昨日,智譜聯合華爲,發佈並開源了其全新一代圖像生成模型 GLM-Image。
該模型拿下了多個 SOTA。
同時,GLM-Image 是目前首個在國產芯片上完成全流程訓練的多模態 SOTA 開源圖像生成模型,並且需要強調的是,其國產並非“部分國產”或“調優在國產”,是從訓練到收斂,全流程跑在昇騰 Atlas 800T A2 上。

光這一點,就已經足夠在國產AI史上寫一段註腳了。
過去幾年,圖像生成領域的主流模型,幾乎默認綁定了某幾種國外 GPU 和軟件棧。
你可以在上面做應用、做微調、做封裝,但底層訓練這一步,很少有人真的敢另起爐竈。
但這次 GLM-Image 從算力、框架、調度、優化,都用國產的。
行業中使用國產的東西並不算稀奇,但把它們湊到一起,穩定訓練出一個能打的多模態模型,這事兒難度一點都不低。
架構方面,GLM-Image 採用的是自迴歸 + 擴散解碼器的混合架構,簡單說就是:文本理解和圖像生成不是各幹各的,而是被放進同一套系統裏聯合建模,這塊跟咕嚕咕嚕的香蕉Pro思路是差不多的。
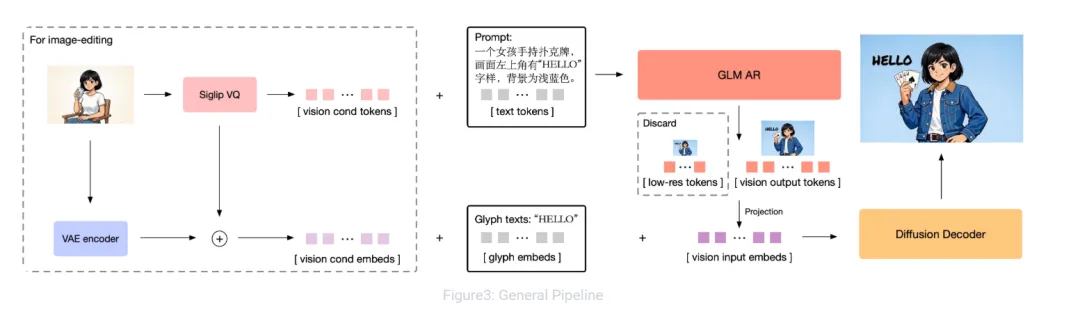
這也是它能在文字渲染榜單上做到開源 SOTA的關鍵原因之一。
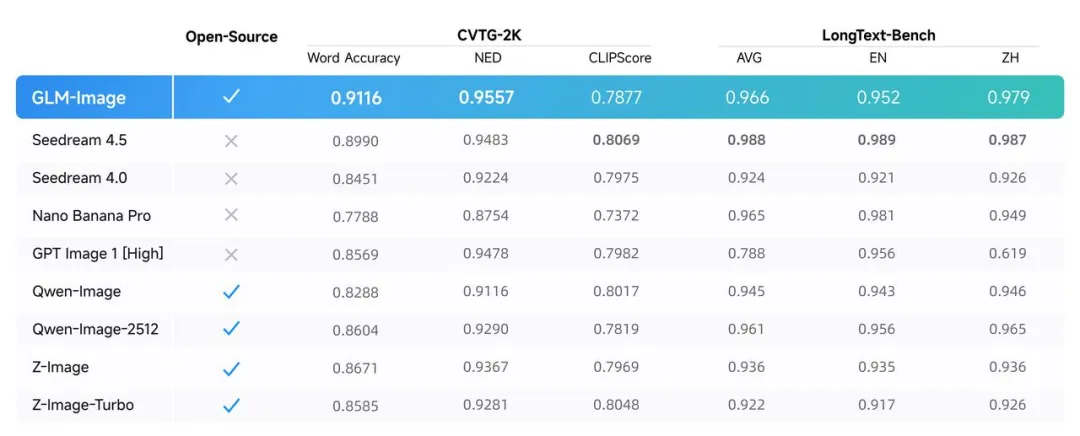

我們也對模型進行了一定的實測,專門對其這方面的能力進行了測試。
高密度文字、複雜排版、標題 + 副標題 + 小字說明這種,最生圖模型容易翻車的場景。
結果怎麼說呢?
確實強。
在大多數測試樣例裏,文字的結構、位置、可讀性都沒什麼大問題,哪怕字數一多,也沒有明顯“糊成一坨”的情況。這一點放在開源模型裏,已經是相當靠前的水準了。

當然,也並非完全無懈可擊,有時候遇到複雜的字體渲染,還是能看到錯誤,但考慮到其是目前開源最強水平(因爲能比過它的就只有少數閉源模型),那麼一切也變得可理解和可接受了。

但如果你把目光從“圖文生成”挪開,放到人像、寫實、光影這些方向,GLM-Image 就會顯得有點落後了。
不是說它畫不出來人,但你一眼看上去,你就知道這和當前最主流那一檔模型,並不在同一個審美世代,希望用這個模型來生人像圖的朋友們可能得拉低心理預期了。
膚質、光影過渡、整體空間感,個人這邊實測的結果確實有點不盡人意(json和普通的Prompt我都測試過)。
跟現在那些已經卷到攝影級質感的產品相比,差距還是挺明顯的。

GLM-Image 也確實沒有把第一目標放在跟誰正面對卷寫實攝影,而是更偏向可控生成、文字準確、可規模化部署這些偏工程、偏應用層的指標。
你再結合它的價格看,就更合理了。
官方給出的定價是:0.1 元 / 次
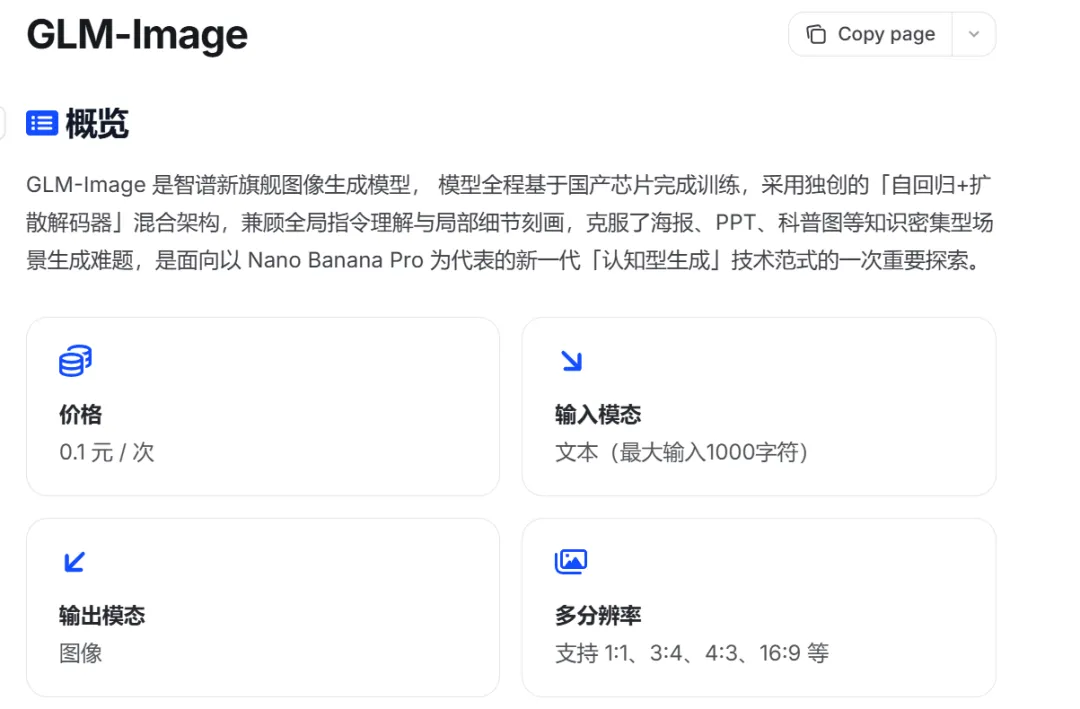
這個數字放在今天的圖像生成市場裏,幾乎屬於隨便用不心疼的級別。
再考慮到它是開源模型,未來無論是私有化部署,還是針對行業場景做定製化優化,空間都非常大。
所以回頭再看 GLM-Image 這件事,重點其實不只是效果好不好。
而是它證明了一件更底層的事情:
在國產芯片 + 國產框架的組合下,我們已經能把一個多模態圖像模型,從訓練、優化到上線,完整跑通,而且最終效果也是很不錯的。
這一步,比任何一張“特別好看”的樣圖都重要。
最後,還是一句比較老派、但真心的話。
GLM-Image 可能還不完美,甚至在某些方向上顯得有點保守,但它已經把一條以前沒人敢走的路,踩實了。
接下來怎麼卷、怎麼進化、怎麼被更多人用起來,那是後話。
至少現在,這一步,值得祝福。
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















