昨日,智谱联合华为,发布并开源了其全新一代图像生成模型 GLM-Image。
该模型拿下了多个 SOTA。
同时,GLM-Image 是目前首个在国产芯片上完成全流程训练的多模态 SOTA 开源图像生成模型,并且需要强调的是,其国产并非“部分国产”或“调优在国产”,是从训练到收敛,全流程跑在昇腾 Atlas 800T A2 上。

光这一点,就已经足够在国产AI史上写一段注脚了。
过去几年,图像生成领域的主流模型,几乎默认绑定了某几种国外 GPU 和软件栈。
你可以在上面做应用、做微调、做封装,但底层训练这一步,很少有人真的敢另起炉灶。
但这次 GLM-Image 从算力、框架、调度、优化,都用国产的。
行业中使用国产的东西并不算稀奇,但把它们凑到一起,稳定训练出一个能打的多模态模型,这事儿难度一点都不低。
架构方面,GLM-Image 采用的是自回归 + 扩散解码器的混合架构,简单说就是:文本理解和图像生成不是各干各的,而是被放进同一套系统里联合建模,这块跟咕噜咕噜的香蕉Pro思路是差不多的。
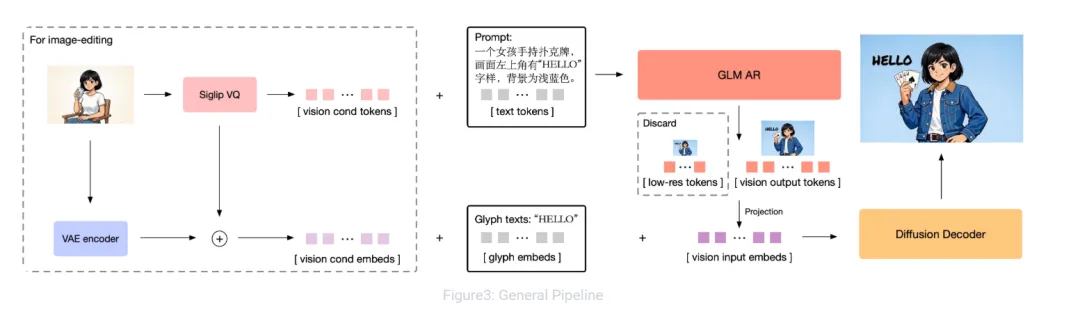
这也是它能在文字渲染榜单上做到开源 SOTA的关键原因之一。
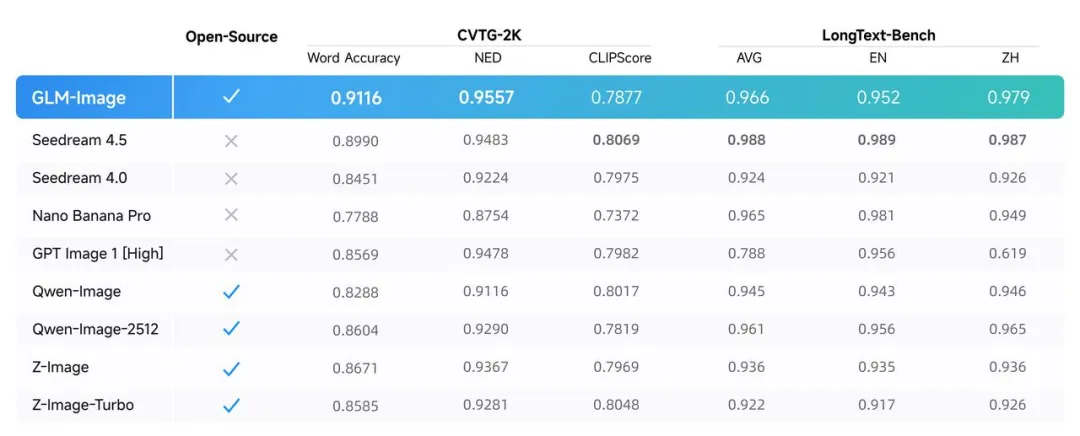

我们也对模型进行了一定的实测,专门对其这方面的能力进行了测试。
高密度文字、复杂排版、标题 + 副标题 + 小字说明这种,最生图模型容易翻车的场景。
结果怎么说呢?
确实强。
在大多数测试样例里,文字的结构、位置、可读性都没什么大问题,哪怕字数一多,也没有明显“糊成一坨”的情况。这一点放在开源模型里,已经是相当靠前的水准了。

当然,也并非完全无懈可击,有时候遇到复杂的字体渲染,还是能看到错误,但考虑到其是目前开源最强水平(因为能比过它的就只有少数闭源模型),那么一切也变得可理解和可接受了。

但如果你把目光从“图文生成”挪开,放到人像、写实、光影这些方向,GLM-Image 就会显得有点落后了。
不是说它画不出来人,但你一眼看上去,你就知道这和当前最主流那一档模型,并不在同一个审美世代,希望用这个模型来生人像图的朋友们可能得拉低心理预期了。
肤质、光影过渡、整体空间感,个人这边实测的结果确实有点不尽人意(json和普通的Prompt我都测试过)。
跟现在那些已经卷到摄影级质感的产品相比,差距还是挺明显的。

GLM-Image 也确实没有把第一目标放在跟谁正面对卷写实摄影,而是更偏向可控生成、文字准确、可规模化部署这些偏工程、偏应用层的指标。
你再结合它的价格看,就更合理了。
官方给出的定价是:0.1 元 / 次
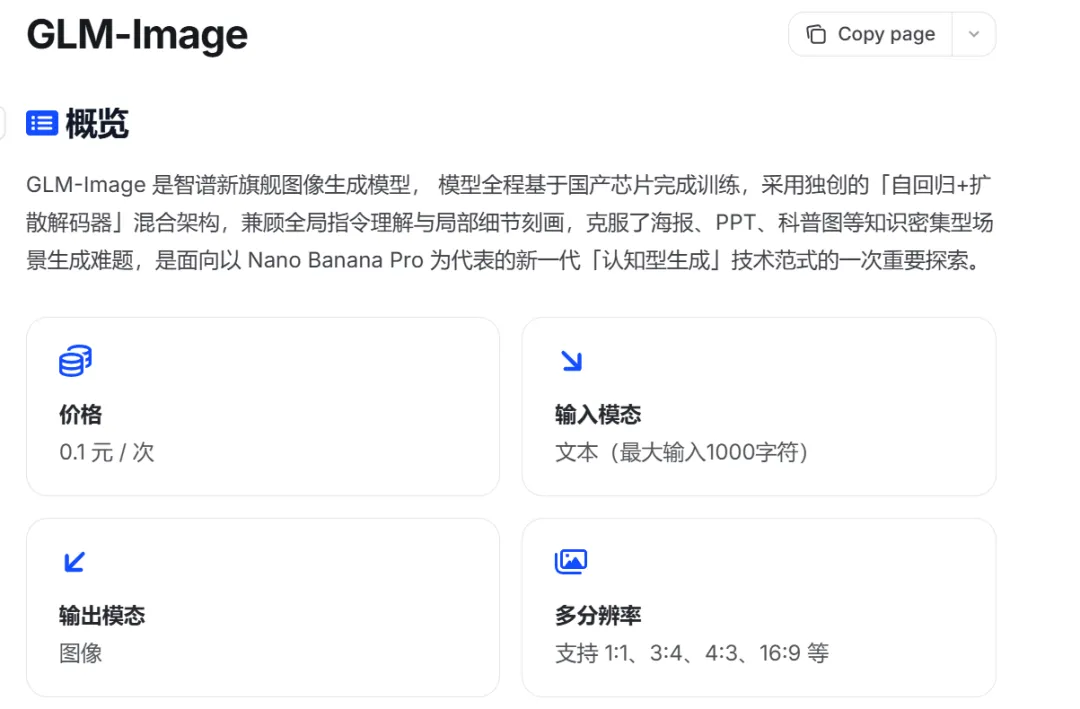
这个数字放在今天的图像生成市场里,几乎属于随便用不心疼的级别。
再考虑到它是开源模型,未来无论是私有化部署,还是针对行业场景做定制化优化,空间都非常大。
所以回头再看 GLM-Image 这件事,重点其实不只是效果好不好。
而是它证明了一件更底层的事情:
在国产芯片 + 国产框架的组合下,我们已经能把一个多模态图像模型,从训练、优化到上线,完整跑通,而且最终效果也是很不错的。
这一步,比任何一张“特别好看”的样图都重要。
最后,还是一句比较老派、但真心的话。
GLM-Image 可能还不完美,甚至在某些方向上显得有点保守,但它已经把一条以前没人敢走的路,踩实了。
接下来怎么卷、怎么进化、怎么被更多人用起来,那是后话。
至少现在,这一步,值得祝福。
我是 CyberImmortal,关注我们,带你畅游AI世界!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















