正在灰度测试的GPT-Image-2,又一次突破了生图模型的极限。

注意:以下出现的所有图片,均为AI生成
上一次让我如此震惊生图大模型的还是NanoBananaPro。
在这之后,出的新模型实在太多了,Qwen、即梦等等。
每次都说「史诗级更新」,每次我都会去看看,然后大概率关掉浏览器,想着,还行,没什么颠覆性的。
这次不一样。
故事从一张前两天流传在国内互联网海报开始。
有人在大模型竞技场Arena。跑了一张原神 x 鸣潮 x 黑悟空 x 洛克王国世界 x 英雄联盟的联动海报。
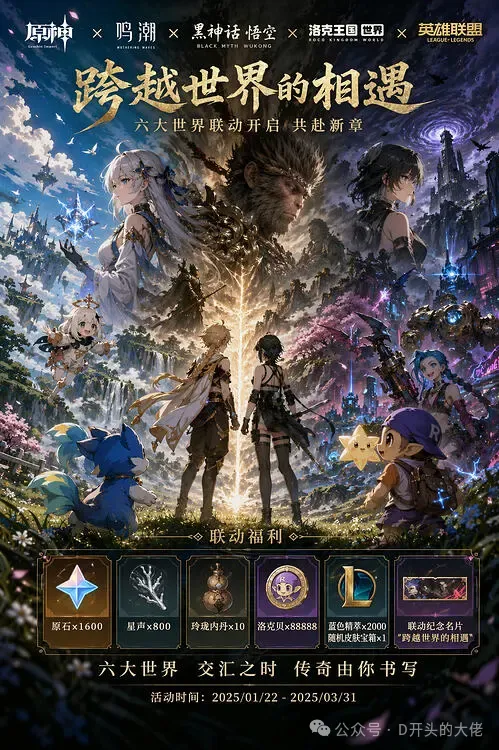
这张海报与Banana的风格明显不同,不管是图中元素、还是文字,还是对每个游戏元素的理解,都比Banana上了一个台阶。
有人开始说,这个跑出海报的duct-tape-2,其实是OpenAI还没公布的GPT-Image-2。
而有些用户也收到了ChatGPT的灰度测试,证实了这张图正是出自GPT-Image-2之手。
于是,我亲自在Arena抽了很多GPT-Image-2生成的结果后,想来和你分享一下我的使用感受。
先说文字。
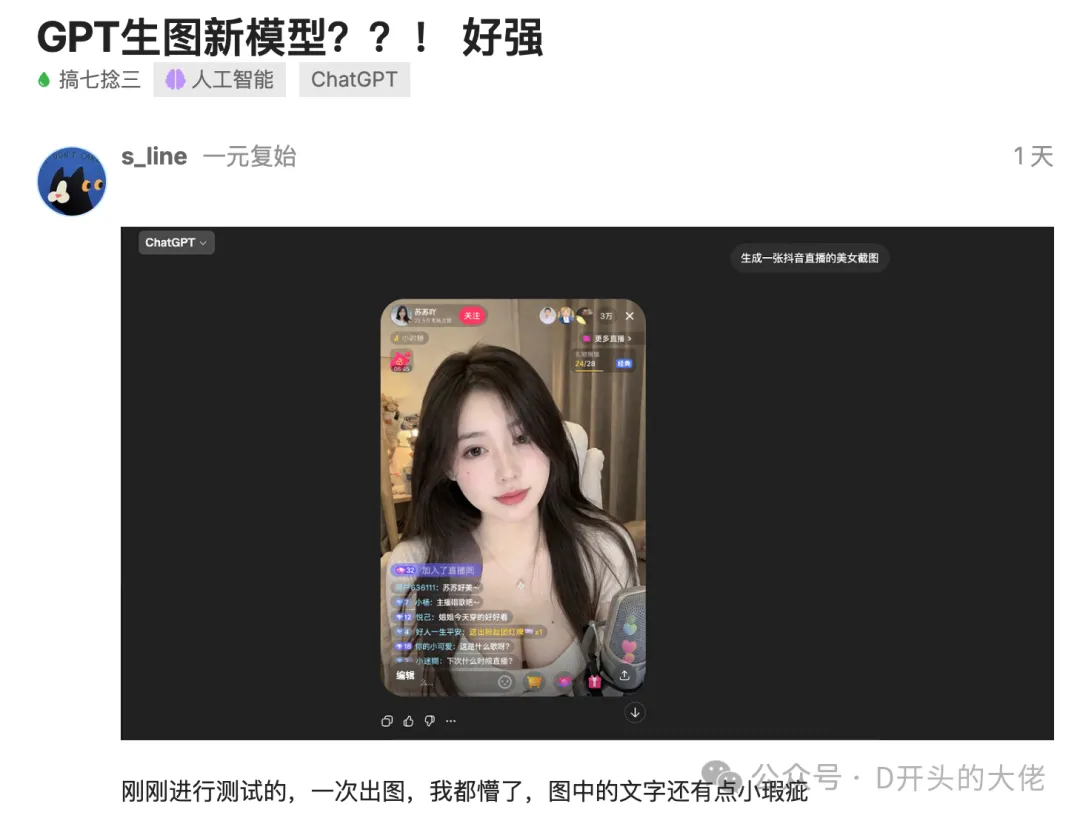
如果你用过BananaPro就知道,让它在图片里写字,总是会有一些瑕疵。标题和大一些的字还好一点,但碰到长句子或者密集排版,它还是会开始胡写,把字母拼错,把字体扭曲成火星文。

GPT-Image-2不一样。
你可以让它直接出一张海报,有密集的英文正文、副标题、大小写混排、标点全都在该在的地方。它不是在「模仿」文字的形状,它是真的知道这些字是什么意思,然后决定怎么排。
这里引用歸藏(guizang.ai)老师在X发布的他的AI产品CodePilot的宣传图。

而我让他生成了一张「GPT-Image-2在X上的用户评价」,90%以上的评价文字,头像、UI排版,全部都很和谐。并且评论内容是连贯正常的。
以前做这种东西,要么你得后期用PS手动贴字,要么你接受那个「AI出火星文」的视觉风险。
现在不需要了。
顺着这个继续说,它的「世界知识」也是让我比较意外的部分。
以前用生图模型做复杂场景,比如UI界面、医疗信息图表,模型经常会开始「发明创造」,出现不存在的结构,把遮挡关系搞反,把逻辑层次混在一起。
GPT-Image-2好像真的「懂」这些东西是怎么运作的。它不只是在拼贴素材,它有一个关于这个世界的基础认知,然后在这个认知上面生成内容。
比如用很简短的提示词“山姆奥特曼在抖音直播间带货OpenAI”
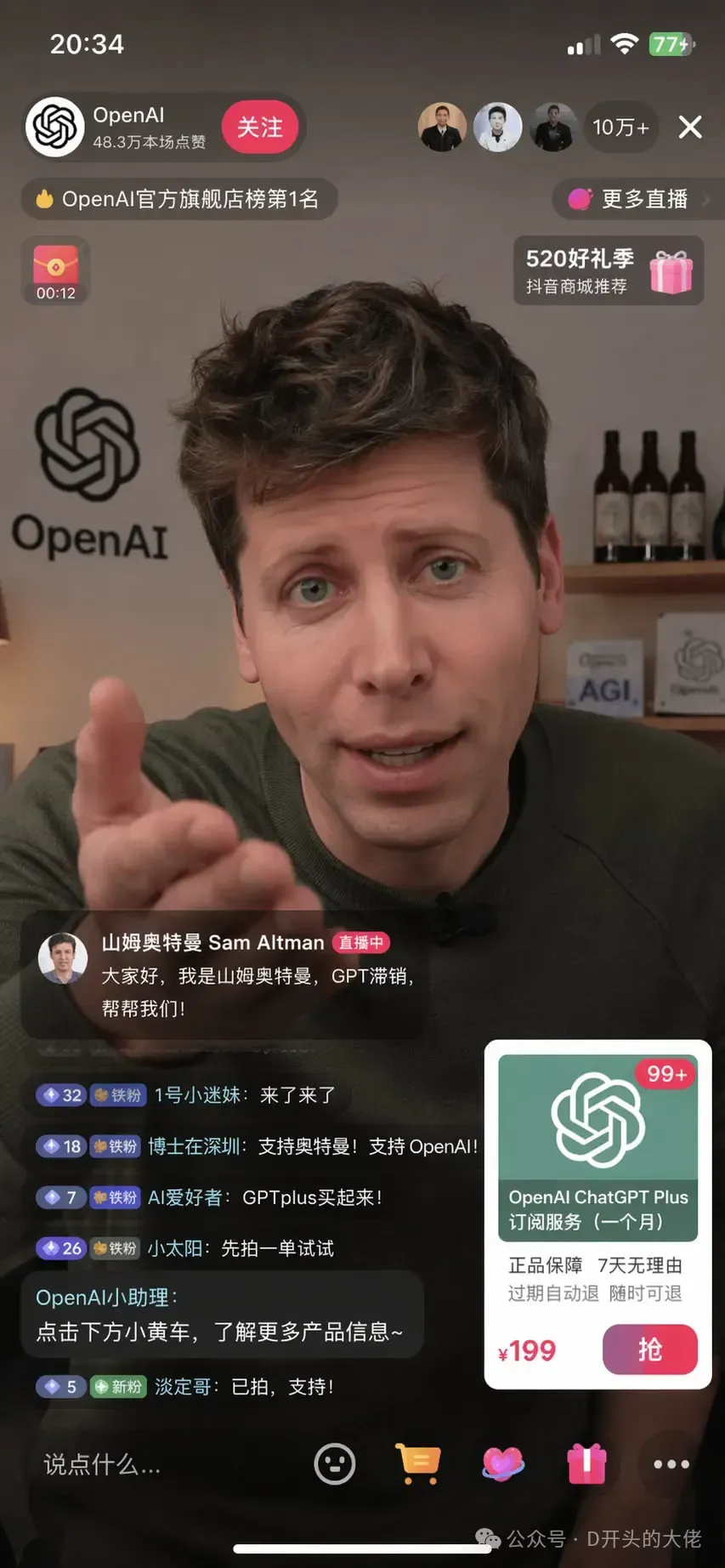
它就能生成与真实直播间完全一致的“手机截图”,弹幕、UI布局,甚至是“小黄车”商品都是那么的合理。
再说真实感。
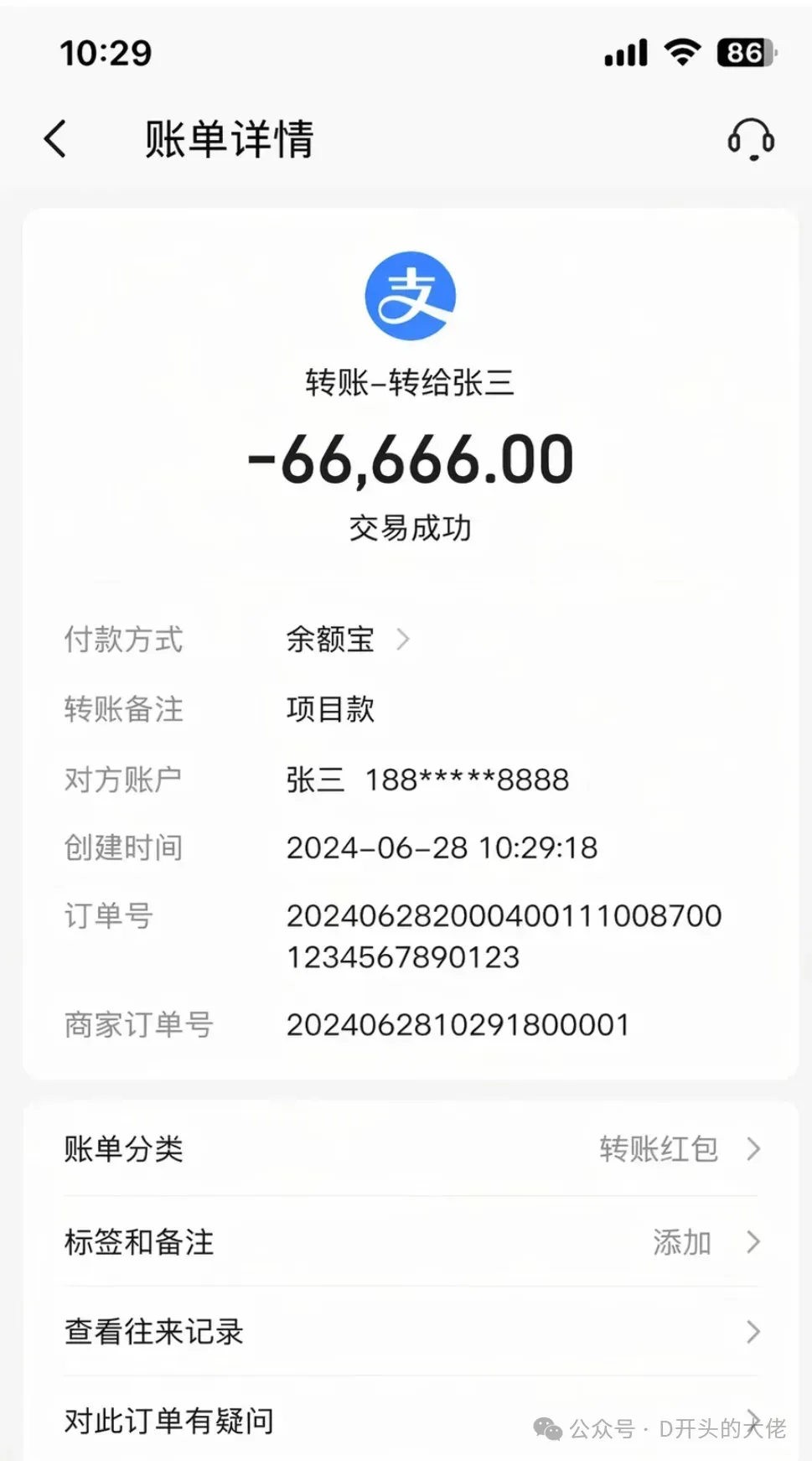
有一说一,我对「AI图片以假乱真」这类说法已经有点免疫了,因为总会有一些破绽,总会有一些AI特有的滤镜,但目前我让GPT-Image-2生成的一些真实图片,确实让我难辨真假。
这张试卷、手机截图,我认为真的已经能达到以假乱真的效果了。
不得不让我感叹,AI造假的成本已经越来越低了。

最后聊聊设计这块,这个是我个人觉得最「实用」的地方。
文字准确 + 空间排版能力强,组合在一起意味着什么,你想想看,它可以直接生成可用的App UI界面,网页排版。
甚至,有人拿它生成了一张YouTube网站的截图,如果我不告诉你他是AI生成,我相信90%的人都看不出来。
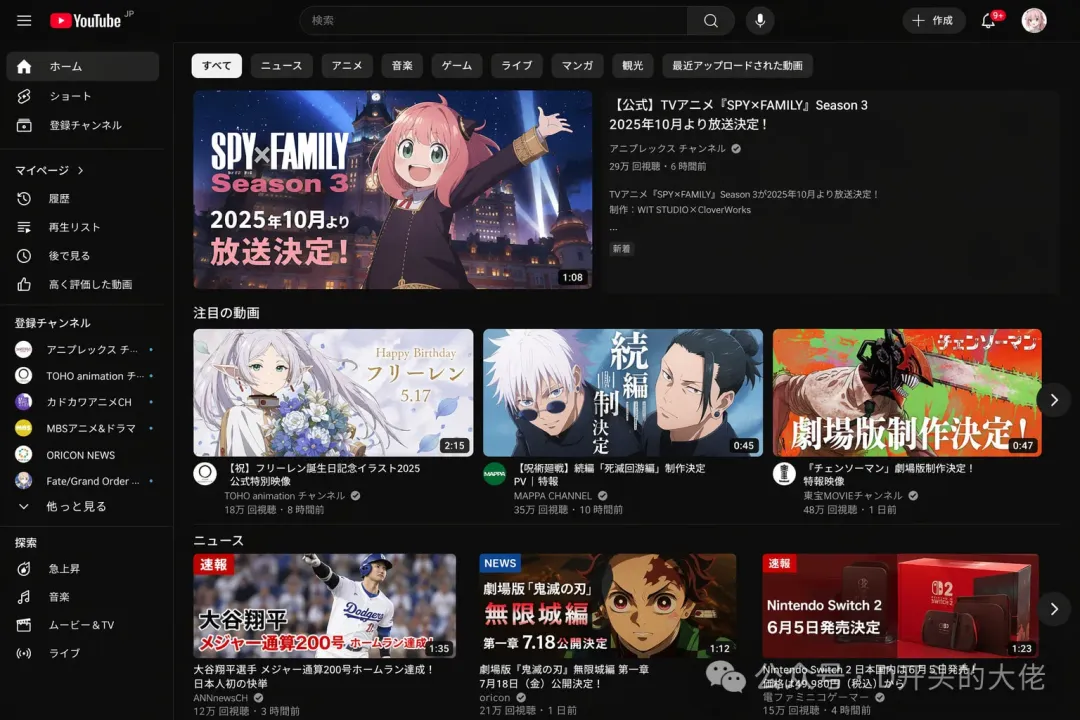
这对设计师、产品经理或者做内容的人来说,是真的会改变工作流的东西。

不是「哇好厉害」那种观赏感,是「我可以用这个做实际工作」的那种实用感。
当然,正式版还没出来,现在说改变工作流还为时过早。
最终正式版是否会因为法规限制、算力限制等各式各样的问题导致降智,还是个未知数。
而且谷歌的Nanobanana也很久没有新模型推出了(NanoBanana2不算,感觉像是Pro的蒸馏版本)。
所以,等正式版出来,我们再好好聊聊。
以上,既然看到这里了,如果觉得不错,随手点个赞、充电、转发三连吧。
谢谢你看我的文章,我们,下次再见。
最后放一些GPT-Image-2跑出来的AI图~


更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com













