近日,備受爭議的小米首款旗艦SoC玄戒O1在正式發佈之後,依然是爭議不斷。最新的質疑稱,玄戒O1並不是小米自研的,而是由Arm公司爲小米定製的。

起因是,Arm官網近日發佈了一篇題爲《XRING O1 Custom Silicon from Xiaomi is Powered by the Arm Compute Platform》的新聞稿(已刪除),常規翻譯過來的意思就是“小米的XRING O1定製芯片由Arm計算平臺提供支持”,並稱這“標誌着小米與Arm合作15年,小米的第一個定製芯片爲下一代設備帶來了先進的AI和性能提升。”
於是乎很多的網友質疑玄戒O1並不是購買了Arm的IP來自己研發設計的,而是由Arm基於其CSS for Client(面向客戶端的 Arm 計算子系統 )爲小米定製的。
那麼,事實究竟如何呢?下面芯智訊就結合已有的公開信息和我們通過採訪瞭解到的相關信息來解讀一下:
一、什麼是“Custom Silicon”?
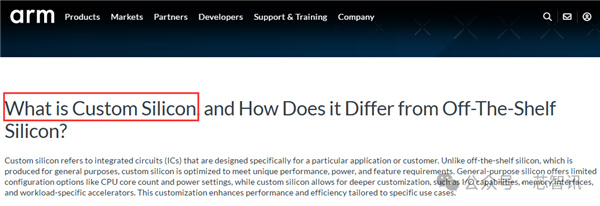
雖然Arm官網發佈的關於小米玄戒O1的文章當中用了“Custom Silicon”這個英文詞組,按照字面意思似乎是“定製芯片”,然而實際上,在半導體行業當中,“Custom Silicon”指的是“高度自定義的芯片”。這一點Arm在其官網上其實就有介紹。
“Custom Silicon”是指:“專爲特定應用或用戶設計的集成電路 (ASIC)。與爲現成通用目的而生產的傳統芯片不同,Custom Silicon 經過優化,可滿足獨特的性能、功耗和功能要求。
通用芯片提供的配置選項有限,例如 CPU 核心數量和功耗設置,而“Custom Silicon”則允許更深入的定製,例如 I/O 功能、內存接口和特定工作負載的加速器。這種定製可以根據特定用例提升性能和效率。”
△圖片來源:https://www.arm.com/glossary/custom-silicon
Arm還進一步指出,相對於架構是固定的,並適用於更通用應用的標準芯片設計來說,“Custom Silicon”允許設計人員針對特定工作負載優化芯片的各個方面,包括內存、電源管理和處理速度進行優化。
此外,與通用的標準芯片相比,“Custom Silicon”能夠幫助企業實現更高的性能、更低的功耗、更佳的功能集成度和更強的安全性。能夠根據特定需求定製芯片設計,爲企業帶來競爭優勢。
Arm還舉例稱,亞馬遜自研的 AWS Graviton 處理器就是專爲雲計算打造的“Custom Silicon”,具有優化的內存加密和能效。另一個例子是亞馬遜的 AWS Nitro DPU,它也是“Custom Silicon”,能夠更高效地處理存儲、網絡和安全問題。

△圖片來源:https://www.arm.com/glossary/custom-silicon
亞馬遜雲科技也在其官網上對於Graviton 處理器介紹中指出,“它(Graviton處理器)是亞馬遜雲科技基於Arm針對雲計算優化 Neoverse(Arm面向服務器/數據中心端的IP核) 系列架構設計,並結合亞馬遜雲科技用戶使用經驗從業務負載角度做了定製和優化。”

△截圖來源:https://aws.amazon.com/cn/campaigns/graviton/
顯然,從Arm官方和亞馬遜官方的介紹來看,作爲“Custom Silicon”的AWS Graviton 處理器並不是Arm來爲亞馬遜定製的處理器,而是亞馬遜基於Arm提供的面向數據中心的Neoverse系列IP核設計,結合了亞馬遜用戶需求來定製和優化的一款處理器。
同理,小米玄戒O1作爲一款“Custom Silicon”也只是基於Arm提供的面向移動終端的處理器IP設計,然後結合了小米麪向自身客戶需求進行了一些列的定製和優化的一款處理器。
二、Arm的商業模式是什麼?是否提供芯片定製服務?
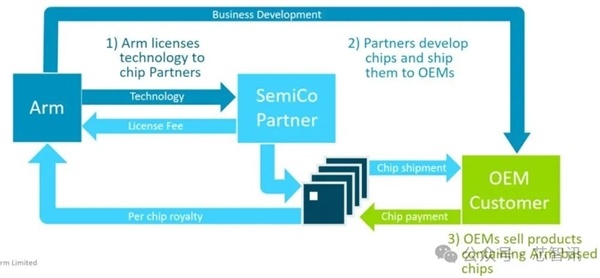
Arm公司是一家半導體IP設計公司,其本身不製造、也不銷售任何實物芯片,只是設計自己的半導體IP,並通過將其授權給客戶來獲得收入。這些IP包括指令集架構、微處理器、圖形核心、NPU(神經網絡處理器)核心、互連架構等等。
具體來說,Arm業務主要有四大類:
1、指令集架構授權(Architectural License):客戶可基於Arm指令集自主設計芯片架構,比如蘋果、高通、華爲。
2、IP核授權(IP Core License):客戶直接使用Arm設計好的IP內核,比如Cortex-A系列CPU內核、Mali系列GPU內核、Ethos系列NPU內核。
3、計算子系統(CSS)許可包。
4、技術諮詢服務。
IP核授權主要包含兩種類型:
一種是軟核授權,提供寄存器傳輸級(RTL)源代碼,客戶可進行代碼級的單元測試,可以自行完成邏輯設計和物理設計;
另一種則是硬核授權,即該內核IP是已經完成了晶體管的佈局佈線的物理版圖,並且與相關晶圓廠的特定製造工藝進行了綁定,是經過優化驗證的,通常以 GDSII 文件或等效文件的形式提供給客戶。雖然,客戶無法對其進行修改,但可以直接拿來集成到自己的SoC設計當中,並交由代工廠製造,可以大幅縮短開發週期,風險也較低。
IP授權收費模式
IP授權主要分爲前期授權費,以及根據每顆芯片的售價按比例收抽取版稅(royalty)。指令集授權則是一次性買斷。
那麼,Arm是否有芯片定製服務呢?
嚴格來說,Arm並沒有對外提供芯片定製服務,因爲對於一款芯片來說,光有CPU/GPU等核心IP是遠遠不夠的。而且,Arm作爲一家上市公司來說,也從未在財報當中披露其有給客戶專門定製SoC的服務。
實際上,半導體行業有很多專門爲客戶提供芯片定製服務的企業,比如創意電子、世芯、博通、Marvell、芯原股份等,其中一個關鍵因素在於,他們手中都擁有豐富的半導體IP和芯片設計和流片經驗,以及能夠拿到很多晶圓廠端的資源支持。
而據芯智訊瞭解,目前能從臺積電拿到產能支持的後端芯片設計服務廠商就只有創意電子、世芯、博通和Marvell四家公司。
當然,Arm也希望針對客戶的需求來發展類似半定製化的IP整合包服務,即提供Arm計算子系統(CSS)平臺,甚至是有計劃自研芯片來直接銷售給客戶。
在2024年12月,Arm與高通的關於技術授權問題的訴訟庭審當中,高通就指控稱,Arm正在爲客戶端和數據中心處理器以及其他用例提供Arm計算子系統(CSS),存在與客戶競爭的嫌疑。
同時,高通的法律團隊出示了Arm 首席執行官 René Haas爲 Arm 董事會準備的一份文件,表明Arm還在考慮設計自己的芯片直接提供給客戶,這將使其成爲包括高通在內的客戶的主要競爭對手。
René Haas則駁斥了這些說法,稱雖然 Arm 正在探索各種商機,但Arm不製造芯片,也從未涉足過這個行業。
不過,今年2月,英國《金融時報》爆料稱,Arm正在開發自己的芯片,首款自研芯片最快會在今年夏天推出,將由臺積電代工,Meta可能將會成爲首批客戶之一。
所以,實際上目前Arm並沒有對外提供定製芯片服務,而Arm計算子系統(CSS)也並不是給客戶定製的,而是將Arm現有的CPU等IP整合成一個系統平臺來進行銷售。
三、什麼是Arm CSS?
Arm CSS全稱是計算子系統(Compute Subsystem),最早是在2023年針對Arm Neoverse 基礎設施產品推出的計算子系統 (CSS) ,首款產品是 Arm Neoverse CSS N2。
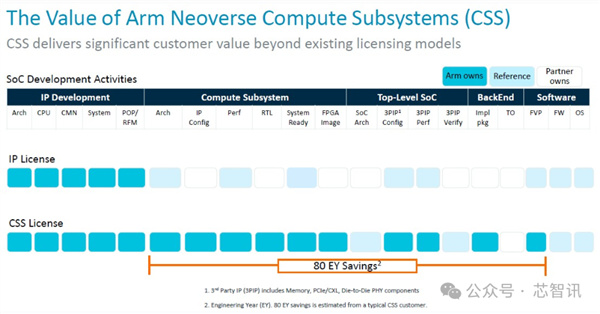
根據當時的Arm產品管理高級總監 Jeff Defilippi介紹,所謂的Neoverse CSS實際上是Arm Neoverse系列多核設計,包括了將CPU、互連、虛擬化 IP 要求等整合在一起,進行驗證,並將其作爲生產就緒的 RTL 可交付成果交付給客戶。
除了 RTL 之外,Arm還提供與之相關的額外的實現包、平面圖、實現腳本以及達到該性能所需的物理 IP 庫以及設計所需的功耗範圍,以及完整的軟件參考堆棧。
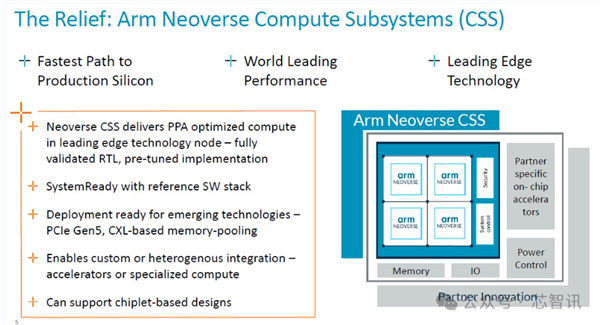
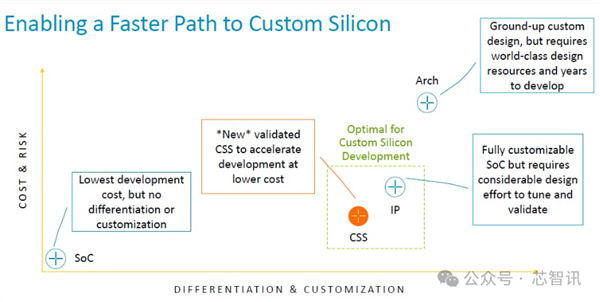
根據Jeff Defilippi當時的說法,客戶通過使用Arm提供的CSS包來進行芯片開發,與使用普通 IP 許可證來進行開發相比,可以節省80個工程師一年時間的開發。而且保留了相當的自由度。(應該是指也可以軟核交付,客戶可以進一步開發和優化設計)
顯然,Arm CSS並不是以交鑰匙的方式去幫助客戶直接定製芯片,而是爲客戶提供了多核集羣的系統級解決方案,客戶不需要再購買單獨的購買不同類型的IP核來進行多核集羣的系統搭建,可以直接選擇Arm的CSS包來進行開發,並且客戶還能在這個基礎上繼續進行定製開發自己的SoC。
而Arm高管關於採用CSS平臺研發比普通IP許可研發方式“可以節省80個工程師一年時間的開發”的說法也印證了這一點。
因爲,一款旗艦手機SoC的研發至少需要接近1000人的研發團隊經過兩三年的研發,如果使用Arm CSS平臺只是能節省80個工程師一年的工作量,怎麼能將該芯片稱之爲完全是交由Arm定製的呢?更何況一款旗艦SoC當中,除了CPU/GPU之外,還有很多其他的功能模塊。
Arm的Neoverse CSS解決方案在服務器市場獲得成功之後,在2024年5月底,Arm正式發佈了首款面向智能手機和PC等終端產品的 Arm 計算子系統 —— Arm CSS for Client。
根據Arm官網的介紹,Arm CSS for Client整合了最新的 Armv9.2 指令集的 CPU 集羣,包括最高性能的 Cortex-X925 CPU、最高效的 Cortex-A725 CPU、更新後的 Arm Cortex-A520 CPU,以及性能最高、效率最高的 GPU——Arm Immortalis-G925 GPU 等,並通過Arm CoreLink CI-700進行互聯。
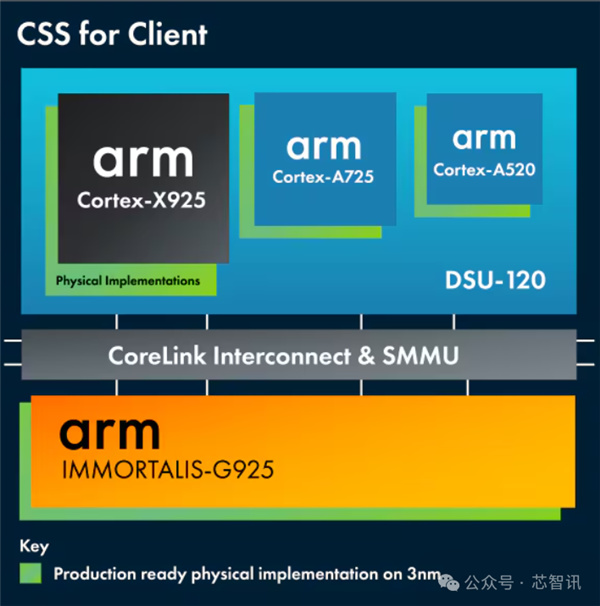
同時,Arm CSS for Client還引入了在3nm上優化的生產就緒、硬化的CPU和GPU核心實現。這些可在多個晶圓代工使用,提供了最大的靈活性。CSS for Client還可使用CSS RTL改進在3nm芯片上提供一流的PPA。
總結來說就是,Arm CSS for Client是一個整合了Arm最新的X925超大核、X725大核、A520能效核和G925 GPU核心及互聯多核解決方案包,並且該解決方案是經過各晶圓廠3nm製程優化驗證的,可以直接提供硬核交付。
值得一提的是,Arm在2024年宣佈推出Arm CSS for Client的新聞稿中,聯發科技資深副總經理、無線通信事業部總經理徐敬全博士當時就表示,“天璣 9400將搭載最新的Armv9 Cortex-X925 CPU 和 Arm Immortalis-G925 GPU客戶端解決方案。我們與 Arm 保持着長期而緊密的合作關係,致力於不斷提升移動芯片的性能和功能,共同推動計算技術的快速發展。”



同時,vivo首席芯片規劃專家夏曉菲也表示:“vivo 非常注重用戶體驗,在 Arm CSS 的技術基礎之上,我們與 Arm 的密切合作,共同推動開發者生態,使手機更流暢更好用,同時也爲設備端帶來了前沿的 AI 體驗。……”
隨後,vivo X200 系列旗艦級首發搭載了聯發科的天璣9400。
那麼,聯發科天璣9400是否是採用了Arm CSS for Client解決方案呢?
Arm在2025年2月5日發佈的“2025財年第三季度電話財報會議”記錄當中就有明確提到,“天璣9400 SoC基於我們的CSS for Client,其中包括Arm Cortex-X925 CPU和Immortalis-G925 GPU。”

△來源:https://investors.arm.com/static-files/f1190d81-408d-4276-a30c-b27c1ce5a30a
顯然,聯發科天璣9400就是基於Arm CSS for Client平臺打造的,所以其X925大核也是基於Arm公佈的3.6GHz標準主頻。
那麼,天璣9400是Arm給聯發科定製的芯片嗎?顯然不是!
而且,Arm還指出,“芯片複雜性的增加正在推動頂級超大規模製造商在最新的Armv9和CSS上‘Custom Silicon’(面向自己的用戶需求自定義芯片)。我們正在通過AWS Graviton、微軟Cobalt、谷歌Axion和英偉達基於基Arm技術的Grace芯片在數據中心獲得份額。”
顯然,AWS Graviton、微軟Cobalt、谷歌Axion和英偉達Grace CPU也都被Arm定義爲“Custom Silicon”。這些芯片也並不是Arm爲他們定製的,而是他們基於Arm的IP來自己設計的。
值得一提的是,網上也有不少網友認爲,小米玄戒O1可能是基於“Arm Total Design”(Arm全面設計)項目推出的。
這裏需要指出的是,Arm Total Design實際上是爲了助力 Arm 服務器 CPU 廠商的芯片設計而推出的。
2023 年 10 月,Arm整合了特殊應用 IC (ASIC) 設計公司、IP 供應商、電子設計自動化 (EDA) 工具供應商、晶圓廠與固件開發商等業界領導企業資源,推出了Arm Total Design,主要是致力於加速並簡化面向數據中心的 Neoverse CSS 構架系統的開發,協助各方進行創新、加速產品上市時程,並降低打造客製化芯片所需的成本與阻力。
簡單來說,Arm Total Design爲了助力亞馬遜、谷歌、微軟等雲廠商加快自己的Arm服務器CPU設計,不僅提供Arm Neoverse CSS解決方案,而且還整合了他們可能會需要的芯片設計服務公司、IP供應商、EDA工具商、晶圓廠等相關的資源。但是這也並不是Arm來爲客戶提供一站式的芯片設計服務。
2024年 6 月,聯發科就有宣佈加入Arm Total Design生態項目,這也引發了當時關於聯發科可能將進軍數據中心市場的相關報道。
另外,可以明確的一點是,Arm Total Design至今都是圍繞着數據中心市場,根本沒有面向智能手機/PC等客戶端市場推出。所以,小米也不可能因爲設計手機芯片玄戒O1而加入面向數據中心的Arm Total Design項目。
四、小米玄戒O1是否基於Arm CSS for Client?
從玄戒O1所採用的3nm製程以及2個Cortex-X925超大核、4個Cortex-A725大核、2個Cortex-A725能效大核、2個Cortex-A520能效小核,以及G925 GPU核心的集羣組合來看,確實有可能是採用了Arm CSS for Client解決方案。

不過,據安謀科技的人向芯智訊透露,據其瞭解,小米玄戒O1並不是基於Arm CSS for Client平臺方案。
芯智訊也聯繫了小米集團副總裁、玄戒負責人朱丹進行求證,對方表示,小米是買的Arm IP軟核授權,“CPU/GPU多核及訪存的系統級設計完全由小米自主研發,後端設計也是完全由小米自主研發,並非是基於Arm CSS軟核或硬核方案。”
這裏有必要介紹一下一款芯片的設計流程,主要可以分爲前端設計和後端設計兩個部分。
前端設計主要包括:
1、規格與功能定義:確定芯片需要什麼樣的性能、要做到什麼樣的功耗、成本需要控制在多少等;
2、系統設計:確定芯片架構、業務模塊、供電等系統級設計,比如用什麼IP、多個核心、多個叢集、配置多少緩存、怎麼互聯等;
3、代碼描述:將芯片的具體電路進行RTL級別的代碼描述;
4、邏輯綜合:將所設計數字電路的高抽象級描述,經過布爾函數化簡、優化後,轉換到邏輯門級別的電路連線網表的過程,以確保電路在面積、時序等目標參數上達到標準;
5、仿真驗證:利用計算機軟件、模型和算法來模擬和分析電路設計的準確性和穩定性。
顯然,對於玄戒O1來說,前端設計主要是在完成對於芯片的規格和功能定義之後,對於Arm IP以及自研或第三方IP的選擇,拿到對應的RTL之後,再進行邏輯綜合並進行仿真驗證。這部分的工作量其實並不太大,更大的工作量實際都集中在後端設計上。
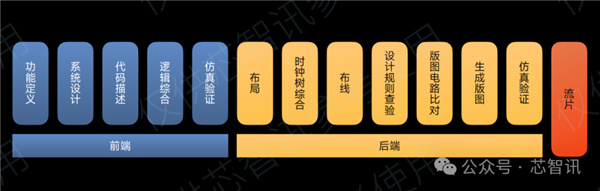
後端設計主要包括:
按照既定的目標PPACR(Power、Performance、Area、Cost、Reliability)的限制,藉助EDA在硅片面積內,對電路進行佈局/(FloorPlan&Place)、佈線(Routing)以及時鐘樹綜合(CTS),將門級網錶轉化爲GDS(Geometry Data Standard)物理版圖。
此後進行籤覈驗證,對佈線後的物理版圖進行功能和時序上的全面驗證,如設計規則查驗(Design Rule Check)、版圖和電路比對(Layout Versus Schematic) 、時序靜態分析(Static Timing Analysis , STA)、功耗分析(Power Analysis)等,確保最終物理版圖滿足設計需求。
需要指出的是,後端設計同樣是不斷迭代的過程,仿真驗證不滿足要求,同樣需重複前序流程。仿真驗證沒有問題之後,纔會進行流片。
五、玄戒O1究竟做了哪些關鍵自研工作?
正如前面所介紹的那樣,如果小米玄戒O1採用了Arm CSS for Client的硬化IP,那麼就等於是省去了整個核心的CPU計算集羣很多後端設計工作,雖然可以縮短開發週期,並降低開發風險,但是也就無法對整個核心的CPU計算集羣進行修改或加入自研的技術,以進一步提升性能和功耗表現。
1、三大自研技術提升至3.9GHz主頻
Arm在發佈Cortex-X925超大核時公佈的信息是,該CPU內核主頻最高可達3.8GHz(常規爲3.6GHz),而玄戒O1公佈的Cortex-X925超大核之則實現高達3.9GHz的主頻,這正是得益於小米自研的邊緣供電技術、自研標準單元(StdCell)和自研高速寄存器的加持。
據朱丹向芯智訊介紹,傳統芯片的超大核採用MTCMOS方式供電,邏輯計算單元周圍分佈着錯綜複雜的供電網絡,成千上萬的供電單元散佈在邏輯計算單元中間,導致邏輯計算單元之間的距離疏遠。
通俗來說,從邏輯計算單元A到邏輯計算單元B,需要繞路。而玄戒O1在X925超大核上設計了全新的邊緣供電技術,將供電單元統一集中到超大核兩側,再通過立體空間組網供電的方式,實現了電源的均流。
這樣核心內部的邏輯計算單元就更加緻密,相互之間的物理距離更近,在保證高質量電源供給的前提下,時鐘速度可以得到提升。
同時,小米爲了實現玄戒O1的性能指標,在晶圓廠基於3nm工藝提供的1500多種各式各樣的標準Cell(門級電路是有多個晶體管組成的,而Cell是由門級電路組成的具備基礎功能的最小單元)基礎上,重新設計了480多種組合邏輯和時序邏輯單元,並且應用在了CPU內部最關鍵的路徑上,這也是讓玄戒O1的超大核頻率能夠提升到3.9GHz的關鍵。
此外,小米芯片研發團隊針對不滿足性能條件的關鍵路徑,逐條打開,調整寄存器內部兩級鎖存器(Latch)的工作邏輯,調整兩級Latch 的時鐘延遲,讓前一級路徑時序 margin更大,同時不影響下一級路徑時序。通過小米自研的全新的高速寄存器,將不滿足3.9GHz(256皮秒)的1000條關鍵路徑進行提速,最終讓玄戒O1的超大核主頻得以提高至3.9GHz。
2、超低功耗設計
除了利用自研技術提升玄戒O1的CPU性能之外,小米還在改進玄戒O1的能效表現上下了非常大的功夫。
根據小米披露的信息來看,玄戒O1的四個A725性能大核在持續高性能的情況下,其功耗表現是優於同樣是3nm的蘋果A18 Pro大核;同樣,玄戒O1的2個低功耗A725核心+2個A520核心在能效表現上也優於蘋果A18 Pro的能效核。

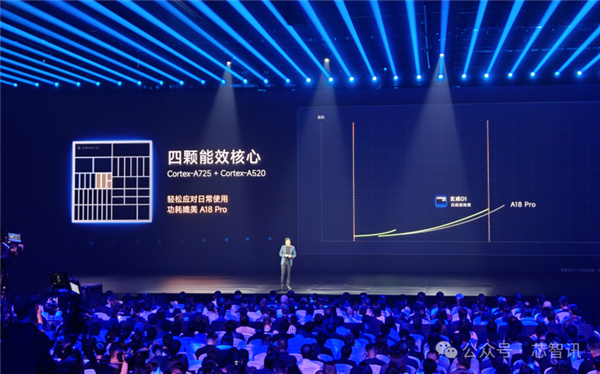
首先,在CPU集羣設計上,玄戒O1並沒有採用常見的“2+4+2”的三叢集設計,而是採用了“2+4+2+2”的組合,其中2顆A520+2顆低主頻的A725形成4核雙能效叢集,相比傳統的“2+4+2”三叢集設計,各場景功耗降低了2%-6%。
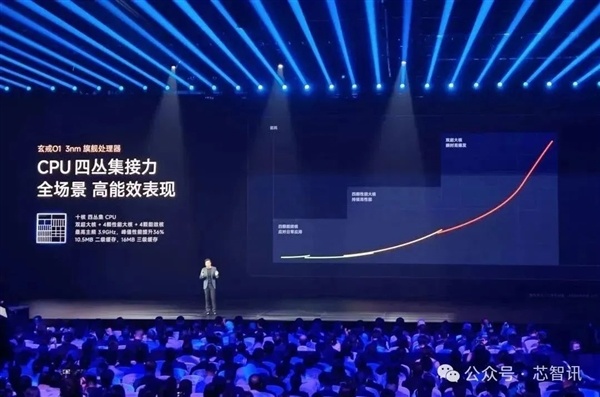
其次,小米芯片團隊還針對玄戒O1整個SoC全局進行4級低功耗系統劃分,玄戒O1可以根據用戶的使用狀態,在Level 0 到Level 3四種狀態自由切換,通過90+電源域分區控制,各個模塊非用即關,可以大大降低了日常使用中因爲芯片設計不合理導致的功耗浪費。
第三,衆所周知,對於芯片來說,工作電壓越低,功耗就越低,但是電壓過低又會影響性能。
所以,找到不同CPU內核的電壓和能效的平衡點,則是優化功耗的一個關鍵手段。對此,玄戒O1對CPU每個核心的每一個頻點,都進行了系統化的VF掃頻,在固定電壓(V)下,尋找到能效最高的頻率點位(Freq)。而掃頻的過程,需要貫穿前端設計和後端設計,不斷仿真驗證進行迭代。
據瞭解,玄戒O1經過998種方案迭代,才固定了能效最優的物理電路版圖,將CPU的每一個核心做到了極致,讓每一個點位都找到能效最高的頻率值,能效曲線表現更優,在相同性能下電壓更低,A725和A520核心下探到0.5V的超低工作電壓。
第四,小米芯片研發團隊爲了進一步降低工作電壓,還在玄戒O1內部集成了25個性能傳感器和22個溫度傳感器,可精準感知芯片內部不同區域、不同子系統的局部體質差異,在滿足性能的前提下,進一步降低工作電壓,最終讓0.5V的最低工作電壓,進一步下探到0.46V,據說是做到了行業最低。這也成就了玄戒O1在保持高性能下,出色的低功耗表現。
3、軟硬深度協同的性能調度設計
由於玄戒O1採用的是“2+4+2+2”的四叢集CPU設計,這也意味着要想用好這個四叢集CPU,就必須要做到針對不同的需求場景能夠實現快速的最優的調度,比如選擇合適的CPU內核,並選擇合適的工作電壓和工作頻率,否則就容易出現不必要的CPU計算資源的浪費或者計算資源不足而導致的卡頓。
而傳統的CPU調度大多是通過軟件來實現的,並且也是由CPU來運行軟件調度算法,這就造成了CPU既要執行當前的任務,還要分心來做額外的調度計算,不僅會帶來延遲,還可能降低調度的精準度,因爲額外的調度計算本身也會被系統識別爲工作負載。
爲了解決這個問題,玄戒O1在CPU內部全新設計了獨立的硬件級的微控單元,專門進行調度計算。不僅能夠精準地監控SoC的負載狀態,而且無需CPU計算,從而以更低的性能開銷,快速調頻,讓CPU調度延遲從16ms降低至2ms。
此外,面對遊戲等固定週期的場景,小米芯片研發團隊還爲玄戒O1還帶來了更精準的聯合一體化調頻措施。
傳統SoC的調頻措施採用的是“試錯式調頻”,比如性能不足時,就提高頻頻,性能過剩了再降低頻率,頻率降多了出現卡頓,然後又再提高頻率。這也意味着這種傳統的SoC調頻措施很容易出現計算資源的浪費,導致功耗的增加。
對此,由於小米芯片研發團隊此前通過掃頻的方式,掌握了每個核心的每個工作頻率點位下的功耗表現,因此可以保證性能的前提下,一次性一體化調整各關鍵器件(CPU、GPU、L3、DDR、MainBus)的頻率,獲得“滿足性能需求同時功耗最低”的SoC各單元的頻點組合,找到全局最優解。
4、超大緩存設計
玄戒O1在CPU內部配備了超大容量多級緩存。其中,在二級緩存上,每個X925核心配備2MB L2緩存,每個A725核心均配備1MB L2緩存,A520核心共享512KB L2緩存,共計10.5MB L2緩存,並且還配備了16MB L3緩存,使得整個CPU的緩存容量達到了26.6MB。
作爲對比,聯發科天璣9400的L2緩存總計爲7MB,L3緩存爲12MB;高通驍龍8至尊版則配備24MB L2緩存(沒有L3緩存)。
玄戒O1憑藉充足的緩存可以高效存儲高頻數據,降低核心訪問DDR讀取數據的次數,從而提升核心間數據流轉效率、提升最終用戶體驗,降低功耗。但是這樣做的代價是大緩存會提升成本並佔據較大的面積,以玄戒O1的L3緩存面積爲例,其甚至超過兩顆X925核心的面積之和。

△玄戒O1與其他旗艦手機SoC的芯片內部結構圖對比
這似乎也可以解釋,同樣臺積電N3E製程的加持下,未集成基帶的玄戒O1的晶體管數量(190億顆)比集成了5G基帶的天璣9400的291億顆晶體管少了34.7%,而面積卻只少了13.5%。
5、自研第四代ISP技術
小米早在2019年就開始了自研ISP(圖像信號處理器)芯片的研發。2021年3月底,小米首款自研ISP芯片澎湃C1正式推出並商用。隨後,小米自研ISP芯片又持續迭代,今年年初發布的小米15 Ultra就集成了澎湃C3芯片。

玄戒O1則進一步集成了小米自研的第四代ISP技術,採用全新的三段式ISP處理管線(Pipeline)設計,相對於行業常規的兩段式處理管線設計,能夠有效提升ISP處理管線的靈活性,便於更多影像算法的Raw域遷移,對Raw域原始數據進行算法處理,帶來高速高畫質的影像體驗。
此外,三段式設計,同樣利於降低ISP功耗,降低對整個芯片的面積佔用。相機CMOS傳感器的速度遠快於ISP,將一級流水和二級流水斷開,一方面能夠保持一級流水的高速高頻狀態,用以匹配CMOS。
而斷開的二級流水和三級流水都可以同相機CMOS的時序解耦,避免整個ISP的處理管線都處於高頻高速狀態,降低功耗。同時二三級流水更「低速」就意味着面積更加小巧,玄戒O1的ISP面積僅爲傳統旗艦芯片的60%。
在性能上,玄戒O1的ISP每秒可以處理高達87億個像素,單攝最大可支持兩億像素,三攝同開最大支持6400萬+5000萬+5000萬。內置獨立3A加速單元,自動對焦、曝光、白平衡速度最高可提升100%,讓相機啓動、相機連拍以及連拍後預覽全面提速。
此外,玄戒O1的ISP內部新增兩大畫質增強硬件:
1、實時多幀HDR融合單元,不僅爲視頻帶來更高的動態範圍,全新的局部對齊技術可以大幅度降低鬼影;
2、Al智能降噪單元,利用CNN模型網絡對 Raw域視頻畫面進行逐幀降噪處理,信噪比最高可提升13dB(信噪比提升約20倍)。憑藉新增的兩大畫質增強硬件,可以支持手機實現全焦段超級夜景視頻,暗光視頻畫面更加清晰銳利,而且第三方應用也可直接調用優秀的夜景視頻能力。
6、自研NPU,100+常見AI算子硬化
目前端側支持生成式AI功能已經成爲了旗艦手機SoC的標配能力,而這就需要有強大的NPU內核來進行支持。
據瞭解,玄戒O1內置了6核心旗艦 NPU,集成Scalar標量加速器、Vector 矢量加速器和Tensor張量加速器,NPU算力可達44TOPS。作爲對比,蘋果A18 Pro的AI算力只有35TOPS。雖然驍龍8至尊版和天璣9400的NPU的具體算力官方並未公佈,但是高通面向AI PC的驍龍X Elite的NPU算力也才45 TOPS。
此外,玄戒O1的NPU還配備了10MB專屬大緩存,並針對AI影像算法、AI應用算法中經常使用的100多種基礎算子進行硬化。對比傳統軟件計算,算子硬化通過專門的硬件加速,可大幅提升計算效率,對CNN、Transformer、Stable Diffusion等模型均有不同程度的加速。
如果搭配小米第三代端側模型,玄戒O1能夠帶來速度更快同時功耗更低的端側AI體驗。據芯智訊瞭解,玄戒O1配合小米第三代端側模型在AI文本潤色任務處理上,速度可達62.13 Tokens/s,是iPhone 16 Pro Max的135%,但功耗僅60%。
7、其他
除了上述已經用於玄戒O1的小米自研技術之外,小米在此前的發佈會上也公佈了其自研的4G手錶芯片玄戒T1,這也反應了小米在自研4G基帶芯片技術上的突破,雖然目前這還只是一款4G Cat.1基帶芯片,但是這也爲後續自研更高速率的4G基帶芯片,乃至未來的5G基帶芯片帶來了可能。

另據芯智訊瞭解,目前小米還在自研DDR接口IP等其他相關自研IP,未來都有可能整合進自己的玄戒系列SoC當中。
小結:
總結來說,Arm雖然在去年推出了CSS for Client平臺,但是這並不是爲客戶去定製整個SoC,而是爲客戶提供CPU、GPU多核集羣的系統級解決方案,並且可以綁定製程工藝的硬核方式進行交付,客戶可以直接將Arm提供的CSS硬核包集成到自己的SoC設計當中,這樣就減少了CPU/GPU這個核心計算模塊的後端設計工作,降低開發難度、縮短開發週期、降低研發投入。
但是,從前面的介紹我們不難看出,小米芯片研發團隊並沒有採用Arm CSS for Client平臺的軟核或硬核方案,而是單獨買的最新的CPU、GPU內核IP授權,並且小米也確實在CPU系統設計當中加入不少自己的技術,比如自研的邊緣供電技術、自研標準單元(StdCell)、自研的高速寄存器、將CPU工作電源降低到0.46V的低功耗設計、面向CPU調度計算的獨立的硬件級微控制單元和一體化調頻方案等。
目前幾乎所有的智能手機芯片都是基於Arm架構的,其中絕大多數都是基於Arm的公版CPU+GPU IP核,少部分採用的是Arm公版CPU或基於公版CPU魔改+第三方(比如Imagination)GPU或自研GPU(比如高通部分芯片)。而採用Arm指令集授權來自研CPU內核IP的手機芯片廠商更是少之又少,目前主要有蘋果、高通和華爲,其中高通最新的驍龍8至尊版才完全轉向了自研的Oryon CPU內核,華爲則是自麒麟9000S才轉向自研的Taishan CPU內核。
玄戒作爲小米於2021年重新組建芯片研發團隊之後推出的第一款SoC芯片,採用Arm公版的CPU/GPU內核IP也並不丟人,因爲路需要一步步地來走,沒有多代芯片的持續迭代,沒有把CPU/GPU技術喫透,就不可能有自研CPU/GPU內核。
此外,對於一款旗艦SoC來說,僅有CPU/GPU計算核心是不夠的,還需要圖像信號處理器(ISP)、DSP(數字信號處理器)、NPU、內存與存儲控制器、多媒體編解碼器、無線模塊(WiFi/藍牙等)、基帶(Modem)、電源管理、傳感器中樞(Sensor Hub)、高速接口等一些列的IP來共同實現。
因此,芯片設計廠商即使買來了Arm公版CPU/GPU內核,也依然還是需要去完成手機SoC所必須的其他功能模塊的開發。雖然上述這些模塊也有一些第三方的IP供應商,但是要找到最適合自己IP,並整合到SoC系統當中,完成優化和驗證,實現既定的規格和功能定義目標仍有很多的工作要做,這並不是像搭積木那樣的簡單。
特別是在越尖端製程工藝節點上,可以選擇的第三方IP供應商就會更少,甚至可能都沒有符合自身需求的第三方的供應商。數年前,OPPO芯片產品高級總監姜波在接受芯智訊採訪時就曾表示,OPPO首款6nm的影像NPU——MariSilicon X時,需要可以用於6nm節點的高速MIPI接口IP,雖然也有一些第三方供應商,但是可選擇範圍較小,且依然是滿足不了OPPO估算的數據量要求,最終被迫選擇了自研MIPI IP。
所幸的是,玄戒O1這款芯片當中,除了有在Arm CPU系統設計當中加入不少自己的技術之外,也有自研ISP和NPU IP。
另外,小米除了已有的自研快充芯片(澎湃P系列)、電池管理芯片(澎湃G系列)、信號增強芯片(澎湃T系列)、4G基帶芯片(玄戒T1)之外,似乎還在研發DDR接口IP等其他的自研IP,憑藉在這些方面技術積累,後續一些技術也有望被整合到未來的旗艦級玄戒SoC當中,推動玄戒SoC的全自研技術佔比逐步提升。
來源:快科技-手機頻道
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















