先說結論:
核心思想:
“大腦是用來思考的,不是用來記憶的,大模型同樣如此。”
難點:
LLM 對話存在連鎖崩潰——對話積累 → 上下文爆炸、Token 成本失控 → 暴力壓縮丟失關鍵信息 → LLM 產生幻覺 → Session 切換 Agent 完全失憶 → 跨項目知識永不互通。現有 RAG、滑動窗口、上下文壓縮方案全是被動兜底。
我解決了什麼問題?
完美解決上下文爆炸問題 主 LLM 每輪只接收精煉上下文(節省 90% tokens),原始歷史零注入,Token 消耗恆定不隨會話增長
解決壓縮失真問題 子代理主動蒸餾而非被動裁剪,關鍵信息不丟失
大幅降低 LLM 幻覺 乾淨上下文消除碎片信息,幻覺概率大幅下降
消除 Agent 失憶 跨 Session 有接力棒 essence.md,對話鏈持續不斷
打破知識孤島 全局記憶作用域跨項目共享知識
----------
AI越來越融入我們的生活了,現在無論做點什麼,感覺完全離不開AI的幫助。
不管是遊戲開發,還是日常對話、想要寫點什麼東西,如果沒有AI輔助,感覺像是回到了原始社會一樣。
但是,不知道你有沒有跟我一樣的痛苦時刻?
你打開 Cursor 或 Claude Code,新建了一個會話(Session)。
前 10 輪對話,AI 簡直是你的靈魂伴侶。你和它詳細對齊了項目架構、定好了特殊的 API 規範、交代了哪個第三方庫有坑千萬別用。
或者反覆跟AI說一些基本的東西,它滿口答應的好好的,但是過一會兒,又要強調一遍,反覆拉扯。
我不是說了要....嗎?
你要先...再...能不能記住??
能不能不要再...!???
....
相信諸如此類的對話,在開發過程中會經常出現。
新 Session 秒變陌生人:新開一個窗口,它完全忘了你是誰。你不得不花半小時把之前的技術背景、避坑指南重新複製粘貼一遍。
注意力稀釋(Lost in the Middle):隨着你們聊得越來越深,單次對話的上下文急劇膨脹。這時候你讓它改個 bug,它開始睜眼說瞎話,因爲真正關鍵的信息已經被淹沒在中間幾萬字的調試日誌裏了。
連鎖崩潰與幻覺大爆發:爲了不讓上下文超限,很多工具會暴力截斷歷史。這一截斷,AI 直接把前天定好的“絕對不能用 WebSockets”的架構決策給“丟”了,又開始瘋狂給你寫 WebSockets 的 Bug 代碼,答非所問,幻覺滿天飛。
我們會遇到非常多的問題:
LLM 對話存在連鎖崩潰——對話積累 → 上下文爆炸、Token 成本失控 → 暴力壓縮丟失關鍵信息 → LLM 產生幻覺 → Session 切換 Agent 完全失憶 → 跨項目知識永不互通。
那麼,有什麼解決辦法?
有的,市面上目前出現多非常多解決方案,github上相關的項目每天的⭐都在暴漲。
我也去嘗試了,用了很多出名的方案。
但是,現有 RAG、滑動窗口、上下文壓縮方案全是被動兜底。
滑動窗口/暴力裁剪:鞋擠腳了,不換鞋,直接把腳指頭切掉。
普通向量 RAG:你問它 A 怎麼寫,它去數據庫裏搜了一堆包含“A”的代碼碎片丟給 LLM。這就好比你問醫生怎麼治感冒,醫生扔給你一噸感冒藥說明書的碎片,說“你自己拼着看吧”。
MemGPT / Letta(虛擬內存):讓主 LLM 在寫代碼的同時,還得自己分心去想“我該把哪段話存到外存,把哪段話取出來”。這就像讓你一邊高強度手撕紅黑樹,一邊還得在腦子裏做垃圾回收(GC),直接把 AI 寶貴的推理心智給榨乾了。
我始終堅信一個觀點:“大腦是用來思考的,不是用來記憶的。” 一個優秀的開發者在寫代碼時,腦子裏裝的應該是算法、邏輯和架構設計,而不是去死記硬背前天聊過的每一句廢話。
爲了把這個理念塞進 AI 的腦子裏,我做過無數次嘗試。我親手搭建過向量數據庫,寫過複雜的檢索算法,也試過各種奇奇怪怪的第三方記憶管理庫……但無一例外,體驗都非常糟糕。它們就像是一塊塊打在 AI 身上的“補丁”,臃腫、遲鈍、充滿人工雕琢的笨拙。
直到有一天,我碰到了 pi-coding-agent。
當我看到它那極其開放、允許深入生命週期的 TS 鉤子、自定義工具和後臺子進程管理機制時,我整個人直接激靈了一下:!!!!我堅信了這麼久的理念,終於找到了能把它完美落地的終極土壤!
1995 年由 McClelland 等學者提出的互補學習系統理論(Complementary Learning Systems),是腦科學界公認的經典。
人腦之所以牛逼,是因爲它把記憶和思考拆成了兩套分工明確的系統:
海馬體(Hippocampus):負責當下的情境體驗。你今天早上喫了什麼,剛纔誰跟你說了句話,海馬體“單次、快速”地記下來。但它容量很小,不適合存一輩子的知識。
大腦新皮層(Neocortex):負責長期的通用知識。它是通過海馬體長期反覆的 Consolidation(鞏固)才把知識固化下來的。
最神奇的交接儀式發生在睡眠中。當你睡覺(離線狀態)時,海馬體會瘋狂“快進重放”白天的經歷,把有價值的、本質的經驗提煉出來,悄悄寫入你的大腦新皮層。
在工程實現上,GitHub 上的兩個頂流項目給了我極大的啓發:
Headroom(工具與日誌的極致壓縮):
chopratejas/headroom 證明了一件事:在工具輸出、終端日誌、文件內容等信息到達 LLM 之前,必須進行高比例的壓縮過濾。AI 沒必要讀一萬行一模一樣的 npm 報錯,它只需要知道“類型定義衝突了”這一行字。過濾無用噪聲,能幫 Agent 節省 60% 到 95% 的 Token!Ralph(輕裝上陣,單輪循環):
snarktank/ralph 提出了一個非常反常識的極客思想:不要讓 AI 揹負着歷史包袱前行。每一次對話,都應該是純淨的。 它的內存不靠對話歷史維持,而是靠狀態文件和 Git。
將這些靈感結合在一起,我的思路徹底清晰了:主腦幹乾淨淨,只管思考;副腦離線整理,各司其職。
基於這個思路,我在 Pi 上用擴展機制開發了 Pi Memory System。我把 Agent 拆成了三個部分,就像一個高效運轉的大腦:
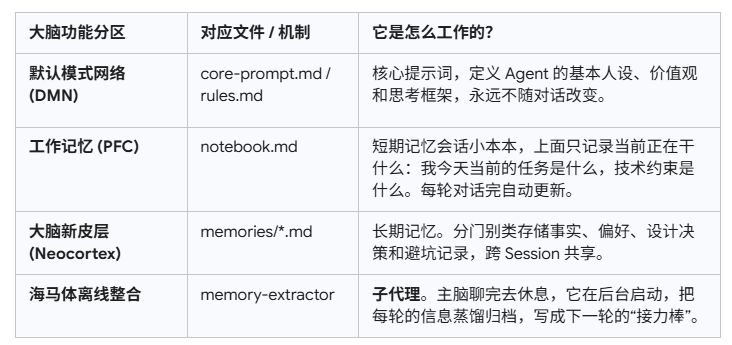
在這個系統裏,主 LLM(負責寫代碼的大腦皮層)過得極其舒服。在面對用戶時,它完全看不到任何原始歷史聊天記錄。
每輪對話發生時,

這樣做,爽在哪裏?
Token 賬單呈“心電圖級”平穩:因爲我們在每輪主腦思考前,把所有歷史對話全部 Wipe(擦除)掉了!主 LLM 看到的上下文永遠只有幾千 token。不管你們聊了 10 輪還是 100 輪,Token 消耗是扁平恆定的,直接幫你省下 90% 的費用!
完美的“接力棒”機制:下一次你新開會話,或者跨 Session 切換,新上崗的 Agent 只要接過 essence.md 這根接力棒,瞬間就能無縫繼續上一次的工作。
不佔用推理帶寬:記憶的整理和歸檔全是在後臺由另一個輕量級子代理悄悄完成的,主 LLM 寫代碼時根本不需要分心。
人腦對不同的記憶,把握程度是不一樣的。比如:“我非常確定我鎖門了” vs “我感覺我好像鎖了”。
系統強制子代理在往長期記憶寫東西時,必須標註置信度:
[confirmed]:已驗證。比如代碼編譯通過了,或者用戶明確點頭了。
[inferred]:合理推斷。根據上下文邏輯猜出來的。
[intuition]:直覺。無直接證據,但有潛在價值的直覺和設想。
如果項目做到後期,你突然決定把原定的 WebSockets 方案廢棄,改成 Server-Sent Events (SSE) 怎麼辦?
傳統的向量檢索只懂得生硬地覆蓋,或者乾脆把舊代碼刪了。但這會導致 AI 失去“爲什麼改”的上下文。
我們引入了 supersede(取代)工具。當新決策產生時,它會在舊條目上打個標記,然後指向新條目:
<!-- memories/decisions/architecture.md -->
- [confirmed] 原定使用 WebSockets 進行實時通信。
- [confirmed] 鑑於客戶端網絡不穩定,架構切換爲 Server-Sent Events (SSE) 配合 HTTP Polling 降級方案。
這樣,AI 不僅記住了新決定,還看懂了“發現錯誤 ➡ 迭代進化”的思維軌跡,再也不會在同一個坑裏摔倒兩次。
記憶絕不是孤立的卡片,而是交織的網絡。
子代理在寫新記憶時,會主動用 [[文件名#章節]] 去鏈接已有的記憶文件(類似 Obsidian 的雙向鏈接)。在搜索記憶(Recall)時,我們不玩死板的餘弦相似度,而是基於內容指紋進行多樣性打散(Diversity Ranking),極大地激活了 LLM 的“自由聯想”,讓 AI 舉一反三。
在這個動不動就用向量數據庫、Embedding 和各種雲端 SaaS 的黑盒時代,我做了一個極其“復古”但極度舒適的選擇:所有的記憶,全部以 Markdown 純文本存儲在本地。
~/.pi/agent/memory/projects/<name>/memories/
├── _index.md ← 自動生成的索引
├── facts.md ← 項目事實
├── preferences.md ← 你的偏好風格
├── decisions/ ← 你的決策
└── events/ ← 踩坑與調試記錄
這樣做,真的太爽了:
絕對透明,毫無黑盒:你隨時可以用 VS Code 打開這些文件,像看自己筆記一樣去讀 AI 的腦回路。
人類擁有最高控制權:如果你覺得 AI 記錯了,你可以直接動手改它的 Markdown;甚至你可以在裏面手寫一段對項目的期望,下一輪它立刻心領神會。
完美的 Git 版本控制:直接把 memories/ 丟進 Git 倉庫。每一次 AI 腦子的進化、記憶的沉澱和修正,在 git log 裏一清二楚!
想要了解更多更詳細內容,可以直接點進這個倉庫查看:
如果你也想體驗這個超級爽的AI記憶系統,歡迎來 GitHub 點個 ⭐!
歡迎各路大神我們一起來優化迭代這個記憶系統!!
我的遊戲《鍵來》6.24發售,歡迎遊玩~
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














