在今年年初的 DeepSeek 開源大模型給大家驚喜之後,似乎一切都變得平淡乏味了起來。
大家原本以爲 2025 年的風口會繼續在閉源巨頭手裏打轉,結果一個意料之外的名字突然冒頭了:
Kimi K2 Thinking
它既不開發佈會,也不搞長篇科普,就這麼悄無聲息上線,然後在各種測試榜單上刷出了不少亮眼成績。
不少研究者看到成績單後,第一反應不是驚喜,而是驚訝:居然是開源模型?

以前開源和閉源的差距,很像學生成績單上的兩道分割線:
基礎題過得去,但一到推理題就腦溢血;能寫詩卻做不對三角函數;能續寫奇幻小說,但真實項目一上手就手忙腳亂。
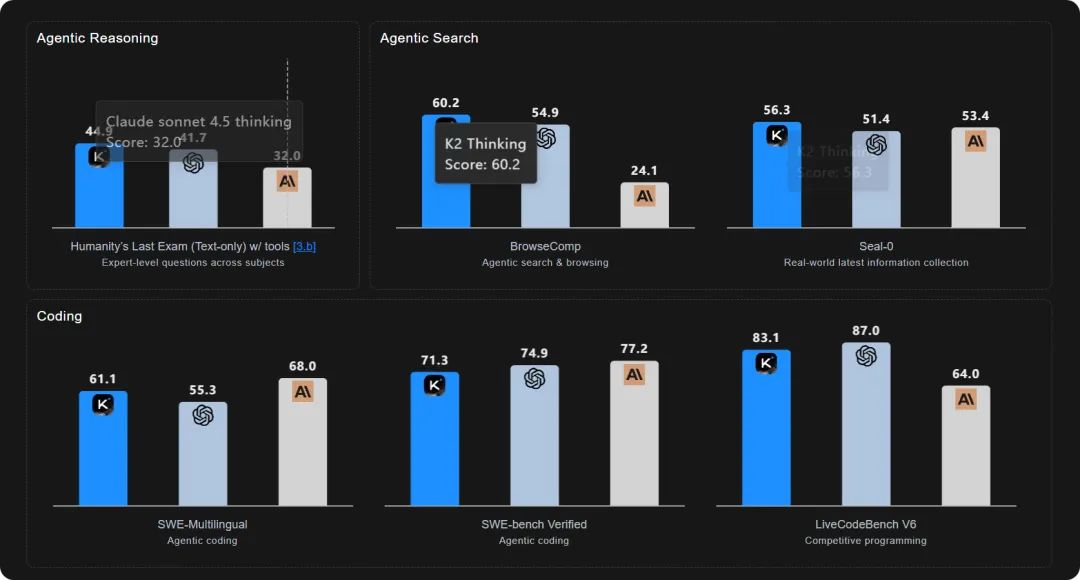
現在,K2 Thinking 在人類最後的考試 HLE(允許使用工具)裏幹到了 44.9
在複雜搜索基準 BrowseComp 上幹到 60.2。
在智能體工具使用 τ²-Bench Telecom 幹到 93。
更要命的是,這些分數,已經壓住 GPT-5 和 Claude Sonnet 4.5(Thinking)。
閉源陣營該怎麼跟投資人解釋這事?說自己是“發揮失常”嗎?
這玩意的能力本質是:
不只會“想”,而且會“幹活”,還能邊幹邊想、邊想邊查,就好像給模型塞了一個離線版的勤奮小助手,它會自己去原網頁驗證資料,會在答案不夠清晰時主動再搜索一輪,會爲了排錯寫代碼並跑測試日誌。
你給它一個模糊的任務,它會自己先拆需求,再試錯,再修正,飆幾百輪工具調用也不吭聲,不會像某些 AI 一樣寫兩行代碼就喊“我累了”。
(上下滑動查看完整對話)

架構方面,月之暗面也下了功夫:
支持 INT4 原生推理,這點估計是專門對國產卡的專門優化。
INT4 提升生成速度兩倍,還能把省下來的硬件成本偷偷轉化爲“再想多幾句”的算力,挺懂工程的。
當然,光有數據吹牛沒意思,那必須來點真實任務。
爲了驗證它的 Agent 能力,我們換了幾種不同類型的任務,儘量模擬開發者真實會遇到的情況,而不是單純讓它“秀肌肉”。
我們還試了面向真實產出的產品小模塊:
讓它設計一個小型權限系統的 API,並補上測試樣例;
它沒有隻寫接口,還順帶檢查邊界場景,各種可能的安全風險及應對措施,同時還補充錯誤返回邏輯等。
順便插一句,創意寫作、學術總結這些基礎能力,它也順帶升了一級。
如果你給它一堆混亂的靈感片段,它能幫你整理成一篇讀者能看完、編輯能過稿、你還能假裝自己很厲害的文章,這對很多博主來說簡直是續命藥。
再說到實際應用層面其實更有意思:
OpenAI 卷通用能力、DeepSeek 捲開源生態、Cursor 卷工具體驗
而月之暗面則清醒得像旁觀者:
在 AI 編程這個賽道上,光有模型不夠,光有工具也不夠,最強組合應該是“模型+工具鏈+商業化體驗”一體化。
所以他們纔會推什麼 KFC(Kimi For Coding)套餐、Kimi CLI(前段時間推出的),全家桶已經不是產品,而是“能幫你認真交付”的一個完整工作流。
還有一個得聊的是,是月之暗面這個公司在行業地位上的對比差:
它在國內算是“六小龍”之一,
但在全球範圍只相當於 OpenAI 估值的 0.5%,是 Anthropic 的 2%。
就這樣的體量,卻把全球最難的兩個方向——推理和智能體直接做出了 SOTA,不是國內 SOTA,也不是開源的 SOTA,而是全面 SOTA!
開源協議還是 MIT,最寬鬆的開源協議之一。
這條新聞如果放在歐美那邊的 AI 圈子怕不是能吹半年。
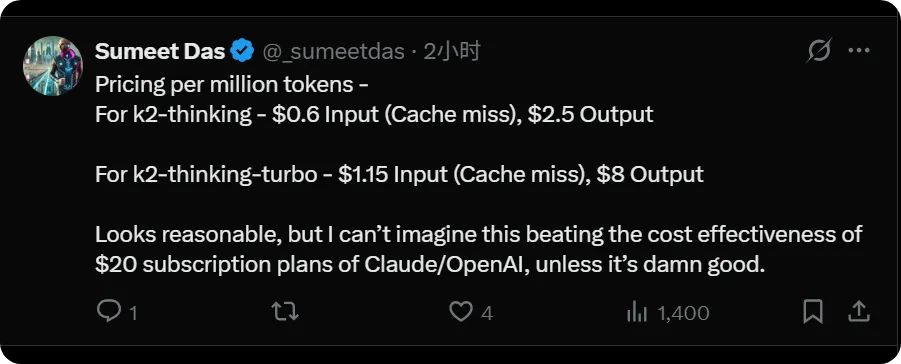
現在的問題來了:
我們討論開源追閉源,到底追的是什麼?
是分數、參數、顯卡堆出來的肌肉?
還是哪個模型先學會“自己去查資料、自己改代碼、自己負責正確性”這種真正能釋放生產力的能力?
如果答案是後者,
那閉源大廠可能真的要緊張了(這裏再次點名一位“開源都是智商稅的”的不知名人士)。
因爲開源模型不僅追上來了,還開始不斷挑戰一衆閉源模型的“看家本領”。
閉源模型的安全感,正在由國內這些開源的選手一錘子一錘子敲碎,不斷崩塌。
當 Kimi K2 Thinking 站上 SOTA 的時候,我們不得不思考一個問題: 到底是誰在追趕誰?

我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com




![不清楚是不是站崗站傻了,想不清楚去年發生了什麼,大事件記得[cube_捂臉哭]](https://imgheybox1.max-c.com/bbs/2026/06/28/bccafc3417454fb6e3871cef41a3b410.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)










