上篇教程中我已經將A卡用戶Windows下運行AI的基礎環境配置講述清楚,本文則基於上篇教程中配置好的環境,對A卡Windows下大模型運行(量化)與微調(原生)進行教學。其中運行的部分所有人均可閱讀,文中有6750GRE運行的速度展示,各位可在下方查看並做爲參考,而微調的部分我推薦顯存在20G及以上的用戶才進行閱讀。
【教程】A卡用戶Windows下AI運行完全指南-基礎環境篇
1.使用llama.cpp進行推理
在正式進入教程之前,還有一些需要了解的基礎背景,我在這裏分別對其進行一些簡單的介紹。
1.1 GGML
GGML是一個用C和C++編寫,專注於Transforemr架構模型推理的開源機器學習庫,其與PyTorch和TensorFlow類似,但具有輕量化、編譯簡單和支持量化的特點。
https://huggingface.co/blog/zh/introduction-to-ggml
1.2 GGUF
可以說GGUF是繼PyTorch的pickle形式和safetensors以來的又一種新的權重保存形式。PyTorch以pickle形式序列化的二進制權重可能含有可執行的惡意代碼;而safetensors的設計確保了數據在讀取時不會執行任意代碼,解決了PyTorch的問題,是目前各類大模型使用最多的權重形式;而GGUF更進一步,不同於safetensors僅限張量的保存形式,GGUF在文件的前部保存了metadata信息,使得保存的權重能以量化的形式讀取。
https://huggingface.co/docs/hub/gguf
所謂量化簡單來說就是對權重以不同的精度進行編碼。在深度學習中,我們常用的精度是fp32,對於以前的一些CV和NLP上的較小的模型(參數量在億以內),一般的消費級GPU的顯存也足夠以fp32的全精度加載它們。而在大模型出現後,即使是財大氣粗的各大企業面對這樣的無底洞時也不得不做出妥協,更多的時候他們會以fp16的半精度對模型進行訓練。同時,一種名爲bf16的編碼方式也得以推廣開來,其與fp16同樣消耗16個bit,但是能表達數字的範圍卻與fp32相同,只不過相較於fp16損失了部分精度而已。
然而對於深度學習任務而言,權重的精度最終對模型的性能影響並不算大(相對而言),所以從fp16到bf16的轉換是非常划算的。即使如此,對於大部分大模型而言,16位的編碼更多地只是一定程度上節約了本就擁有足量的專業級GPU的廠商在對其訓練和運行時所需要的成本。而對於個人用戶而言,哪怕是最強的消費級顯卡,其最高也不過只有24GB顯存,單張顯卡要以16位的精度運行大模型依然是無法實現的,難道給個人消費者的路就只剩下重金購買多卡、重金購買專業卡和租服務器了嗎?當然不!既然權重的精度對模型性能的影響有限,何不再讓他的精度低一點,用8位,4位甚至1.75位來將訓練好的權重轉換過來呢?
這就是GGML和GGUF做的事情,通過對權重進行重新編碼,以更小的位數來表示相同(近)的信息,通過損失一部分精度的代價來使得同樣的顯存能運行更大的模型,這對於對性能沒有過於嚴苛的要求的普通用戶而言意義重大。況且,合理的量化精度對最終指標的影響並不明顯,下圖是同一模型在不同量化精度下的困惑度(PPL)比較,可以看到一直到了Q3,其困惑度相比於fp16纔有較爲明顯的上漲。而13B的模型哪怕是Q2量化的版本,其困惑度也要比7B模型的fp16原版要低。
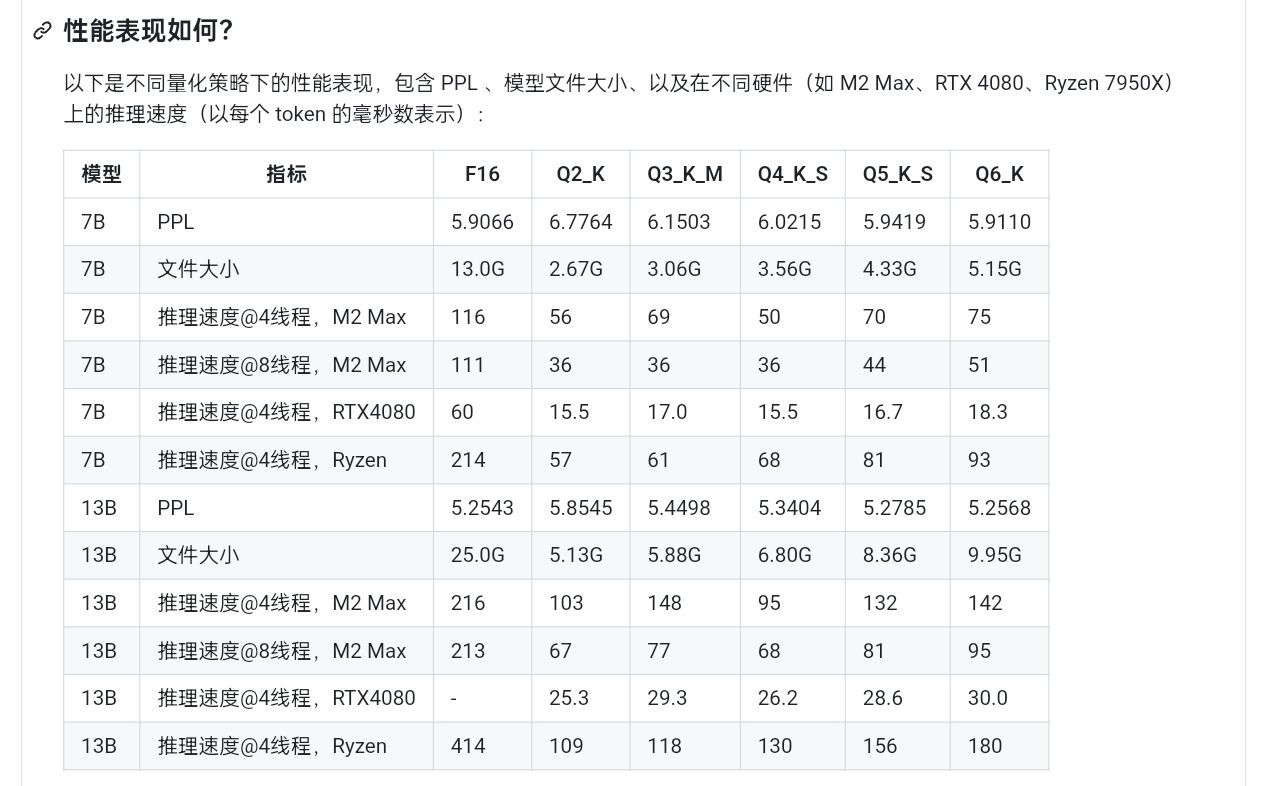
不同量化精度性能對比
也就是說,比起更高的量化精度,參數量對模型性能的影響是要更大的,這再一次證明了量化精度對模型性能的影響是有限的。各位選擇模型的時候,若以性能而非速度爲最高指標的話,大可以選擇自己的顯存能以最低的量化精度加載的參數量最大的模型,若對速度有更高要求再去選擇參數量少一點的模型。具體而言,此網頁也介紹了目前所有量化類型的具體量化方式:
https://huggingface.co/docs/hub/gguf
1.3 llama.cpp
llama.cpp是基於GGML的一個大語言模型推理工具,其能讓以LLaMA模型爲代表的多種大語言模型以量化的形式(包括Qwen系列、ChatGLM系列和MiniCPM系列等模型)在多種後端上推理起來。其內置的llama-server能夠讓模型通過OpenAI API的形式進行輸出,這代表着一系列支持自定義api的對話前端以及工具均可對其進行調用。
https://github.com/ggerganov/llama.cpp
llama.cpp支持多種計算後端,CUDA不再是唯一可選項,你可以使用AMD的hipBLAS,蘋果的Metal甚至國產摩爾線程的MUSA作爲計算的後端。對於AMD而言,hipBLAS能讓你以原生的方式完全地將顯卡的性能利用起來,而不同於Zluda和DirectML這類有明顯性能損失的轉譯運行方法,而你所需要做的僅僅是在編譯時加上GGML_HIP=ON的參數。
至此,你所需要了解的基礎背景就介紹完畢了,下面正式開始爲你自己的顯卡編譯運行llama.cpp的教學。
你首先需要做的是按照我基礎環境篇中的內容將HIP SDK安裝好:
【教程】A卡用戶Windows下AI運行完全指南-基礎環境篇
之後安裝git:
https://git-scm.com/downloads/win
下載64-bit Git for Windows Setup。
選擇64-bit Git for Windows Setup
下載後運行,將"{安裝目錄}\cmd"添加到環境變量-系統變量-Path中:
git環境變量
接着安裝cmake:
https://cmake.org/download/
選擇Windows x64 Installer
下載Windows x64 Installer後進行安裝,將"{安裝目錄}\bin"添加到環境變量-系統變量-Path中:
CMake環境變量
接着安裝ninja:
https://github.com/ninja-build/ninja/releases
從releases中選擇最新的win版本下載。
選擇win版本
下載後解壓到任意位置,將解壓的位置同樣添加到Path變量中:
ninja環境變量
接着安裝perl:
https://strawberryperl.com/
選擇MSI安裝包
下載MSI安裝包並運行安裝,正常情況下安裝程序會自動配置環境變量,若沒有則請手動添加以下3個路徑到Path中(安裝位置替換成你自己的):
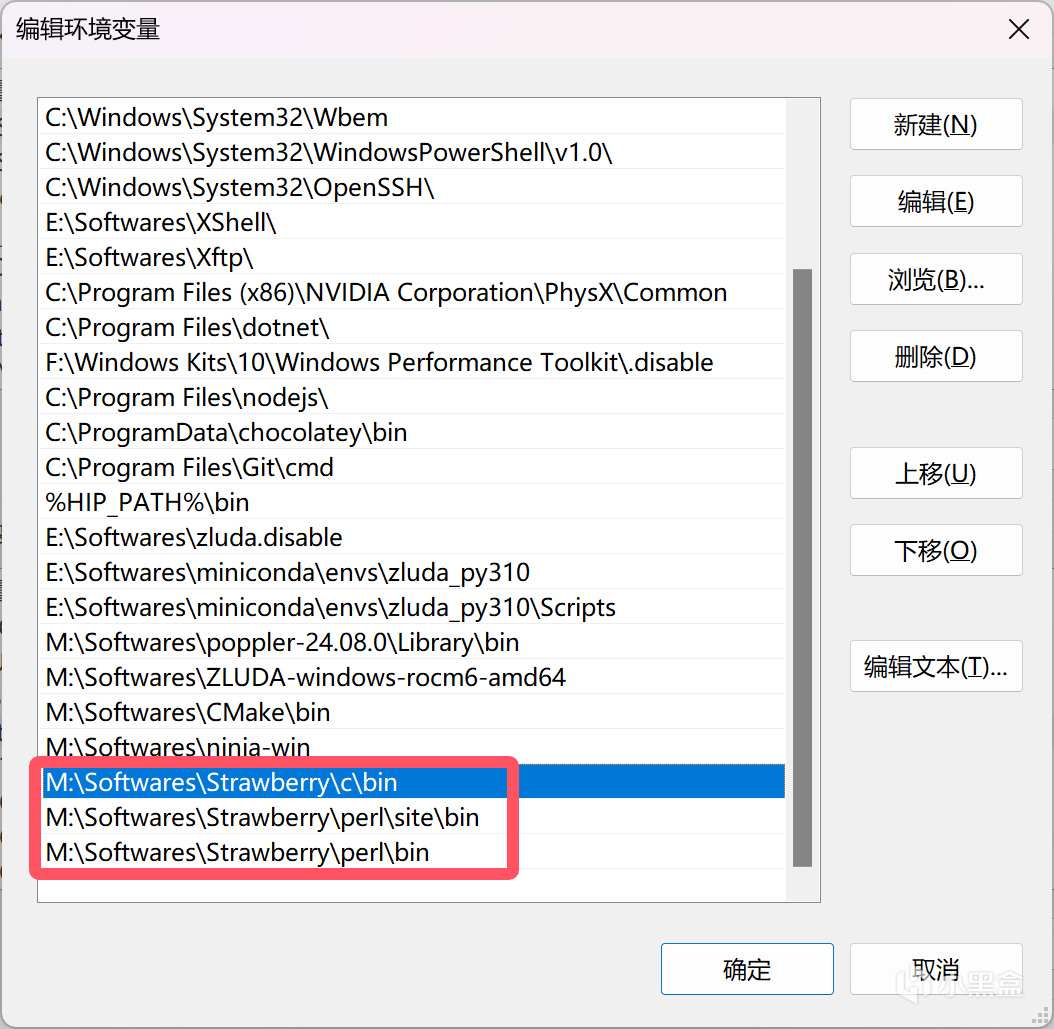
perl環境變量
接着在Visual Studio Installer中安裝Windows SDK:
https://visualstudio.microsoft.com/zh-hans/downloads/
選擇社區版
下載後打開Visual Studio Installer,安裝Visual Studio,別的想勾什麼隨便,但是Windows 11 SDK必須勾上(如果你是Windows 10那就換成任意一個Windows 10 SDK),之後等待下載安裝即可。
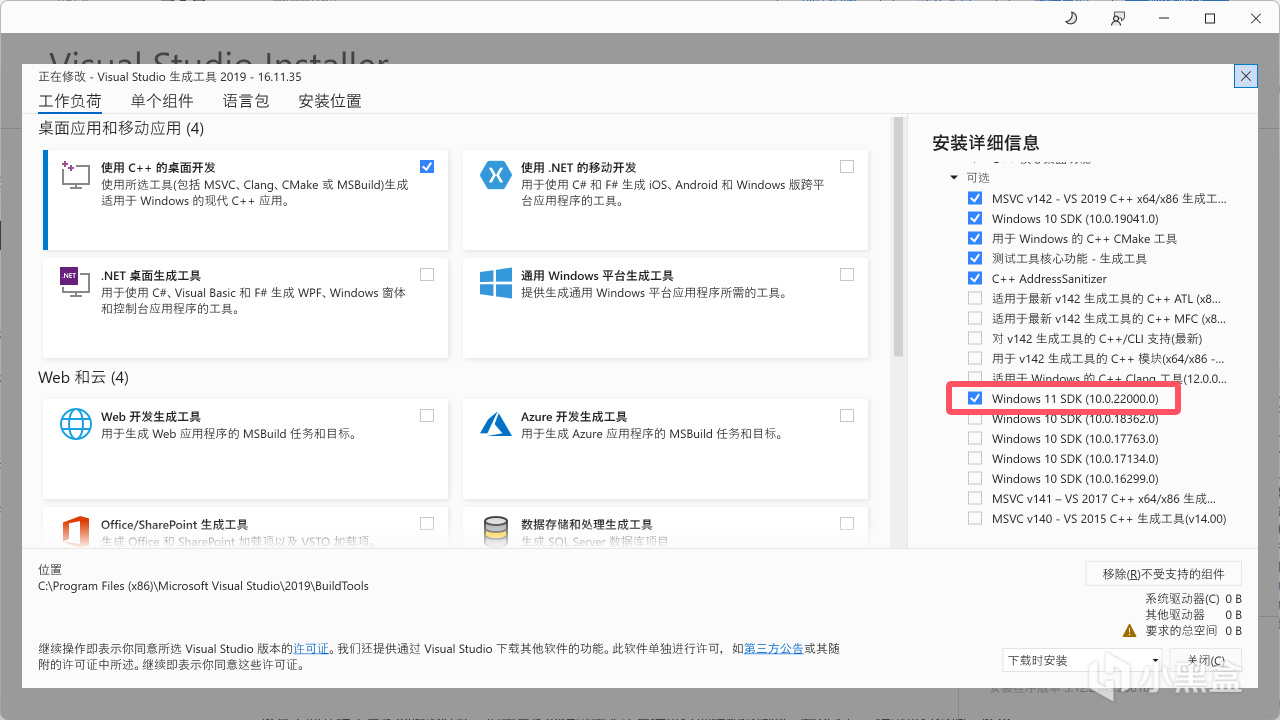
選擇Windows 11 SDK
完成這一切工具的安裝後,正式開始llama.cpp的編譯工作,打開控制檯,cd到你想要安裝llama.cpp的目錄。
cd到安裝目錄
運行如下指令,將llama.cpp的源碼clone到硬盤:
git clone https://github.com/ggerganov/llama.cpp.git
clone源碼
cd到llama.cpp的目錄:
cd llama.cpp
cd到llama.cpp的目錄
運行以下指令:
set PATH=%HIP_PATH%\bin;%PATH%
之後運行如下指令進行編譯的配置:
cmake -S . -B build -G Ninja -DAMDGPU_TARGETS=gfx1100 -DGGML_HIP=ON -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_BUILD_TYPE=Release
其中"-DAMDGPU_TARGETS=gfx1100"代表了你要編譯的目標GPU,各位請根據自己的GPU型號進行修改,如RX7900XT就是gfx1100,而RX6750GRE則是gfx1031。
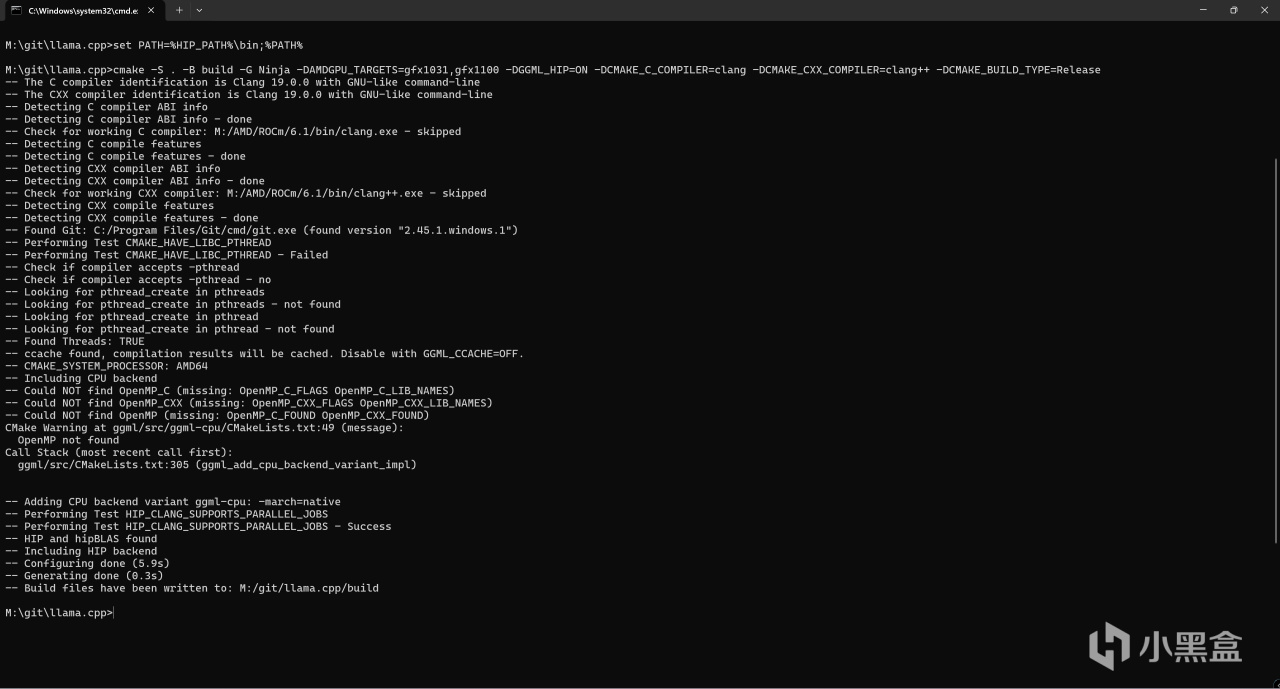
進行編譯配置
之後運行以下指令正式開始編譯:
cmake --build build
在等待十幾分鐘左右後,編譯結束。
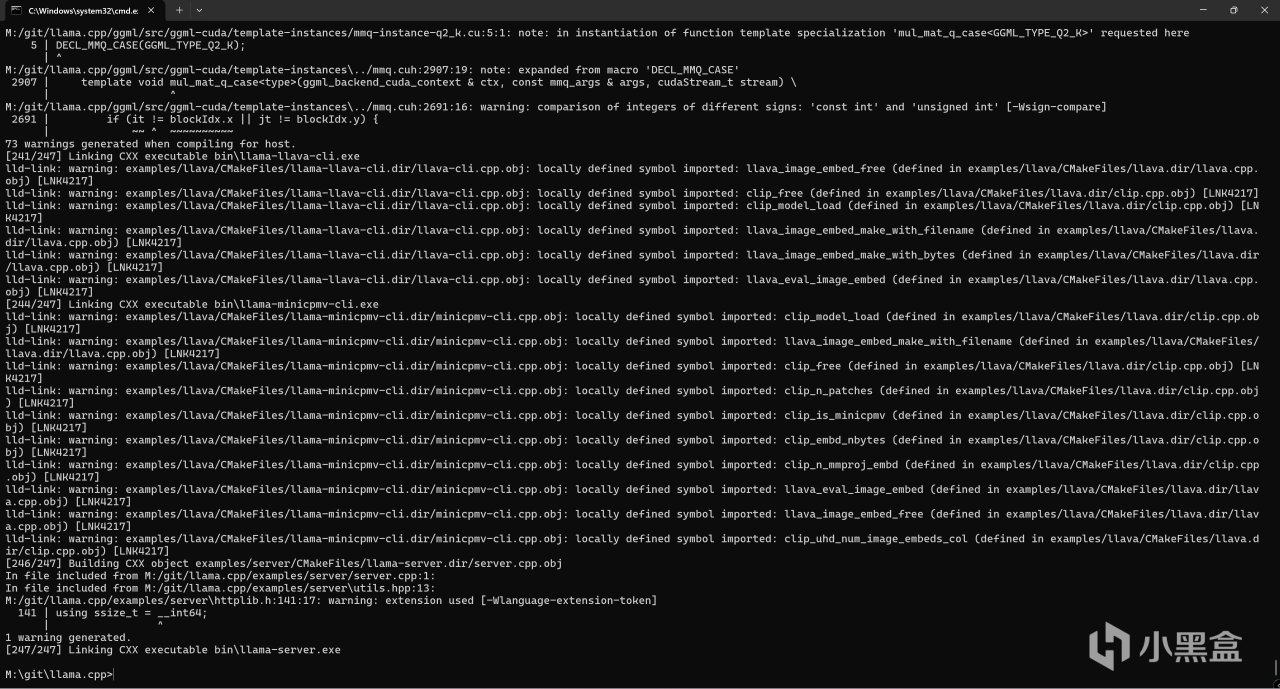
編譯結束
如果你之前已經下載過模型,那此時就已經可以正常運行了(此處僅作展示,後文會有詳細教程)。
"./build/bin/llama-cli.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf -co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." -fa -ngl 80 -n 512 -mg 0 -sm none
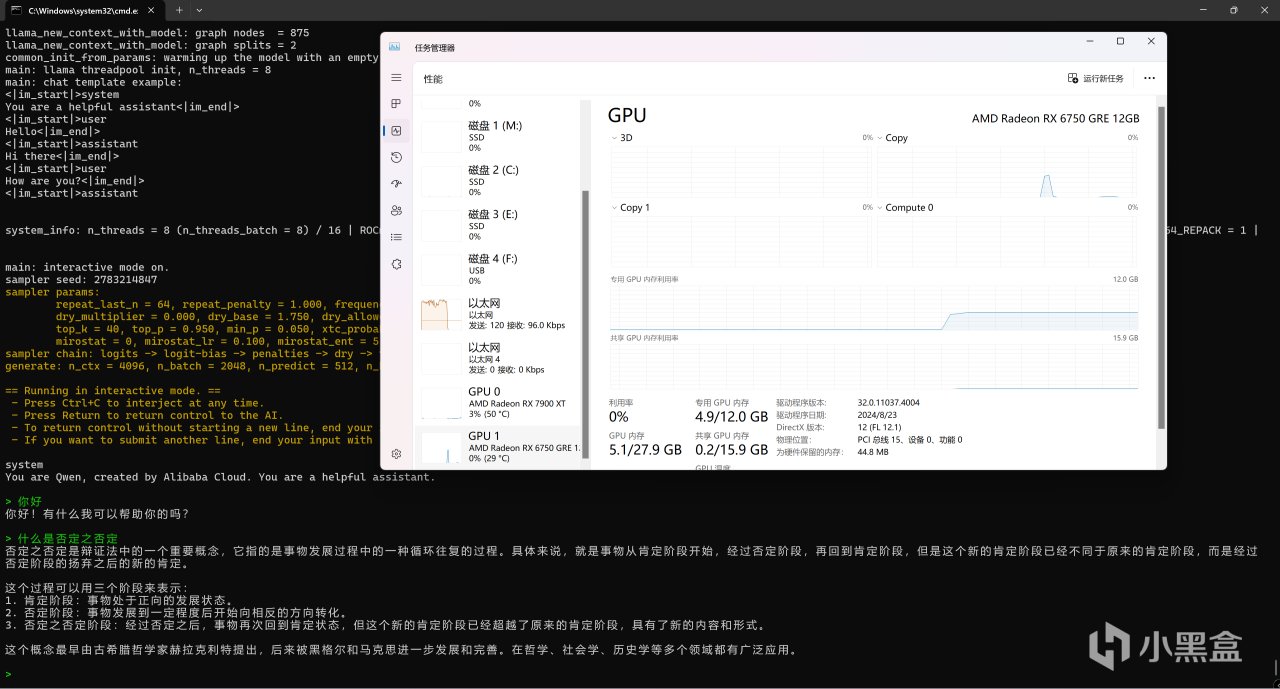
模型成功地運行在6750GRE上
6750GRE的速度也是非常的快。
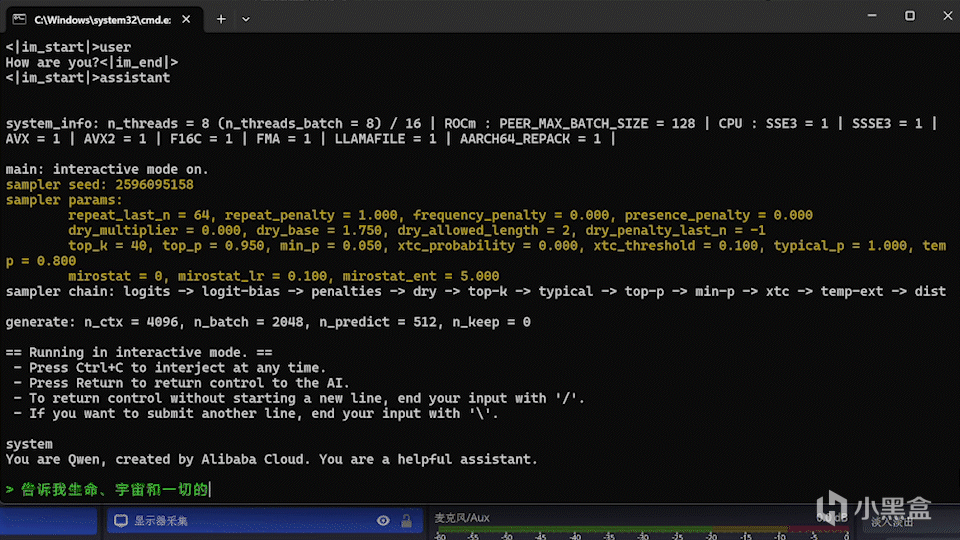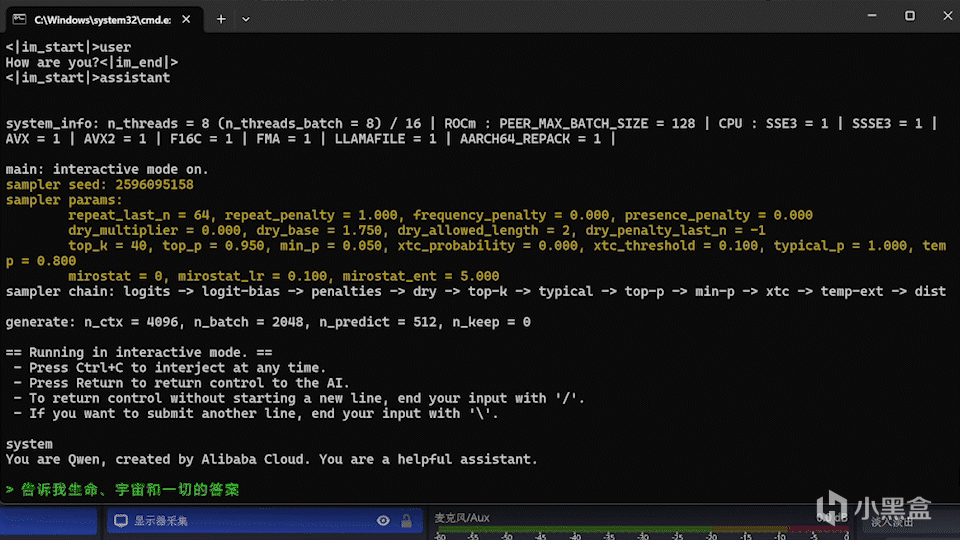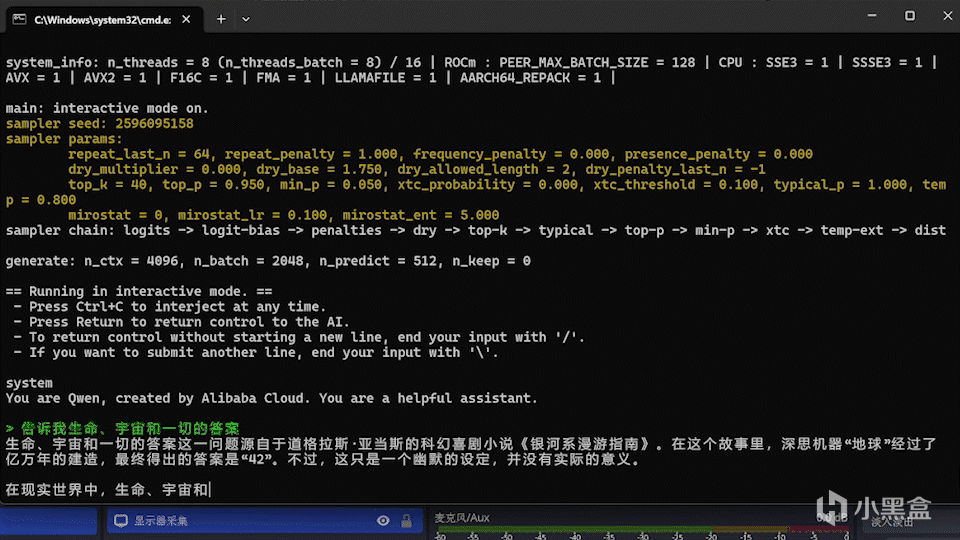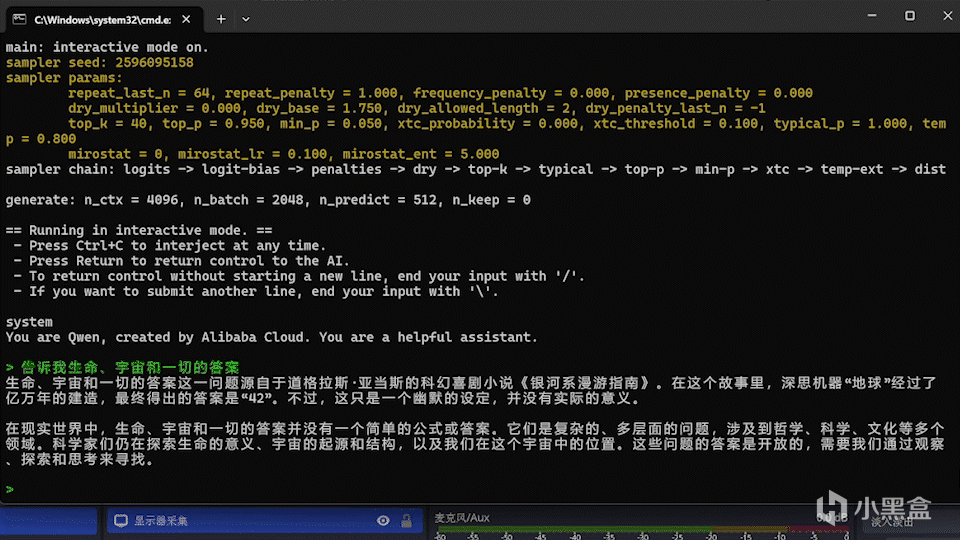
此動圖未進行任何加速
到此爲止,llama.cpp的編譯已經完全結束。如果你是gfx1100(RX7900系列)和gfx1031(RX6750和RX6700系列)的用戶,我在這裏已經給你們預編譯好了同時支持這兩種芯片的版本,你們不用再親自編譯。但需要注意的是,即使我現在這個版本是截止2024年12月02日的最新版,但是由於我的精力有限,我不會對此版本進行更新。對於以後的更新,gfx1100用戶可自行到github項目原地址的releases頁面下載官方編譯的對應的版本,gfx1031的用戶則需要根據我上面的步驟自行編譯。而其他GPU的用戶,也請根據我上面的步驟自行編譯。
llama.cpp(gfx1031&gfx1100).7z 百度網盤:
https://pan.baidu.com/s/1cbzSidjb1UAiQBLzFvmw0Q?pwd=23vc
llama.cpp(gfx1031&gfx1100).7z 夸克網盤:
https://pan.quark.cn/s/d5430743a50c
1.4 HuggingFace
上面有提到下載模型後進行運行,而大部分情況下,我們下載預訓練模型的來源就是HuggingFace了。HuggingFace是一個廣受歡迎的開源平臺,其專注於各類深度學習模型的分享與交流,目前已有大量模型在HuggingFace上進行發佈,在這裏我以Qwen/Qwen2.5-7B-Instruct-GGUF爲例介紹模型的下載與運行,各位的GPU若具有更大的顯存則可選擇32B乃至更多參數的模型。
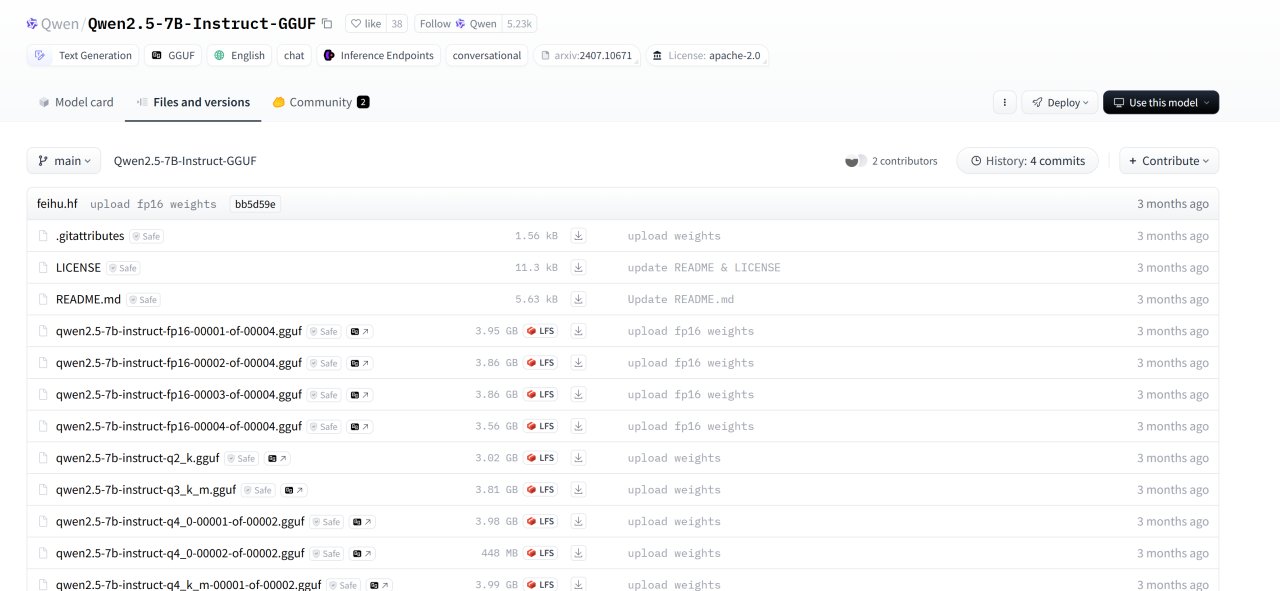
HuggingFace頁面
儘管我們可以從網頁上直接下載模型,但不同於環境只用配置一次,我們往往要不斷地下載新的模型,而不少模型的大小動輒就是幾十GB,從流量的角度考慮,鏡像的使用就顯得很有必要。不僅如此,對於一些要求驗證的模型(如Stable Diffusion 3.5),我們無法直接從鏡像的網頁進行下載,此時我們就需要用到huggingface-cli這個工具了。
首先通過如下指令安裝huggingface-cli:
pip install -U huggingface_hub
之後編輯環境變量,新建變量HF_ENDPOINT並設置爲https://hf-mirror.com,將huggingface-cli的下載源修改爲國內鏡像站。
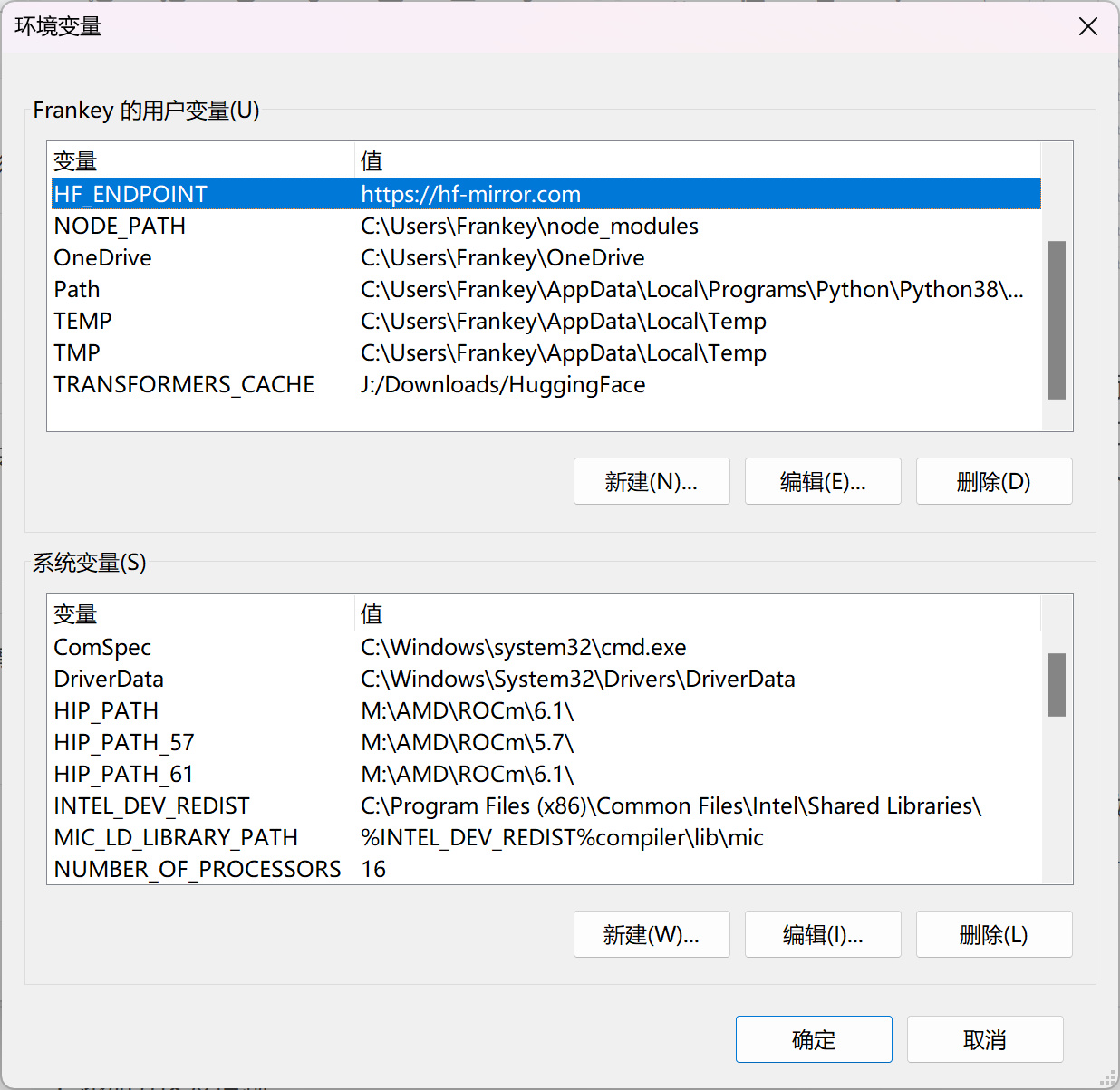
HF_ENDPOINT變量
設置好環境變量後,可正式開始模型權重的下載,Qwen2.5-7B-Instruct-GGUF具有多個量化版本,量化的定義在上文"GGUF"一節中已有介紹,在這裏我以q4_k_m量化的版本爲例:
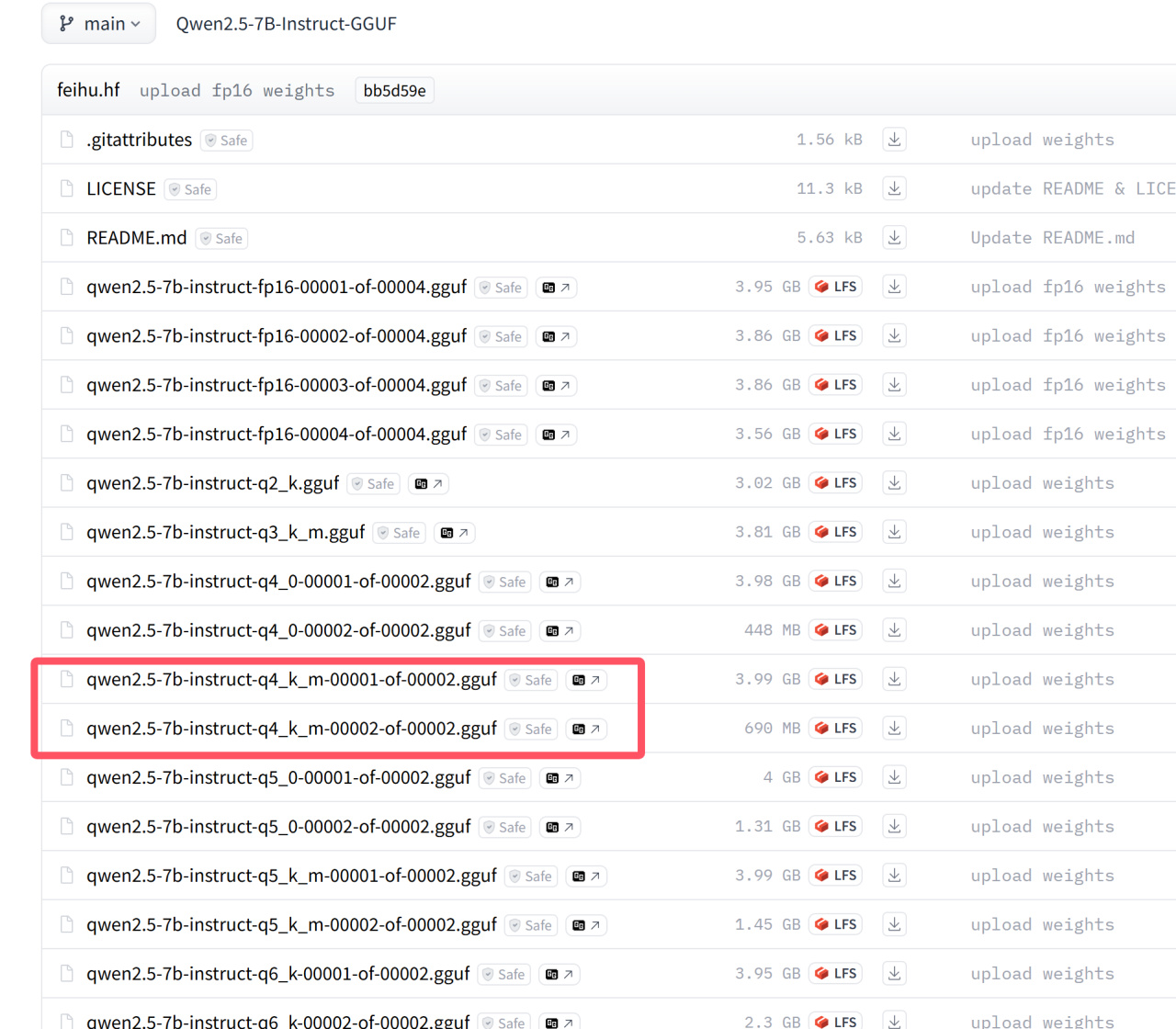
不同的量化版本
運行如下指令對模型進行下載:
huggingface-cli download --resume-download Qwen/Qwen2.5-7B-Instruct-GGUF --include "qwen2.5-7b-instruct-q4_k_m*.gguf" --local-dir J:\Downloads\HuggingFace\Qwen2.5-7B
--include 參數表示要下載的文件
--local-dir 改爲你自己的保存路徑
下載完成後,cd到llama.cpp的目錄,運行如下指令將兩個gguf文件合併爲單個文件:
"./build/bin/llama-gguf-split" --merge J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m-00001-of-00002.gguf J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf
第一個路徑是模型列表的首個文件,第二個路徑是合併完成後模型的保存路徑,請自行將這兩個路徑替換爲你自己的路徑。
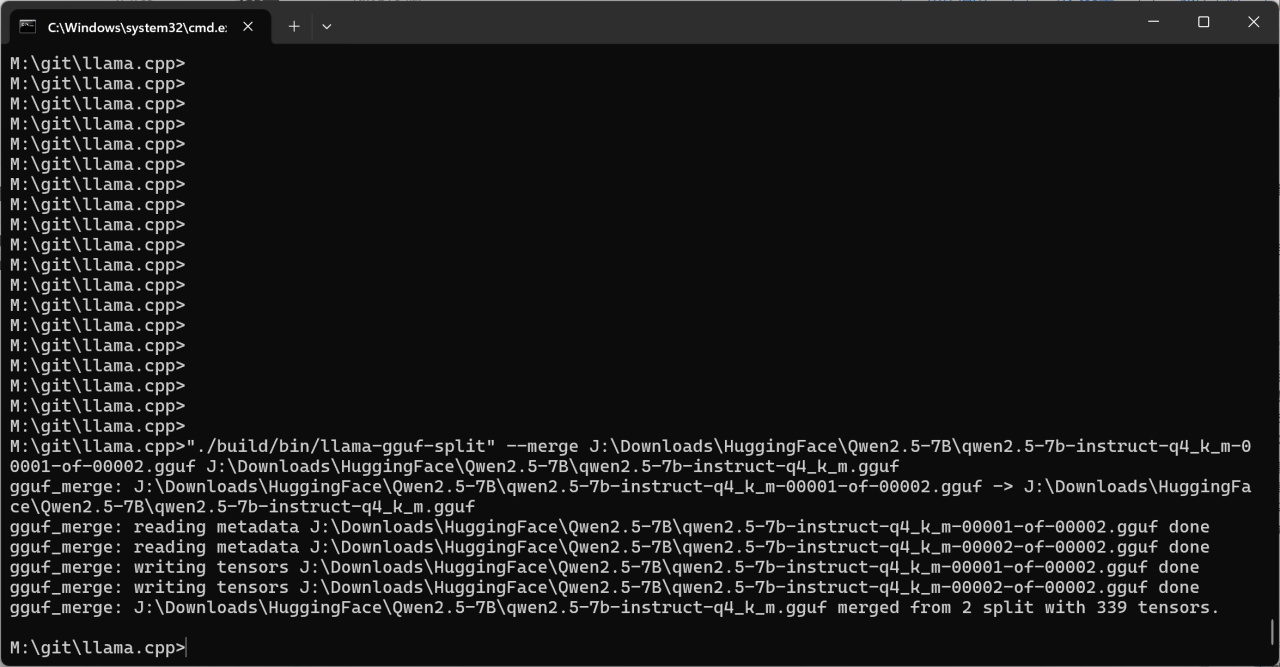
合併模型文件
此時我們就將權重轉換爲了單個文件,運行以下指令可在命令行中進行測試:
"./build/bin/llama-cli.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf -co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." -fa -ngl 80 -n 512 -mg 0 -sm none
模型成功地運行在6750GRE上
6750GRE的速度也是非常的快。
此動圖未進行任何加速
測試完畢後按Ctrl+C退出程序,運行如下指令啓用api監聽:
"./build/bin/llama-server.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf --port 8084 -a qwen -fa -ngl 80 -n -2 -c 32768 -mg 0 -sm none --host 0.0.0.0
--port 8084 表示監聽的端口
--host 0.0.0.0 表示監聽任意地址,默認只會監聽127.0.0.1的本地地址
-n -2 表示輸出內容長度無限制(直到填滿上下文)
其他各個參數的含義詳見以下頁面,也可以對api_key進行設置(此例子未進行設置):
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
啓動完成後即可通過OpenAI API進行訪問了。
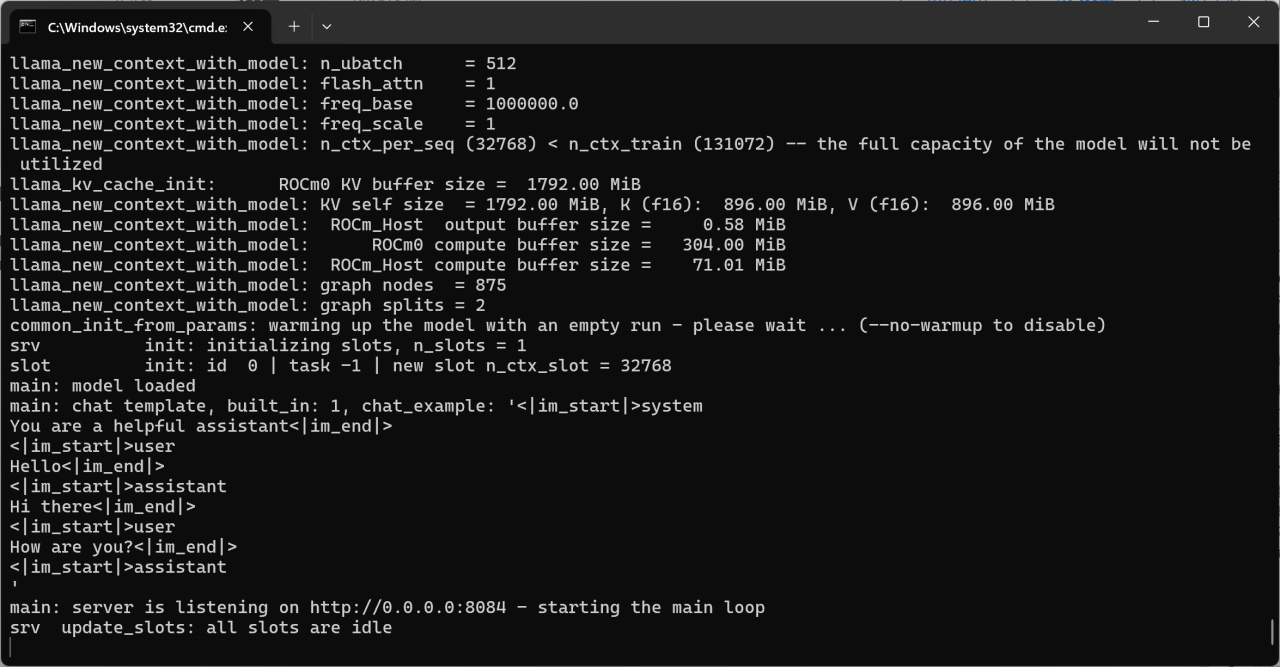
服務器啓動完畢
以https://github.com/Dooy/chatgpt-web-midjourney-proxy項目爲例,進入項目前端後將API接口和API Key(上面沒設置所以此處不需要)設置好並保存。
項目體驗地址,可直接打開:https://vercel.ddaiai.com/#/chat/1002
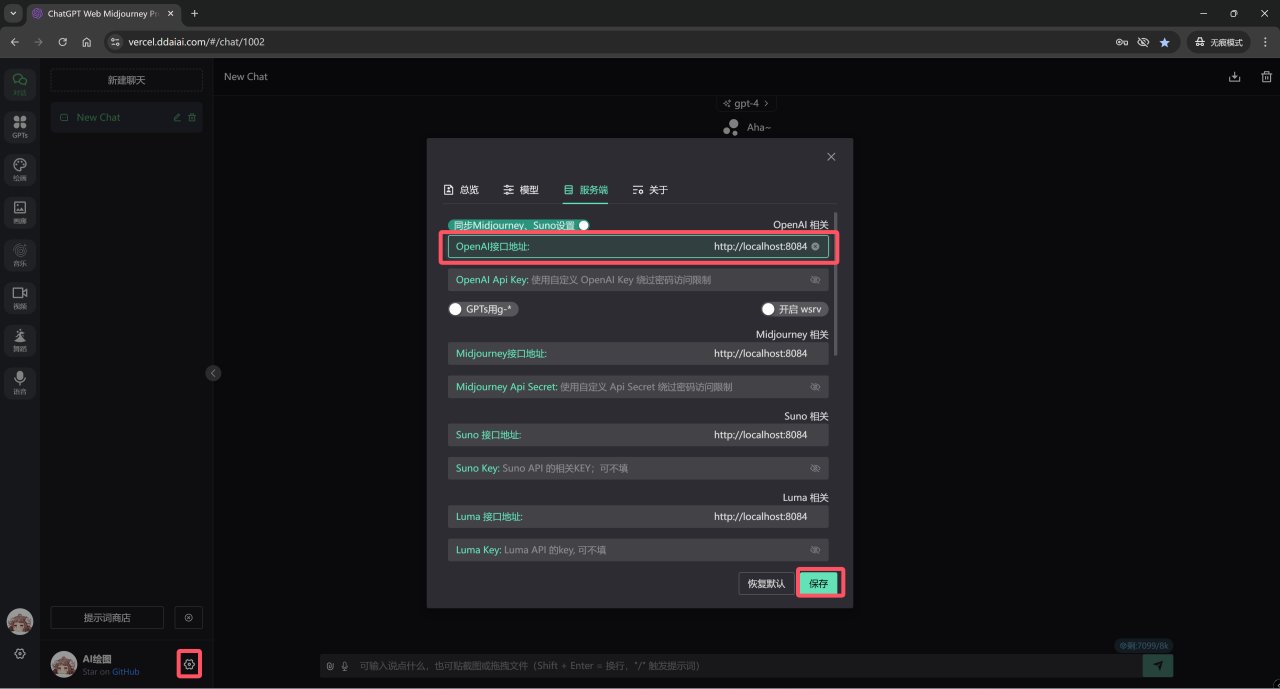
設置API
設置好之後就可以直接進行對話,不需要特地指定模型名字,任何模型名字(包括默認的gpt-4)都會被直接忽略掉:
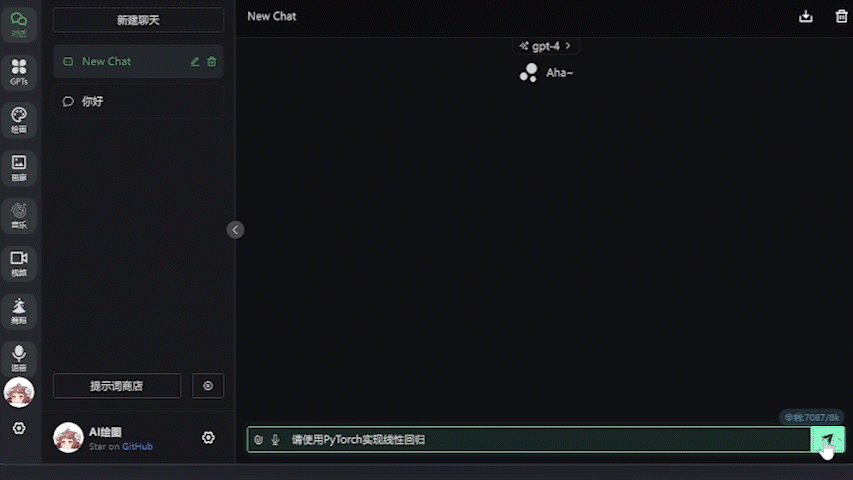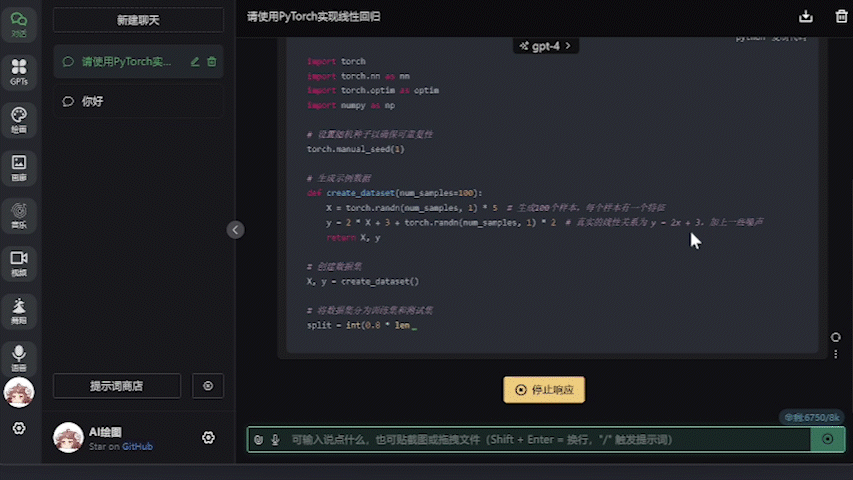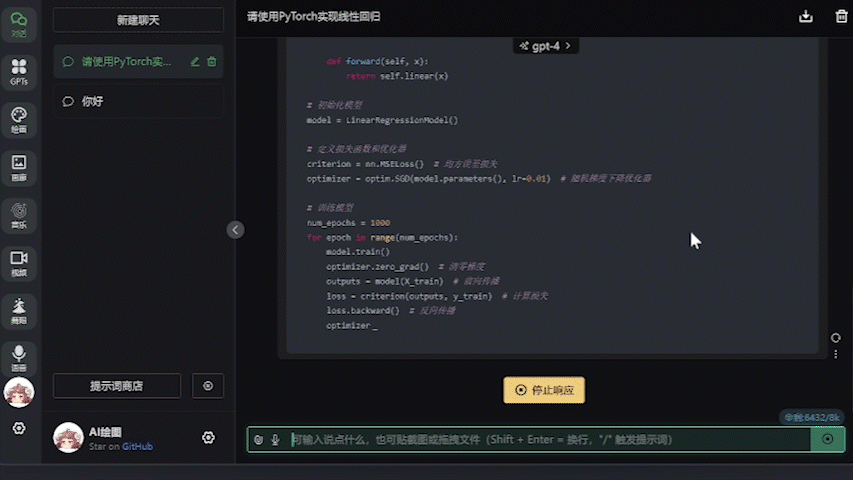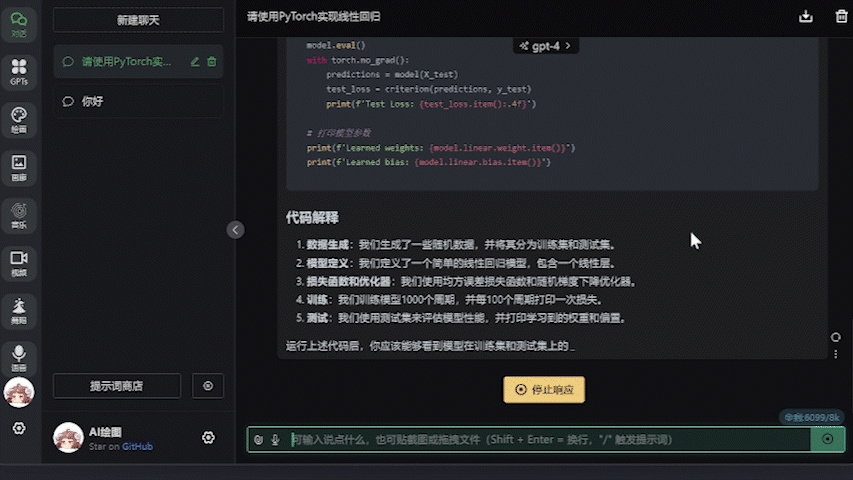
運行測試
可以看到6750GRE的生成速度是足夠快的(後臺數據在50token/s左右),並且爲壓縮動圖大小我將幀率限制在了4幀/s,而實際使用的時候是非常流暢的。
到此,你已經成功地將大模型運行在了你的AMD GPU上,同時成功通過API進行了監聽,上面的項目是一個最典型的例子,任何可以設置OpenAI API的項目均可以以你本地的這個大模型爲後端進行運行,從此在大量使用的時候不再爲API大量付費,並將數據牢牢握在自己的手中,更不需要爲此去買一張性能少量提升價格卻巨幅增加的N卡。
2.使用LLaMA Factory進行微調
儘管上面介紹了量化的諸多好處,但是量化的模型是無法直接進行訓練和微調的,要對大語言模型進行微調,依然需要使用其原始的形式。介於我的GPU只有20G的顯存,本文將以4B的MiniCPM 3.0爲例,介紹如何通過LLaMA Factory對大模型進行微調。
此部分教程基於MiniCPM的官方文檔,有基礎的讀者可自行閱讀:
https://modelbest.feishu.cn/wiki/PpUrwsmDAiAAoEk8jc8cnBh7nOh
要進行下面的操作,你應該已經按照上一篇教程中的內容在WSL中安裝好了AMD提供的PyTorch並進行了後續的配置,若還沒有完成基礎環境配置的讀者請閱讀上一篇教程:
【教程】A卡用戶Windows下AI運行完全指南-基礎環境篇
考慮到效率,此教程以上篇教程中WSL中的環境爲例,不對Zluda如何配置進行介紹。
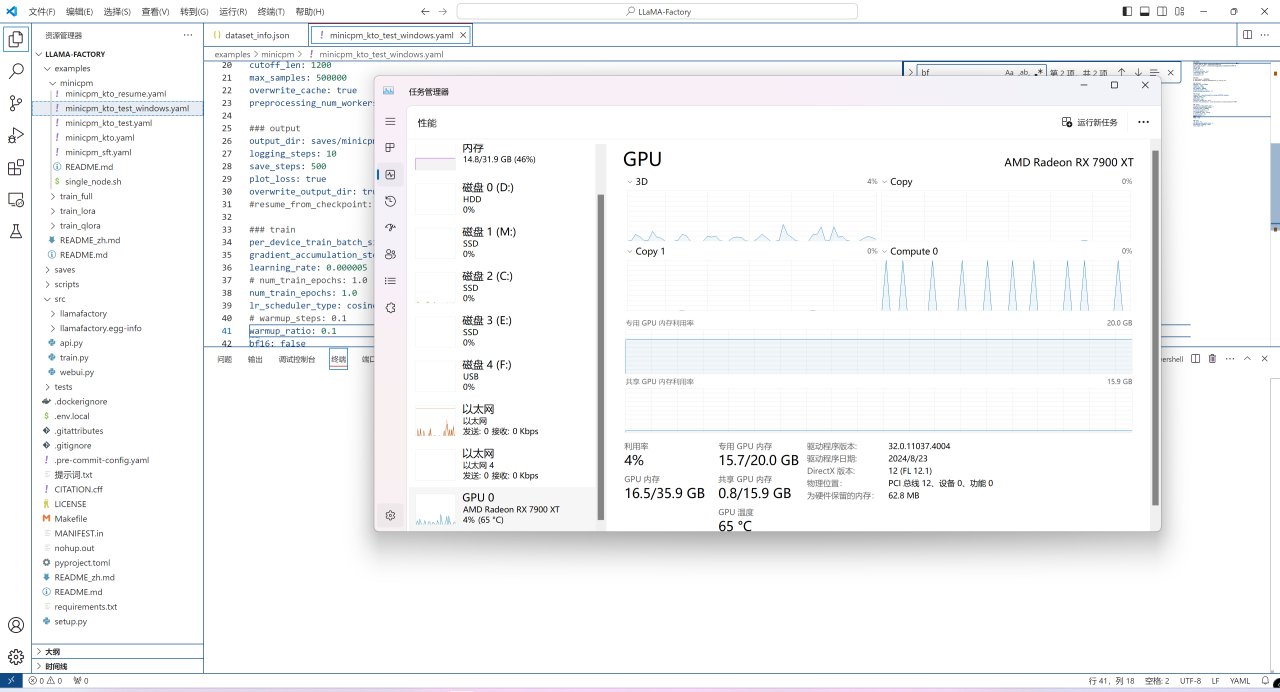
Zluda儘管能夠成功運行,但是效率不足
首先進入WSL中,cd到你認爲合適的目錄,運行以下命令clone源碼:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
儘管可以直接在已安裝好的環境上進行操作,但爲了避免重複安裝PyTorch,我這裏選擇從基礎環境clone一份環境,請自行將以下指令的目標和源替換爲自己的路徑:
conda create --prefix /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/llama-factory --clone /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/torch310
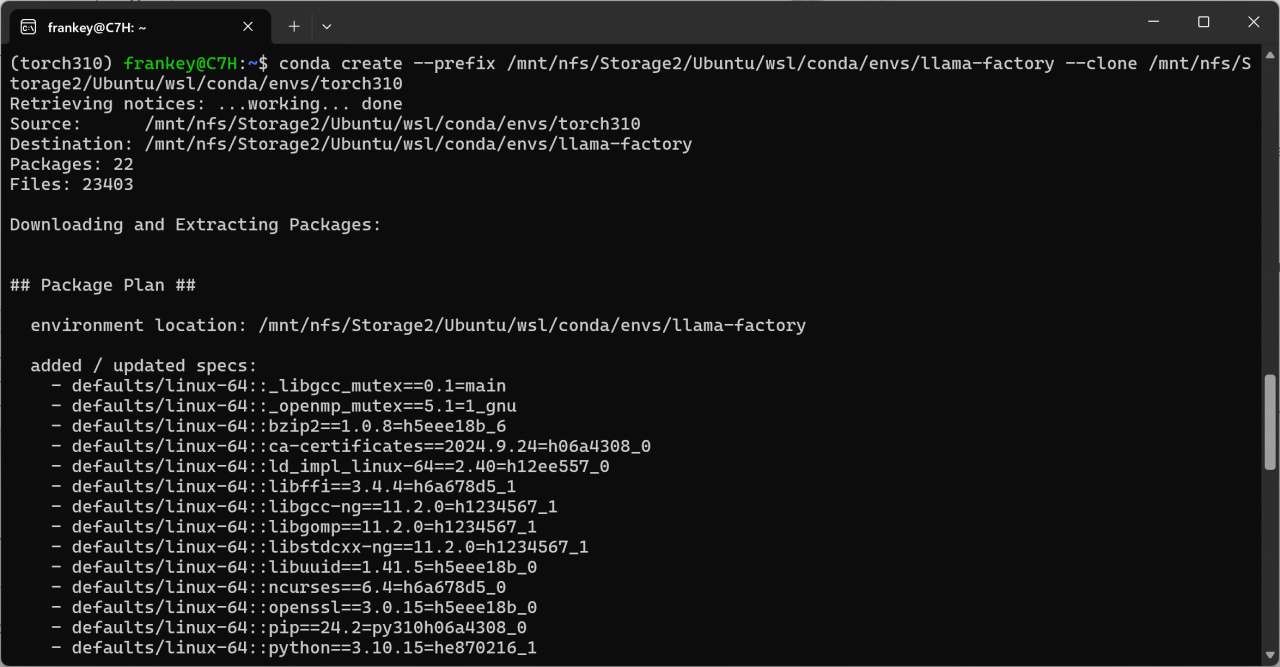
克隆已有PyTorch的基礎環境
之後,爲方便修改代碼和配置文件,直接使用VS Code打開WSL中的文件夾,首先安裝VS Code:
https://code.visualstudio.com/download
選擇System Installer (x64)
選擇System Installer (x64)
安裝好後會提示設置語言爲中文,之後打開商店安裝Remote - SSH遠程資源管理器(如果剛纔沒設置中文的話也可以在商店裏面搜索Chinese來安裝)。
安裝遠程資源管理器
之後安裝WSL拓展:
安裝WSL拓展
之後在遠程資源管理器中切換爲WSL目標,並選擇“在當前窗口中連接”:
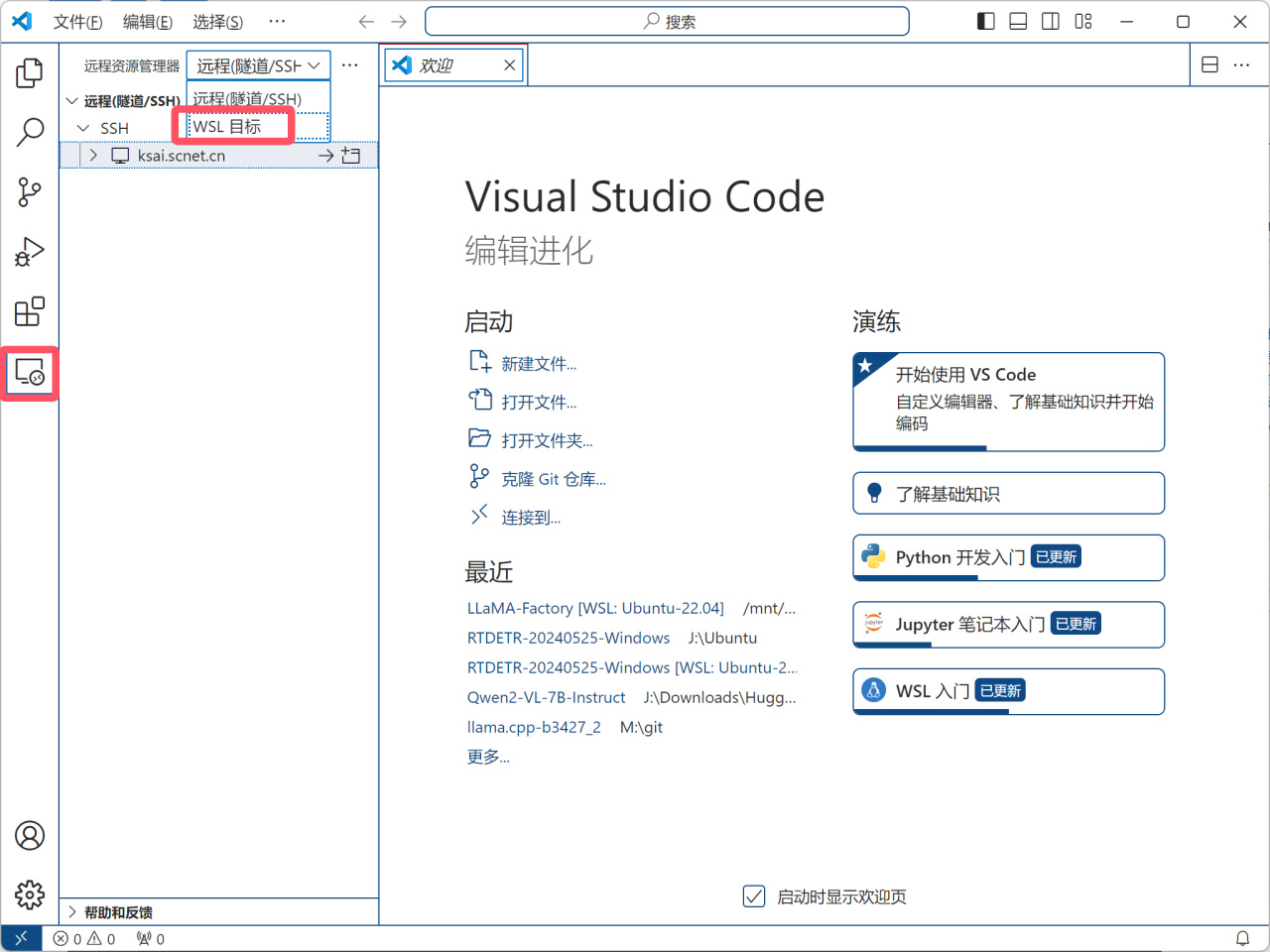
切換爲WSL目標
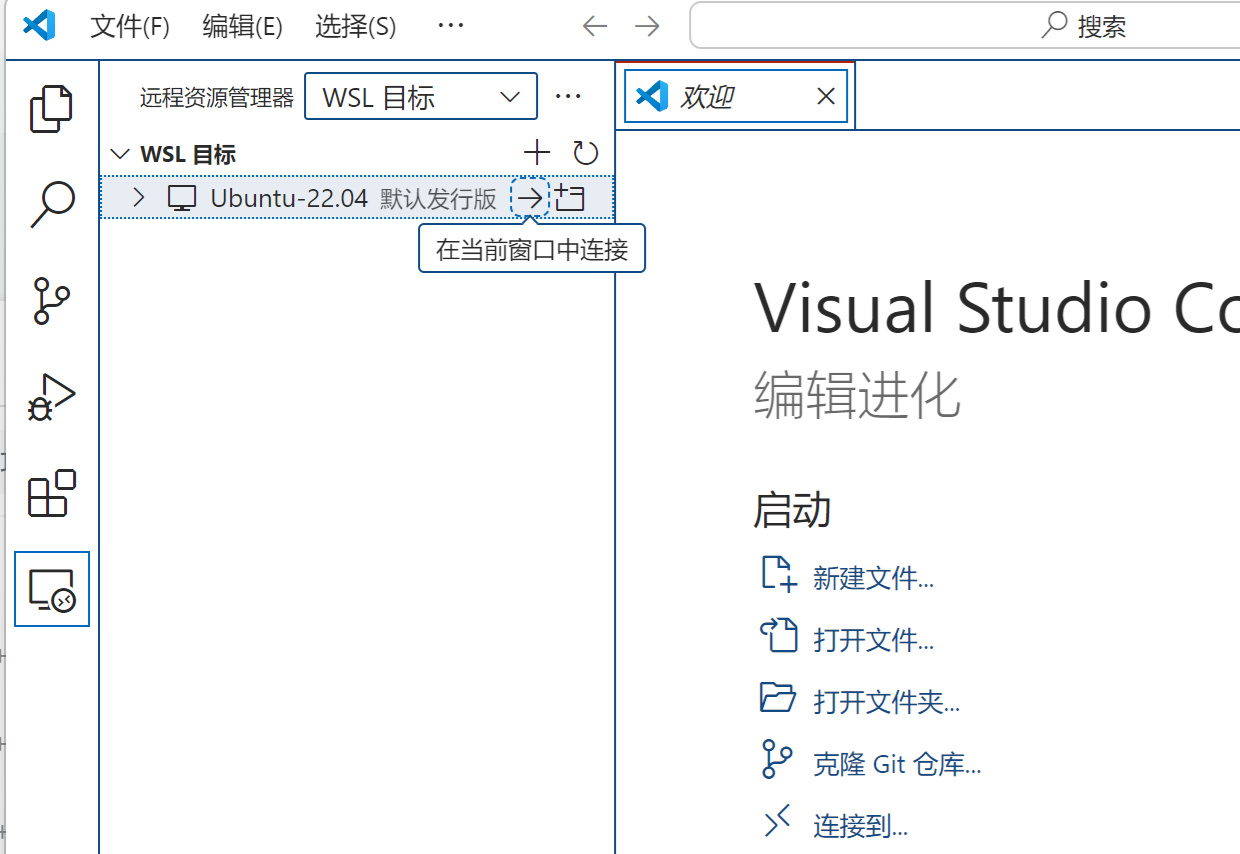
在當前窗口中連接
之後選擇菜單欄-文件-打開文件夾,打開LLaMA-Factory的源碼目錄,點擊setup.py,在extra_require中找到torch一行並按Ctrl+K+C註釋掉:
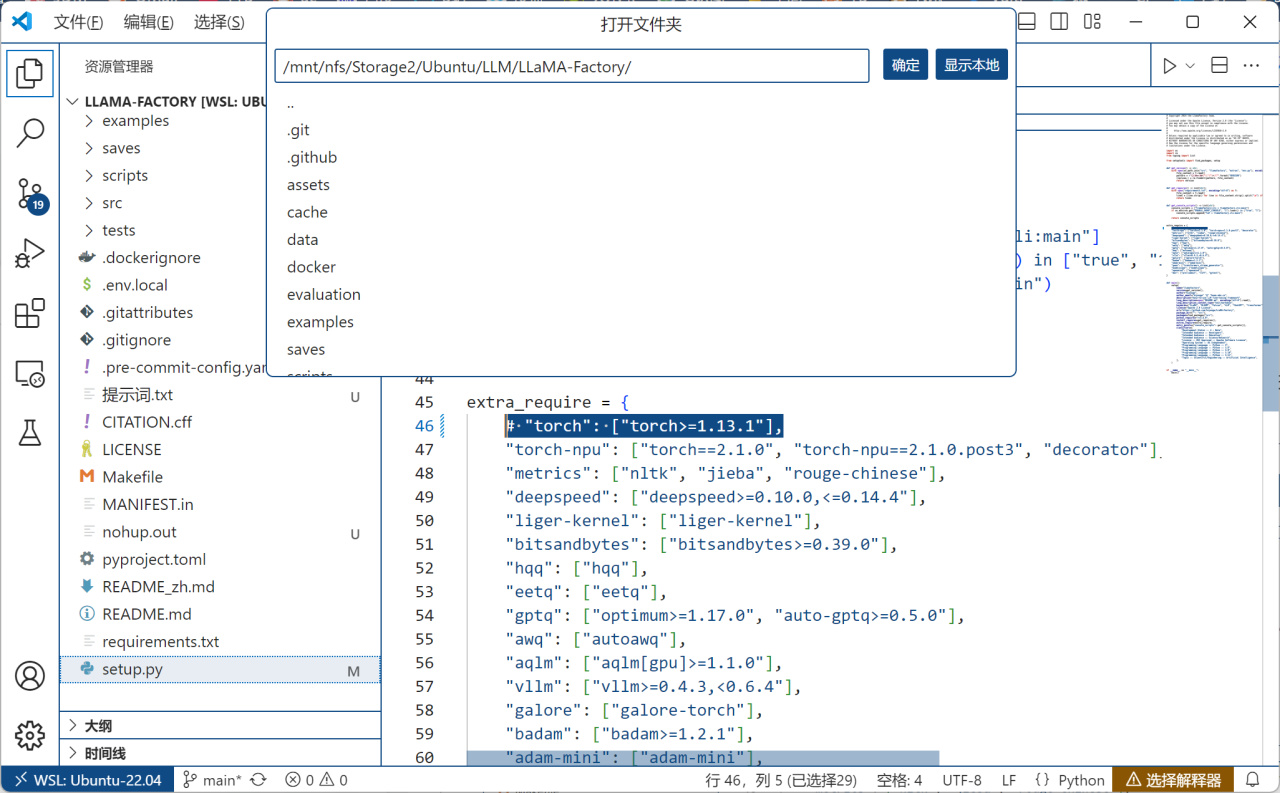
防止重複安裝PyTorch
菜單-終端-新建終端打開一個WSL中的終端:
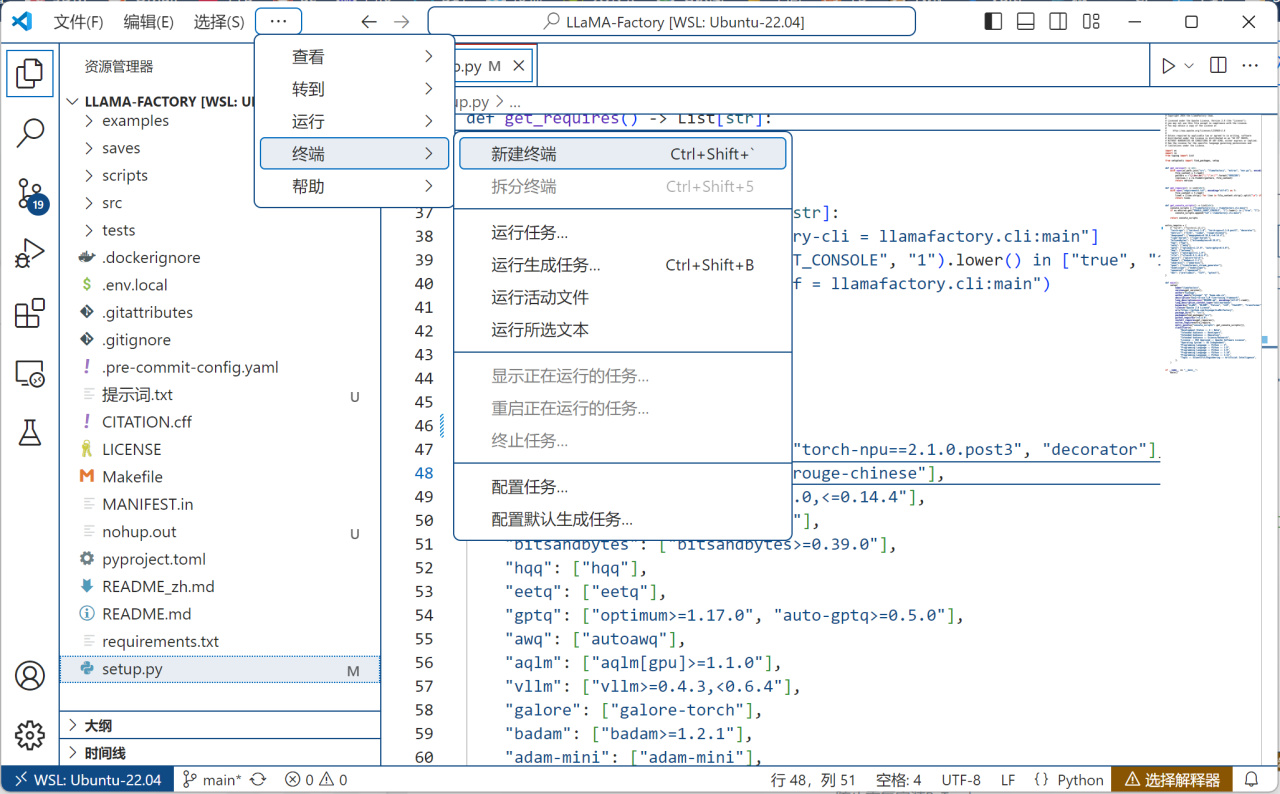
新建終端
切換到剛纔克隆的環境中(自行替換爲你自己的路徑):
conda activate /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/llama-factory
切換環境
運行以下命令安裝LLaMA Factory所需要的PyTorch以外的其他環境:
pip install -e ".[metrics]"
其他環境的安裝
暫時離開LLaMA Factory,新開一個終端在你認爲合適的目錄將MiniCPM相關的代碼clone下來:
git clone https://github.com/OpenBMB/MiniCPM.git
之後回到原來的終端,將微調的相關配置和代碼複製到LLaMA-Factory的對應目錄中:
cd LLaMA-Factory/examples
mkdir minicpm
# 以下代碼中的/your/path要改成你的MiniCPM代碼和LLaMA-Factory路徑
cp -r /your/path/MiniCPM/finetune/llama_factory_example/* /your/path/LLaMA-Factory/examples/minicpm
複製微調配置
之後準備好你的數據集,剛纔複製的文件中提供了dpo、kto和sft三種格式的數據格式示例:
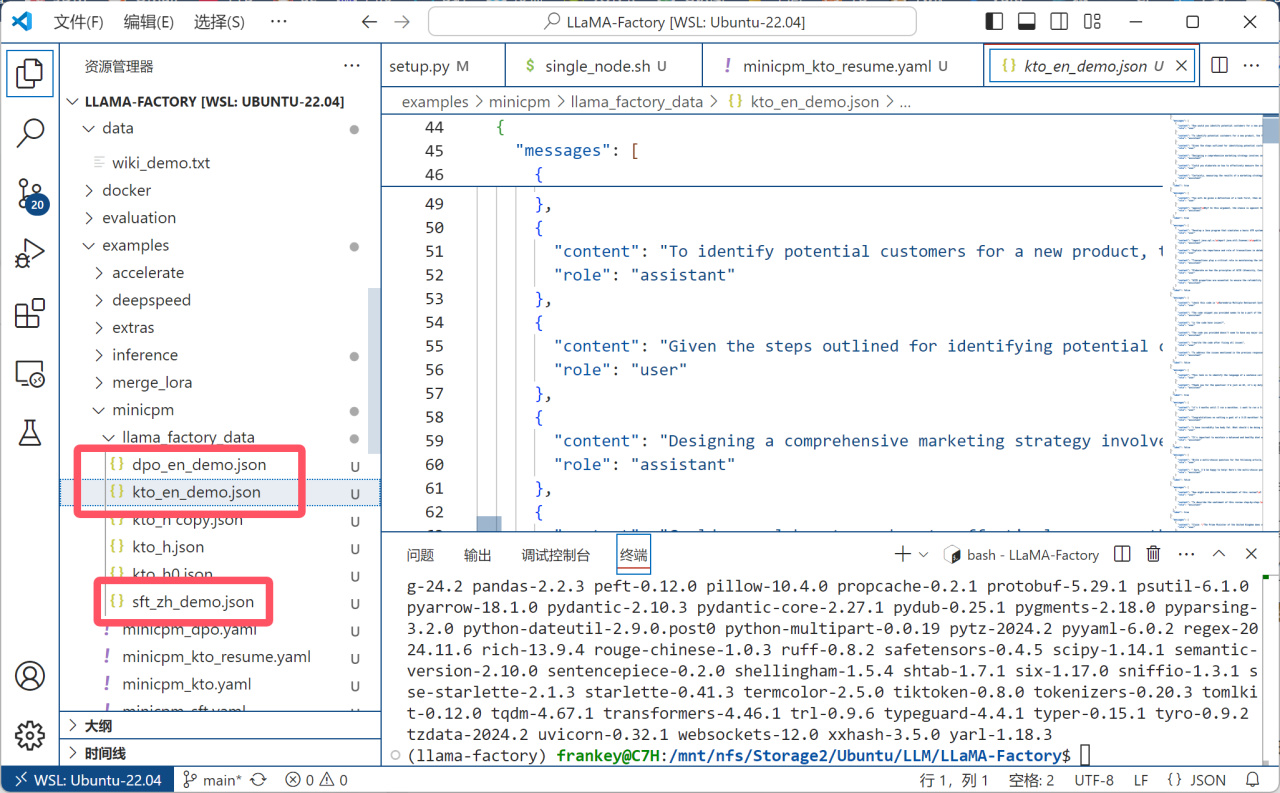
數據格式示例
這裏以kto格式爲例進行演示,具體介紹詳見上面貼出的官方文檔鏈接,其主要特點爲每個問題和回覆都可以有一個true(好的),或者false(不好的評價):
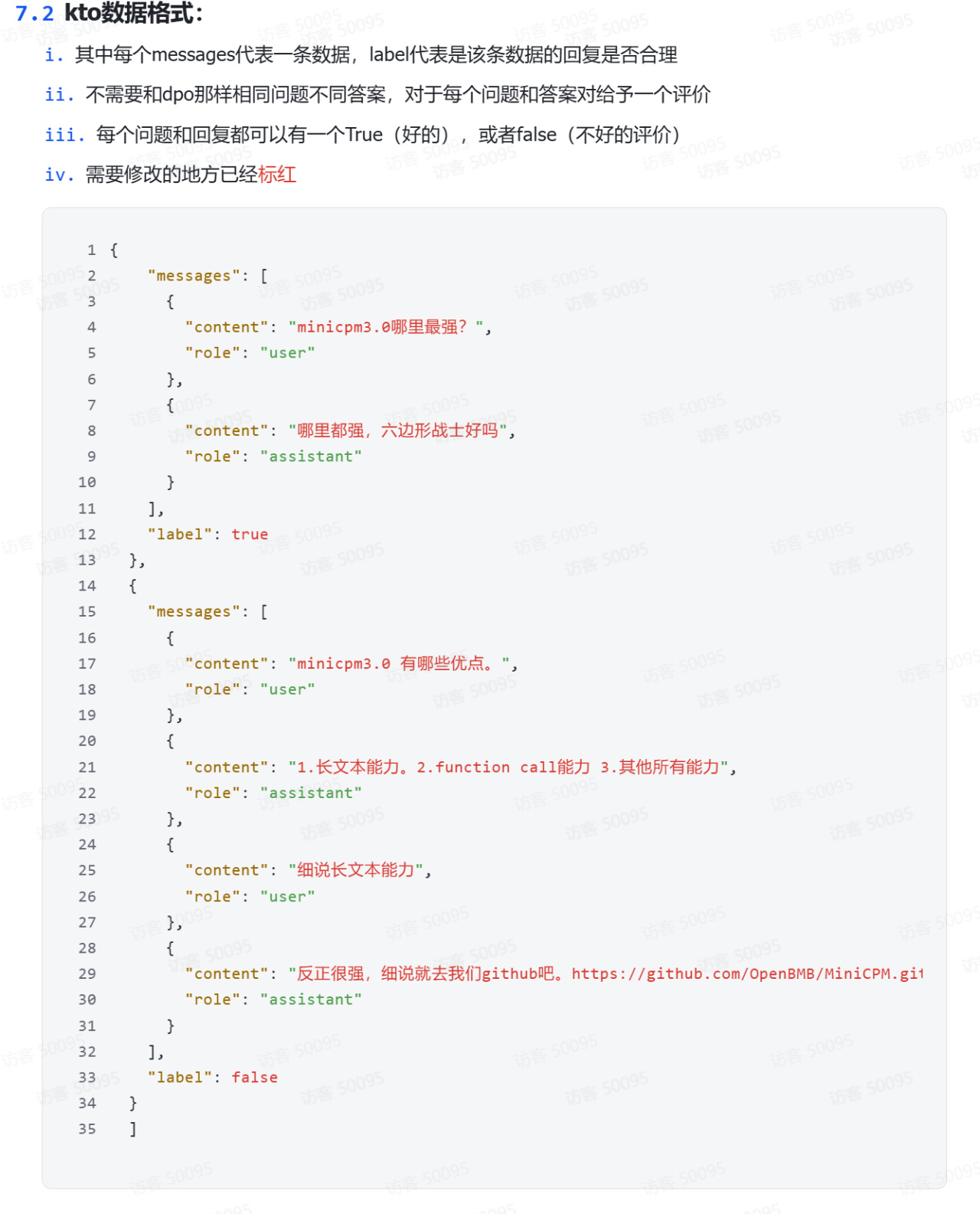
kto格式數據集
我在此處自己爬取並製作了一個具有750組對話的數據集,各位可根據自己的需求自行準備數據集,也可以只給幾組簡單的"你是誰"的對話,這同樣是有效果的。
數據集
之後在llama_factory/data/dataset_info.json中添加數據集信息,保證dataset_info.json中能找到你的數據集:
"數據集名字": {
"file_name": "/改成/你剛纔創建的/數據集/的位置.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"kto_tag": "label"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
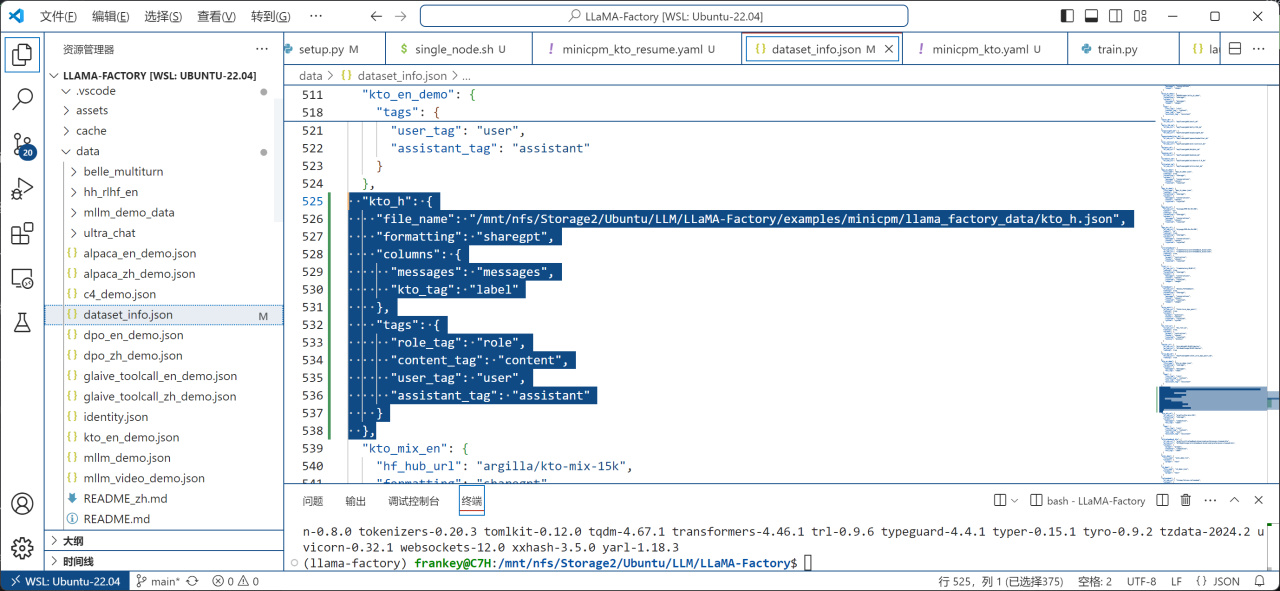
添加數據集信息
之後按照上文中的方式,通過huggingface-cli下載openbmb/MiniCPM3-4B到你指定的目錄,唯一不同的是,做爲Linux,你需要運行以下指令來設置鏡像地址環境變量:
export HF_ENDPOINT=https://hf-mirror.com
模型下載完成後,即可對訓練配置進行修改,從之前複製的examples/minicpm/minicpm_kto.yaml示例中再複製一個新的配置文件,並做如下改動:
將model_name_or_path設置爲你剛纔從HuggingFace下載模型權重的目錄;
將finetuning_type從full改爲lora;
添加lora_target參數並設置爲all;
註釋掉kto_ftx參數;
註釋掉ddp_timeout參數;
註釋掉deepspeed參數;
將dataset從kto_harmless修改爲你剛剛在llama_factory/data/dataset_info.json中設置的數據集名字;
將template從cpm修改爲cpm3;
將output_dir修改爲你想將Lora權重保存在的目錄;
將per_device_train_batch_size從4改爲1以防止顯存不足;
將gradient_accumulation_steps從4改爲1;
將num_train_epochs從1改爲你想要的迭代次數(走過你一整個數據集的次數);
將warmup_steps參數改爲warmup_ratio,否則會報錯;
將per_device_eval_batch_size從16改爲1以防顯存不足。
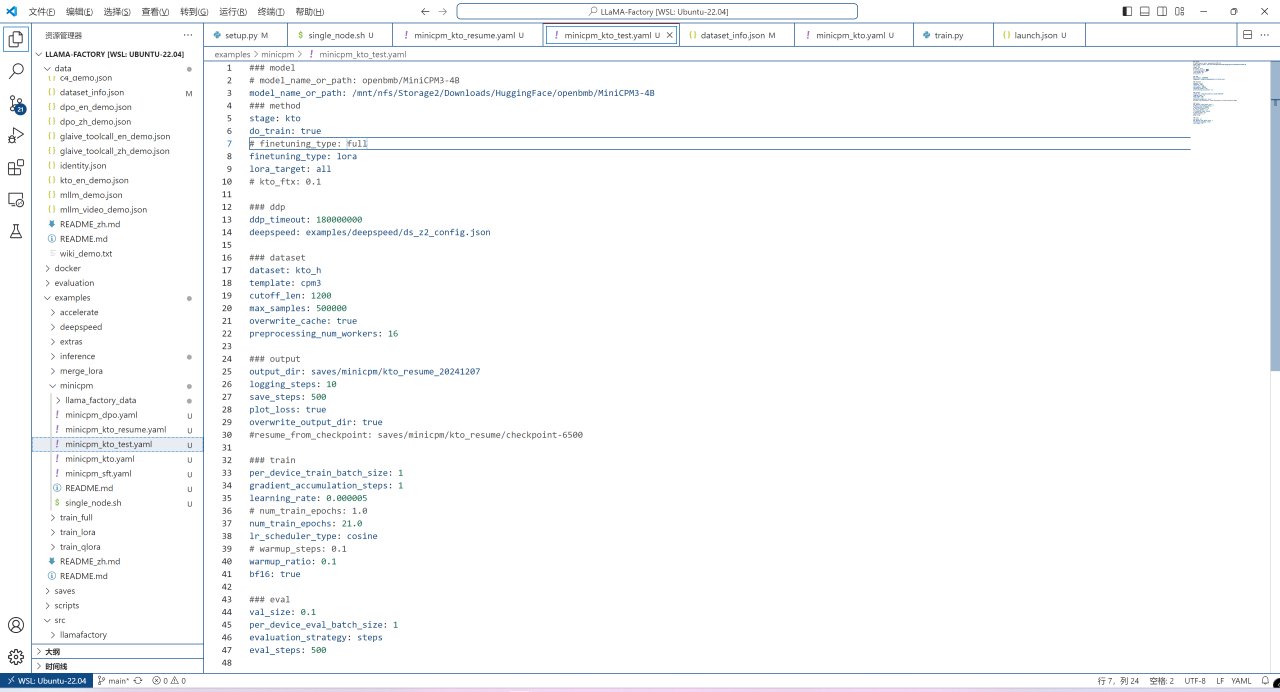
修改訓練配置文件
之後選擇菜單-運行-添加配置,選擇"Python Debugger",再選擇"帶有參數的Python文件":
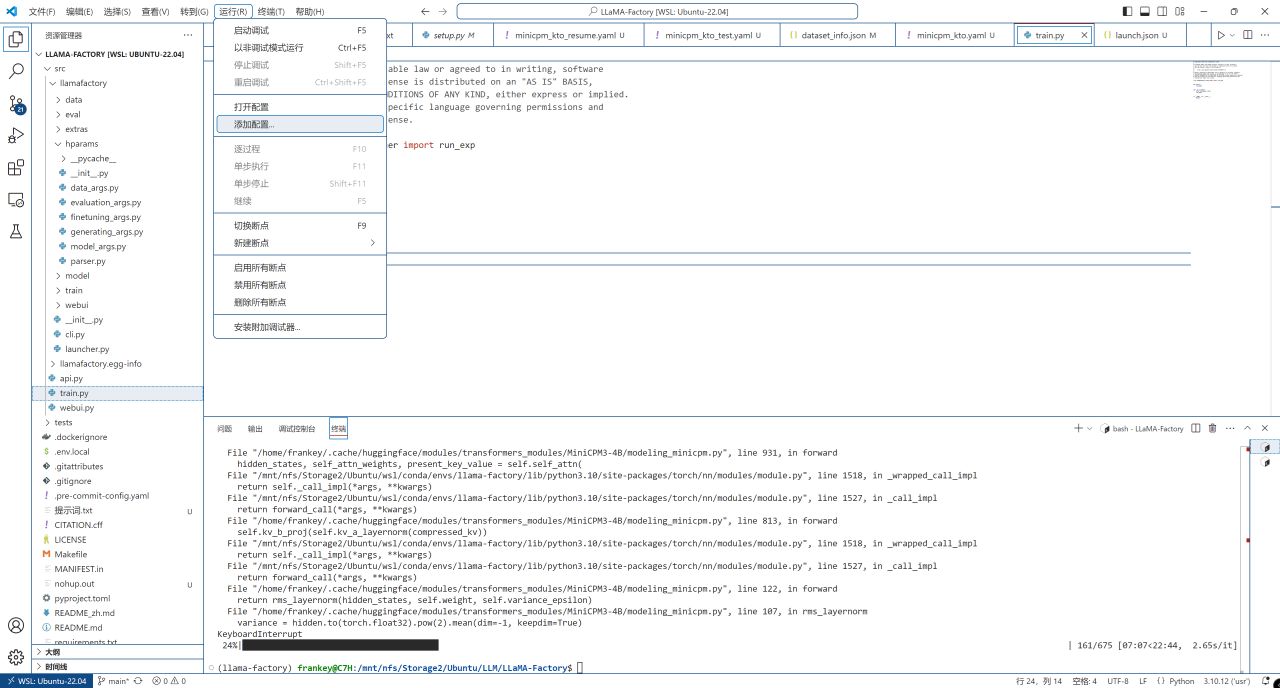
添加配置

帶有參數的Python文件
之後如下圖,將program改爲${workspaceFolder}/src/train.py,再將args改爲你剛纔創建的配置文件的位置:
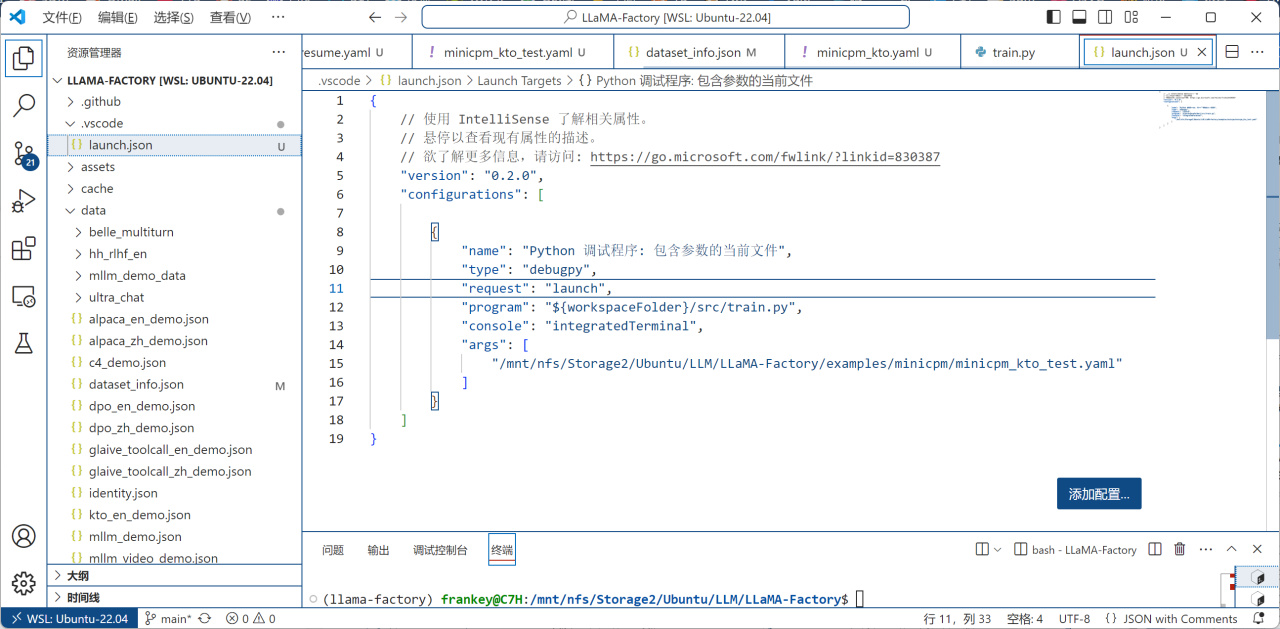
運行配置
之後打開src/train.py,在右下角選擇解釋器,選擇前面創建的那個conda環境:
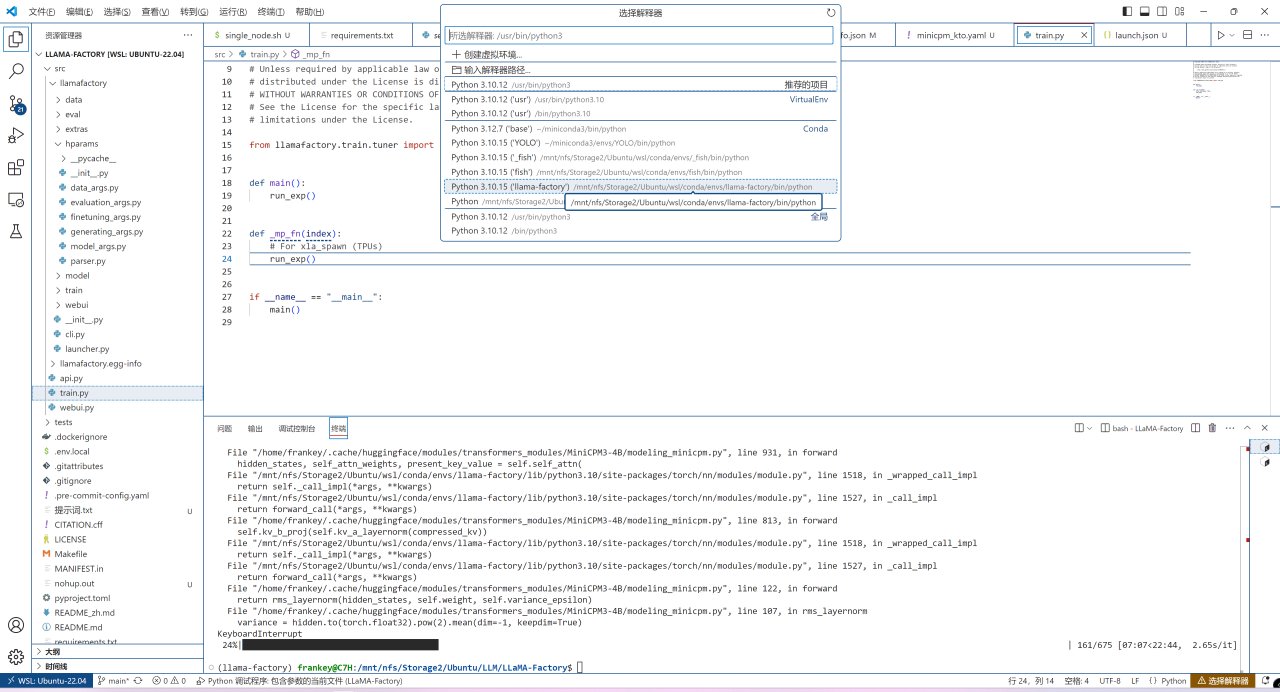
選擇conda環境
點擊運行-以非調試模式運行:
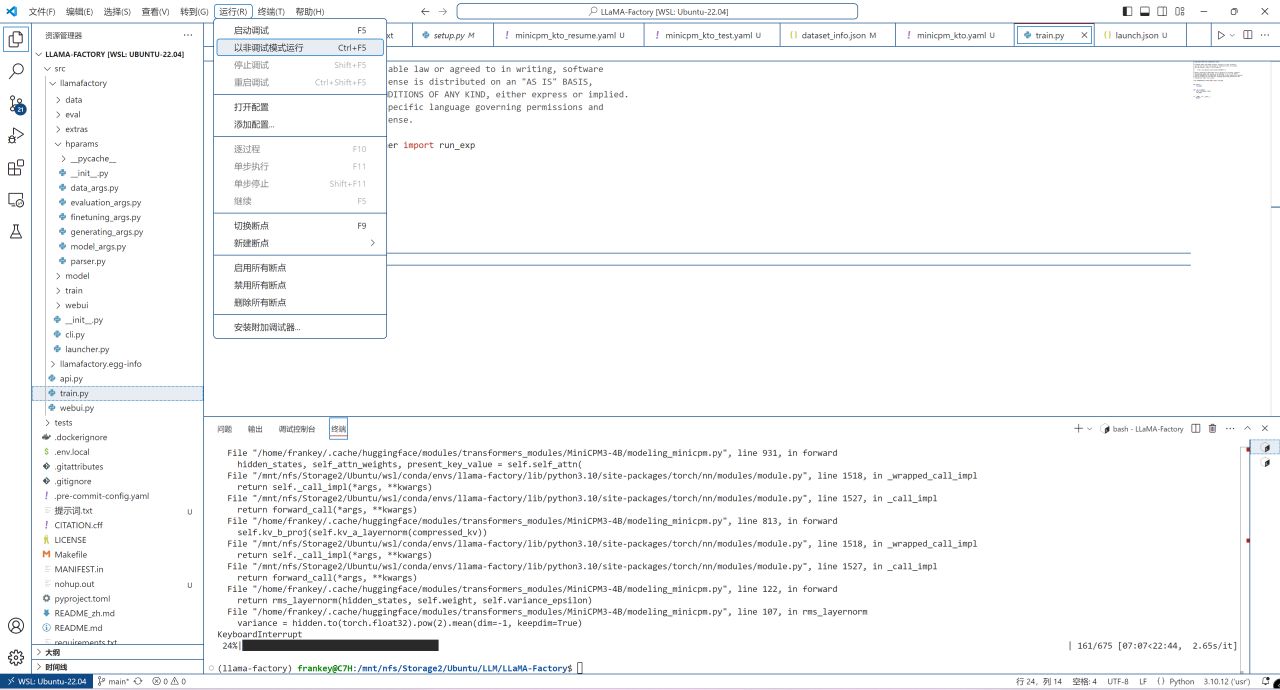
正式運行訓練
若提示缺少任何依賴的話,新開一個終端切換到環境直接安裝即可,這不會很多。
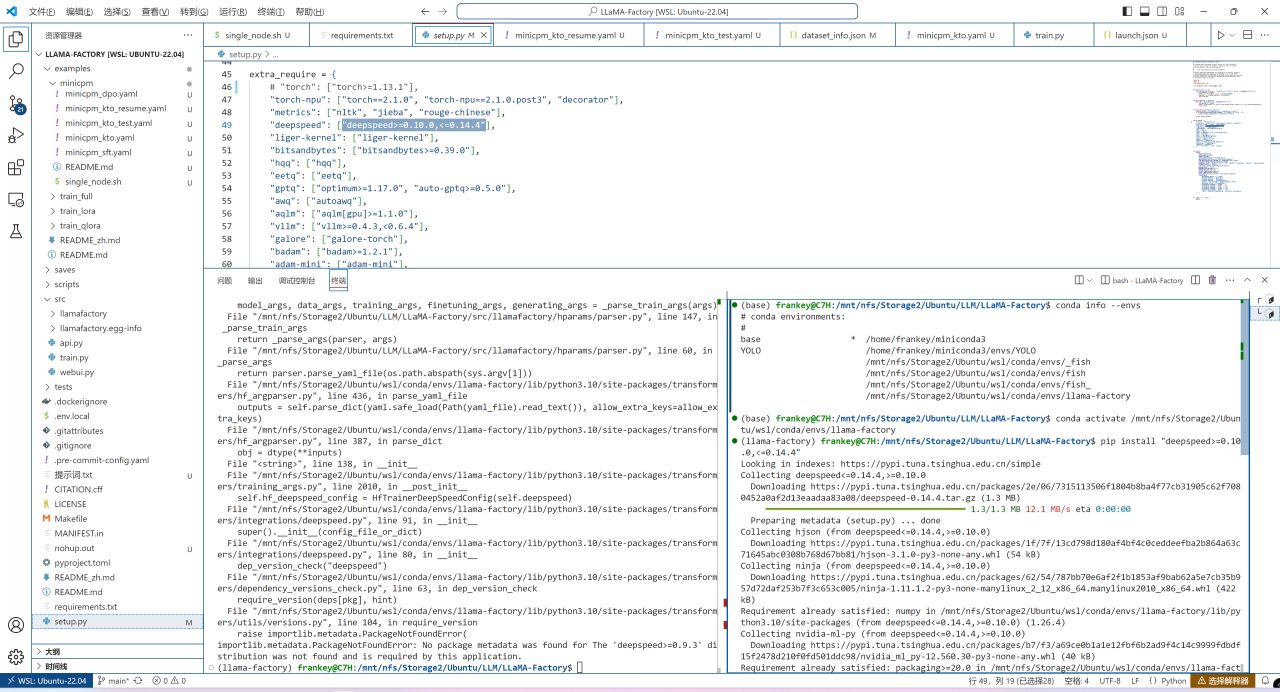
安裝遺漏的依賴
此時微調就已經正常開始了,7900XT做爲一張20GB顯存的顯卡,其能夠微調的極限大概也就是40億參數的模型了,各位可根據自己的顯存自行選擇模型:
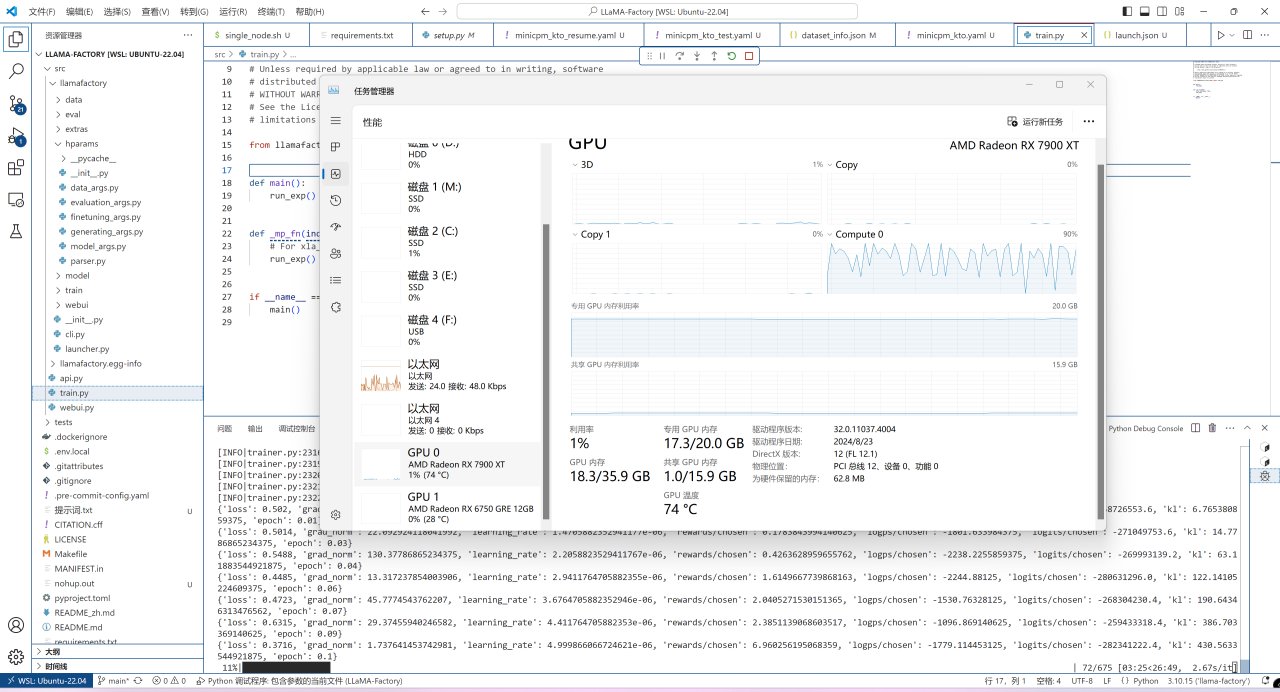
微調訓練中的模型
微調結束後的權重和其他文件將保存在剛纔的訓練配置文件中的output_dir中:
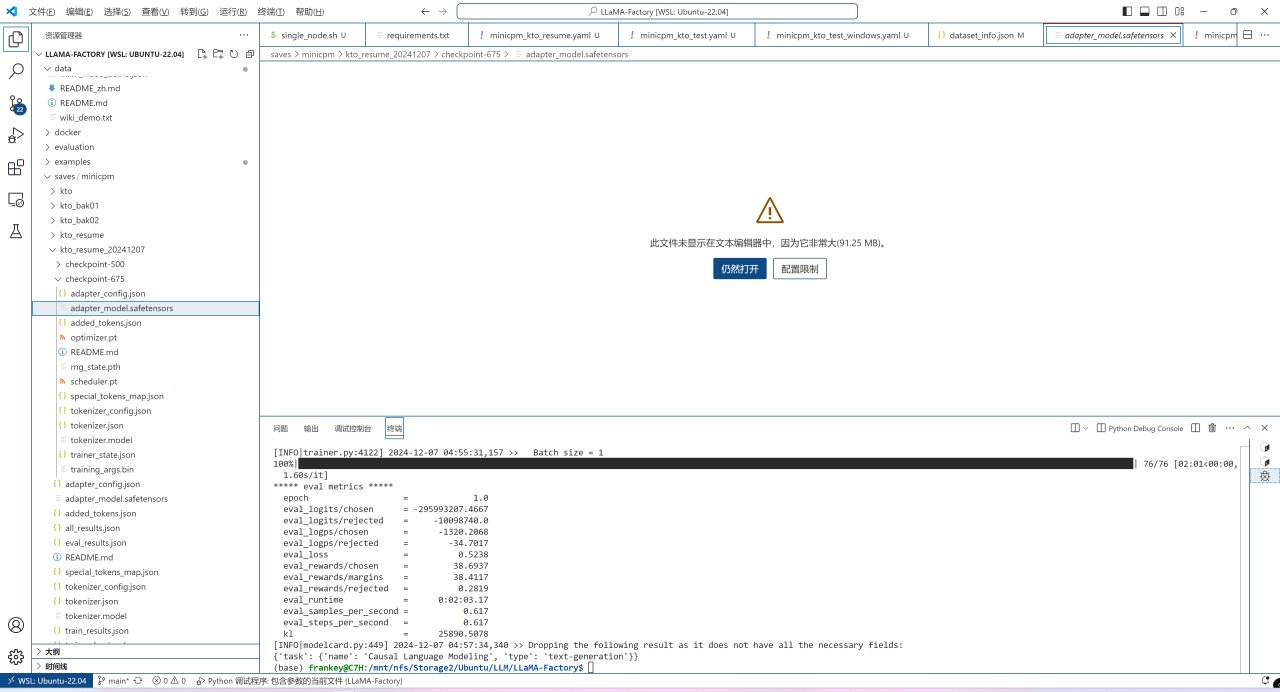
微調訓練後的文件
之後則是合併lora權重到原權重中,複製一份examples/merge_lora/llama3_lora_sft.yaml到原目錄,將複製的文件名稱改爲minicpm_merge.yaml,打開後做如下修改:
將model_name_or_path修改爲你之前從HuggingFace下載模型權重的目錄;
將adapter_name_or_path修改爲剛纔訓練完成的output_dir;
將template修改爲cpm3;
將export_dir修改爲你要將合併後的模型保存到的位置。
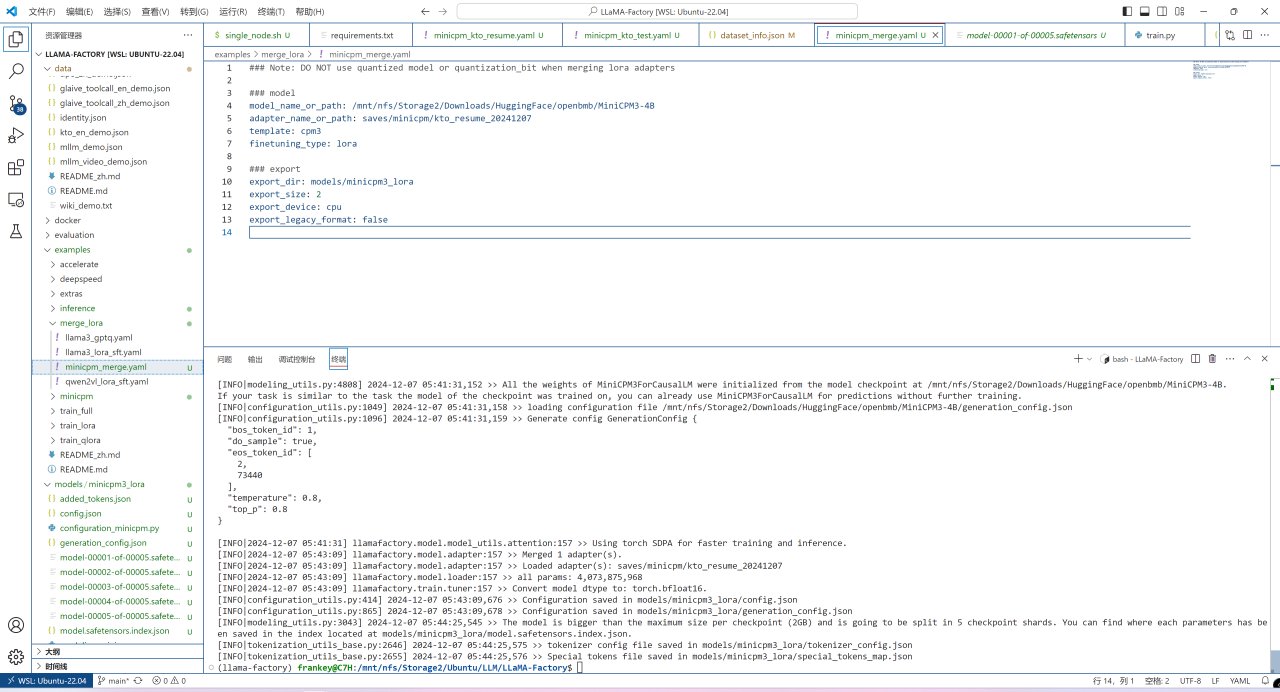
模型合併配置文件
之後運行如下指令正式開始合併:
llamafactory-cli export examples/merge_lora/minicpm_merge.yaml
合併完成後的文件會以safetensors的形式保存在上面設置的輸出目錄中:
合併完成後的文件
此時WSL中的工作已經結束,切換到Windows中llama.cpp的目錄,準備將safetensors轉換爲gguf。
首先新建一個conda環境並切換到該環境,運行如下指令安裝llama.cpp的python相關程序(主要爲轉換)的代碼,由於我們僅在此環境進行轉換,無需運行推理,故此處的PyTorch版本可直接使用其默認的CPU的版本。
pip install -r requirements.txt
之後運行如下指令將safetensors轉換爲gguf,記得把輸入目錄和輸出路徑改爲你自己的:
python convert_hf_to_gguf.py J:\Ubuntu\LLM\LLaMA-Factory\models\minicpm3_lora --outtype bf16 --outfile J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora.gguf
轉換完成後輸出目錄就會出現我們需要的gguf文件:
輸出的gguf
之後運行如下指令來量化模型,依舊需要將輸入和輸出路徑換爲你自己的,另外此處的精度是q8_0,你也可以根據自己的需要進行更改:
"./build/bin/llama-quantize.exe" J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora.gguf J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora_q8_0.gguf q8_0
之後運行量化後的模型,依舊需要把路徑改成你自己的,測試完全成功,需要注意的是,不同於上面的Qwen2.5,這裏-fa參數需要移除掉以禁用flash attention,否則會輸出亂碼:
"./build/bin/llama-server.exe" -m J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora_q8_0.gguf --port 8084 -a qwen -ngl 80 -n -2 -mg 0 -sm none --host 0.0.0.0
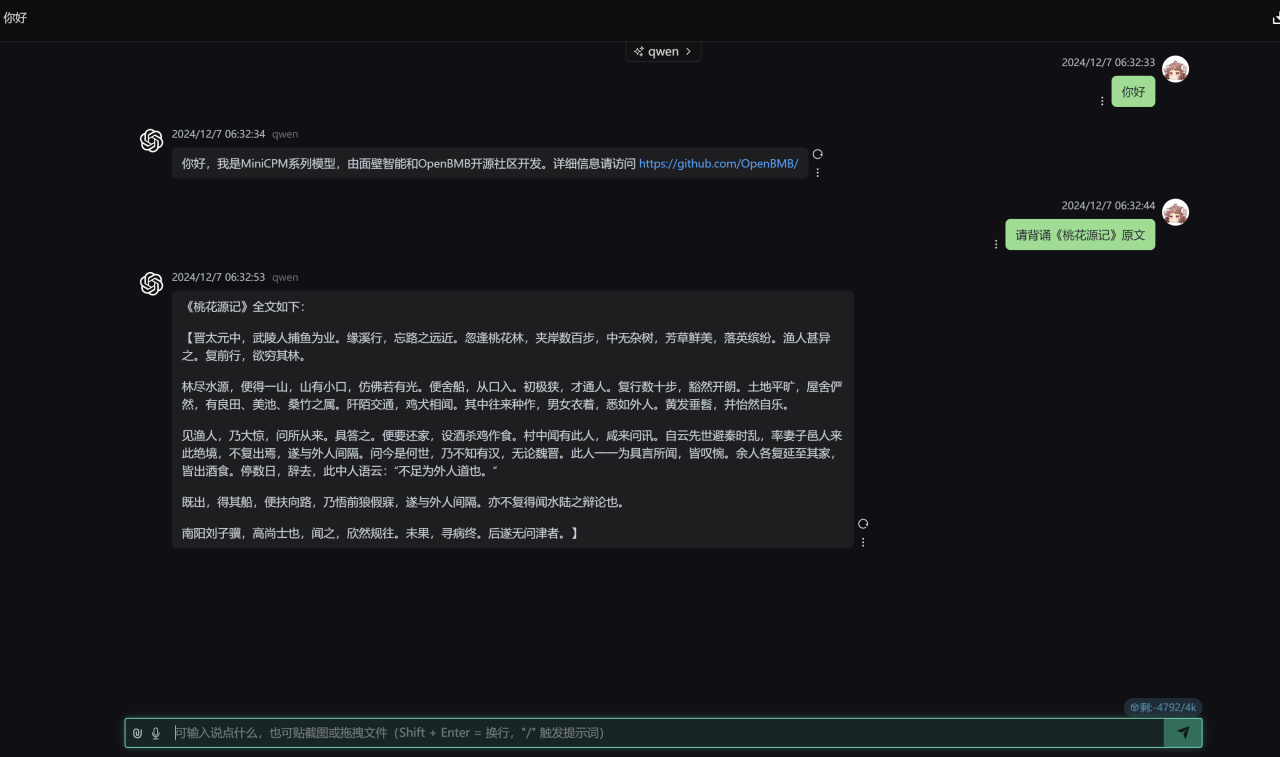
運行量化後的Lora模型
到此爲止,本篇教程完全結束。如果你跟着操作到了這裏,那麼恭喜你,你已經可以用一張AMD GPU完成從微調訓練到轉換再到量化最後到推理的完整流程,徹底把模型掌握在自己的手中。從此,你手中的A卡不止可以用來玩遊戲,至少在AI方面,他成爲了一個高性價比的生產力工具。接下來我將繼續發佈有限顯存下A卡運行AI繪畫大模型(FLUX.1)的教程,同時語音克隆和其他模型也在日程之內,而有了這兩篇教程的基礎,剩餘的教程將變得十分簡單,各位敬請期待。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















