本人已發佈微調大模型Qwen3-1.7B-MT-en2zh-Gungeon,這是一個專門針對遊戲《挺進地牢》(Enter the Gungeon)文本翻譯任務微調的模型,以 Qwen3-1.7B 爲基線模型,專注於提升相關語境下的翻譯質量。
模型訓練不易,本人投入了大量人力財力,發佈供大家免費學習使用,請多多支持點贊盒電。
模型優勢
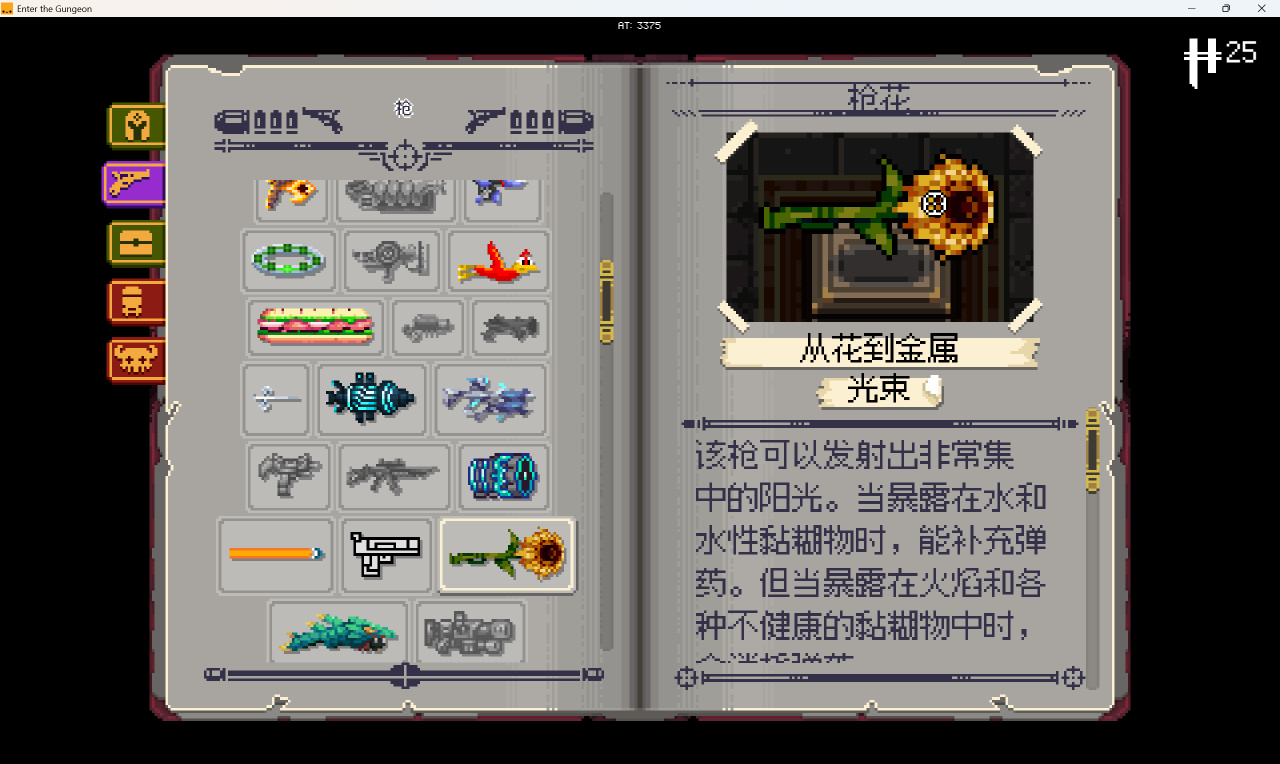
且1.7B模型經過量化,在需要較低顯存和具有較快推理速度的同時仍保持較高的翻譯質量和流暢度,這意味着可以在本地運行和推理,佔用僅約2GB顯存。配合上AutoTranslate模組,可以實現完全本地,完全免費,兼顧速度的遊戲內翻譯。最重要的是,經過槍牢語料的訓練,翻譯結果接近槍牢風格。例如以下爲Gunflower的翻譯:
使用前的注意事項
優先選擇用WSL進行llama.cpp服務的搭建,它比Windows直接使用llama.cpp性能更好。需要注意的是,WSL開啓後會啓動Windows的虛擬機平臺,請權衡利弊,介意的可以用Windows直接使用llama.cpp,但是顯存優化沒那麼好。
下面會安裝WSL、CUDA Toolkit、編譯llama.cpp、使用Qwen3-1.7B-MT-en2zh-Gungeon進行翻譯,確保硬盤有至少15GB空餘空間,顯存至少4GB。下面作爲演示,以NVIDIA顯卡用CUDA加速。其他顯卡如AMD要使用ROCm,Intel要用IPEX-LLM加速,否則純CPU推理速度慢。
教程開始
首先在Windows更新你的顯卡驅動,啓用WSL,在WSL上安裝好Ubuntu,以Ubuntu22.04爲例。這步不贅述,網絡上教程一大把。
進入WSL-Ubuntu,安裝一些必要的庫:
sudo apt update
sudo apt install gcc g++ cmake -y
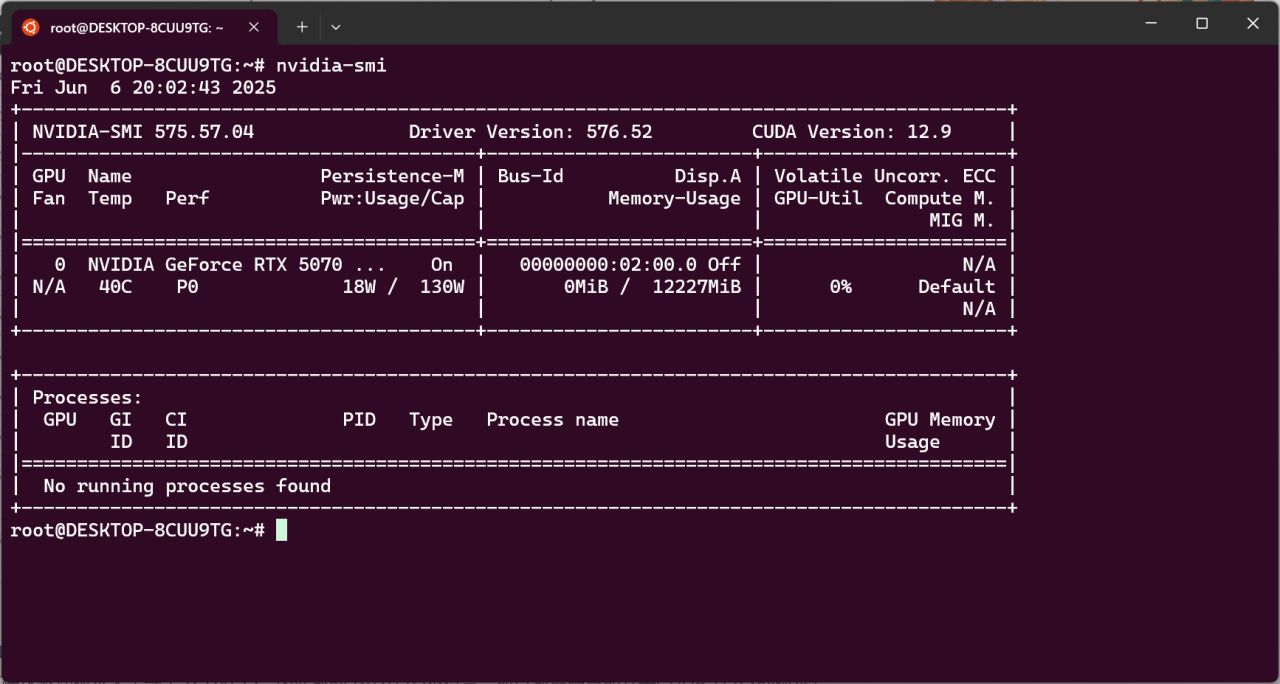
下面安裝CUDA Toolkit,輸入nvidia-smi回車,可以看到支持的CUDA版本,你的版本可能和示例不同。
在https://developer.nvidia.com/cuda-toolkit-archive下載WSL的CUDA Toolkit。選擇你上面顯示的CUDA版本,選擇WSL_Ubuntu的deb(network),會出現對應的安裝命令。
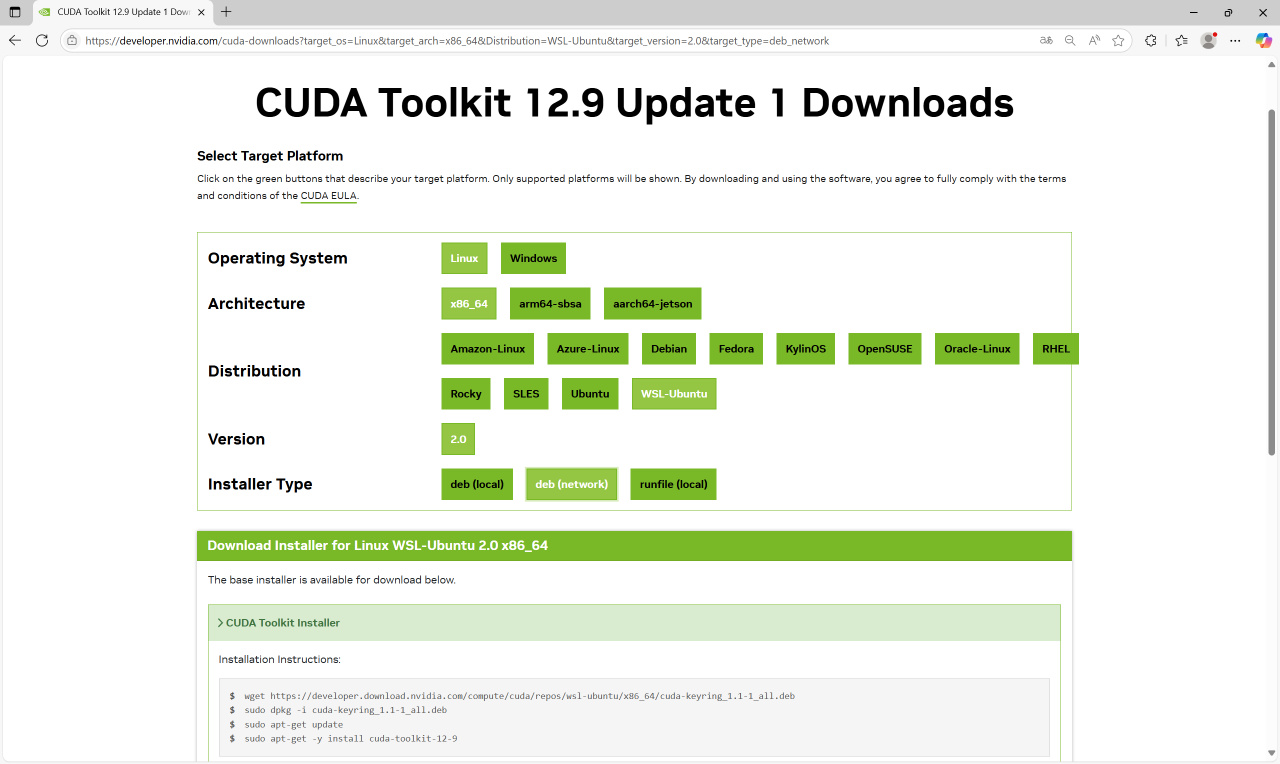
仿照上圖在WSL-Ubuntu命令行裏輸入上圖中的命令的【前三行】。
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
注意,因爲我們不需要完整的toolkit,那太大了,所有最後一行安裝toolkit要替換爲下面這行命令,可以節省約10GB存儲空間。
sudo apt-get install -y cuda-nvcc-<cuda版本> cuda-runtime-<cuda版本> libcublas-dev-<cuda版本>
<cuda版本>是版本,和你的網頁中一致,我這裏是12-9:
sudo apt-get install -y cuda-nvcc-12-9 cuda-runtime-12-9 libcublas-dev-12-9
等待安裝完畢。
安裝完畢輸入以下命令進行環境變量添加。
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
source ~/.bashrc
接下來進行llama.cpp的編譯。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
mkdir build
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=OFF
cmake --build build --config Release --parallel 4
cd build
make install
echo "/usr/local/lib" | sudo tee /etc/ld.so.conf.d/llama.conf
sudo ldconfig
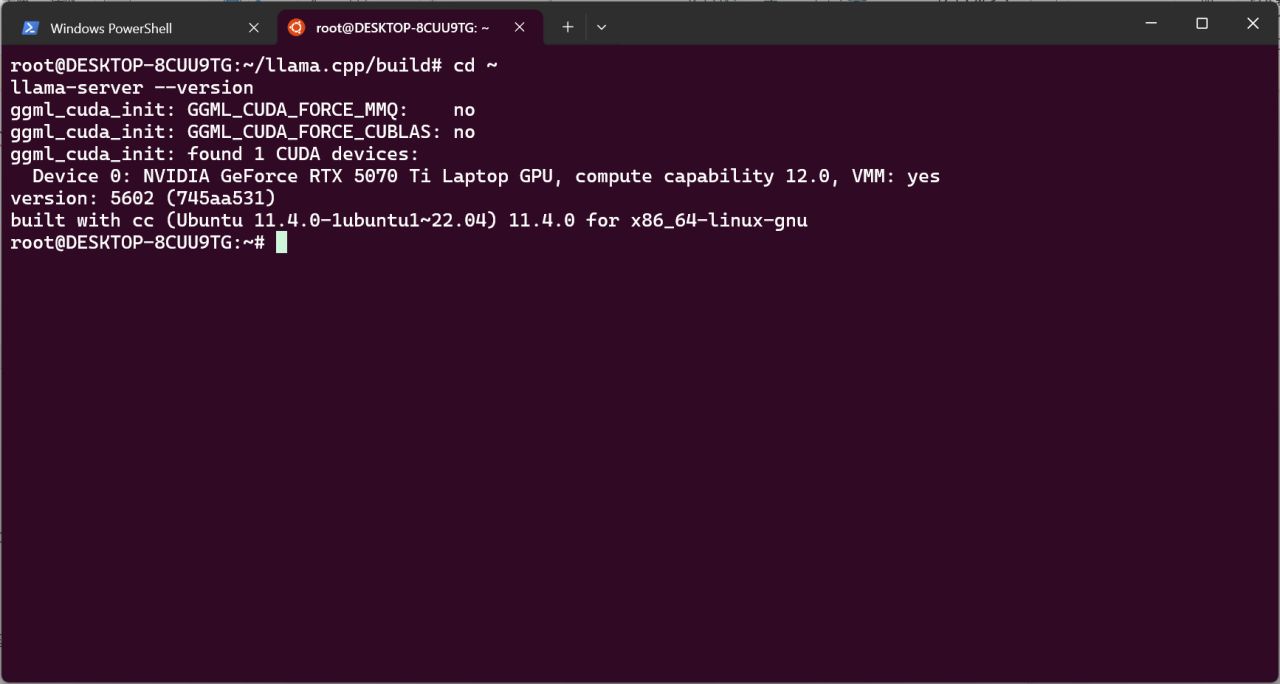
等待編譯結束。此後執行命令,會看到llama-server正常顯示版本。
cd ~
llama-server --version
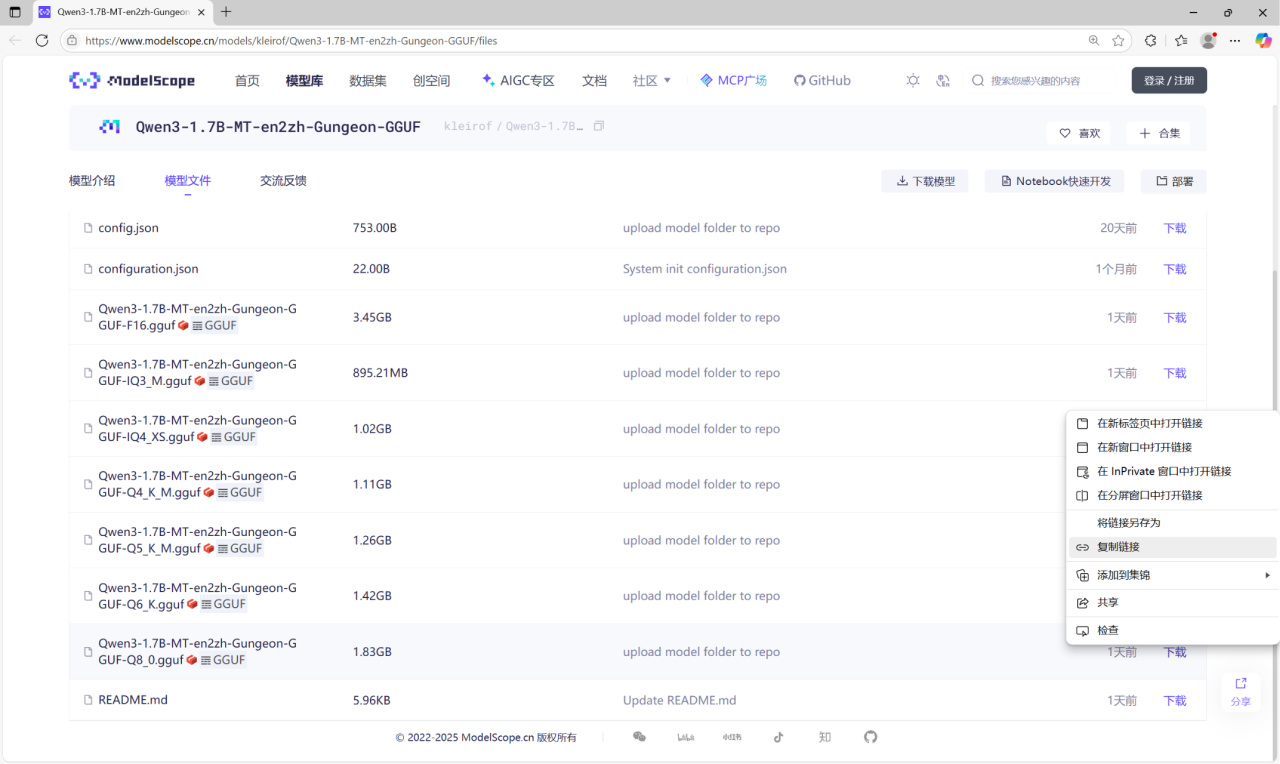
下面下載Qwen3-1.7B-MT-en2zh-Gungeon模型。量化模型發佈於ModelScope:
https://www.modelscope.cn/models/kleirof/Qwen3-1.7B-MT-en2zh-Gungeon-GGUF/files
不同量化程度的模型具有不同的精度和推理速度,此處以Q8_0量化爲例。下面把模型放到WSL-Ubuntu中。在模型的下載處右鍵 - 複製鏈接。
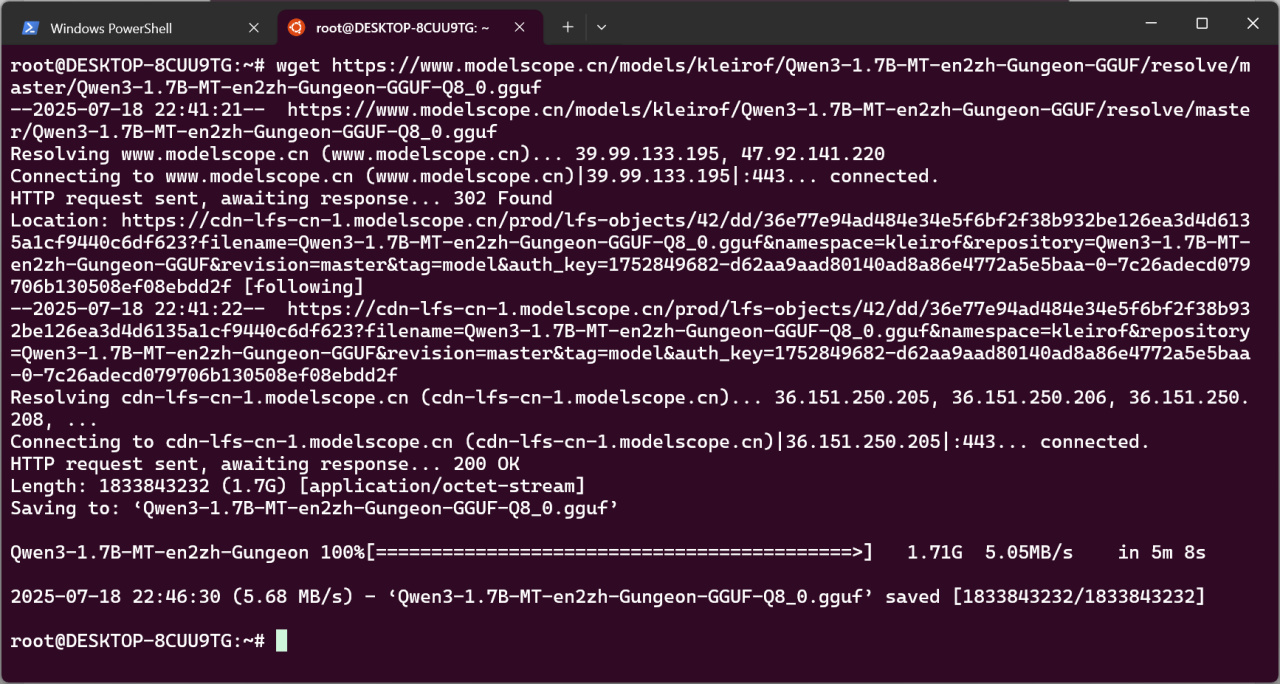
在WSL輸入命令:
cd ~
wget <複製的鏈接>
等待下載完成。
這時就可以啓動推理服務了。在WSL命令行輸入:
llama-server -m <模型路徑> --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
此處案例模型名爲Qwen3-1.7B-MT-en2zh-Gungeon-GGUF-Q8_0.gguf,故命令爲:
llama-server -m Qwen3-1.7B-MT-en2zh-Gungeon-GGUF-Q8_0.gguf --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
類似這樣,就說明模型啓動成功。
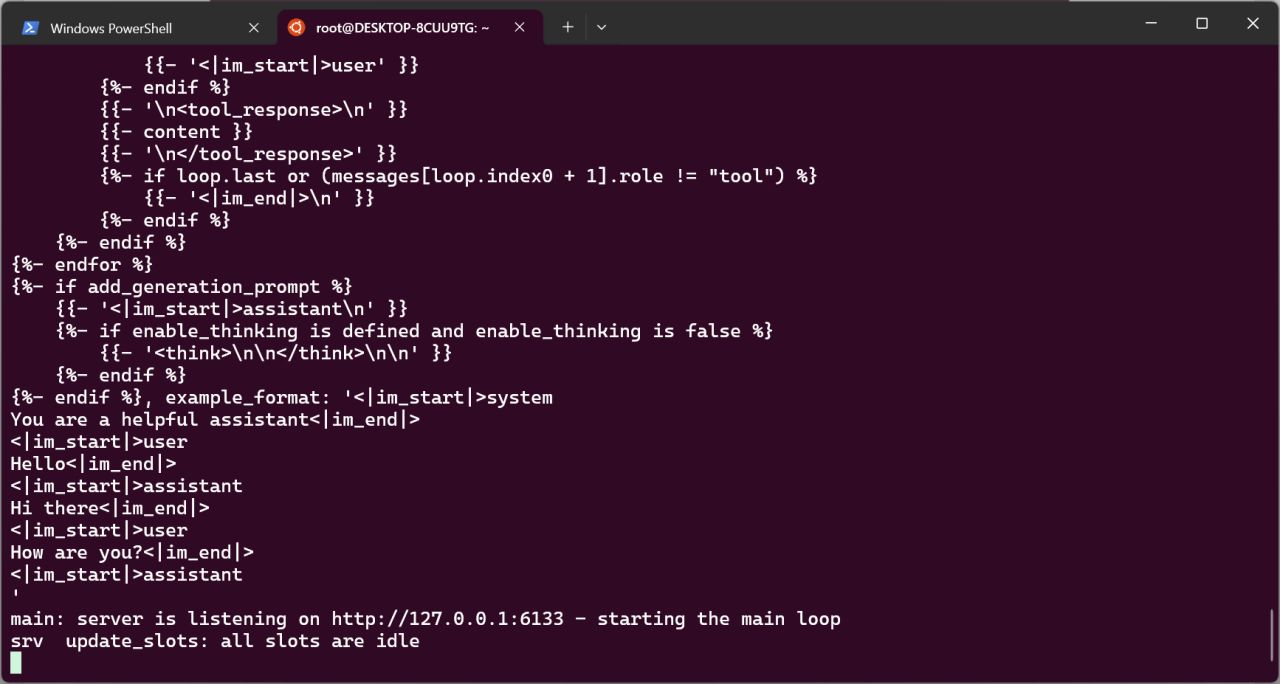
接下來設置Auto Translate模組,模組發佈貼見我的主頁,請閱讀模組聲明並選擇是否同意。
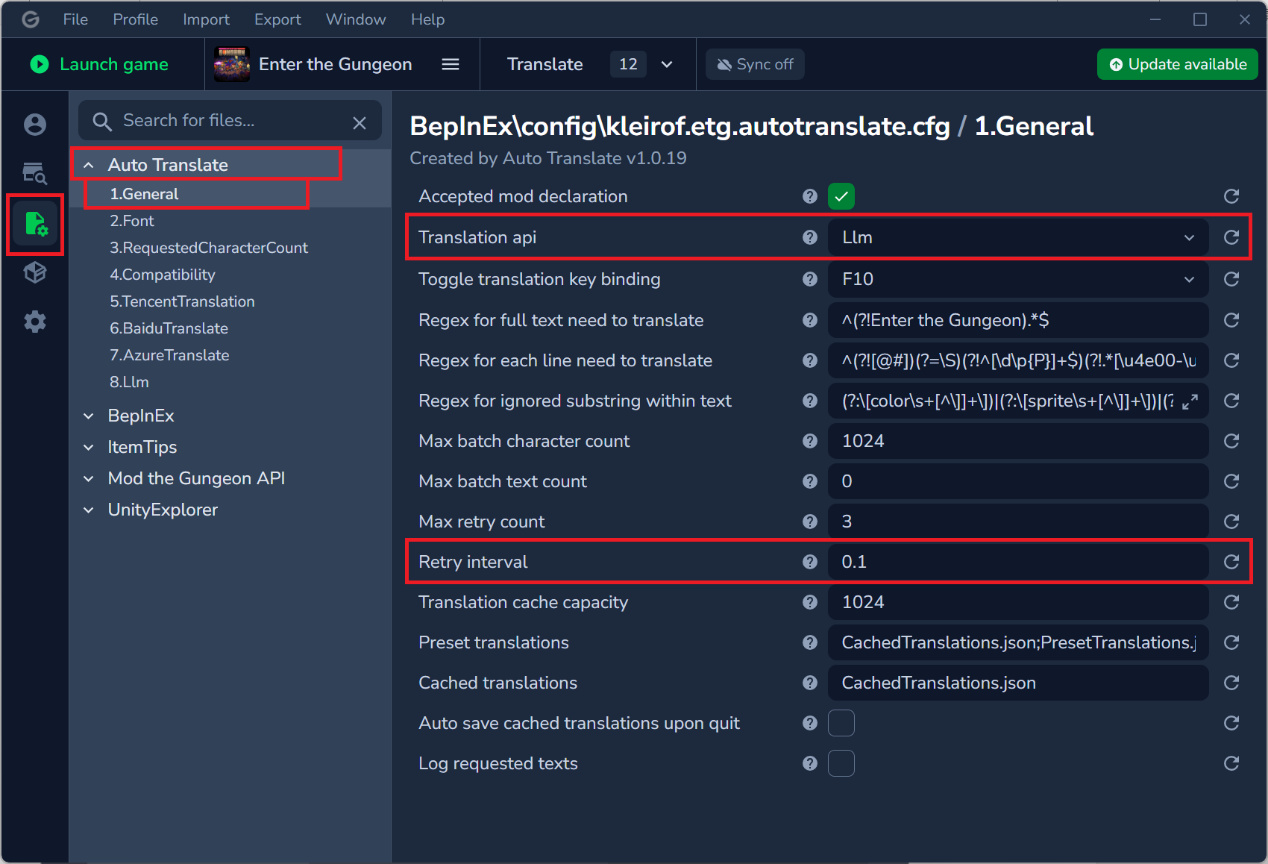
在模組管理器中,此處以Gale管理器爲例,在配置- Auto Translate - General,選擇Translation api爲Llm,下方Retry interval爲0.1。
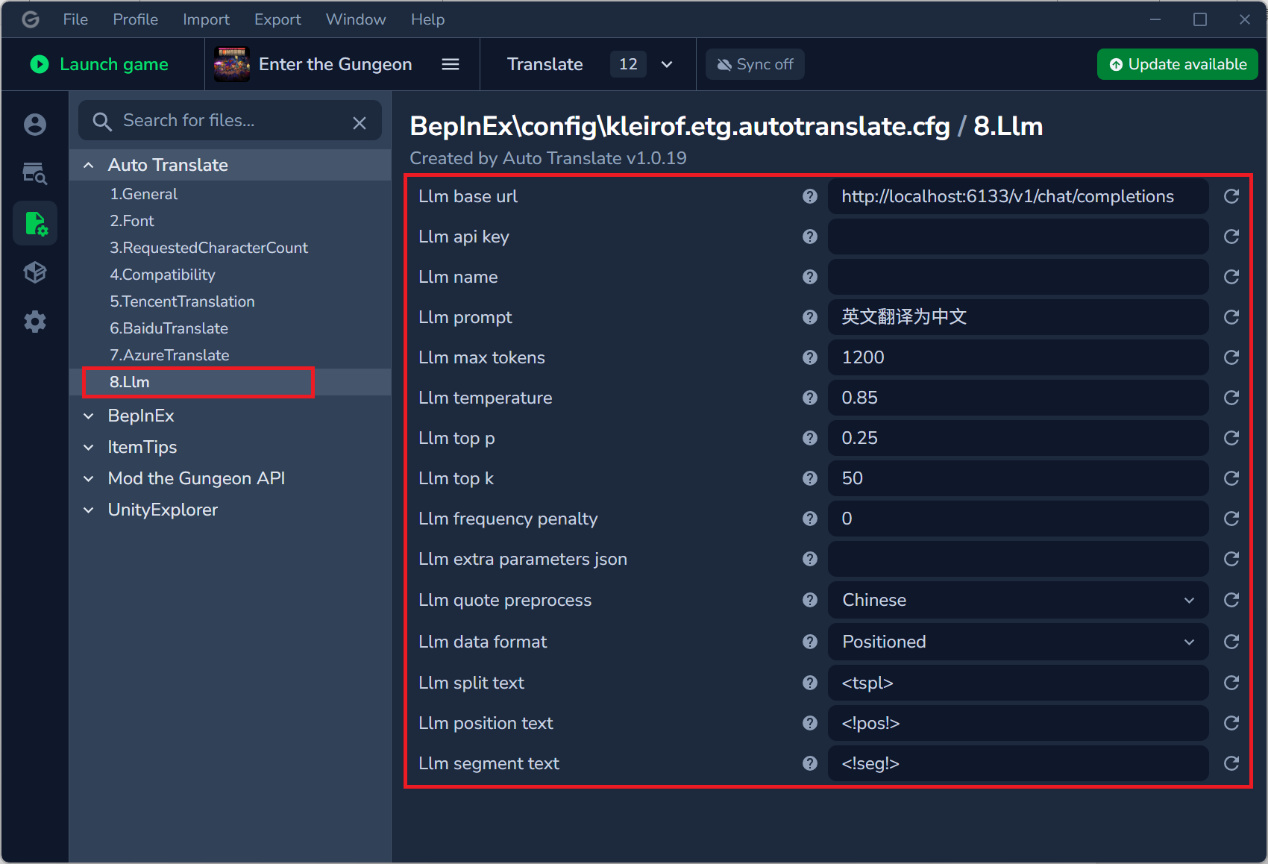
選擇Llm,設置如下:
Base url爲:http://localhost:6133/v1/chat/completions
Api key留空
Name留空
Prompt爲:英文翻譯爲中文
Max tokens爲:1200
Temperature爲:0.85
Top p爲:0.25
Top k爲:50
Frequency penalty爲:0
Extra parameters json留空
Quote preprocess爲:Chinese
Data format爲:Positioned
Llm position text爲:<!pos!>
Llm segment text爲:<!seg!>
啓動遊戲即可。
之後再次使用時,只需要開啓WSL並輸入上面的llama-server命令:
llama-server -m <模型路徑> --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
接着啓動遊戲即可。
附
以下爲擴展(可選):
由於nvcc在編譯後不是必要的,可以卸載以節省空間。
sudo apt remove --purge cuda-nvcc-12-9 libcublas-dev-12-9 -y
sudo apt autoremove -y
sudo apt autoclean
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















