閱讀指南:時間有限的話,重點看 Section 3(進化四層)和 Section 5(記憶歸屬權)。前者讓你從零理解記憶系統的每一層爲什麼存在,後者告訴你爲什麼這件事比你想象的更重要。
---
1. 你的 AI 助手爲什麼今天又忘記你的名字
你跟 ChatGPT 聊了二十分鐘,告訴它你叫什麼、做什麼工作、最近在折騰什麼項目。聊得挺投機。你覺得它"認識"你了。
第二天你打開新對話,滿懷期待地問了一句:"我們昨天聊的那個方案怎麼樣了?"
它完全不知道你在說什麼。
這不是 ChatGPT 的 bug,也不是你用的模型不夠貴。大語言模型在設計上就是無狀態的——每次你發一條消息,它收到的都是一整段從開頭到現在的完整對話歷史。它不"記得"你,它只是在每次請求時重新讀了一遍聊天記錄。就像一個人每說一句話都要從頭把之前的對話默唸一遍,唸完就忘。
你感受到的"記憶",是一種精心設計的幻覺。你以爲的"它記住了我的名字",實際上只是因爲你的名字在當前的上下文窗口裏。一旦對話太長,最早的內容被截掉,它就"忘"了。一旦你開了新對話,一切清零。
這個無狀態特性意味着:如果你關掉對話窗口,開一個新的,之前的一切都不存在了。模型不認識你,不知道你說過什麼,不瞭解你的偏好。你在上一個對話裏精心調教好的 Agent 人設,在新對話裏全部失效。
這就是 Agent 開發者面對的核心問題之一:怎麼讓 AI 在不同的對話、不同的會話、甚至不同的工具之間保持記憶。
我們來看一個最簡單的 Agent 長什麼樣——一個沒有任何記憶的 Agent:
class MemoryAgent:
"""一個完全無狀態的 Agent"""
def __init__(self):
self.model = "gpt-4"
def chat(self, user_input: str) -> str:
"""每次調用都是全新對話,
不保留任何歷史信息"""
messages = {"role": "user", "content": user_input}
" class="hb-emoji hb-emoji-
{"role": "system", "content": "你是一個助手"},
{"role": "user", "content": user hb-emoji-
{"role": "system", "content": "你是一個助手"},
{"role": "user", "content": user_input}
">
return call_llm(self.model, messages)
def reset(self):
"""無狀態 Agent 不需要重置,
因爲本來就沒狀態"""
pass
這個 Agent 的記憶存在哪裏?在 API 調用的間隙——不存在。
怎麼讓它記住?你可能會想,存個變量不就行了?存個文件?用數據庫?這些方案都對,但又都不夠。原因我們慢慢拆。先搞清楚一個前提:人類記憶是怎麼工作的,因爲 Agent 記憶的設計幾乎完全照搬了認知科學的框架。
---
2. 給 Agent 裝個大腦——記憶的三層模型
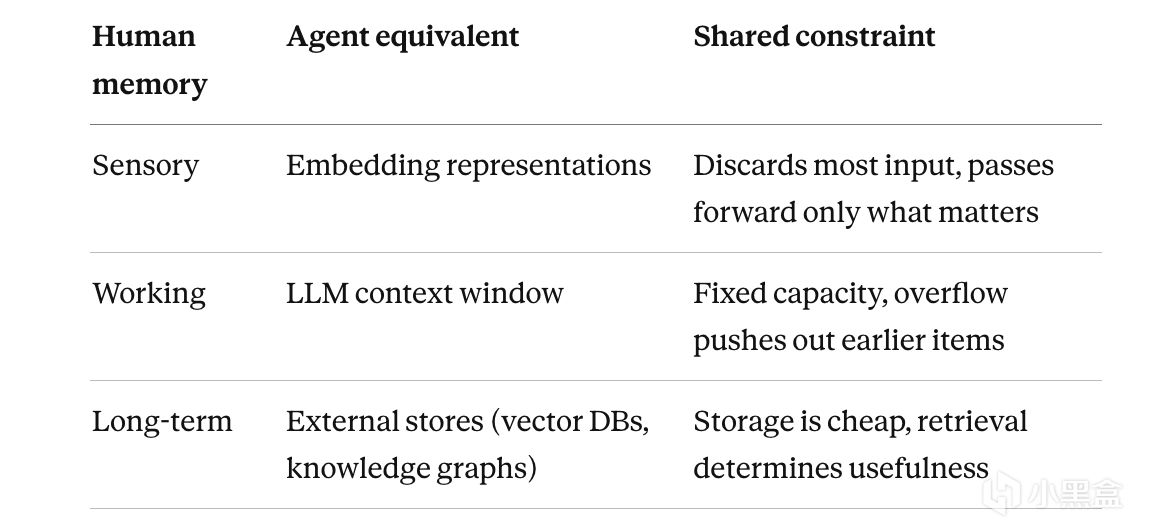
心理學家把人類記憶分成三層,這個模型從 1968 年 Atkinson 和 Shiffrin 提出到現在,基本框架沒變過。
短時記憶(short-term memory):這是剛纔看到的東西,剛纔聽到的音調,剛纔做出的動作。也就是剛剛經過感官的輸入,正在大腦某個部位停留幾秒鐘的東西。在 Agent 的世界裏,這對應就工具返回的原始輸出——一大坨 JSON、一段網頁文本、一條命令行輸出。這些信息在當前輪次可能有用,但下一輪就被新的輸入覆蓋了。
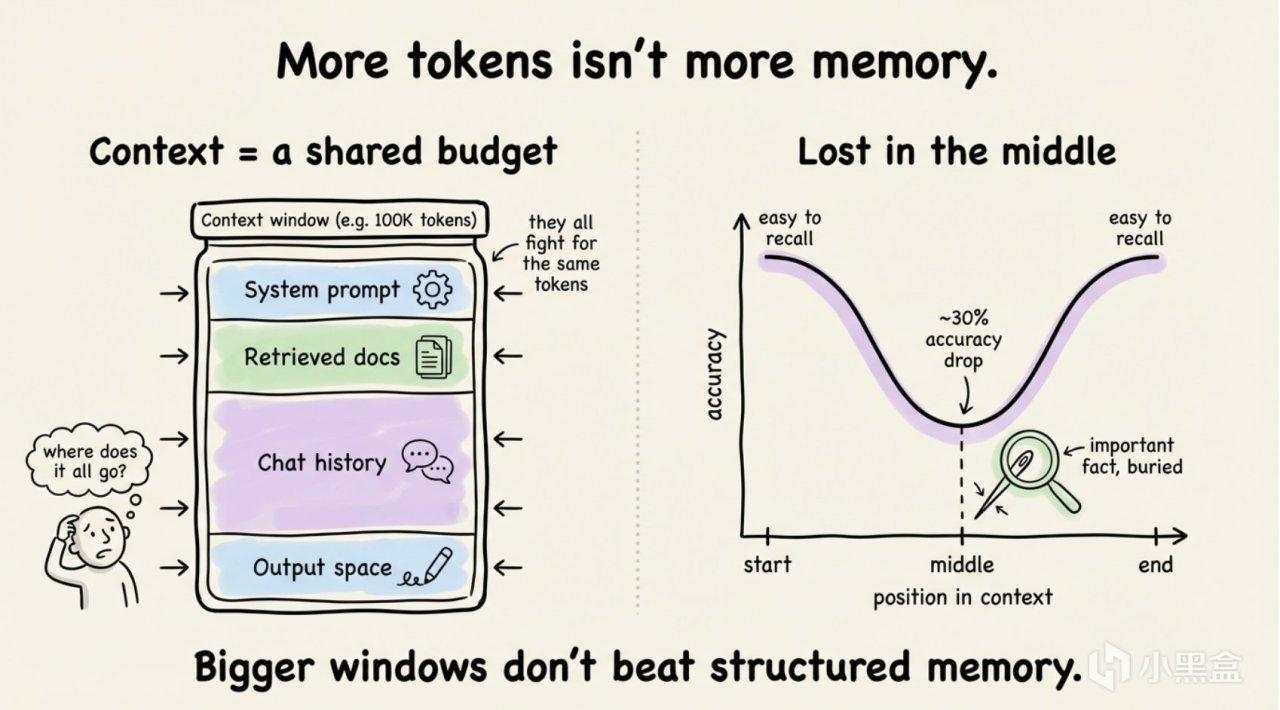
工作記憶(working memory):它容量有限,但它能持續維持。心理學家 George Miller 在 1956 年發表了一篇超級經典的論文,論述並提出了一個很有名的數字:7±2。也就是說人類同時能在腦子裏維持下面的信息單元數量是大約 5 到 9 個。這個論文有很多後續研究修改和演繹,比如 Cowan 在 2001 年修正爲 4±1,但核心結論沒變:工作記憶的容量是非常有限的。對應到 Agent 就是上下文窗口。GPT-4 的窗口是 128K token,聽上去這麼多數量還挺多的,但是稍微複雜點的項目聊天,代碼、日誌、文檔引用幾千字很容易就填滿了。
長時記憶(long-term memory):這一塊我認爲是最複雜的也是最有用的一部分。長時記憶按照認知科學的定義,又被細分成三種:
- 情景記憶(episodic memory):你上週三去開會,聽老闆講了一件事。你去年去旅遊,中午喫了個烤全羊。具體的帶時間戳的記憶。
- 語義記憶(semantic memory):北京是中國的首都。Python 是一種編程語言。從各種各樣具體記憶中抽象出來的知識體系。時間無關的、一般化的知識。
- 程序性記憶(procedural memory):肌肉記憶,打球的都懂。
映射到 Agent 的世界的話就是:
情景記憶 = 對話歷史、任務執行日誌、用戶反饋記錄。信息加時間戳。比如“用戶上週二問了怎麼退款,我告訴他聯繫售後”
語義記憶 = 知識庫、向量數據庫、文檔索引。語言模型本身也是一種語義記憶。比如“公司的退款政策是 7 天無理由退貨”——這條語句的知識可能不是某個具體回答用戶來自的,而是你在大量互動經驗中提煉總結出來的
程序性記憶 = 提示詞模板、工具調用規範、工作流定義。比如”用戶提問涉及到退款,那就先調用查詢訂單狀態工具,然後確認退貨期限,最後執行退款動作”
簡單來說:情景記憶就是經歷了什麼你就記住什麼。但是如果某些相似的模式反覆出現(比如用戶每次問你退款都需要走同樣的流程),那麼你的情景記憶就會抽象爲語義記憶(”退款流程是這樣的”)和程序性記憶(”用戶反問有關退款的問題,就自動觸發這個流程”)。
這三層搞清楚了,從下一節開始我們以一個完整代碼示例爲基準,從最簡單的方案一層層進化,完善一個混合架構的Agent。每層代碼基於之前的內容改造和添加,每一層都解決一個實際問題。
接下來我們定義了一張表格,用來追蹤每一層方案解決了什麼問題:
解決方案 | 多輪對話 | 持久化 | 語義檢索 | 關係推理 | 歸屬權
Agent(無狀態) | — | — | — | — | 你
這個表目前還只有一個最簡單的無狀態Agent,下面我們開始一步步升級。
---
3. Agent 記憶進化
---
3.1:對話歷史
最容易想到的方法,也是最簡單的方法:既然我們的模型要看到歷史消息才能記住之前發生過什麼,我們就把歷史消息存下來,每次請求都發到模型那邊去。
class MemoryAgent:
"""一個用列表來存儲對話歷史的 Agent"""
def __init__(self):
self.model = "gpt-4"
self.messages = [
{"role": "system",
"content": "你是一個有幫助的助手"}
]
def chat(self, user_input: str) -> str:
"""存儲消息的函數並且每次發完整的對話"""
self.messages.append(
{"role": "user", "content": user_input})
response = call_llm(self.model, self.messages)
self.messages.append(
{"role": "assistant", "content": response})
return response
def get_history_length(self) -> int:
"""查詢對話歷史長度"""
return len(self.messages)
現在你的 Agent 可以記住對話上下文啦。你問它名字,下一秒她就記得。多輪對話的基本能力有了。
但是馬上又會面臨兩個問題:
第一個問題:上下文長度是有限的。 4.7 opus和剛出的deepseek-4-pro可以達到1M的上下文,你可能感覺很多,但是如果你讓你的 Agent 去做一個稍微複雜點的任務,比如分析一個大型代碼庫、讀取一份長報告,那你的對話歷史就會迅速積累到上限。超過一定閾值之後,Agent就會壓縮,丟失部分信息,那記憶本質上也丟失了。
第二個問題:進程重啓,內存清零。 這個 self.messages 變量就存儲在 Python 的內存裏。你關閉了終端、服務器重啓了、又或者你的 Python 進程崩潰了一下,信息就全沒了。這在實際部署場景中非常常見,一旦 重啓,積累在內存中的大量上下文信息就會丟失。
簡單粗暴的列表記憶方案解決了“多輪對話”的問題,但是引入了“記憶持久化”的新問題。
解決方案 | 多輪對話 | 持久化 | 語義檢索 | 關係推理 | 歸屬權
Agent(無狀態) | — | — | — | — | 你
+ 對話歷史 | ✓ | — | — | — | 內存(進程死=記憶滅)
存儲在內存裏。進程掛了,內存也沒了。
那怎麼解決呢?將內存中的記憶做持久化存儲。
---
3.2:文件 I/O — 記憶寫成你能看懂的 markdown 文本
解決記憶持久化的最自然方式:把東西寫進文件。重啓Agent再讀回來。
但是我們可以稍微變通一點點,我們讓 Agent 做一些額外的工作,把重要信息提煉成一個個記憶筆記,並且存儲爲 markdown 格式。每次啓動我們讀取這些記憶筆記,作爲我們發給模型的上下文內容的一部分。
如果你用過 Claude Code 的話,它的 MEMORY.md 和 CLAUDE.md 文件就是這套方案的體現:用 markdown 格式記錄項目約定、用戶偏好、長期決策等內容,Agent 每次啓動時自動讀取內容。
OpenClaw 和 Hermes 這兩個 Agent 框架,都把這種文件記憶模式作爲底層默認特性。
class MemoryAgent:
"""一個用 markdown 文件持久化記憶的 Agent"""
def __init__(self, memory_file="memory.md"):
self.model = "gpt-4"
self.messages = []
self.memory_file = memory_file
self.memory = self._load_memory()
def _load_memory(self) -> str:
"""從文件讀取記憶"""
try:
with open(self.memory_file) as f:
return f.read()
except FileNotFoundError:
return ""
def _save_memory(self, new_info: str):
"""向文件寫入新增信息"""
with open(self.memory_file, "a") as f:
f.write(f"\n- {new_info}")
self.memory = self._load_memory()
def chat(self, user_input: str) -> str:
"""帶文件記憶讀取的交互"""
context = ""
if self.memory:
context = f"已知信息:\n{self.memory}\n\n"
self.messages.append(
{"role": "user",
"content": context + user_input})
response = call_llm(self.model, self.messages)
self.messages.append(
{"role": "assistant", "content": response})
return response
現在我們的 Agent 可以把記憶寫入文件了。注意這裏我們用到的 markdown 格式,天然的可讀。你隨便用什麼編輯器都能打開這個文件,隨意修改內容,用Git管理版本。
但是它有一個致命的缺陷,不怎麼好搜索。
假設你在記憶文件裏寫下了:我們將產品數據庫遷移到新 AWS 區域。而過了幾天你問 Agent:“我們的雲端遷移進展得如何了?”它搜索不到。文件裏頭沒有“雲端”這三個字。你說的話和文件裏的內容語義上是一個意思,但不是字面上的意思。
再比如你寫下了:Alice 負責 Project Atlas。你現在搜索筆記文件,“誰負責數據庫項目?”搜索不到結果。記憶文件裏面沒有“數據庫項目”這幾個字,雖然你知道 Atlas 就是用數據庫做的項目。
Obsidian、Notion 這類筆記軟件都有這個問題。全文檢索可以根據輸入的關鍵詞來匹配內容,但無法找到“意思相近”的內容。隨着你的筆記越來越多,這個問題會越來越嚴重。
問題來了:你的記憶存在哪裏?
解決方案 | 多輪對話 | 持久化 | 語義檢索 | 關係推理 | 歸屬權
Agent(無狀態) | — | — | — | — | 你
+ 對話歷史 | ✓ | — | — | — | 內存(進程死=記憶滅)
+ 文件 I/O | ✓ | ✓ | — | — | 你的文件(可打包帶走)
現在我們可以把記憶永久地記錄在本地了,但是檢索能力比較差。
---
3.3:向量檢索
前面提到過,關鍵詞搜不到“意思相近”的內容,根本原因就是因爲文字對人有意義,對計算機只是一串字符串。
如何解決這個問題?就是需要讓計算機理解文字的意思。
這個方法就是 embedding(向量嵌入)。文本經過了 embedding 後,變成了一串數字座標。比如“數據庫”和“PostgreSQL”它們的字符串完全不一樣,但是在 embedding 後的向量表示空間裏,兩者是鄰居。當你搜索數據庫的時候,PostgreSQL 自然會被檢索出來。
向量檢索就是用向量空間裏相似來檢索,而不是直接字符串匹配。
class VectorStore:
"""一個超簡單版的向量存儲——用硬編碼距離來演示基本概念"""
def __init__(self):
# 預先計算好的向量距離,純粹爲了演示做了硬編碼
# 實際中這裏會用 embedding 模型計算出來
self.distances = {
("數據庫", "PostgreSQL"): 0.15,
("數據庫", "MySQL"): 0.18,
("雲遷移", "將生產數據庫遷移到AWS"): 0.12,
("Alice", "PostgreSQL"): 0.35,
("Alice", "Project Atlas"): 0.25,
}
def search(self, query: str, top_k=3) -> list:
"""返回距離 query 最近的 k 個結果"""
results = []
for (a, b), dist in self.distances.items():
if query.lower() in a.lower() or query.lower() in b.lower():
results.append(
(a if query in b else b, dist))
return sorted(results, key=lambda x: x[1])
def add(self, text: str, embedding: list):
"""添加新文本(超簡化了,不涉及實際計算嵌入)"""
pass
class MemoryAgent:
"""加上向量檢索的 Agent"""
def __init__(self, memory_file="memory.md"):
self.model = "gpt-4"
self.messages = []
self.memory_file = memory_file
self.memory = self._load_memory()
self.vectors = VectorStore()
def _load_memory(self) -> str:
try:
with open(self.memory_file) as f:
return f.read()
except FileNotFoundError:
return ""
def chat(self, user_input: str) -> str:
"""先向量檢索相關記憶,然後再聊天"""
related = self.vectors.search(user_input)
context = ""
if related:
context += f"相關記憶: {related}\n"
if self.memory:
context += f"已知信息:\n{self.memory}\n"
self.messages.append(
{"role": "user",
"content": context + user_input})
response = call_llm(self.model, self.messages)
self.messages.append(
{"role": "assistant", "content": response})
return response
這樣搜索“雲遷移”可以匹配到我們記錄的“將生產數據庫遷移到 AWS 區域”的記憶。向量檢索徹底打破了關鍵詞匹配的侷限性。
ChatGPT 在今年年初發布的記憶功能就是建立在向量檢索上面的。ChatGPT 會把用戶輸入的東西和長期記憶裏的內容計算語義距離,選取距離最近的幾個內容,並且把它們注入到聊天上下文之中。這樣即使你換了種說法,也能找到相關內容。
但向量檢索也有缺點,假設你的記憶庫裏有以下三條內容:
Alice 是 Project Atlas 的負責人
Project Atlas 使用的數據庫是 PostgreSQL
PostgreSQL 昨天掛掉了一次,影響了部分用戶
然後你問你的 Agent:“Alice 的項目最近出現了什麼問題嗎?”
爲了正確答覆這個問題,Agent 必須要連接起上面三條內容:Alice → Project Atlas → PostgreSQL → 故障。
而向量檢索做了什麼?計算“跟 Alice 關係密切的”內容,找到了 Alice 和 Project Atlas 的關係。計算“跟問題相關的內容”,找到了 PostgreSQL 出故障這條記錄。它看不到 Alice → Project Atlas → PostgreSQL 這條三連。
究其根本原因,還是因爲你寫進去的內容是一堆孤立的字符串,而不是一個知識圖譜。
如果你換一種問法:"PostgreSQL 最近有什麼問題?
向量搜索能完美回答,因爲"PostgreSQL"和"故障"在向量空間裏確實很近。問題出在多級上:從 Alice 到 Atlas 是一級,從 Atlas 到 PostgreSQL 是另一級,從 PostgreSQL 到故障是第三級。每一級都需要沿着一條明確的關係邊走過去,而不是在向量空間裏直線測量距離。
爲什麼呢?因爲向量空間裏,每個事實是一個孤立的點。"Alice 管理 Atlas"是一條邊,"Atlas 使用 PostgreSQL"是另一條邊,"PostgreSQL 有故障"是第三條邊。
這三條邊可以在向量空間表示成三個獨立的向量。向量距離只能度量兩個點之間的相似度,並不能沿着”管理→使用→有故障“的鏈路一路走到底。
這三個實體之間的關係對向量搜索來說是不可見的。
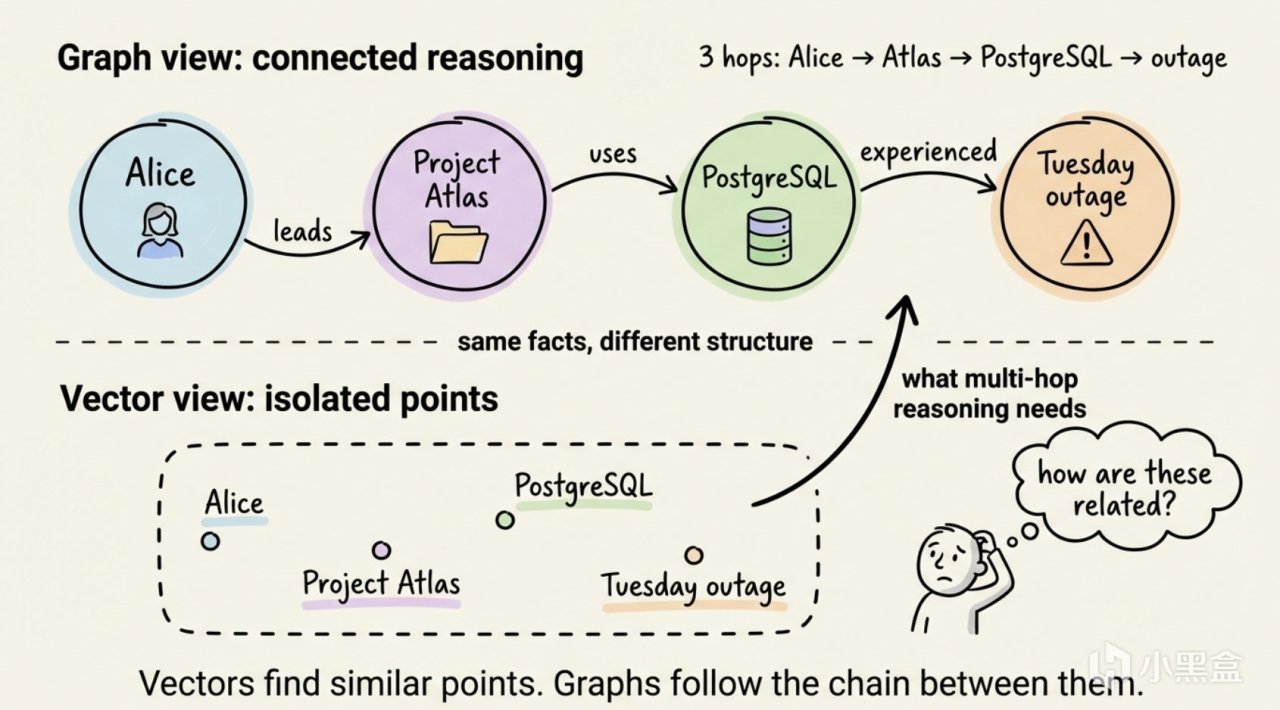
這就是多級推理無法實現的原因。也是純粹依賴關鍵詞匹配和向量搜索都不完美的原因。
讓我們回到能力矩陣。
方案 | 多輪對話 | 持久化 | 語義檢索 | 關係推理 | 歸屬權
Agent(無狀態) | — | — | — | — | 你
+ 對話歷史 | ✓ | — | — | — | 內存(進程死=內存丟失)
+ 文件 I/O | ✓ | ✓ | — | — | 你的文件(可存檔)
+ 向量搜索 | ✓ | ✓ | ✓ | — | 向量數據庫(格式綁定)
語義檢索搞定了,但關係推理還不行。最後一層。
---
4.知識圖譜 + 混合架構
想要完成多級推理,我們需要引入一種可以顯示存儲“關係”的數據結構:知識圖譜(knowledge graph,用節點存儲實體、用邊存儲關係,像張網一樣把所有東西都連在一起)。
但知識圖譜搜索不是搜索數據庫……知識圖譜也不擅長語義檢索。在圖譜裏,”數據庫“和”PostgreSQL“是兩個完全不同的節點。如果我搜索”數據庫“是不一定能找到 PostgreSQL 的。
所以最終的解決方案是混合架構。
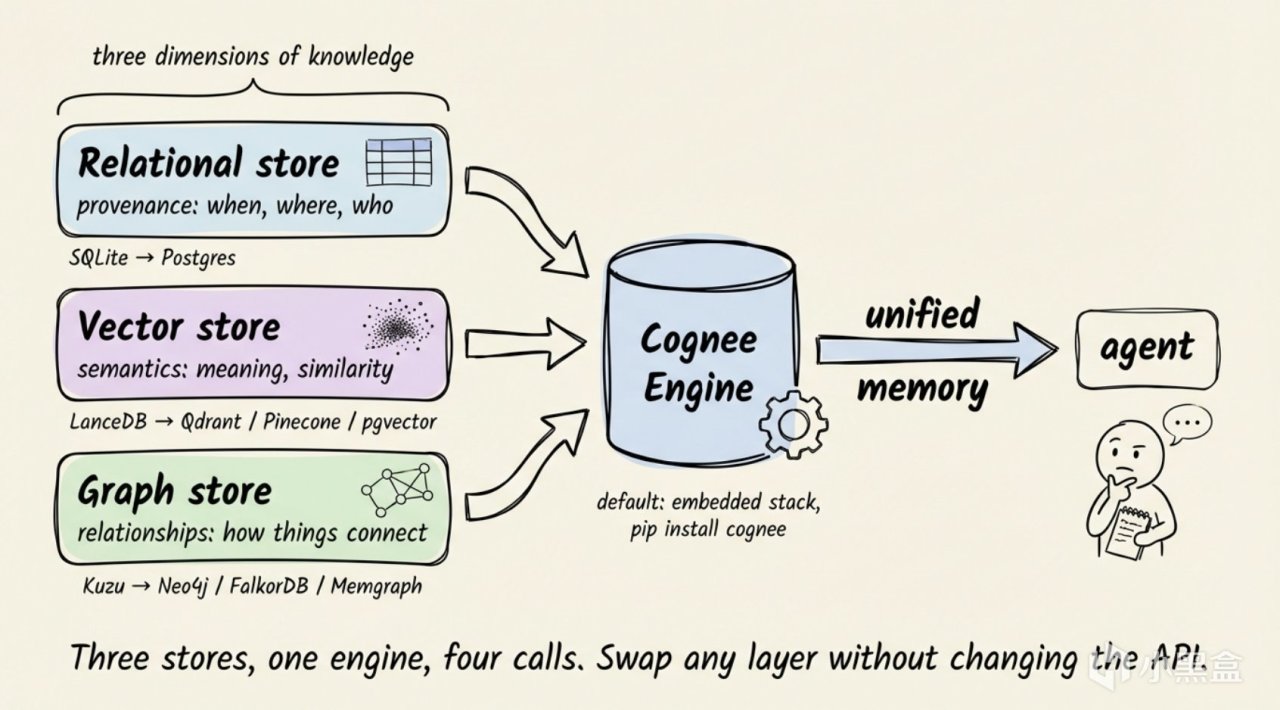
**關鍵詞精確匹配**:BM25,精確的詞面匹配。”PostgreSQL”搜索”PostgreSQL”一定能命中。
**向量搜索** :語義相關,“數據庫”可以找到”PostgreSQL“。
**圖譜遍歷** :知識圖譜搜索,“管理”的女兒就是 Alice 使用過的所有數據庫。
這三種結果如何融合到一起呢?你可以使用一種叫做 RRF 的技術(Reciprocal Rank Fusion),簡單來說就是讓三個“人”各自爲候選項排序,之後用”排名越前越高權重越大“的規則將排序融合在一起(就像每個人對一個結果投一張選票,票越靠前投的人排名越靠前越重)。最終的得分就是按分數排序的倒數之和。
class KnowledgeGraph:
"""簡化版知識圖譜——用字典存儲實體關係"""
def __init__(self):
self.edges = {
("Alice", "manages"): ["Project Atlas"],
("Project Atlas", "uses"): ["PostgreSQL"],
("PostgreSQL", "had_outage"): ["2024-03-15"],
("Alice", "role"): ["Tech Lead"],
}
def traverse(self, start: str, max_hops=3) -> list:
"""從起點出發,沿着關係鏈路走"""
visited, found = set(), []
queue = [start]
for _ in range(max_hops):
next_q = []
for node in queue:
if node in visited:
continue
visited.add(node)
for (s, rel), targets in self.edges.items():
if s == node:
found.extend(targets)
next_q.extend(targets)
queue = next_q
return found
def reciprocal_rank_fusion(
bm25_hits, vec_hits, graph_hits, k=60):
"""RRF 融合:三路檢索結果合併排序。
每個結果從三路各獲得一個排名,
最終分數 = 各路 1/(k+排名) 之和。
排名越靠前,分數越高。"""
scores = {}
for results in [bm25_hits, vec_hits, graph_hits]:
for rank, item in enumerate(results):
scores[item] = scores.get(
item, 0) + 1.0 / (k + rank + 1)
return sorted(scores.items(),
key=lambda x: -x[1])
class MemoryAgent:
"""完整混合架構——三路檢索 + RRF 融合"""
def __init__(self, memory_file="memory.md"):
self.model = "gpt-4"
self.messages = []
self.memory_file = memory_file
self.memory = self._load_memory()
self.vectors = VectorStore()
self.graph = KnowledgeGraph()
def _load_memory(self) -> str:
try:
with open(self.memory_file) as f:
return f.read()
except FileNotFoundError:
return ""
def chat(self, user_input: str) -> str:
"""三路並行檢索,RRF 融合,然後對話"""
bm25_hits = keyword_search(
self.memory, user_input)
vec_hits = self.vectors.search(user_input)
graph_hits = self.graph.traverse(
extract_entity(user_input))
merged = reciprocal_rank_fusion(
bm25_hits, vec_hits, graph_hits)
context = f"綜合檢索: {merged[:5]}\n"
if self.memory:
context += f"已知信息:\n{self.memory}\n"
self.messages.append(
{"role": "user",
"content": context + user_input})
response = call_llm(self.model, self.messages)
self.messages.append(
{"role": "assistant", "content": response})
return response
開源項目 Cognee 把這整套架構封裝成了 4 個 API:add() 存數據、cognify() 自動構建圖譜和向量索引、memify() 優化權重(後面會講)、search() 做混合檢索。底層自動管理三種數據庫——SQLite 做關係存儲、LanceDB 做向量、Kuzu 做圖查詢。
Hindsight 走了另一條路:不需要你手動搭建三種數據庫,而是提供了一個仿生記憶系統,2 行代碼就能快速接入。底層用 PostgreSQL 統一管理,同時支持語義檢索、關鍵詞匹配、圖譜遍歷和時間維度檢索四路並行。
agentmemory 則專注於跨 Agent 可移植性。它的記憶層不綁定任何特定 Agent——你在 Cursor 裏積累的記憶,可以無縫遷移到 Windsurf 或 Claude Code 裏繼續用。在 LongMemEval 基準測試上,它的召回準確率達到了 92% 以上。
一些智能客服產品,背後就是這種混合架構。它沿着"用戶 → 訂單 → 商品 → 庫存狀態"的鏈路一步步找答案,最後把幾路結果融合起來給你一個準確的回覆。
三種數據庫意味着三個供應商。誰來保證數據一致性?誰真正擁有你的 Agent 的完整記憶?
方案 | 多輪對話 | 持久化 | 語義檢索 | 關係推理 | 歸屬權
Agent(無狀態) | — | — | — | — | 你
+ 對話歷史 | ✓ | — | — | — | 內存(進程死=內存丟失)
+ 文件 I/O | ✓ | ✓ | — | — | 你的文件(可存檔)
+ 向量搜索 | ✓ | ✓ | ✓ | — | 向量數據庫(格式綁定)
+ 圖譜混合 | ✓ | ✓ | ✓ | ✓ | 三個供應商(誰擁有完整記憶?)
能力矩陣填滿了。但代價不只是技術複雜度——還有運維成本。你需要維護三種數據庫(關係型、向量、圖譜),需要保證它們之間的數據一致性,需要處理索引更新、圖譜重建、向量重新嵌入等定時任務。在生產環境中,Cognee 建議的配置是 PostgreSQL 做關係存儲、Qdrant 做向量檢索、Neo4j 做圖譜查詢——三個獨立的服務需要監控、備份和故障恢復。
值不值得?取決於你的場景。如果你的 Agent 只需要回答"這個用戶喜歡什麼"這類簡單問題,文件 + 向量就夠了。但如果它需要回答"Alice 的項目最近有什麼問題"這類需要鏈路推理的問題,混合架構不是奢侈,是必需。
---
6. 記憶會遺忘才健康——衰減與自我優化
到這一層你可能以爲,存儲多、檢索準確,纔是完美的記憶系統。實際上,完美的記憶系統是會主動遺忘的。
Cognee 的 memify() 函數做了一個看似違反常理的事情:主動地對知識圖譜的邊做一些弱化操作。意思是說,在知識圖譜裏有的節點 A 和 B 之間的關係,會被逐漸弱化,如果不經過強化(查詢),它的權重會越來越低。
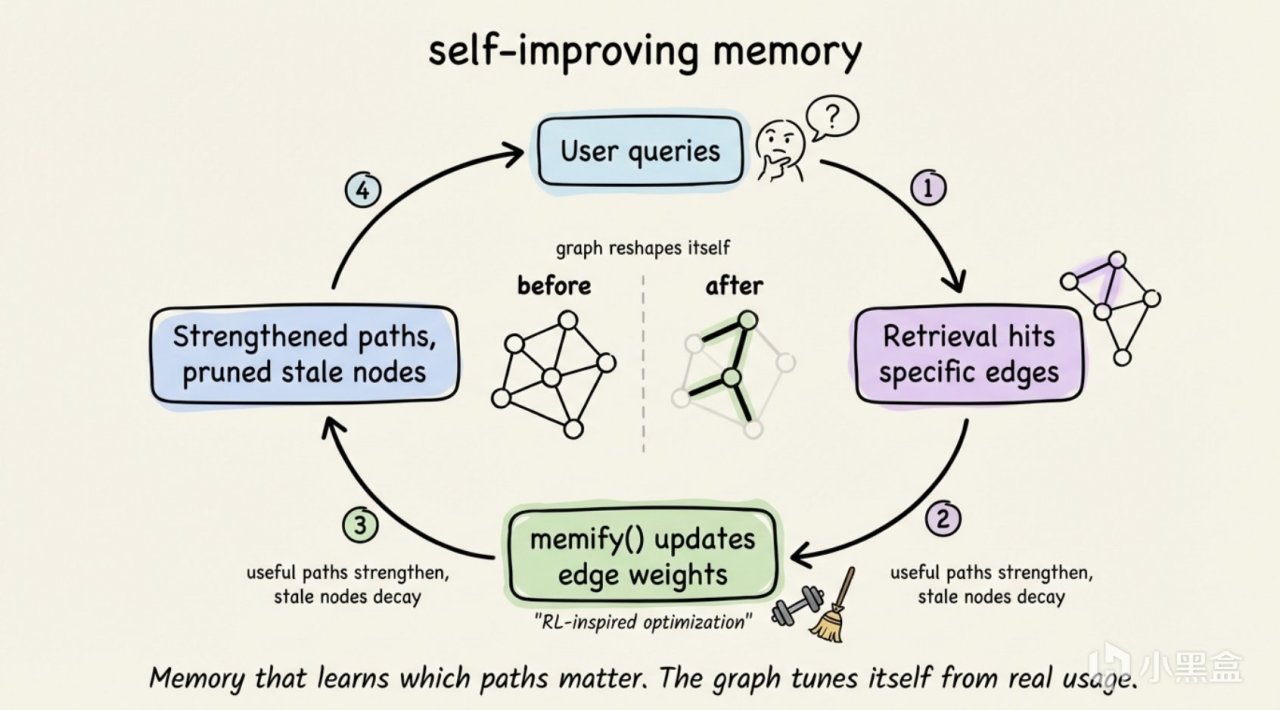
原理很簡單:對於每條邊(即表示兩個實體之間的關係)都設置一個權重(weight),表示這條邊的優先級。每當有查詢經過這條路徑時,會被強化(加大權重)——類似於森林裏的小路,被人走的越多,越寬。而長期無人走的路徑,它的強化權重會被按一定的比例進行衰減,直到忘記。
這背後的理論來自強化學習。以"用戶 → 訂單 → 商品 → 庫存狀態"爲例,Cognee 的系統每當有人問 AI 客服"最近有哪些庫存賣光的商品",這條路徑的強化權重就會被加大一些。
越經常被查詢的路徑,越容易被檢索到。
還是拿剛剛那個例子:你有一個 AI 的客服 agent。每天被問一次 "退款怎麼辦",然後用戶需要去"商品 → 規格"看具體退款說明的路徑,每天會被搜索引擎加強調查 300 次。而 3 年前某個已經被廢棄的功能點,幾乎不會有用戶查詢,權重會慢慢衰減到 0。
比如說同時爲銷售和 HR 內部部門做知識圖譜搜索的 Agent。銷售團隊每天都會通過"產品 → 文檔 → 解決方案"這條路徑查詢知識,這條邊的強化權重會被加大。HR 管理員偶爾也會搜索員工的培訓記錄——通過"員工 → 培訓記錄"這條路徑。因爲後者使用頻率低,前者使用頻率高,系統會自動優化圖譜,使搜索的頻繁路徑權重加大。
你的大腦也是這麼實現記憶重要性的:你每天都會走從家到公司的路線。你閉着眼睛都能找到對應的路。因爲你每天走這條路,這條路徑被反覆強化了。
19 世紀的心理學家 Hermann Ebbinghaus 通過實驗總結出了人腦記憶衰減的規律:遵循指數曲線衰減。學習了一個完全新鮮的知識點,一小時後你只記住了它的 44%;一天後你只記住 33%。但如果你在這知識快被你完全遺忘時,去複習這個知識點一次。那麼你的記憶就會被延長。
Cognee 的圖譜衰減機制其實和 Hermann Ebbinghaus 概括的記憶衰減規律差不多:不常查的路徑會被逐漸淘汰,經常查的路徑會被強化。當用戶的查詢模式真實反映了系統被使用的場景時,系統其實已經幫你配置好了重要程度。
永不遺忘的記憶系統是噪音放大器。 購買了 3 年前的那些功能點和剛發佈的核心功能,在檢索時都有一樣的優先級——搜索結果每次都會被各種無關緊要的噪音干擾。
Hindsight 框架的作者也意識到了這一點。他們實現了一個名叫 reflect 的操作:定期從當前的記憶中自動提取出新的知識點。就像你去睡覺,白天的很多記憶都被整理成了生物鐘能記住的 episodic memory 一樣。你跟 Agent 說了一百遍:『 我喜歡深色主題 』——Hindsight 的深度學習模型會自動生成一個 semantic rule:『 用戶喜歡深色的界面主題 』。
好的記憶系統會記住重要的,主動遺忘過時的,從重複查詢中提煉規律。
綜上四層,加上這層衰減和遺忘機制,才能完整描述一個 AI Agent 的記憶架構。
但是還有最後一個問題沒有解決:這些記憶到底歸屬於誰?
---
7. 你的記憶,屬於誰?
歸屬權是我覺得 Agent 時代最容易被忽視的問題之一:很多人在發現記憶被丟失或者鎖死以後,才意識到歸屬問題的存在。
它有三個級別,也可以叫鎖定級別。從輕到重:
輕度鎖定:有狀態 API 。 有的 AI 服務商提供了類似"自動上下文壓縮"的功能,你的對話歷史存在他們的服務器上,按照特定壓縮格式保留。效果確實不錯,省去了你自己去管理上下文窗口的麻煩。但代價就是:換個模型商,你的記憶就丟失了。這些壓縮好的上下文格式基本不具備可遷移性。比如說 Anthropic 家的 Claude ,雖然他們有服務端記憶的功能,但壓縮後的對話上下文是無法導出的,你只能看到"Claude 記住了你喜歡喫辣"這個事實,而看不到壓縮前的原始數據。Google Gemini 也類似,他們的"記憶"也是存在在 Google 的服務器上的。
中度鎖定:封閉的 Agent 框架。 因爲他們內置的記憶格式是自家專有的、壓縮格式的摘要。用戶看不到裏面原始的內容,更無從遷移、導出。一篇叫"Your Harness, Your Memory"的文章,指出:你選擇了什麼樣的 harness(框架),你的 agent 就會有怎麼樣的記憶系統。
爲什麼這麼說呢?因爲有的框架開發者在設計記憶系統時,並不考慮跨框架使用的兼容性。他們考慮的是和自家產品的無縫對接,以提升整體用戶體驗。如果你要從一個框架遷移到另一個,你的記憶是帶不走的。框架不一定差:他們可能很強大、開發體驗很好用。但你需要知道,用了這套框架多久,離換框架的痛苦值就會翻倍。
重度鎖定:平臺級記憶。 這個是歸屬權問題的最嚴重的情況,因爲涉及到你整個數字化辦公體系。有用戶在論壇上分享過自己的經歷:他使用了一家 AI 郵件助手,來幫助他整理半年的工作郵件。郵件助手 AI 瞭解他的溝通風格,給領導的郵件正式簡練、給用戶提問題時貼心周全。AI 慢慢學會了這個用戶所有重要聯繫人的喜好、每個項目的重要節點、每個溝通中產生的待解決問題。
經過半年的積累,這個 AI 助手變成了這個用戶的日常工作流的一部分。可後來這個產品調整了新的計費模式,比他之前預算的高。於是他找了其他的產品對比,並最終下了決定要換一個替代產品。但這位用戶發現,自己積累半年的"記憶"全部被鎖在了原來的平臺裏,無法導出。改用新的平臺以後,新產品的表現一落千丈。
換個角度說:新助手缺少的是半年積累下來的系統瞭解這個用戶工作習慣的能力。
你或許會認爲這是極端情況。但這時你請問自己:你用 AI 助手有多久了?它積累了多少關於你工作習慣、項目細節以及偏好的信息?如果明天因爲某種原因,這個平臺被關停了,或者提價到你無法接受的價格?你能不能帶走你和它積累下來的"記憶"?
隨着工具的發展和成熟,Agent 的記憶會越來越具備複利作用:使用的時間長,AI 理解你的越透徹,幫你的越省力。而歸屬權問題也變得越來越重要。
我非常贊同開源精神:開源工具 + 開源格式 = 可遷移
你的Agent的記憶,理論上應該是一個可以下載的文件夾。文件夾裏面只有你可以用記事本編輯的純文本文件。
比如我們項目裏面用到的 MEMORY.md、.SOUL.md、.USER.md 就是一個開放格式的體現。所有的內容都是純文本,完全是人類可讀的。任何編輯器都能打開、編輯。任何 Agent 都能讀取。甚至可以用 Git 追蹤版本變更歷史。你不需要向任何公司申請就能查看、編輯你 Agent 的記憶。
Deep Agents 項目有一個很好的實踐:他們設計了一個可以無縫換底層數據庫引擎的記憶系統。換句話說,你可以選擇 MongoDB、Postgres、Redis 作爲你的記憶後端;而當你遷移時,也可以隨意更換,因爲他們的接口是開放的、可插拔的。
你現在可能正在用的工具裏也有。如果你用過 Claude Code ,你自己搭建 Agent 的項目根目錄裏那些 .md 文件其實就是你 Agent 在本地硬盤上存儲的文件。你不依賴任何 API、任何雲服務商、任何平臺,完全自建。換一個 Agent SDK?文件還在。換個工具讀取它們就好。
即便 Claude Code 明天倒閉了,你隨時可以用另外一個文本編輯器,直接查看其中的內容。
這就是開源格式的好處:控制權在你手上,而不是鎖定在某一家公司的服務器上。
在選型記憶系統的時候,不僅要衡量它的技術能力(能不能檢索準確、能不能做多級推理),還需要考慮記憶的可移植性:
如果明天我要換工具,我的記憶能帶走嗎?
如果你的答案不能,那麼你可能需要找一套更開放的解決方案。
---
記憶選型決策樹
說這麼多方案,落地時到底該怎麼選?
你可以用下面這張圖:
你的 Agent 需要記住多少事實?
│
├─ 幾個到幾十個 → Markdown 文件就夠了
│ 不用引入任何數據庫。
│ MEMORY.md + Git 版本管理,簡單可靠。
│
├─ 需要語義搜索嗎("意思相近"能找到)?
│ ├─ 不需要 → 關鍵詞 + 文件,到此爲止
│ │ 適合項目文檔、API 文檔等結構明確的內容
│ └─ 需要 → 加向量數據庫
│ 用 embedding 模型建立索引
│ 搜索從"字面匹配"升級爲"語義匹配"
│
├─ 需要關係查詢嗎("A 通過 B 關聯到 C")?
│ ├─ 不需要 → 向量 + 文件就夠了
│ │ 大多數聊天機器人和知識庫場景到此爲止
│ └─ 需要 → 混合架構(向量 + 圖譜 + BM25)
│ 用 RRF 融合三路檢索結果
│ Cognee、Hindsight 可以幫你搭好
│
└─ 不確定?從 Markdown 開始,遇到瓶頸再升級
這是最務實的路徑。每一層代碼改動都不大,
而且你會清楚地知道"我爲什麼需要更復雜的方案"——因爲簡單方案在某個具體場景下失敗了
工具 | 一句話特色 | 適合誰
Markdown 文件 | 零依賴,人類可讀,Git 管理 | 個人開發者、輕量級 Agent ,不想引入額外基礎設施
Hindsight | 仿生記憶、2 行代碼接入、內置衰減 | 快速原型,想先跑起來再說
agentmemory | 跨 Agent 可移植記憶層,LongMemEval 92%+ | 多工具協同(Cursor + Claude + Windsurf 同時用)
Cognee | 四個 API 搭好三重存儲、自動圖譜構建 | 需要完整混合架構的生產項目
Hermes / OpenClaw | 內置 MEMORY.md 模式,Agent 策展記憶、開放格式 | 日常開發 Agent ,偏好開放格式和可移植性
如果我可以再給你一點建議的話,那就是從 Markdown 文本文件開始。用一個月的時間,把遇到的所有問題寫下來。寫到你發現哪些問題,關鍵詞搜索無法解決。用一個月時間,集中解決關鍵詞搜索無法解決的問題。再等關鍵詞搜索跑得滿地都是 bug 的時候,再考慮引入向量檢索。用向量檢索又過一個月,看看那些問題是因爲"找不到相關關係"造成的。再引入一整套混合檢索系統,去解決鏈路推理無法解決的問題。
逐步升級,以實用爲主。
同時,不管你用哪種工具。都記住一個道理:選擇開源的、開放的。
你的記憶是你工作中最能反映個人習慣、偏好的底層數據資產之一。甚至可以說是數據資產裏面最能反映你個人的那一份。把它鎖定在別人無法提供的格式裏,那就等於把自己所有的數字化積累工作都交給了別人。
你的項目裏用了哪些記憶方案?有遇到記憶丟失或者記憶被鎖死的問題嗎?評論區聊聊 ❤
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















