前言:國內百度“文心一言”的發佈正式拉開了國內AI的帷幕。大家驚奇的的發現AI的能力實在是強大了:聊天打屁、看病問藥無所不能。但是被人忽略的是AI背後大量數據的培養的根基,鮮有人討論。開發商秉承着不盈利就沒事的態度一直的培養着AI!

對比可能有點不合適,還記得DC裏面的正義的超人和《黑袍糾察隊》裏面的祖國人嗎?這兩個人都是能力超強,但是結果確是截然相反。
超人正義大方豁達,祖國人自私高傲。原因是什麼大家應該也都知道,就是培養的過程問題。超人的父母給了超人足夠好的教育,祖國人確是直接被散養。長大了反而更加渴望母愛。


回到AI,AI的培養除了計算機的大量算力以外就是需要大量數據的澆灌。畢竟AI也不能憑空生成,AI繪畫也是同理。AI依靠許多畫家的數據投餵才能穩定生成值得一看的圖片,現在的聊天AI也是如此。
從零到一的跨越是一道巨大的鴻溝,跨越以後就會變得非常簡單。這也是爲什麼之前AI的雛形一經發布然後就遍地開花的原因。

如果用不正常的數據來投餵AI呢?國內的文心一言則是給了一個很好的例子。文心一言那些驚爲天人的回答。

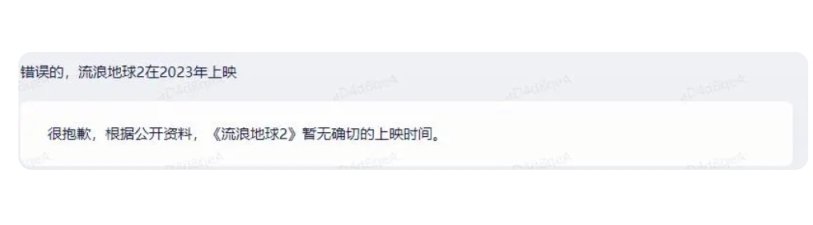
一個問題每次詢問都會有不同的結果,不只是百度的文心一言。國外的ChatGPT也面臨同樣的問題,同樣的1+1或者是3+2和2+3都會有不同的答案。
今天微博也有大V指出了這個問題,ChatGPT貌似會自己編造信息來源。

chatgpt可以一本正經地編造信息,但是對於普通人來說到底該不該相信呢?AI投餵數據的侷限性和錯誤性會導致chatgpt回答出錯誤的答案,嚴重的甚至可以自己編造來源。

這對於普通人分辨信息真假真是太困難了,即使是專業人員也有可能中招。chatgpt有時候給人的感覺就是一本正經的說瞎話,如果是你正好擅長的領悟還可以鑑別。但是如果你是門外漢的話,那你就只能聽之信之了。
chatgpt和文心一言的功能大多類似,如果你把它們當成搜索引擎就是完全錯誤的選擇。充其量就是個信息處理工具罷了。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
![慢訊:阿里通義千問Qwen核心負責人離職[cube_滑稽]](https://imgheybox1.max-c.com/bbs/2026/03/07/381409aa8b7b37bd877f9706e0a22f64.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)















