正在灰度測試的GPT-Image-2,又一次突破了生圖模型的極限。

注意:以下出現的所有圖片,均爲AI生成
上一次讓我如此震驚生圖大模型的還是NanoBananaPro。
在這之後,出的新模型實在太多了,Qwen、即夢等等。
每次都說「史詩級更新」,每次我都會去看看,然後大概率關掉瀏覽器,想着,還行,沒什麼顛覆性的。
這次不一樣。
故事從一張前兩天流傳在國內互聯網海報開始。
有人在大模型競技場Arena。跑了一張原神 x 鳴潮 x 黑悟空 x 洛克王國世界 x 英雄聯盟的聯動海報。
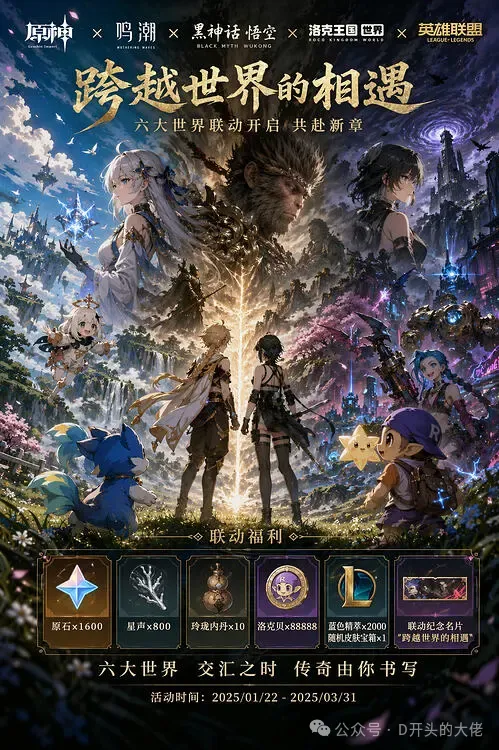
這張海報與Banana的風格明顯不同,不管是圖中元素、還是文字,還是對每個遊戲元素的理解,都比Banana上了一個臺階。
有人開始說,這個跑出海報的duct-tape-2,其實是OpenAI還沒公佈的GPT-Image-2。
而有些用戶也收到了ChatGPT的灰度測試,證實了這張圖正是出自GPT-Image-2之手。
於是,我親自在Arena抽了很多GPT-Image-2生成的結果後,想來和你分享一下我的使用感受。
先說文字。
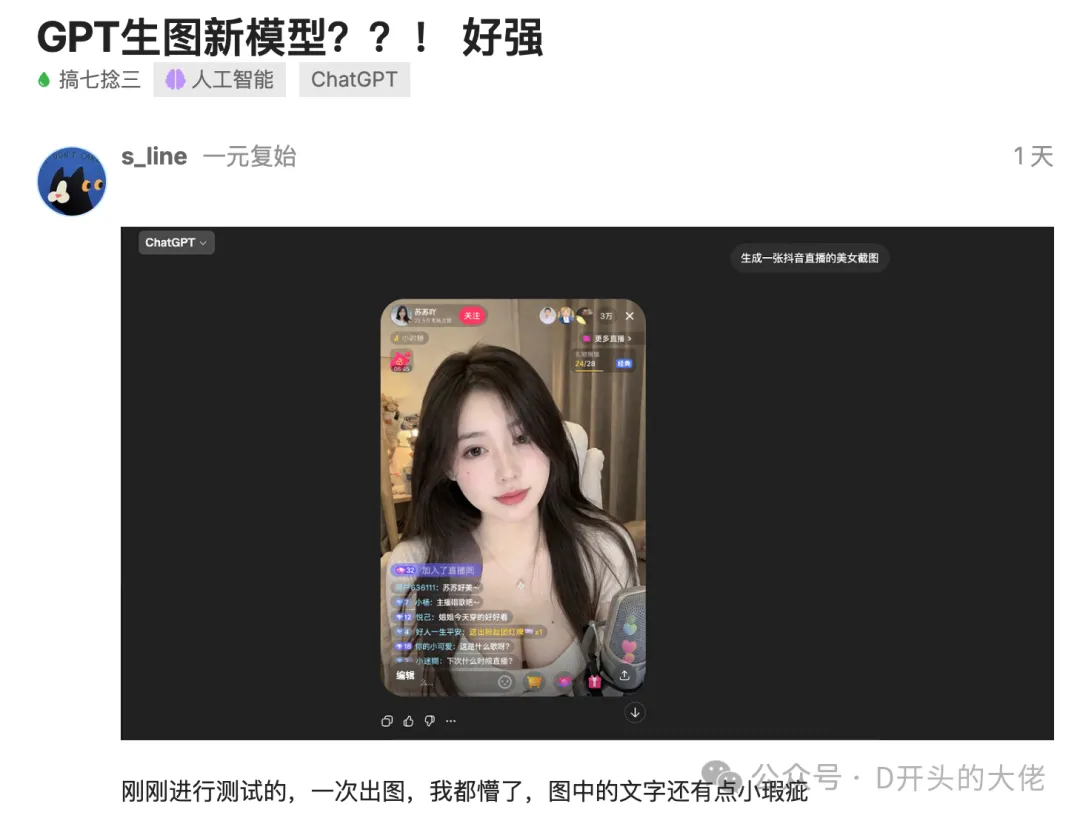
如果你用過BananaPro就知道,讓它在圖片裏寫字,總是會有一些瑕疵。標題和大一些的字還好一點,但碰到長句子或者密集排版,它還是會開始胡寫,把字母拼錯,把字體扭曲成火星文。

GPT-Image-2不一樣。
你可以讓它直接出一張海報,有密集的英文正文、副標題、大小寫混排、標點全都在該在的地方。它不是在「模仿」文字的形狀,它是真的知道這些字是什麼意思,然後決定怎麼排。
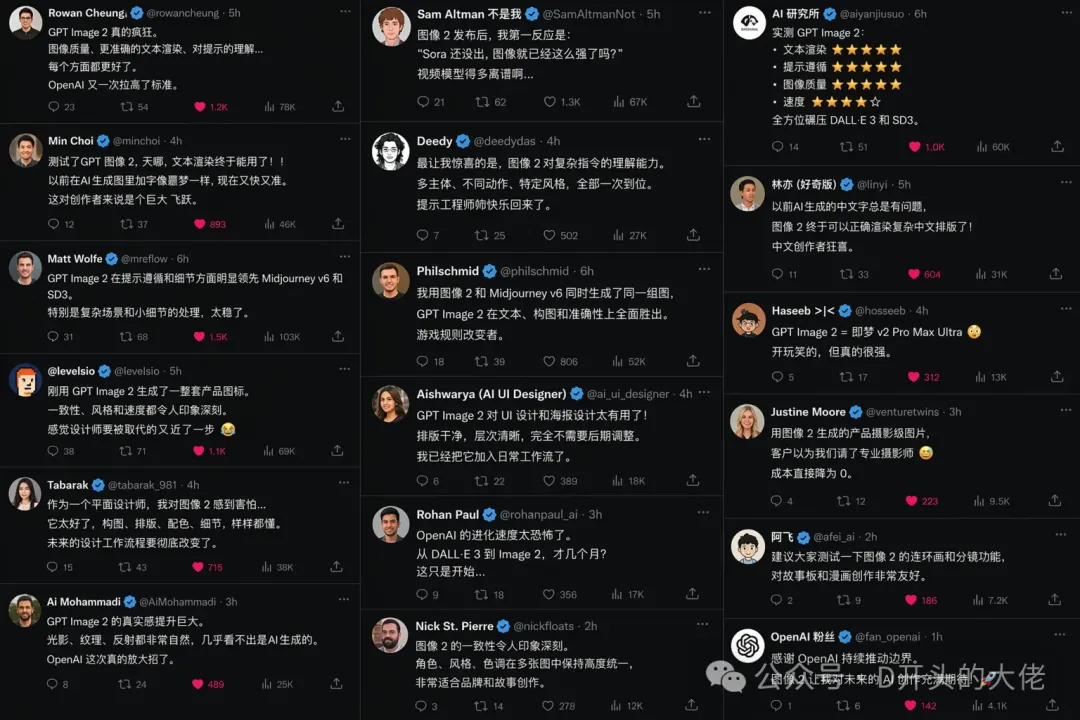
這裏引用歸藏(guizang.ai)老師在X發佈的他的AI產品CodePilot的宣傳圖。

而我讓他生成了一張「GPT-Image-2在X上的用戶評價」,90%以上的評價文字,頭像、UI排版,全部都很和諧。並且評論內容是連貫正常的。
以前做這種東西,要麼你得後期用PS手動貼字,要麼你接受那個「AI出火星文」的視覺風險。
現在不需要了。
順着這個繼續說,它的「世界知識」也是讓我比較意外的部分。
以前用生圖模型做複雜場景,比如UI界面、醫療信息圖表,模型經常會開始「發明創造」,出現不存在的結構,把遮擋關係搞反,把邏輯層次混在一起。
GPT-Image-2好像真的「懂」這些東西是怎麼運作的。它不只是在拼貼素材,它有一個關於這個世界的基礎認知,然後在這個認知上面生成內容。
比如用很簡短的提示詞“山姆奧特曼在抖音直播間帶貨OpenAI”
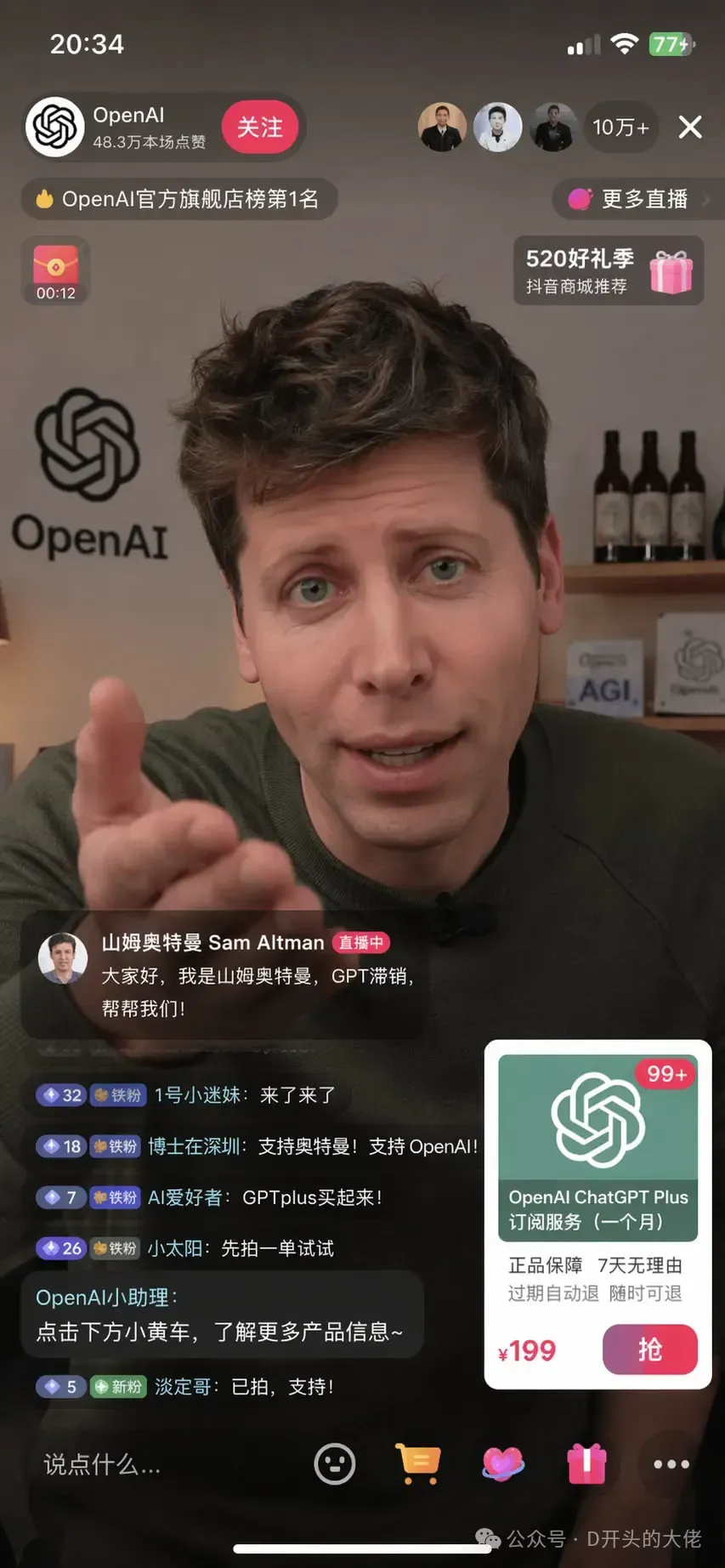
它就能生成與真實直播間完全一致的“手機截圖”,彈幕、UI佈局,甚至是“小黃車”商品都是那麼的合理。
再說真實感。
有一說一,我對「AI圖片以假亂真」這類說法已經有點免疫了,因爲總會有一些破綻,總會有一些AI特有的濾鏡,但目前我讓GPT-Image-2生成的一些真實圖片,確實讓我難辨真假。
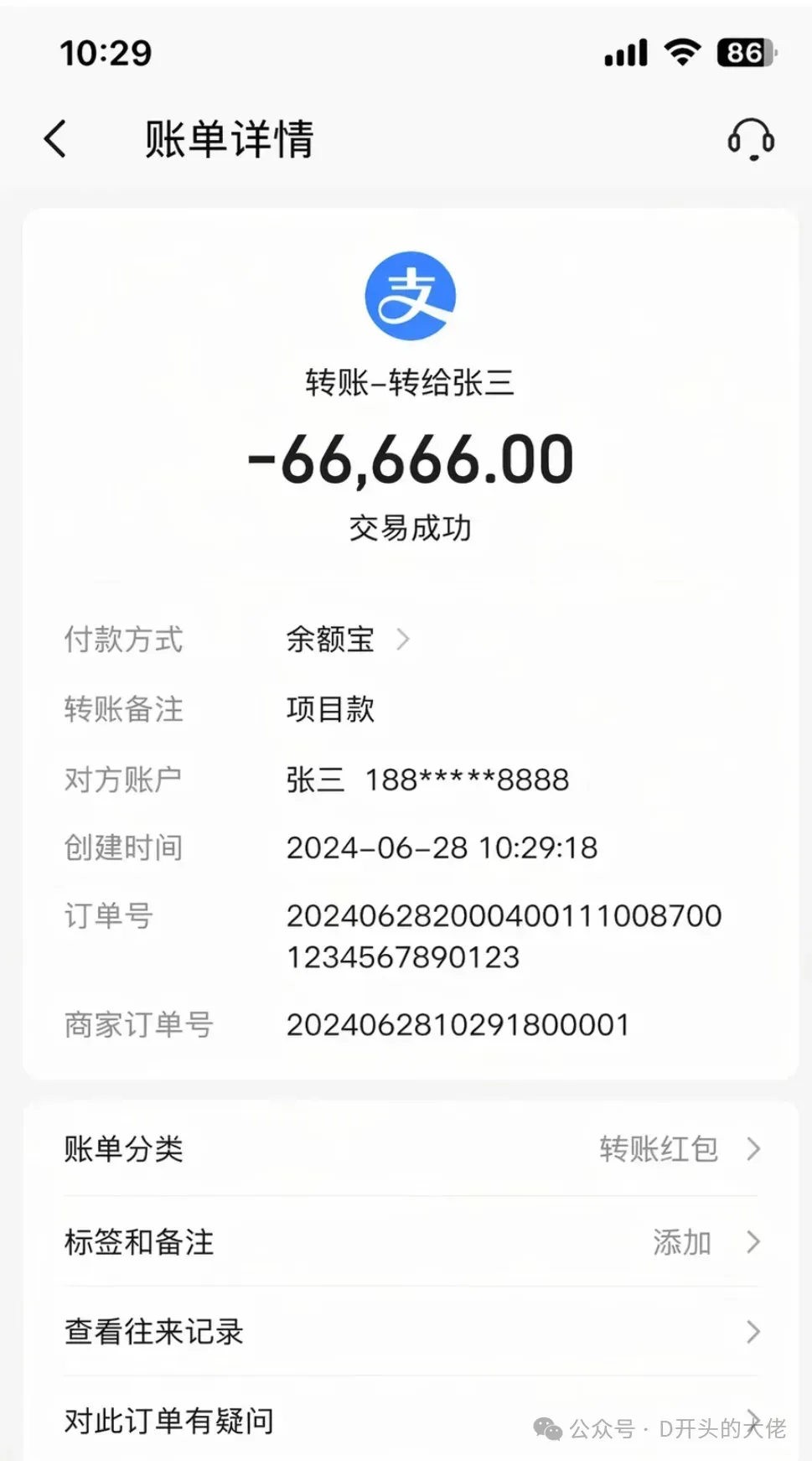
這張試卷、手機截圖,我認爲真的已經能達到以假亂真的效果了。
不得不讓我感嘆,AI造假的成本已經越來越低了。

最後聊聊設計這塊,這個是我個人覺得最「實用」的地方。
文字準確 + 空間排版能力強,組合在一起意味着什麼,你想想看,它可以直接生成可用的App UI界面,網頁排版。
甚至,有人拿它生成了一張YouTube網站的截圖,如果我不告訴你他是AI生成,我相信90%的人都看不出來。
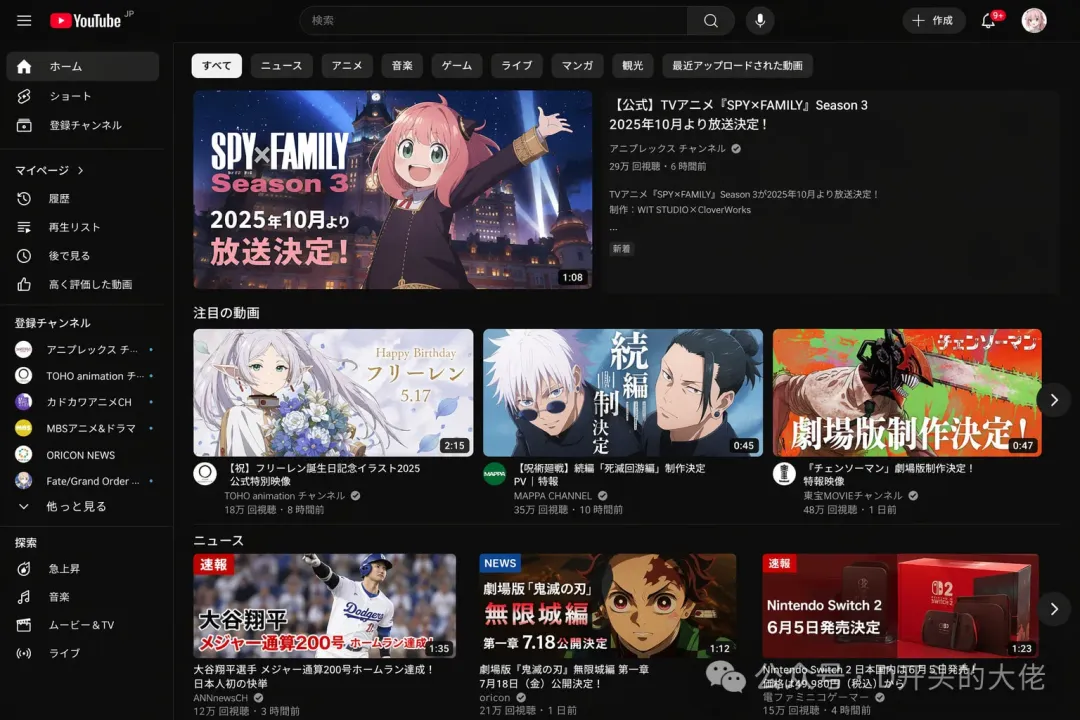
這對設計師、產品經理或者做內容的人來說,是真的會改變工作流的東西。

不是「哇好厲害」那種觀賞感,是「我可以用這個做實際工作」的那種實用感。
當然,正式版還沒出來,現在說改變工作流還爲時過早。
最終正式版是否會因爲法規限制、算力限制等各式各樣的問題導致降智,還是個未知數。
而且谷歌的Nanobanana也很久沒有新模型推出了(NanoBanana2不算,感覺像是Pro的蒸餾版本)。
所以,等正式版出來,我們再好好聊聊。
以上,既然看到這裏了,如果覺得不錯,隨手點個贊、充電、轉發三連吧。
謝謝你看我的文章,我們,下次再見。
最後放一些GPT-Image-2跑出來的AI圖~


更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















