包含“A”的代码碎片丢给 LLM。这就好比你问医生怎么治感冒,医生扔给你一吨感冒药说明书的碎片,说“你自己拼着看吧”。
MemGPT / Letta(虚拟内存):让主 LLM 在写代码的同时,还得自己分心去想“我该把哪段话存到外存,把哪段话取出来”。这就像让你一边高强度手撕红黑树,一边还得在脑子里做垃圾回收(GC),直接把 AI 宝贵的推理心智给榨干了。
我始终坚信一个观点:“大脑是用来思考的,不是用来记忆的。” 一个优秀的开发者在写代码时,脑子里装的应该是算法、逻辑和架构设计,而不是去死记硬背前天聊过的每一句废话。
为了把这个理念塞进 AI 的脑子里,我做过无数次尝试。我亲手搭建过向量数据库,写过复杂的检索算法,也试过各种奇奇怪怪的第三方记忆管理库……但无一例外,体验都非常糟糕。它们就像是一块块打在 AI 身上的“补丁”,臃肿、迟钝、充满人工雕琢的笨拙。
直到有一天,我碰到了 pi-coding-agent。
当我看到它那极其开放、允许深入生命周期的 TS 钩子、自定义工具和后台子进程管理机制时,我整个人直接激灵了一下:!!!!我坚信了这么久的理念,终于找到了能把它完美落地的终极土壤!
1995 年由 McClelland 等学者提出的互补学习系统理论(Complementary Learning Systems),是脑科学界公认的经典。
人脑之所以牛逼,是因为它把记忆和思考拆成了两套分工明确的系统:
海马体(Hippocampus):负责当下的情境体验。你今天早上吃了什么,刚才谁跟你说了句话,海马体“单次、快速”地记下来。但它容量很小,不适合存一辈子的知识。
大脑新皮层(Neocortex):负责长期的通用知识。它是通过海马体长期反复的 Consolidation(巩固)才把知识固化下来的。
最神奇的交接仪式发生在睡眠中。当你睡觉(离线状态)时,海马体会疯狂“快进重放”白天的经历,把有价值的、本质的经验提炼出来,悄悄写入你的大脑新皮层。
在工程实现上,GitHub 上的两个顶流项目给了我极大的启发:
Headroom(工具与日志的极致压缩):
chopratejas/headroom 证明了一件事:在工具输出、终端日志、文件内容等信息到达 LLM 之前,必须进行高比例的压缩过滤。AI 没必要读一万行一模一样的 npm 报错,它只需要知道“类型定义冲突了”这一行字。过滤无用噪声,能帮 Agent 节省 60% 到 95% 的 Token!Ralph(轻装上阵,单轮循环):
snarktank/ralph 提出了一个非常反常识的极客思想:不要让 AI 背负着历史包袱前行。每一次对话,都应该是纯净的。 它的内存不靠对话历史维持,而是靠状态文件和 Git。
将这些灵感结合在一起,我的思路彻底清晰了:主脑干干净净,只管思考;副脑离线整理,各司其职。
基于这个思路,我在 Pi 上用扩展机制开发了 Pi Memory System。我把 Agent 拆成了三个部分,就像一个高效运转的大脑:
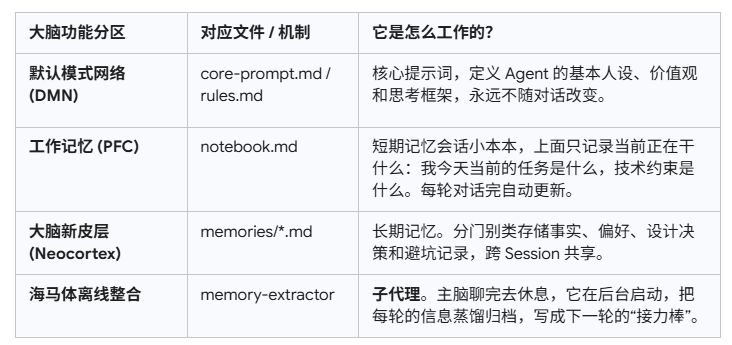
在这个系统里,主 LLM(负责写代码的大脑皮层)过得极其舒服。在面对用户时,它完全看不到任何原始历史聊天记录。
每轮对话发生时,

这样做,爽在哪里?
Token 账单呈“心电图级”平稳:因为我们在每轮主脑思考前,把所有历史对话全部 Wipe(擦除)掉了!主 LLM 看到的上下文永远只有几千 token。不管你们聊了 10 轮还是 100 轮,Token 消耗是扁平恒定的,直接帮你省下 90% 的费用!
完美的“接力棒”机制:下一次你新开会话,或者跨 Session 切换,新上岗的 Agent 只要接过 essence.md 这根接力棒,瞬间就能无缝继续上一次的工作。
不占用推理带宽:记忆的整理和归档全是在后台由另一个轻量级子代理悄悄完成的,主 LLM 写代码时根本不需要分心。
人脑对不同的记忆,把握程度是不一样的。比如:“我非常确定我锁门了” vs “我感觉我好像锁了”。
系统强制子代理在往长期记忆写东西时,必须标注置信度:
[confirmed]:已验证。比如代码编译通过了,或者用户明确点头了。
[inferred]:合理推断。根据上下文逻辑猜出来的。
[intuition]:直觉。无直接证据,但有潜在价值的直觉和设想。
如果项目做到后期,你突然决定把原定的 WebSockets 方案废弃,改成 Server-Sent Events (SSE) 怎么办?
传统的向量检索只懂得生硬地覆盖,或者干脆把旧代码删了。但这会导致 AI 失去“为什么改”的上下文。
我们引入了 supersede(取代)工具。当新决策产生时,它会在旧条目上打个标记,然后指向新条目:
<!-- memories/decisions/architecture.md -->
- [confirmed] 原定使用 WebSockets 进行实时通信。
- [confirmed] 鉴于客户端网络不稳定,架构切换为 Server-Sent Events (SSE) 配合 HTTP Polling 降级方案。
这样,AI 不仅记住了新决定,还看懂了“发现错误 ➡ 迭代进化”的思维轨迹,再也不会在同一个坑里摔倒两次。
记忆绝不是孤立的卡片,而是交织的网络。
子代理在写新记忆时,会主动用 [[文件名#章节]] 去链接已有的记忆文件(类似 Obsidian 的双向链接)。在搜索记忆(Recall)时,我们不玩死板的余弦相似度,而是基于内容指纹进行多样性打散(Diversity Ranking),极大地激活了 LLM 的“自由联想”,让 AI 举一反三。
在这个动不动就用向量数据库、Embedding 和各种云端 SaaS 的黑盒时代,我做了一个极其“复古”但极度舒适的选择:所有的记忆,全部以 Markdown 纯文本存储在本地。
~/.pi/agent/memory/projects/<name>/memories/
├── _index.md ← 自动生成的索引
├── facts.md ← 项目事实
├── preferences.md ← 你的偏好风格
├── decisions/ ← 你的决策
└── events/ ← 踩坑与调试记录
这样做,真的太爽了:
绝对透明,毫无黑盒:你随时可以用 VS Code 打开这些文件,像看自己笔记一样去读 AI 的脑回路。
人类拥有最高控制权:如果你觉得 AI 记错了,你可以直接动手改它的 Markdown;甚至你可以在里面手写一段对项目的期望,下一轮它立刻心领神会。
完美的 Git 版本控制:直接把 memories/ 丢进 Git 仓库。每一次 AI 脑子的进化、记忆的沉淀和修正,在 git log 里一清二楚!
想要了解更多更详细内容,可以直接点进这个仓库查看:
如果你也想体验这个超级爽的AI记忆系统,欢迎来 GitHub 点个 ⭐!
欢迎各路大神我们一起来优化迭代这个记忆系统!!
我的游戏《键来》6.24发售,欢迎游玩~
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















