還記得幾個月前,當咕嚕咕嚕的香蕉模型及其Pro系列橫空出世時,整個 AI 圈子是個什麼反應嗎?
先不說咕嚕咕嚕那邊有多火爆,OpenAI 這邊的流量反正是低了不少,要不是還有個 Sora2 (文-圖生視頻模型)撐場子,否則大家還真以爲 OpenAI 要 Close大吉了。
那時候的 Sora (注意我說的是生成圖像的Sora)在圖像生成方面雖然還能打,但在生成速度、尤其是那令人抓狂的不可控性面前,確實顯得有點老態龍鍾。
特別是商業落地方面,Sora 和 DALL (opai的另一個生圖模型)系列則更是被咕嚕咕嚕的香蕉系列打得滿地找牙。

但在沉寂了這麼久之後,OpenAI 昨天夜裏終於搞了點大動作。
直接發佈 GPT-Image-1.5,並且立刻在 ChatGPT 裏全量推送。
我看了一圈官方的技術文檔和演示案例,腦子裏只有一個想法:這哪是發佈新模型,這分明是 OpenAI 被谷歌逼急了,直接把壓箱底的核武器給搬出來了。

這次更新最核心的關鍵詞,其實就兩個字:聽話。
以前我們用 Sora(或者說很多的一些生圖模型) 的 AI 生圖,本質上是在玩“抽卡遊戲”。
你輸入一段咒語,AI 給你吐出來幾張圖,好不好看能不能用全看運氣。
如果你覺得其中一張圖構圖不錯,但想把主角穿的紅衣服換成藍衣服,在過去的曾經,這幾乎是個不可能完成的任務,不過隨着模型一代又一代的進步,這個問題正在逐漸被解決,不過各家水平也是參差不齊。
因爲一旦你修改提示詞重新生成,AI 會重新計算整個畫面,光影、姿態、背景細節等這些要素中至少有一項很有可能會發生變化,前一秒還是寫實風,後一秒可能就變成了油畫風。
但 GPT-Image-1.5 這次帶來的“精確編輯”功能,終結了opai家的“抽卡時代”。
咱們來看官方的演示案例。




這組圖簡直是把“可控性”這三個字寫在了臉上。
以前的模型不懂什麼是“局部”,它只知道“重畫”,一旦重畫,便幾乎可預知的是一場災難。
但 GPT-Image-1.5 居然這次真的做到了,它像是一個精通圖層的頂級修圖師,精準地鎖定了畫面中的特定像素區域進行重繪,同時完美地保留了原本的光影邏輯。當那隻狗從真狗變成毛絨玩具時,它腳下的陰影、身上的反光,竟然還能跟周圍那個真實的寫實環境完美融合。
這就非常有意思了。
這意味着 ChatGPT 裏的圖片不再是一次性的“快餐”,而變得可以反覆打磨、修改。
你可以先生成一個滿意的構圖,然後像甲方指點江山一樣,指着畫面說:這裏給我加一堆亂跑的孩子,那裏給我換成電影海報的字體,主角的衣服給我換成 OpenAI 的文化衫。
模型不僅能聽懂,而且執行得嚴絲合縫。
這就引出了這次更新的另一個大殺器:文字渲染能力。
在很長一段時間裏,讓 AI 畫圖裏帶字,簡直就是災難現場。它生成的文字通常是亂碼,或者看起來像火星文。
但這次 OpenAI 展示了一個極其硬核的案例:讓 AI 生成一張豎構圖的報紙,並且要把一段複雜的 Markdown 格式文本,以自然的報紙排版填進去。結果怎麼樣?它不僅把文字一個不錯地寫了上去,甚至還處理好了標題的字號、正文的縮進,以及報紙特有的那種陳舊紙張質感。


但在吹了這麼多之後,咱們還是得回到現實。官方的演示視頻向來都是“賣家秀”,實際到手到底幾斤幾兩,還得咱們實測了纔算數。
於是我們上手試了試。
我們測試了之前一次寫關於餓了麼的文章的配圖生成👇。
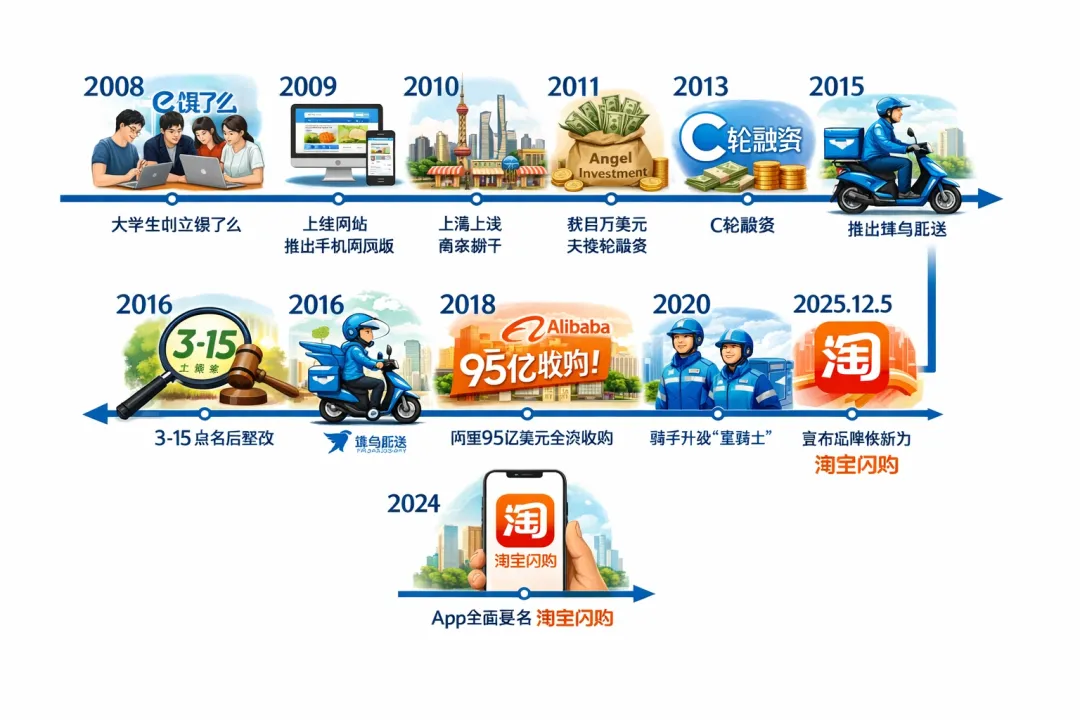
一言難盡啊,文字方面幾乎是不可用的......
香蕉Pro生成的👇
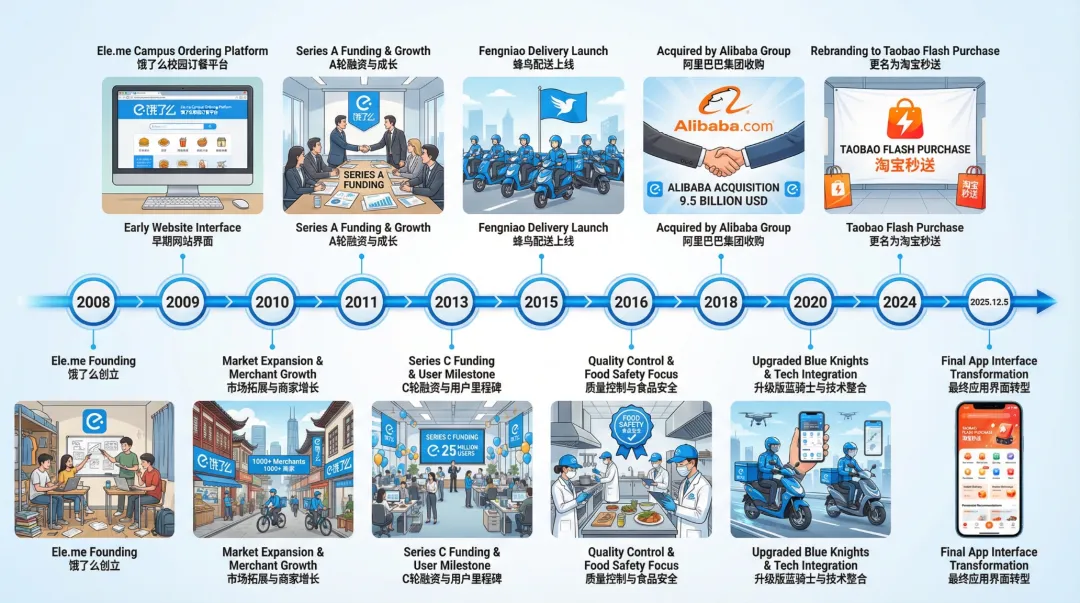
這就很有意思了。
既然它在海報排版上還是個“偏科生”,OpenAI 爲什麼還要這麼急吼吼地把 GPT-Image-1.5 掏出來?甚至爲了它,把生成速度硬生生提了 4 倍 ?
這背後的商業野心和焦慮,隔着屏幕都能聞得到。
之前咕嚕咕嚕的香蕉之所以能搶佔市場,靠的就是更強的編輯靈活性和更低的試錯成本。
OpenAI 這次不僅把性能提上來了,還反手打了一張價格牌:API 價格直接降了 20%。這明顯就是衝着開發者去的,尤其是那些做電商海報、做自動化設計的公司。
這對於像 Adobe 這樣的傳統軟件巨頭,或者靠賣素材過日子的圖庫網站來說,無疑是一次不小的打擊。
當修改圖片不再需要套索工具、不再需要蒙版,甚至不再需要理解什麼是圖層,只需要一句人話的時候,圖形設計的門檻就被徹底踏平了。
不過,這裏面也有個細思極恐的細節。
當 AI 開始能夠完美地“局部篡改”現實,且不留痕跡時,我們眼見爲實的底線又被拉低了一寸。
以前的 AI 假圖因爲細節崩壞還容易辨認,現在的 1.5 版本,能讓你在保持環境光影絕對真實的前提下,憑空讓一個人從照片裏消失,或者給一個人穿上他從未穿過的衣服,亦或者學會了“模擬真實缺陷”,讓你難以分辨。

這種級別的“真實感欺騙”,在社交媒體引發的混亂,早就開始了,而GPT-Image-1.5 的入局,恐怕會讓本就混亂的情況再添一把火。
最後,咱們來做個總結。
對於咱們普通用戶來說,GPT-Image-1.5 的出現無疑是個好消息。這意味着你口袋裏從此多了一個隨叫隨到、還聽得懂人話的頂級修圖師 。
但對於那些還在靠“摳圖”、“換底”、“去水印”賺辛苦錢的基礎美工來說,寒冬可能真的要來了。
還沒有失業的產品圖文字海報圖等設計師也別急着笑,等能幾乎完美處理文字且兼顧藝術性的模型出來,恐怕飯碗也難受保障了。

這技術進步的每一步,都在殘酷地擠壓着傳統重複性技能的生存空間。
我們唯一能做的,似乎只有哪怕是被動地,也得學會如何更好地向這些機器發號施令。
畢竟,那個只會瞎畫的傻 AI 已經畢業了,現在站在你面前的,是一個精明、高效、廉價,而且還不知疲倦的超級乙方。
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com













