本人已发布微调大模型Qwen3-1.7B-MT-en2zh-Gungeon,这是一个专门针对游戏《挺进地牢》(Enter the Gungeon)文本翻译任务微调的模型,以 Qwen3-1.7B 为基线模型,专注于提升相关语境下的翻译质量。
模型训练不易,本人投入了大量人力财力,发布供大家免费学习使用,请多多支持点赞盒电。
模型优势
且1.7B模型经过量化,在需要较低显存和具有较快推理速度的同时仍保持较高的翻译质量和流畅度,这意味着可以在本地运行和推理,占用仅约2GB显存。配合上AutoTranslate模组,可以实现完全本地,完全免费,兼顾速度的游戏内翻译。最重要的是,经过枪牢语料的训练,翻译结果接近枪牢风格。例如以下为Gunflower的翻译:
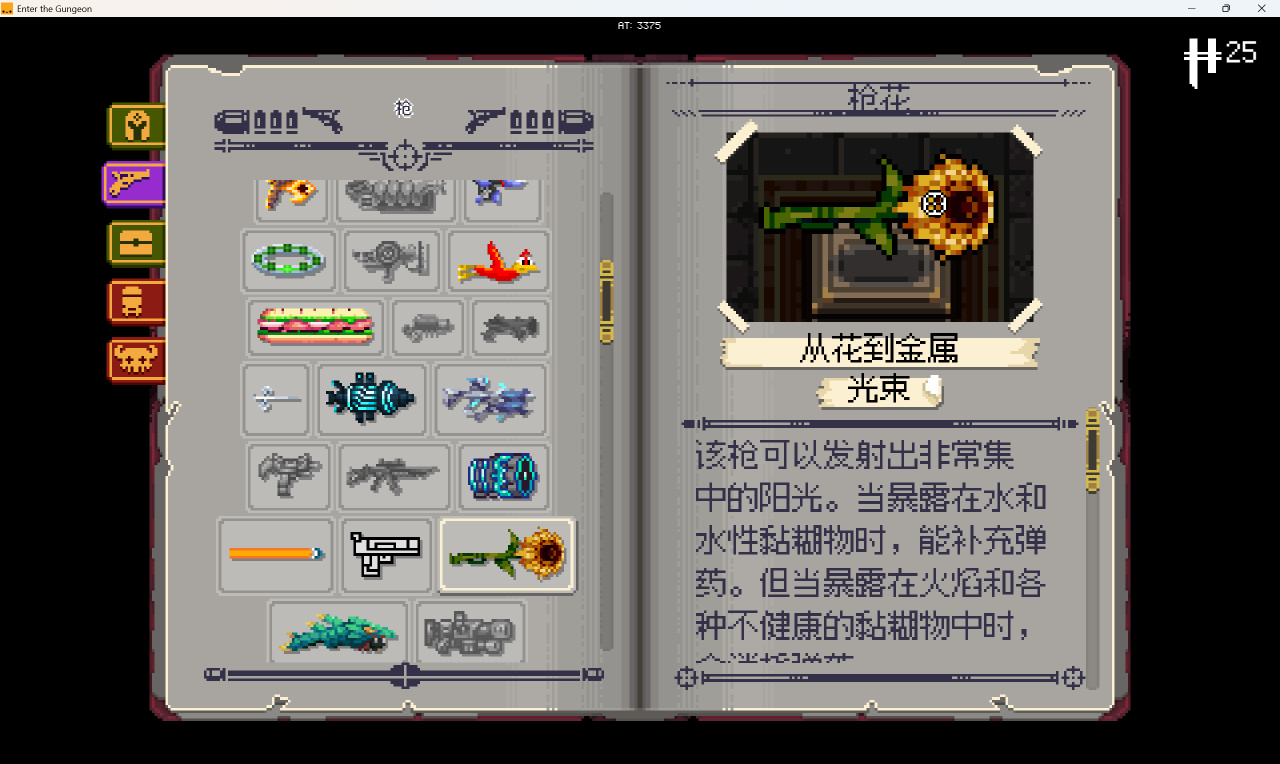
使用前的注意事项
优先选择用WSL进行llama.cpp服务的搭建,它比Windows直接使用llama.cpp性能更好。需要注意的是,WSL开启后会启动Windows的虚拟机平台,请权衡利弊,介意的可以用Windows直接使用llama.cpp,但是显存优化没那么好。
下面会安装WSL、CUDA Toolkit、编译llama.cpp、使用Qwen3-1.7B-MT-en2zh-Gungeon进行翻译,确保硬盘有至少15GB空余空间,显存至少4GB。下面作为演示,以NVIDIA显卡用CUDA加速。其他显卡如AMD要使用ROCm,Intel要用IPEX-LLM加速,否则纯CPU推理速度慢。
教程开始
首先在Windows更新你的显卡驱动,启用WSL,在WSL上安装好Ubuntu,以Ubuntu22.04为例。这步不赘述,网络上教程一大把。
进入WSL-Ubuntu,安装一些必要的库:
sudo apt update
sudo apt install gcc g++ cmake -y
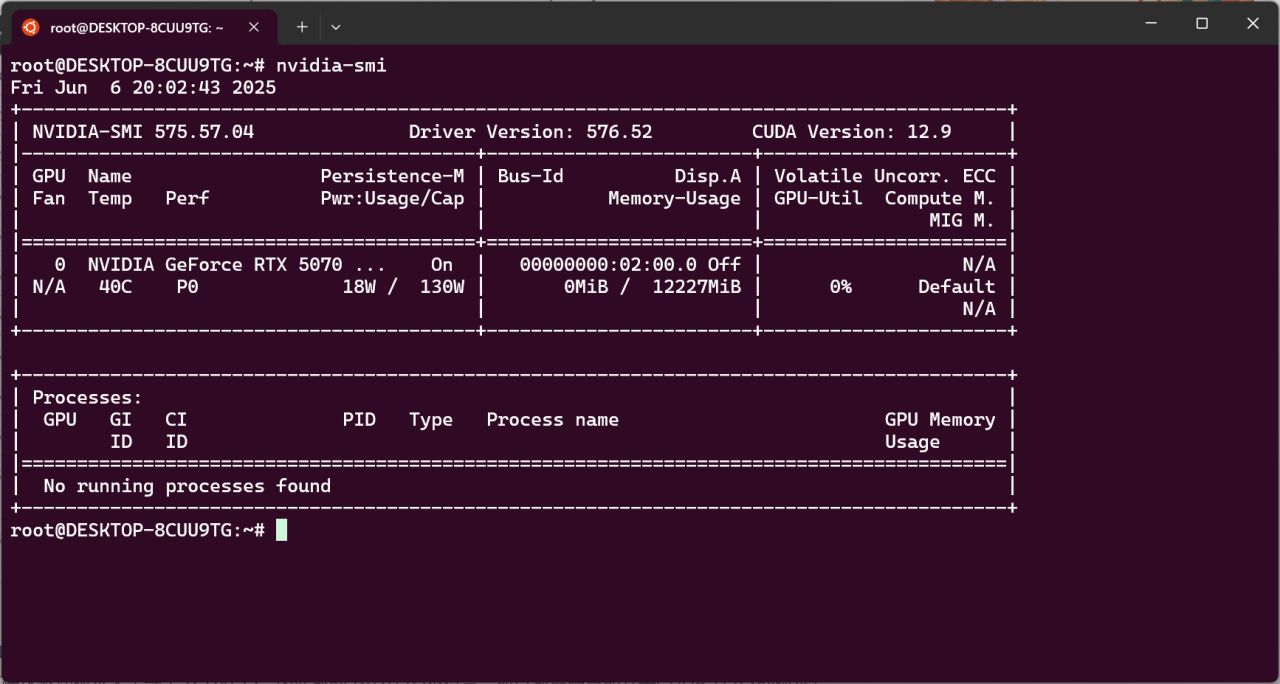
下面安装CUDA Toolkit,输入nvidia-smi回车,可以看到支持的CUDA版本,你的版本可能和示例不同。
在https://developer.nvidia.com/cuda-toolkit-archive下载WSL的CUDA Toolkit。选择你上面显示的CUDA版本,选择WSL_Ubuntu的deb(network),会出现对应的安装命令。
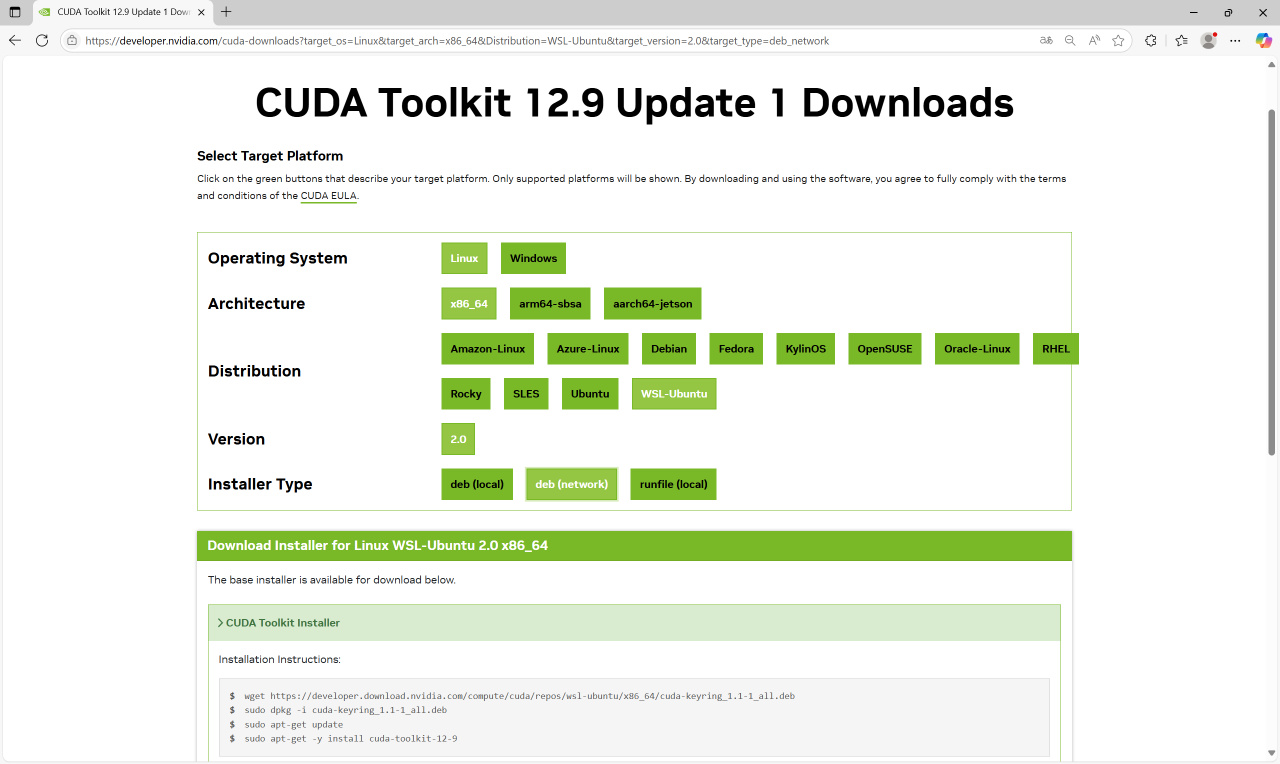
仿照上图在WSL-Ubuntu命令行里输入上图中的命令的【前三行】。
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
注意,因为我们不需要完整的toolkit,那太大了,所有最后一行安装toolkit要替换为下面这行命令,可以节省约10GB存储空间。
sudo apt-get install -y cuda-nvcc-<cuda版本> cuda-runtime-<cuda版本> libcublas-dev-<cuda版本>
<cuda版本>是版本,和你的网页中一致,我这里是12-9:
sudo apt-get install -y cuda-nvcc-12-9 cuda-runtime-12-9 libcublas-dev-12-9
等待安装完毕。
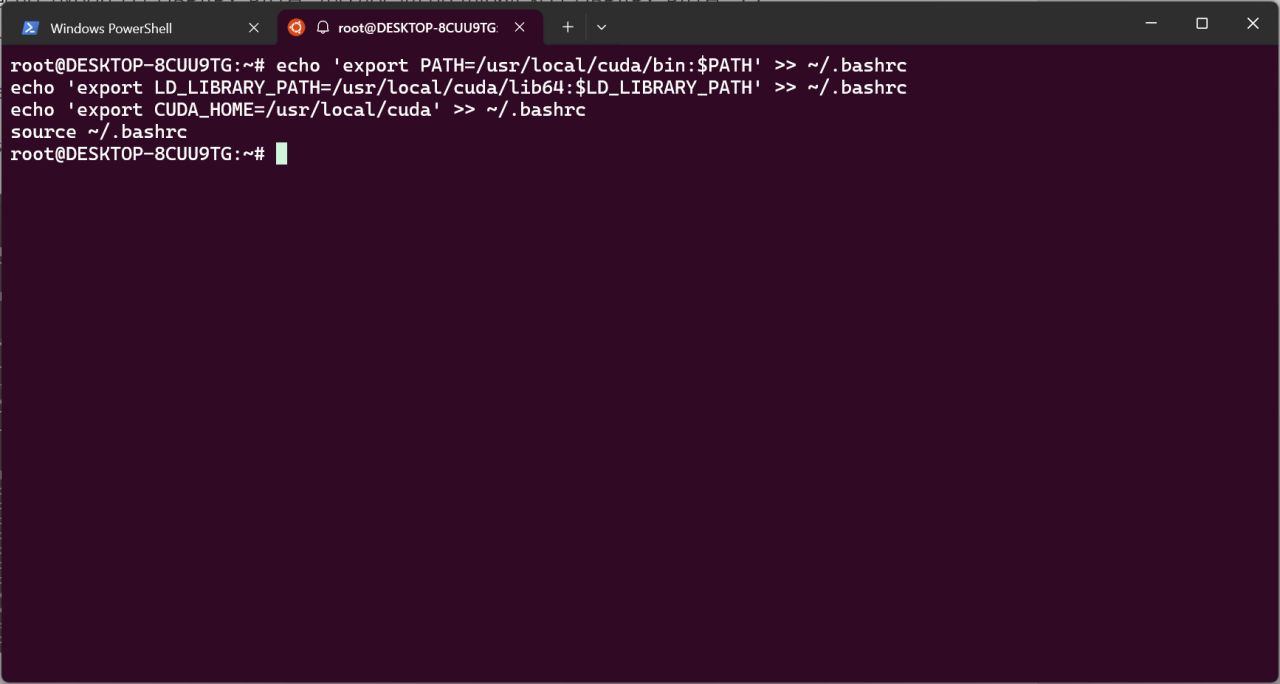
安装完毕输入以下命令进行环境变量添加。
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
source ~/.bashrc
接下来进行llama.cpp的编译。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
mkdir build
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=OFF
cmake --build build --config Release --parallel 4
cd build
make install
echo "/usr/local/lib" | sudo tee /etc/ld.so.conf.d/llama.conf
sudo ldconfig
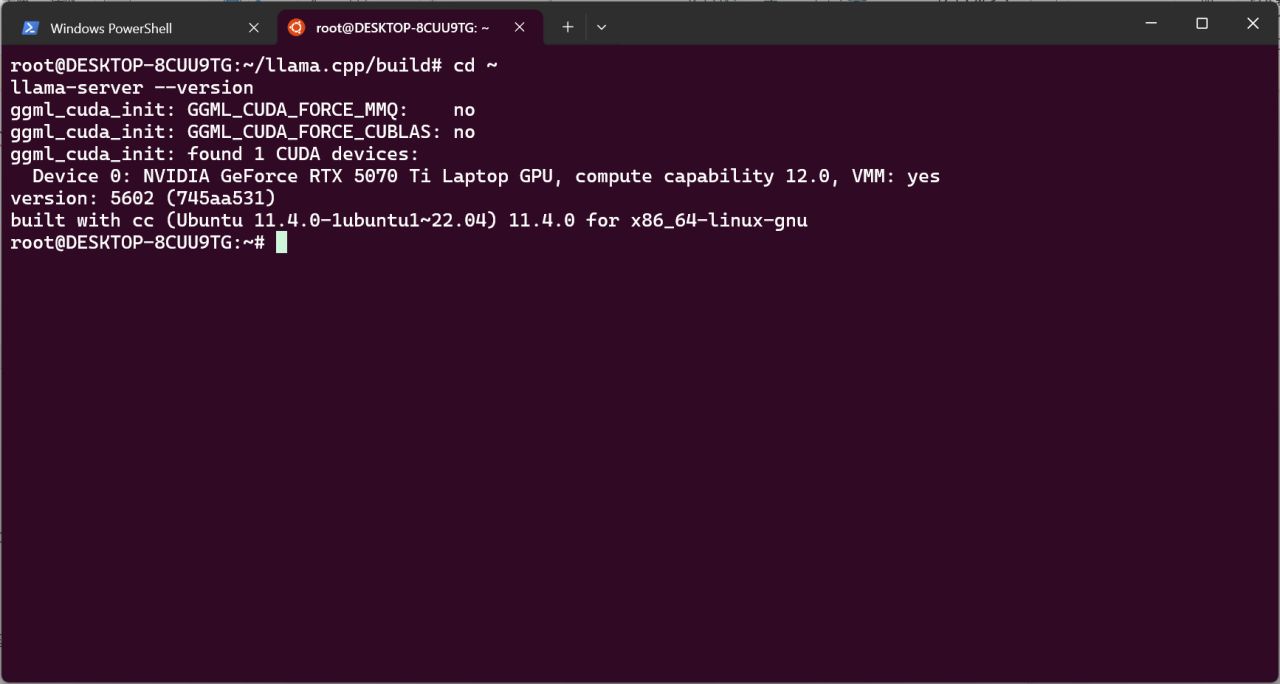
等待编译结束。此后执行命令,会看到llama-server正常显示版本。
cd ~
llama-server --version
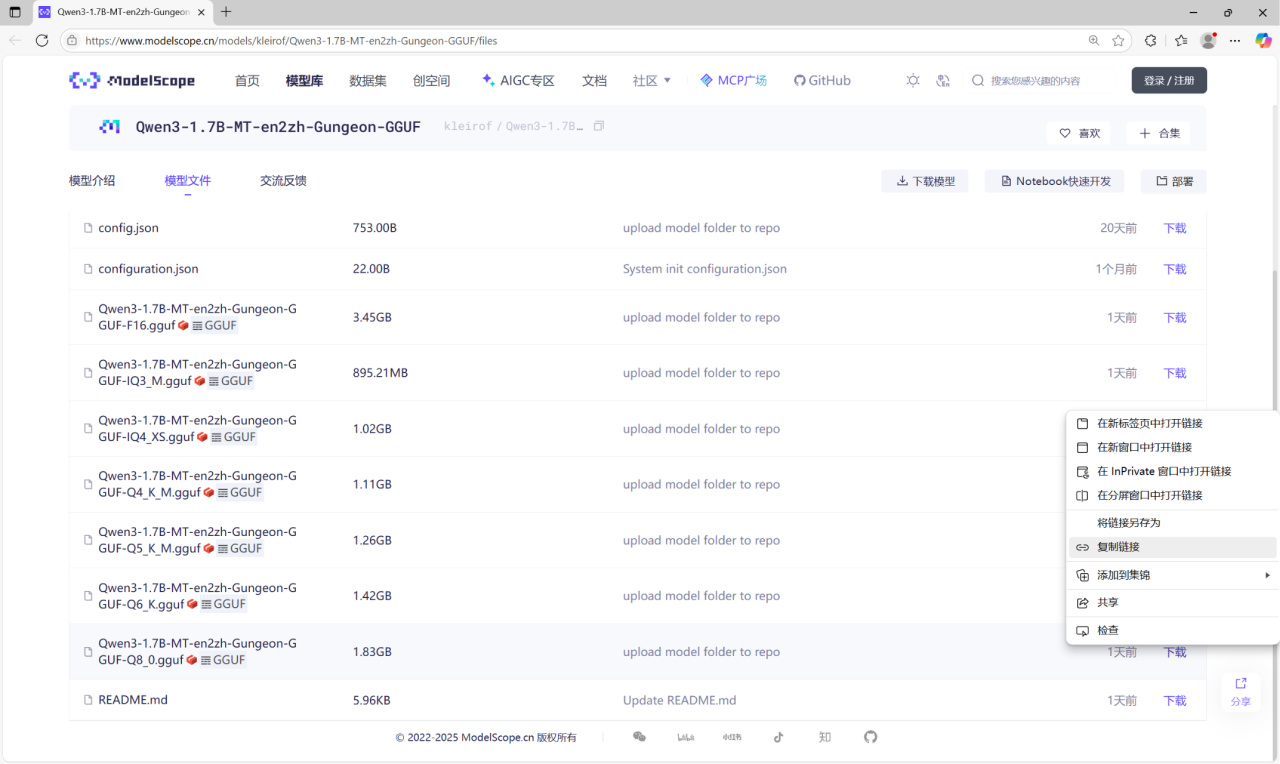
下面下载Qwen3-1.7B-MT-en2zh-Gungeon模型。量化模型发布于ModelScope:
https://www.modelscope.cn/models/kleirof/Qwen3-1.7B-MT-en2zh-Gungeon-GGUF/files
不同量化程度的模型具有不同的精度和推理速度,此处以Q8_0量化为例。下面把模型放到WSL-Ubuntu中。在模型的下载处右键 - 复制链接。
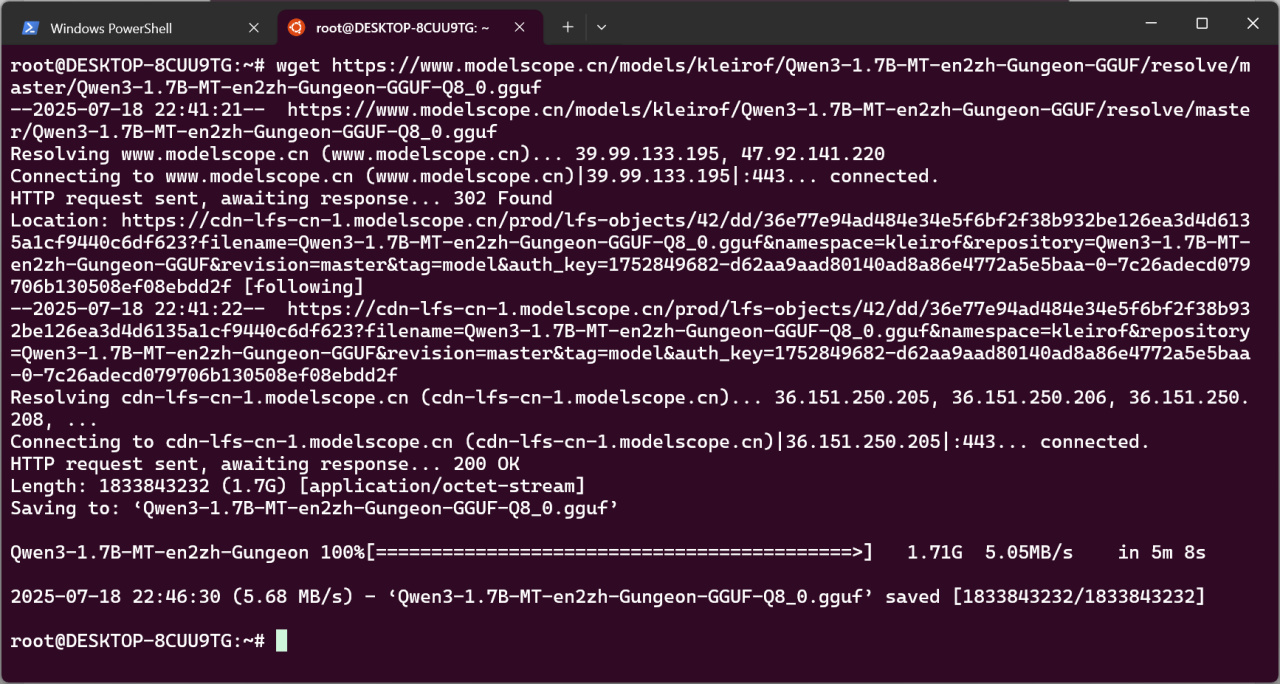
在WSL输入命令:
cd ~
wget <复制的链接>
等待下载完成。
这时就可以启动推理服务了。在WSL命令行输入:
llama-server -m <模型路径> --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
此处案例模型名为Qwen3-1.7B-MT-en2zh-Gungeon-GGUF-Q8_0.gguf,故命令为:
llama-server -m Qwen3-1.7B-MT-en2zh-Gungeon-GGUF-Q8_0.gguf --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
类似这样,就说明模型启动成功。
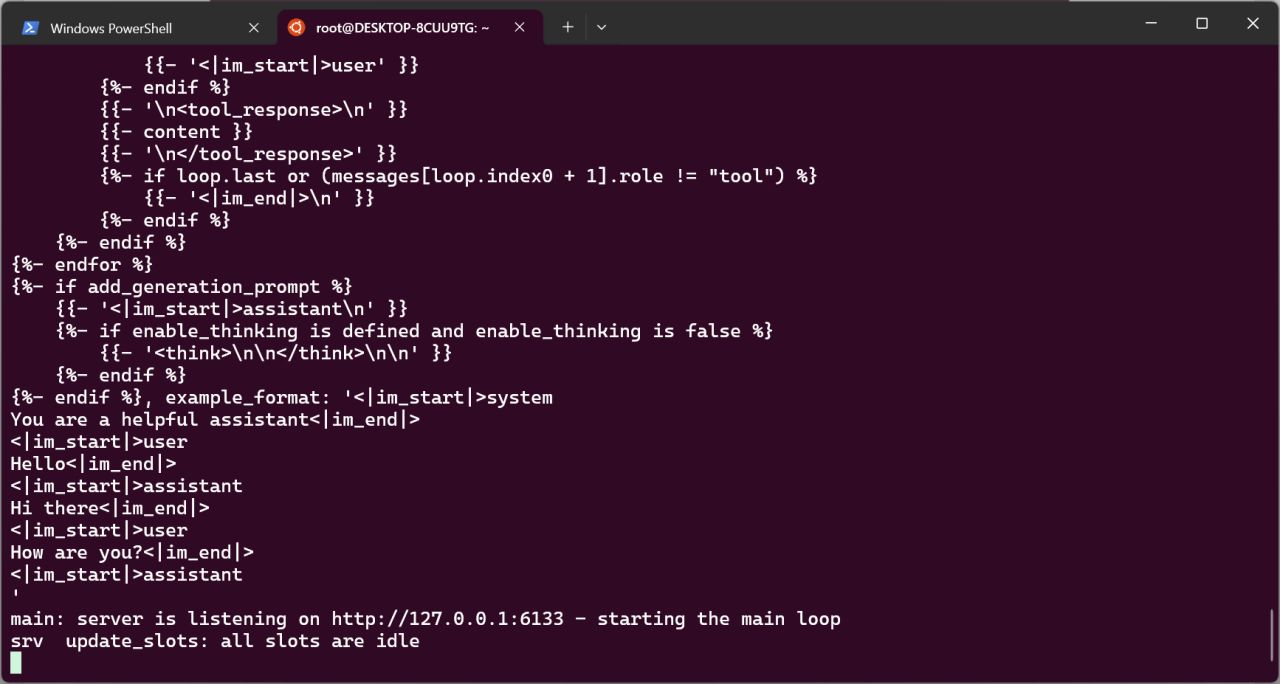
接下来设置Auto Translate模组,模组发布贴见我的主页,请阅读模组声明并选择是否同意。
在模组管理器中,此处以Gale管理器为例,在配置- Auto Translate - General,选择Translation api为Llm,下方Retry interval为0.1。
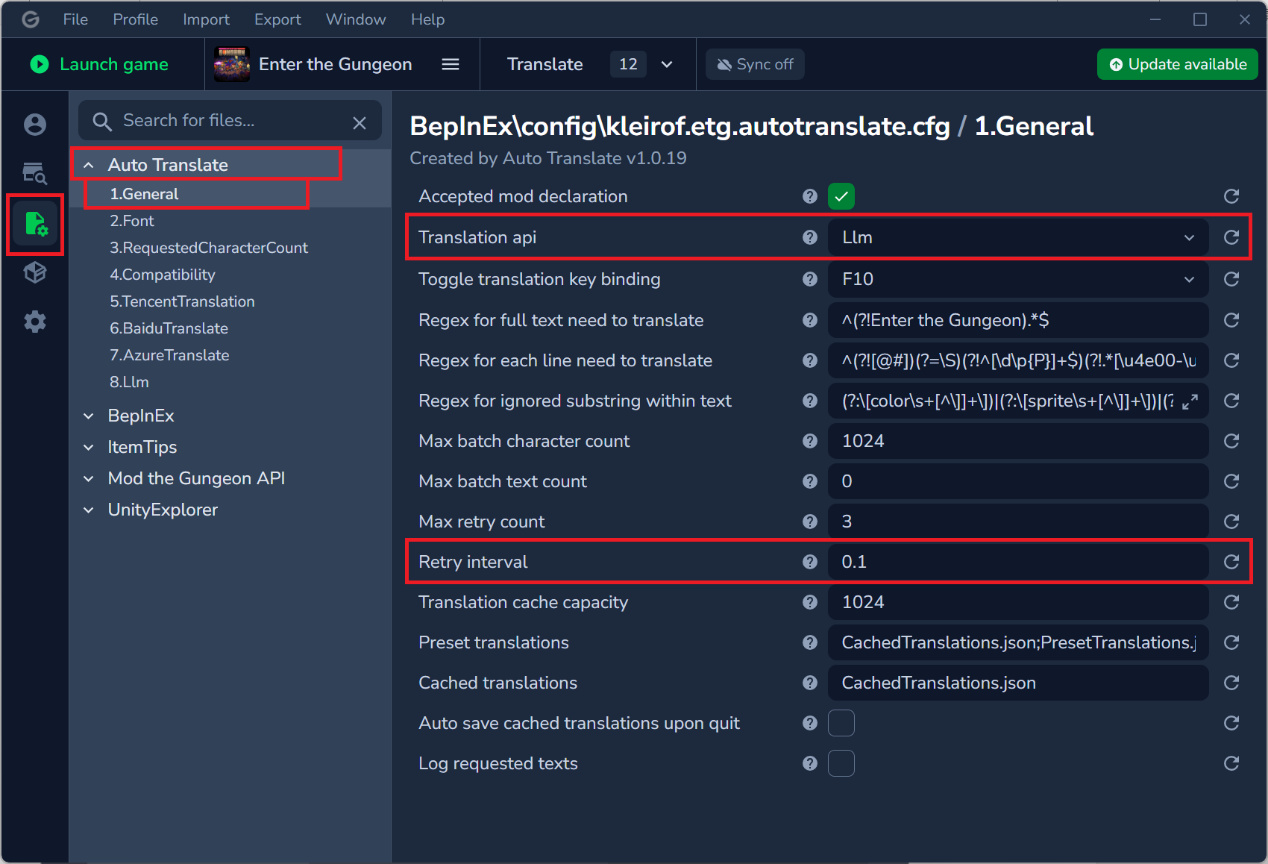
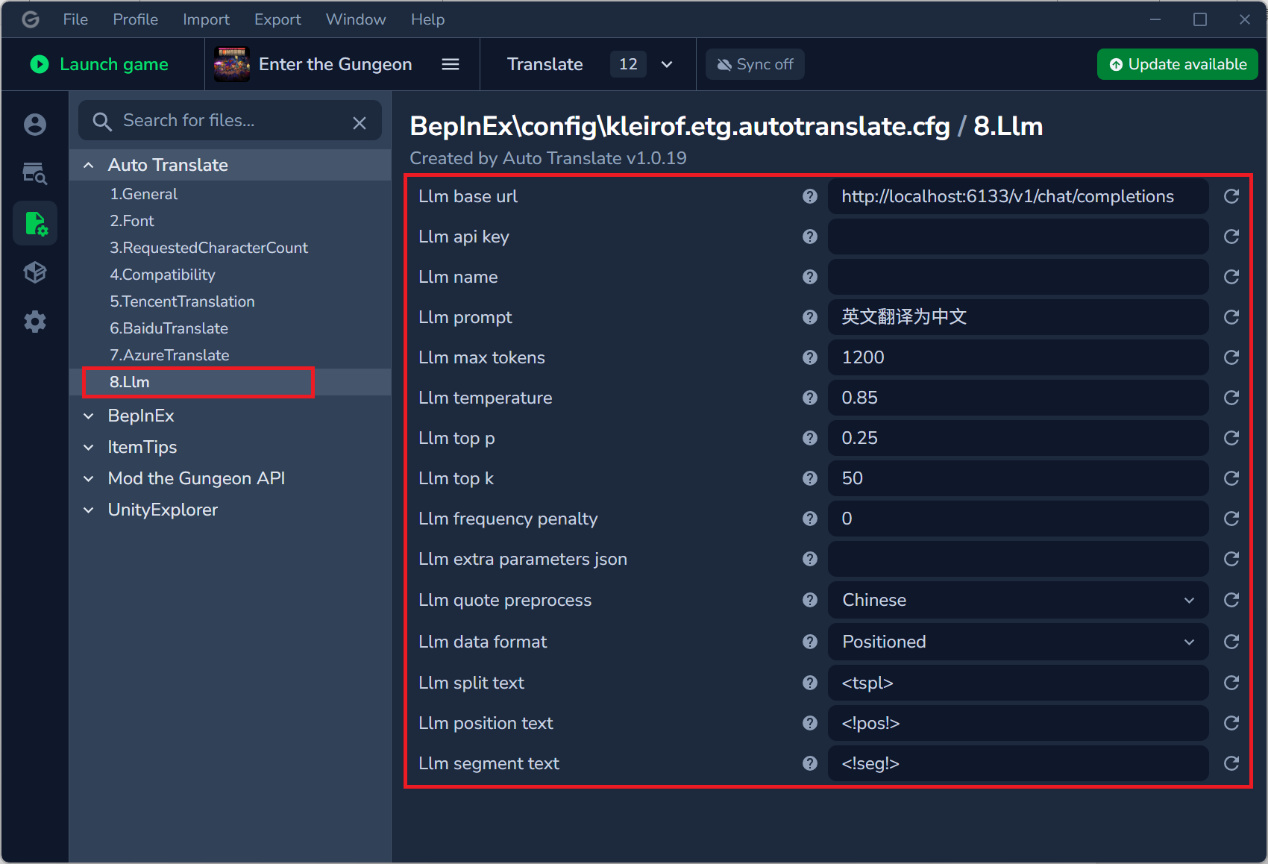
选择Llm,设置如下:
Base url为:http://localhost:6133/v1/chat/completions
Api key留空
Name留空
Prompt为:英文翻译为中文
Max tokens为:1200
Temperature为:0.85
Top p为:0.25
Top k为:50
Frequency penalty为:0
Extra parameters json留空
Quote preprocess为:Chinese
Data format为:Positioned
Llm position text为:<!pos!>
Llm segment text为:<!seg!>
启动游戏即可。
之后再次使用时,只需要开启WSL并输入上面的llama-server命令:
llama-server -m <模型路径> --port 6133 --jinja --reasoning_budget 0 -ngl 1000 --no-webui
接着启动游戏即可。
附
以下为扩展(可选):
由于nvcc在编译后不是必要的,可以卸载以节省空间。
sudo apt remove --purge cuda-nvcc-12-9 libcublas-dev-12-9 -y
sudo apt autoremove -y
sudo apt autoclean
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















