上篇教程中我已经将A卡用户Windows下运行AI的基础环境配置讲述清楚,本文则基于上篇教程中配置好的环境,对A卡Windows下大模型运行(量化)与微调(原生)进行教学。其中运行的部分所有人均可阅读,文中有6750GRE运行的速度展示,各位可在下方查看并做为参考,而微调的部分我推荐显存在20G及以上的用户才进行阅读。
【教程】A卡用户Windows下AI运行完全指南-基础环境篇
1.使用llama.cpp进行推理
在正式进入教程之前,还有一些需要了解的基础背景,我在这里分别对其进行一些简单的介绍。
1.1 GGML
GGML是一个用C和C++编写,专注于Transforemr架构模型推理的开源机器学习库,其与PyTorch和TensorFlow类似,但具有轻量化、编译简单和支持量化的特点。
https://huggingface.co/blog/zh/introduction-to-ggml
1.2 GGUF
可以说GGUF是继PyTorch的pickle形式和safetensors以来的又一种新的权重保存形式。PyTorch以pickle形式序列化的二进制权重可能含有可执行的恶意代码;而safetensors的设计确保了数据在读取时不会执行任意代码,解决了PyTorch的问题,是目前各类大模型使用最多的权重形式;而GGUF更进一步,不同于safetensors仅限张量的保存形式,GGUF在文件的前部保存了metadata信息,使得保存的权重能以量化的形式读取。
https://huggingface.co/docs/hub/gguf
所谓量化简单来说就是对权重以不同的精度进行编码。在深度学习中,我们常用的精度是fp32,对于以前的一些CV和NLP上的较小的模型(参数量在亿以内),一般的消费级GPU的显存也足够以fp32的全精度加载它们。而在大模型出现后,即使是财大气粗的各大企业面对这样的无底洞时也不得不做出妥协,更多的时候他们会以fp16的半精度对模型进行训练。同时,一种名为bf16的编码方式也得以推广开来,其与fp16同样消耗16个bit,但是能表达数字的范围却与fp32相同,只不过相较于fp16损失了部分精度而已。
然而对于深度学习任务而言,权重的精度最终对模型的性能影响并不算大(相对而言),所以从fp16到bf16的转换是非常划算的。即使如此,对于大部分大模型而言,16位的编码更多地只是一定程度上节约了本就拥有足量的专业级GPU的厂商在对其训练和运行时所需要的成本。而对于个人用户而言,哪怕是最强的消费级显卡,其最高也不过只有24GB显存,单张显卡要以16位的精度运行大模型依然是无法实现的,难道给个人消费者的路就只剩下重金购买多卡、重金购买专业卡和租服务器了吗?当然不!既然权重的精度对模型性能的影响有限,何不再让他的精度低一点,用8位,4位甚至1.75位来将训练好的权重转换过来呢?
这就是GGML和GGUF做的事情,通过对权重进行重新编码,以更小的位数来表示相同(近)的信息,通过损失一部分精度的代价来使得同样的显存能运行更大的模型,这对于对性能没有过于严苛的要求的普通用户而言意义重大。况且,合理的量化精度对最终指标的影响并不明显,下图是同一模型在不同量化精度下的困惑度(PPL)比较,可以看到一直到了Q3,其困惑度相比于fp16才有较为明显的上涨。而13B的模型哪怕是Q2量化的版本,其困惑度也要比7B模型的fp16原版要低。
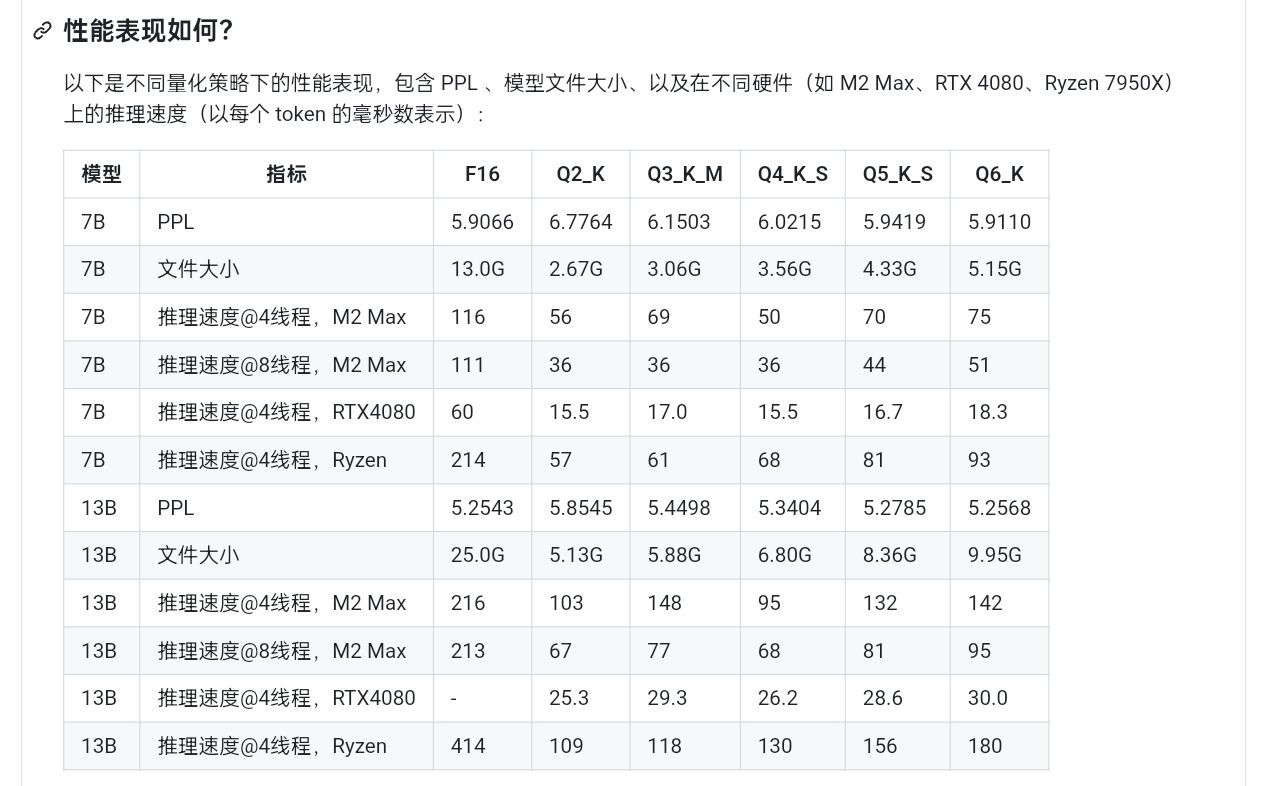
不同量化精度性能对比
也就是说,比起更高的量化精度,参数量对模型性能的影响是要更大的,这再一次证明了量化精度对模型性能的影响是有限的。各位选择模型的时候,若以性能而非速度为最高指标的话,大可以选择自己的显存能以最低的量化精度加载的参数量最大的模型,若对速度有更高要求再去选择参数量少一点的模型。具体而言,此网页也介绍了目前所有量化类型的具体量化方式:
https://huggingface.co/docs/hub/gguf
1.3 llama.cpp
llama.cpp是基于GGML的一个大语言模型推理工具,其能让以LLaMA模型为代表的多种大语言模型以量化的形式(包括Qwen系列、ChatGLM系列和MiniCPM系列等模型)在多种后端上推理起来。其内置的llama-server能够让模型通过OpenAI API的形式进行输出,这代表着一系列支持自定义api的对话前端以及工具均可对其进行调用。
https://github.com/ggerganov/llama.cpp
llama.cpp支持多种计算后端,CUDA不再是唯一可选项,你可以使用AMD的hipBLAS,苹果的Metal甚至国产摩尔线程的MUSA作为计算的后端。对于AMD而言,hipBLAS能让你以原生的方式完全地将显卡的性能利用起来,而不同于Zluda和DirectML这类有明显性能损失的转译运行方法,而你所需要做的仅仅是在编译时加上GGML_HIP=ON的参数。
至此,你所需要了解的基础背景就介绍完毕了,下面正式开始为你自己的显卡编译运行llama.cpp的教学。
你首先需要做的是按照我基础环境篇中的内容将HIP SDK安装好:
【教程】A卡用户Windows下AI运行完全指南-基础环境篇
之后安装git:
https://git-scm.com/downloads/win
下载64-bit Git for Windows Setup。
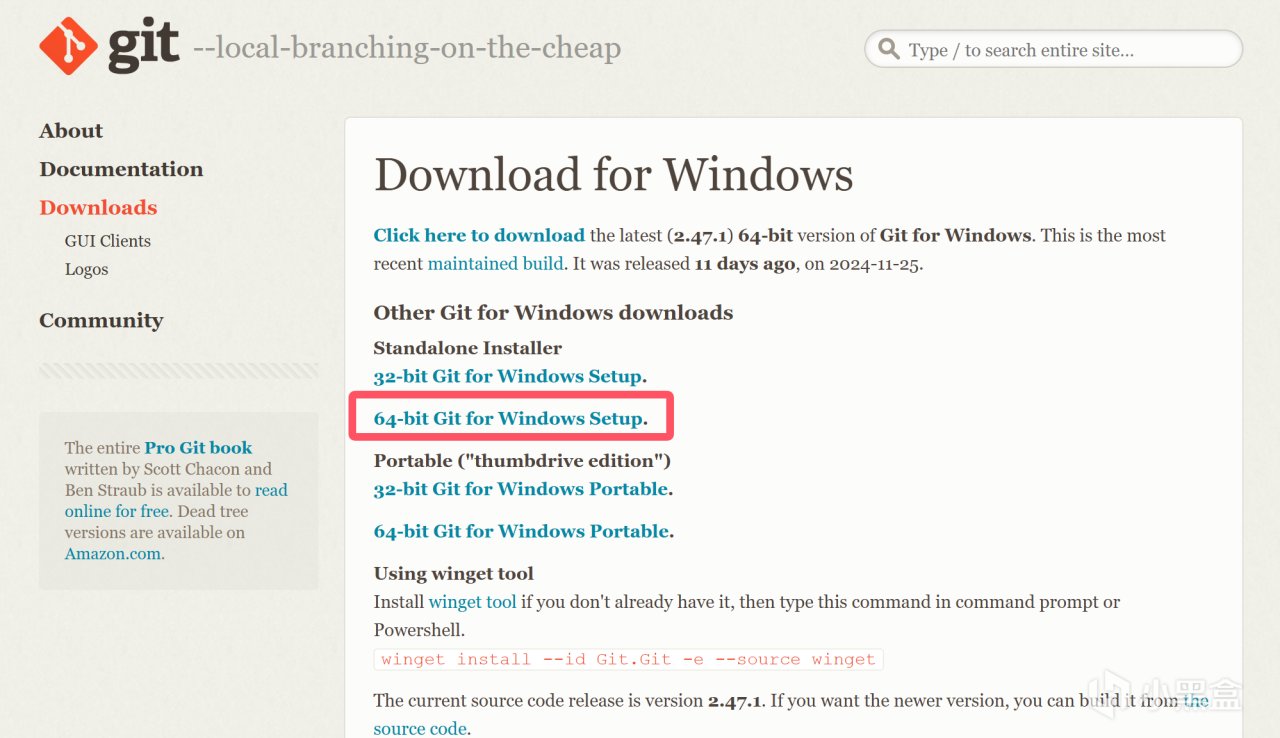
选择64-bit Git for Windows Setup
下载后运行,将"{安装目录}\cmd"添加到环境变量-系统变量-Path中:
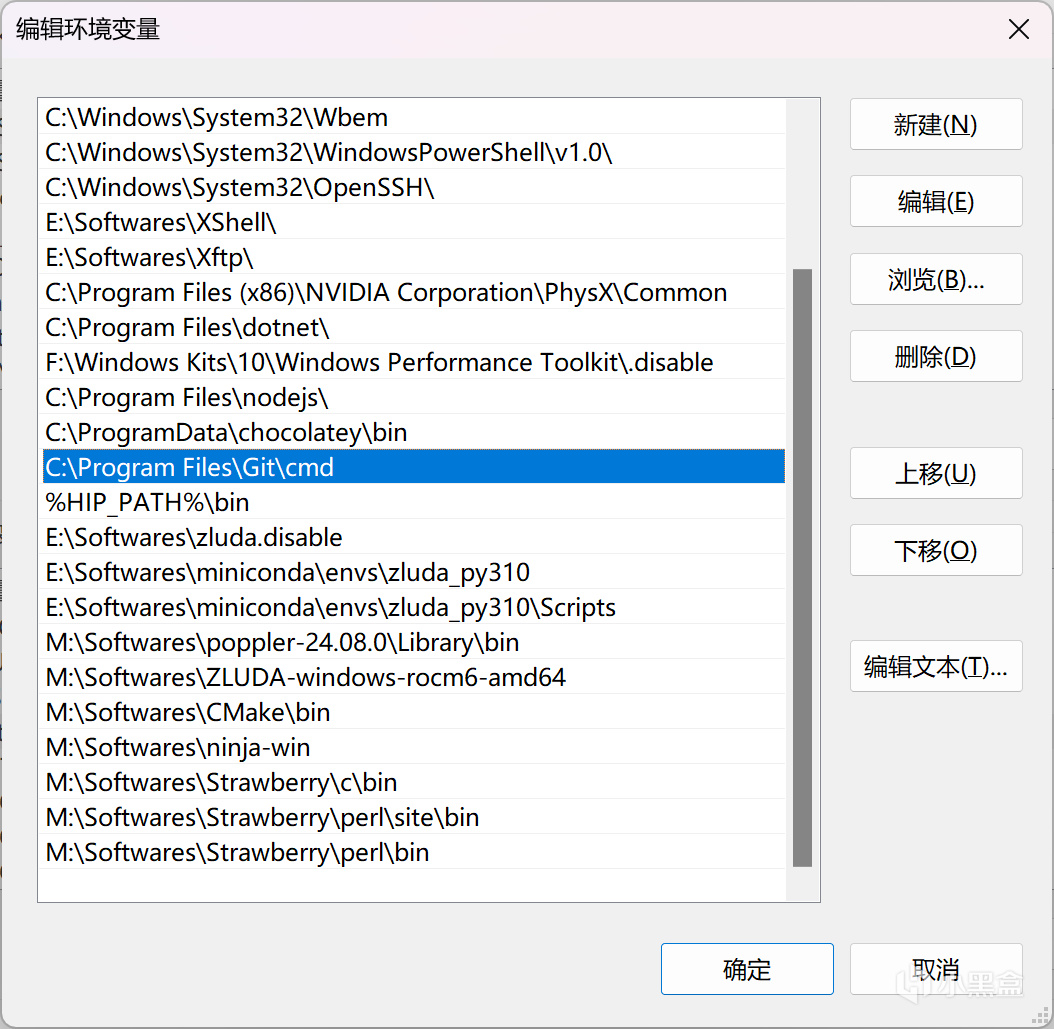
git环境变量
接着安装cmake:
https://cmake.org/download/
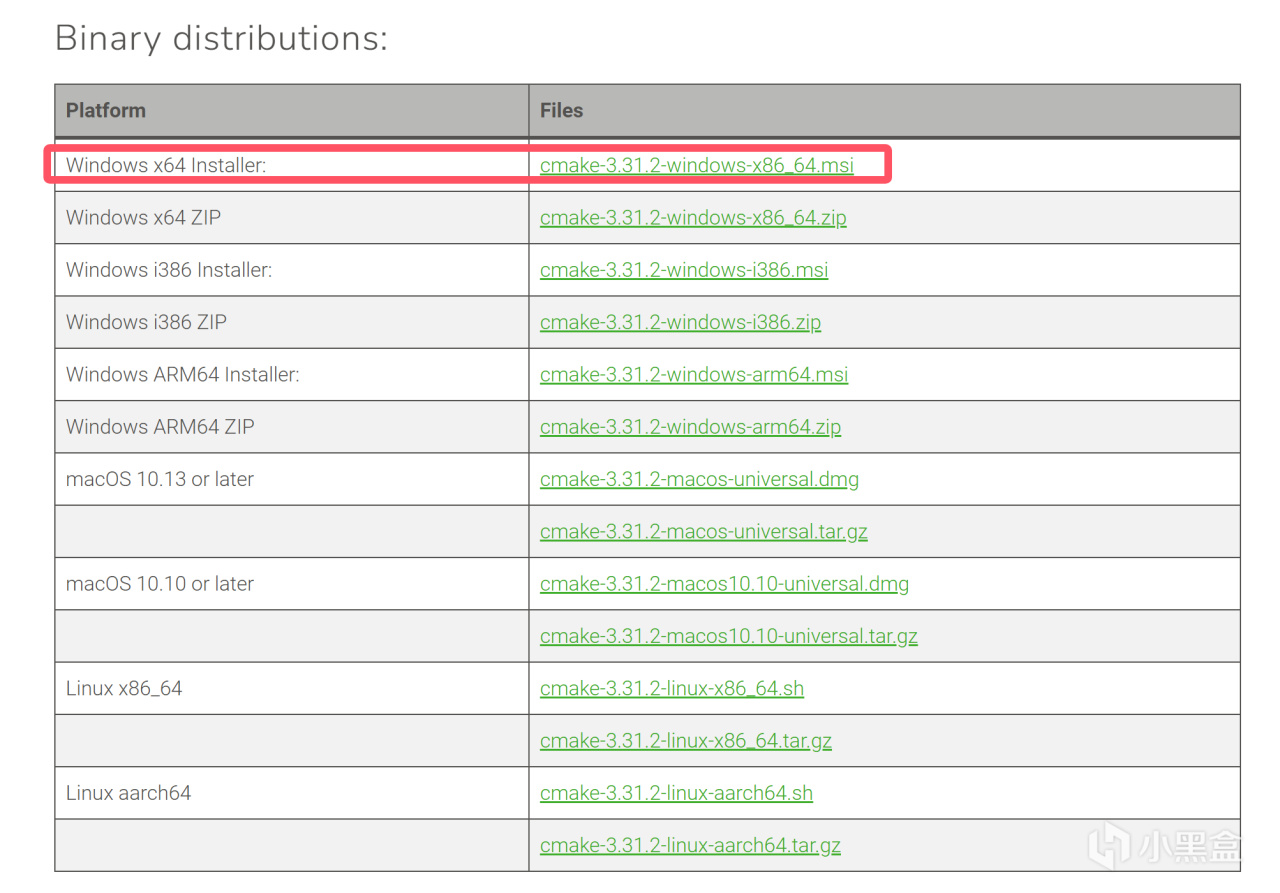
选择Windows x64 Installer
下载Windows x64 Installer后进行安装,将"{安装目录}\bin"添加到环境变量-系统变量-Path中:
CMake环境变量
接着安装ninja:
https://github.com/ninja-build/ninja/releases
从releases中选择最新的win版本下载。
选择win版本
下载后解压到任意位置,将解压的位置同样添加到Path变量中:
ninja环境变量
接着安装perl:
https://strawberryperl.com/
选择MSI安装包
下载MSI安装包并运行安装,正常情况下安装程序会自动配置环境变量,若没有则请手动添加以下3个路径到Path中(安装位置替换成你自己的):
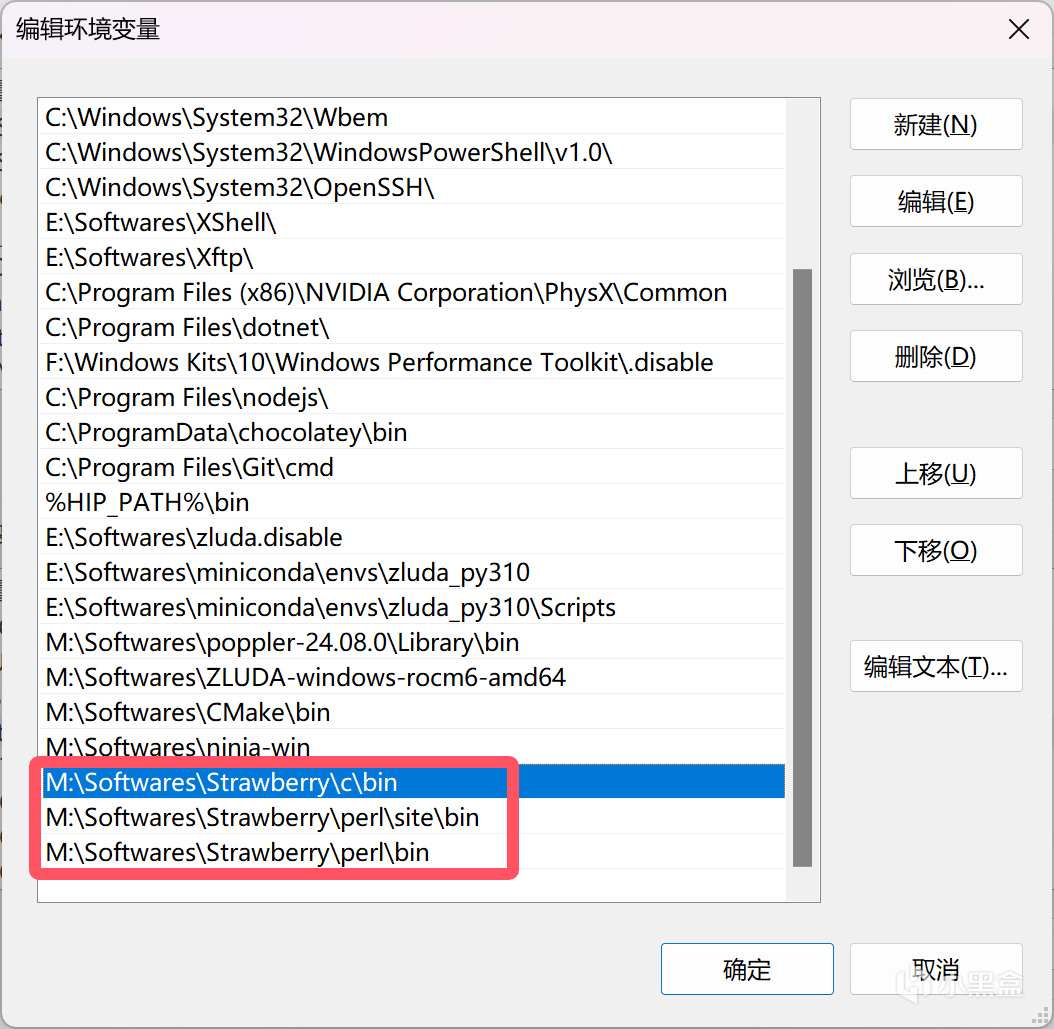
perl环境变量
接着在Visual Studio Installer中安装Windows SDK:
https://visualstudio.microsoft.com/zh-hans/downloads/
选择社区版
下载后打开Visual Studio Installer,安装Visual Studio,别的想勾什么随便,但是Windows 11 SDK必须勾上(如果你是Windows 10那就换成任意一个Windows 10 SDK),之后等待下载安装即可。
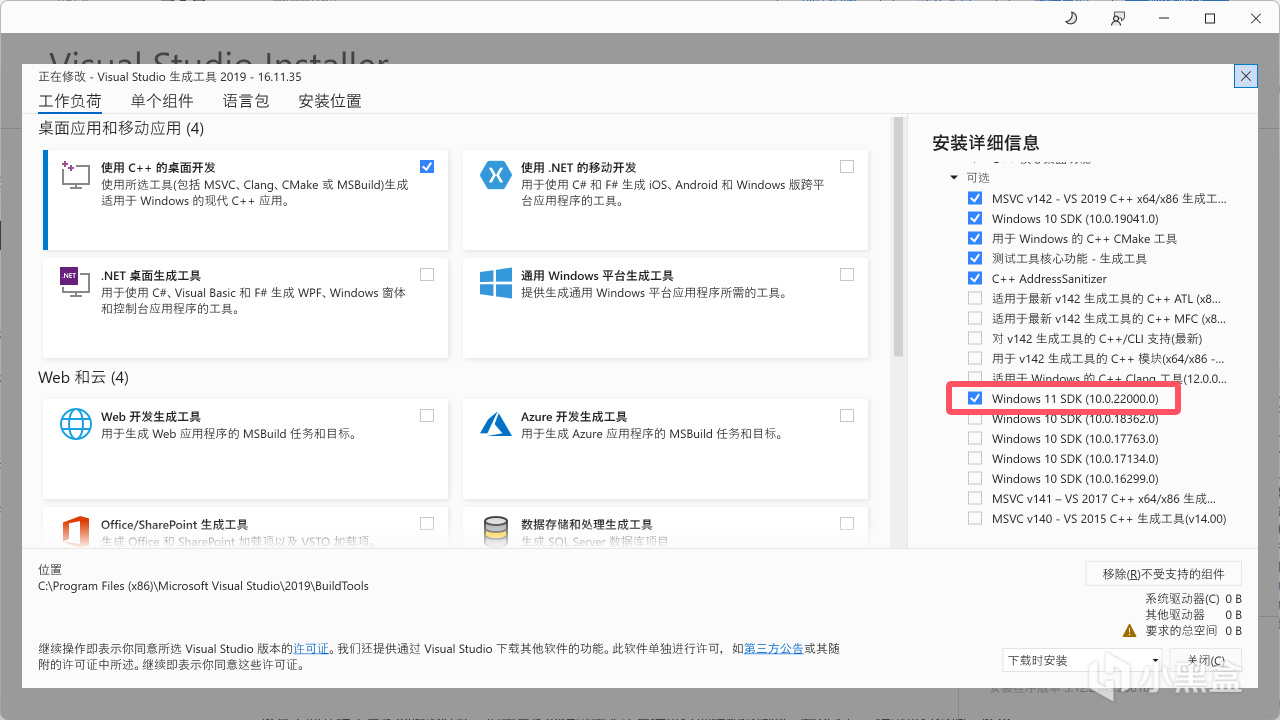
选择Windows 11 SDK
完成这一切工具的安装后,正式开始llama.cpp的编译工作,打开控制台,cd到你想要安装llama.cpp的目录。
cd到安装目录
运行如下指令,将llama.cpp的源码clone到硬盘:
git clone https://github.com/ggerganov/llama.cpp.git
clone源码
cd到llama.cpp的目录:
cd llama.cpp
cd到llama.cpp的目录
运行以下指令:
set PATH=%HIP_PATH%\bin;%PATH%
之后运行如下指令进行编译的配置:
cmake -S . -B build -G Ninja -DAMDGPU_TARGETS=gfx1100 -DGGML_HIP=ON -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_BUILD_TYPE=Release
其中"-DAMDGPU_TARGETS=gfx1100"代表了你要编译的目标GPU,各位请根据自己的GPU型号进行修改,如RX7900XT就是gfx1100,而RX6750GRE则是gfx1031。
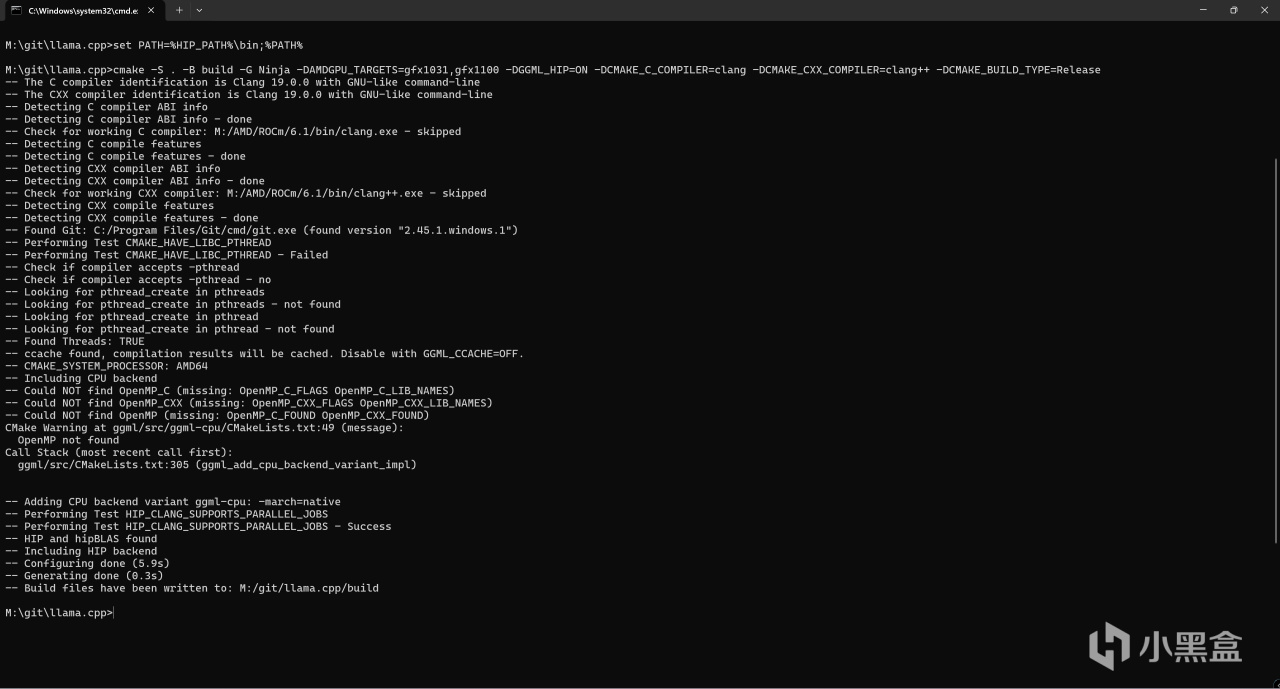
进行编译配置
之后运行以下指令正式开始编译:
cmake --build build
在等待十几分钟左右后,编译结束。
编译结束
如果你之前已经下载过模型,那此时就已经可以正常运行了(此处仅作展示,后文会有详细教程)。
"./build/bin/llama-cli.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf -co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." -fa -ngl 80 -n 512 -mg 0 -sm none
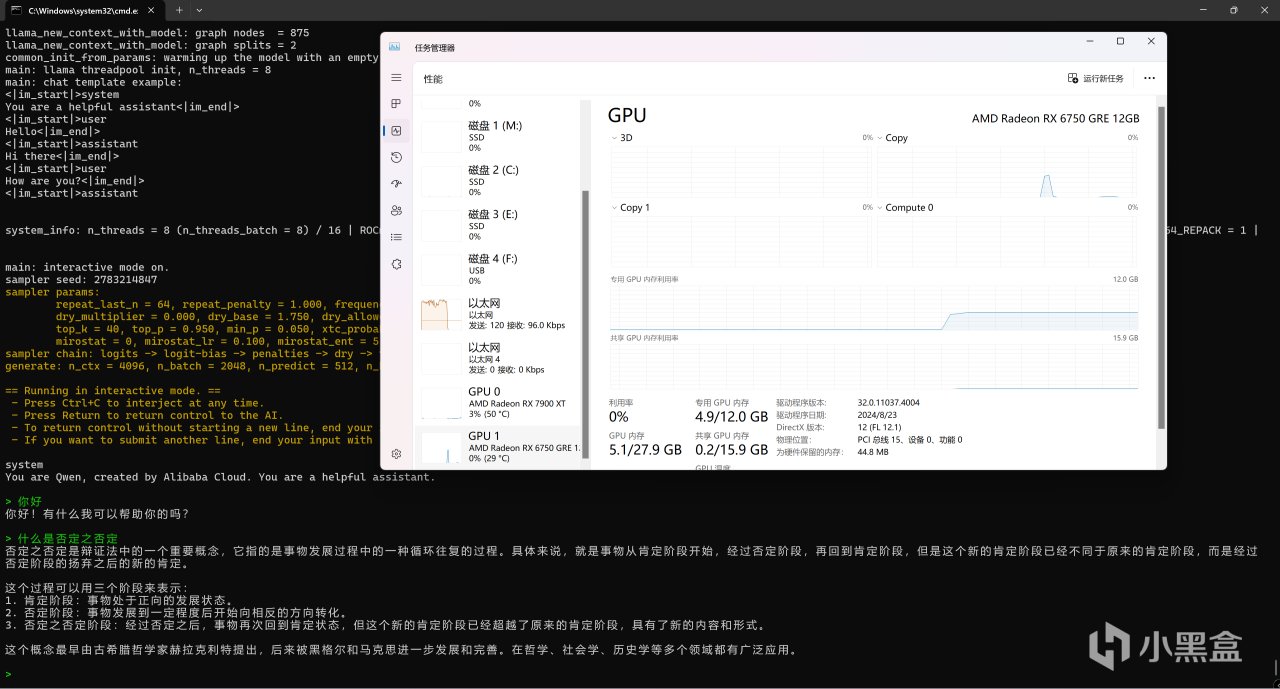
模型成功地运行在6750GRE上
6750GRE的速度也是非常的快。
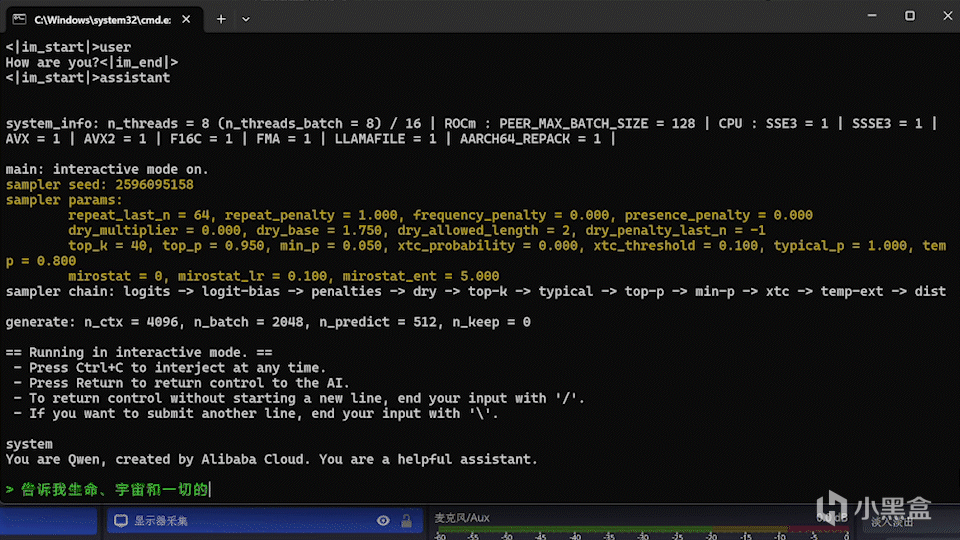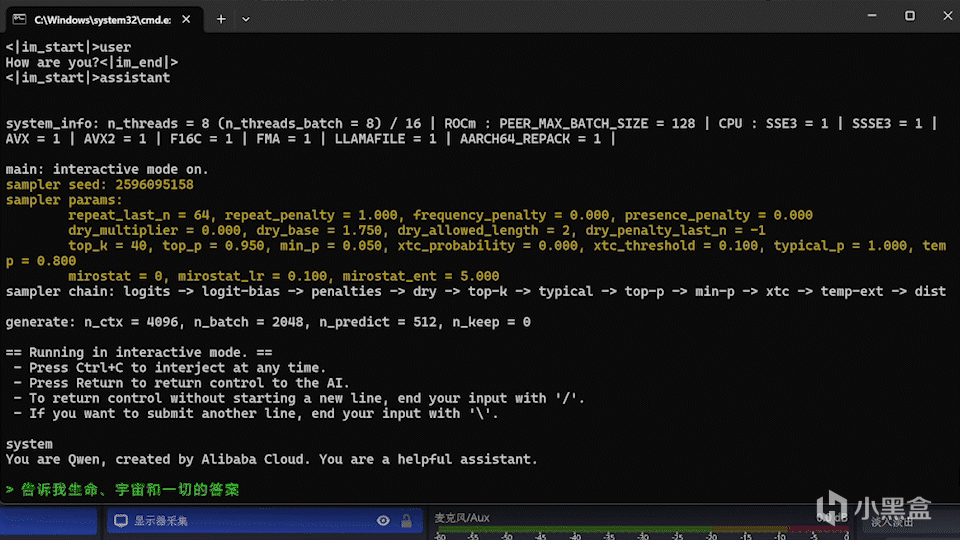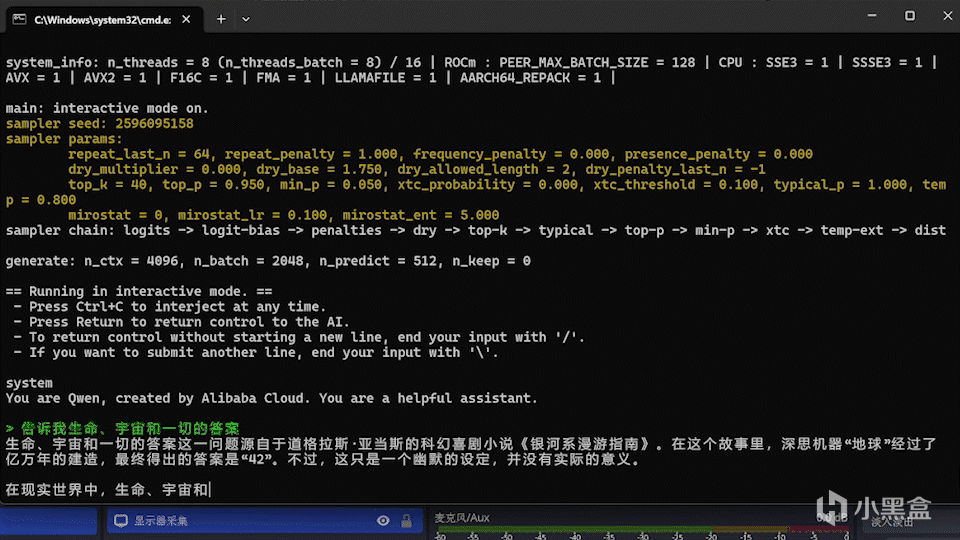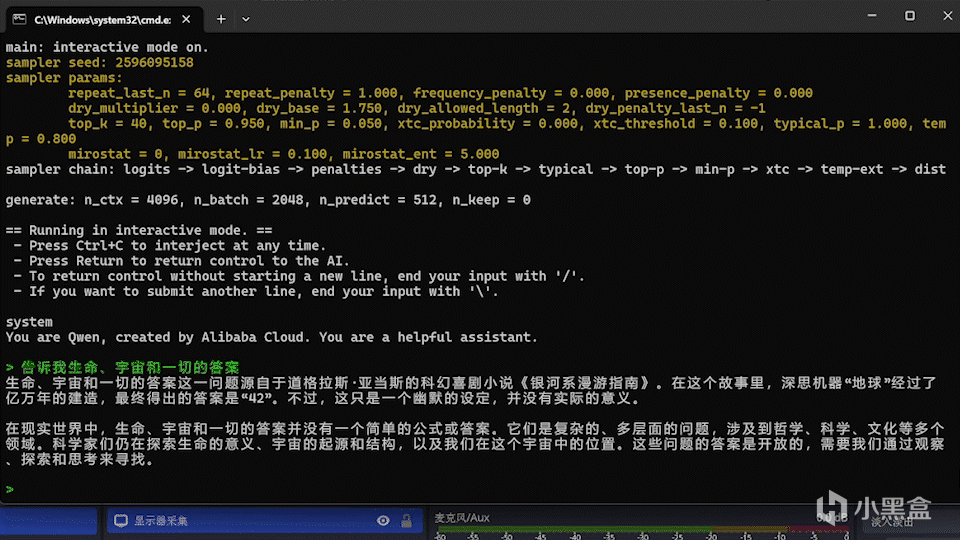
此动图未进行任何加速
到此为止,llama.cpp的编译已经完全结束。如果你是gfx1100(RX7900系列)和gfx1031(RX6750和RX6700系列)的用户,我在这里已经给你们预编译好了同时支持这两种芯片的版本,你们不用再亲自编译。但需要注意的是,即使我现在这个版本是截止2024年12月02日的最新版,但是由于我的精力有限,我不会对此版本进行更新。对于以后的更新,gfx1100用户可自行到github项目原地址的releases页面下载官方编译的对应的版本,gfx1031的用户则需要根据我上面的步骤自行编译。而其他GPU的用户,也请根据我上面的步骤自行编译。
llama.cpp(gfx1031&gfx1100).7z 百度网盘:
https://pan.baidu.com/s/1cbzSidjb1UAiQBLzFvmw0Q?pwd=23vc
llama.cpp(gfx1031&gfx1100).7z 夸克网盘:
https://pan.quark.cn/s/d5430743a50c
1.4 HuggingFace
上面有提到下载模型后进行运行,而大部分情况下,我们下载预训练模型的来源就是HuggingFace了。HuggingFace是一个广受欢迎的开源平台,其专注于各类深度学习模型的分享与交流,目前已有大量模型在HuggingFace上进行发布,在这里我以Qwen/Qwen2.5-7B-Instruct-GGUF为例介绍模型的下载与运行,各位的GPU若具有更大的显存则可选择32B乃至更多参数的模型。
HuggingFace页面
尽管我们可以从网页上直接下载模型,但不同于环境只用配置一次,我们往往要不断地下载新的模型,而不少模型的大小动辄就是几十GB,从流量的角度考虑,镜像的使用就显得很有必要。不仅如此,对于一些要求验证的模型(如Stable Diffusion 3.5),我们无法直接从镜像的网页进行下载,此时我们就需要用到huggingface-cli这个工具了。
首先通过如下指令安装huggingface-cli:
pip install -U huggingface_hub
之后编辑环境变量,新建变量HF_ENDPOINT并设置为https://hf-mirror.com,将huggingface-cli的下载源修改为国内镜像站。
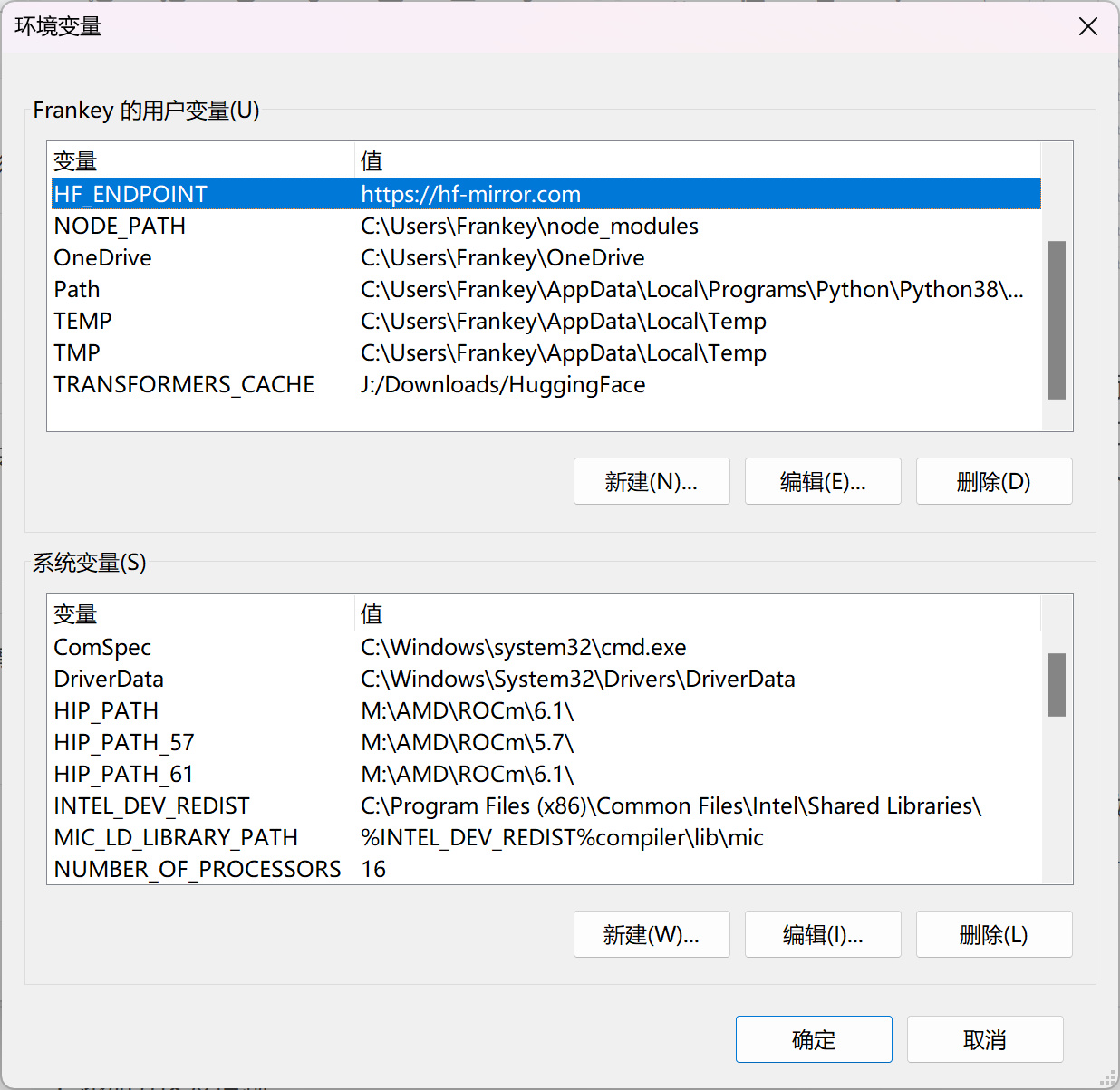
HF_ENDPOINT变量
设置好环境变量后,可正式开始模型权重的下载,Qwen2.5-7B-Instruct-GGUF具有多个量化版本,量化的定义在上文"GGUF"一节中已有介绍,在这里我以q4_k_m量化的版本为例:
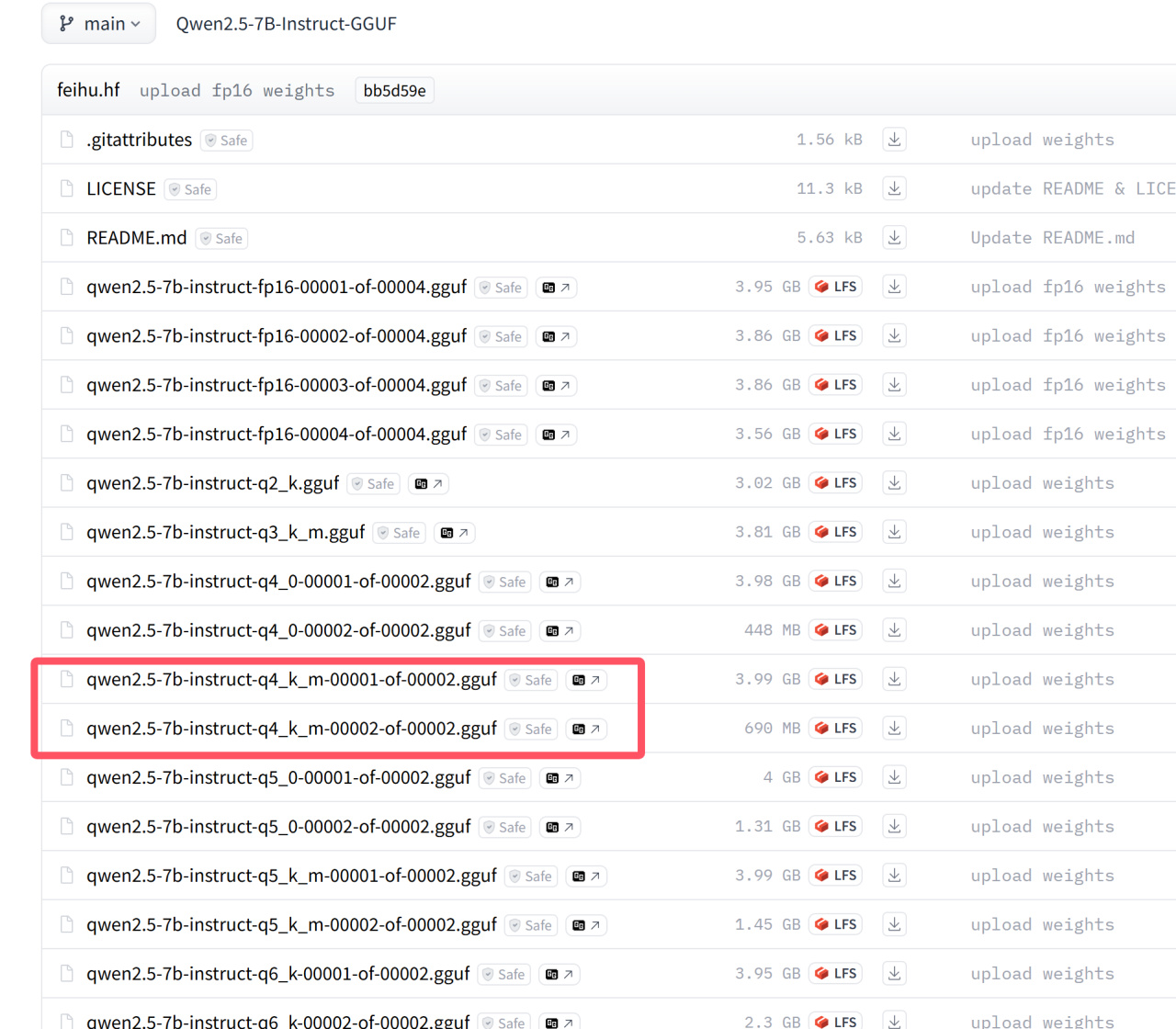
不同的量化版本
运行如下指令对模型进行下载:
huggingface-cli download --resume-download Qwen/Qwen2.5-7B-Instruct-GGUF --include "qwen2.5-7b-instruct-q4_k_m*.gguf" --local-dir J:\Downloads\HuggingFace\Qwen2.5-7B
--include 参数表示要下载的文件
--local-dir 改为你自己的保存路径
下载完成后,cd到llama.cpp的目录,运行如下指令将两个gguf文件合并为单个文件:
"./build/bin/llama-gguf-split" --merge J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m-00001-of-00002.gguf J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf
第一个路径是模型列表的首个文件,第二个路径是合并完成后模型的保存路径,请自行将这两个路径替换为你自己的路径。
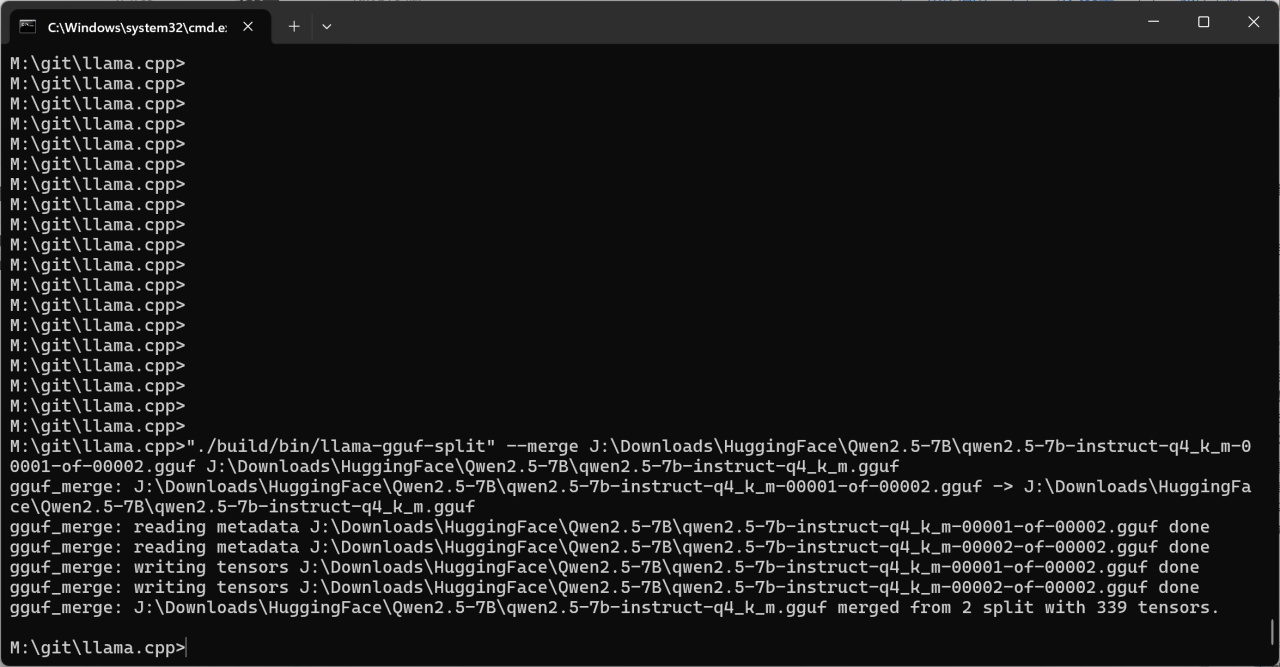
合并模型文件
此时我们就将权重转换为了单个文件,运行以下指令可在命令行中进行测试:
"./build/bin/llama-cli.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf -co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." -fa -ngl 80 -n 512 -mg 0 -sm none
模型成功地运行在6750GRE上
6750GRE的速度也是非常的快。
此动图未进行任何加速
测试完毕后按Ctrl+C退出程序,运行如下指令启用api监听:
"./build/bin/llama-server.exe" -m J:\Downloads\HuggingFace\Qwen2.5-7B\qwen2.5-7b-instruct-q4_k_m.gguf --port 8084 -a qwen -fa -ngl 80 -n -2 -c 32768 -mg 0 -sm none --host 0.0.0.0
--port 8084 表示监听的端口
--host 0.0.0.0 表示监听任意地址,默认只会监听127.0.0.1的本地地址
-n -2 表示输出内容长度无限制(直到填满上下文)
其他各个参数的含义详见以下页面,也可以对api_key进行设置(此例子未进行设置):
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
启动完成后即可通过OpenAI API进行访问了。
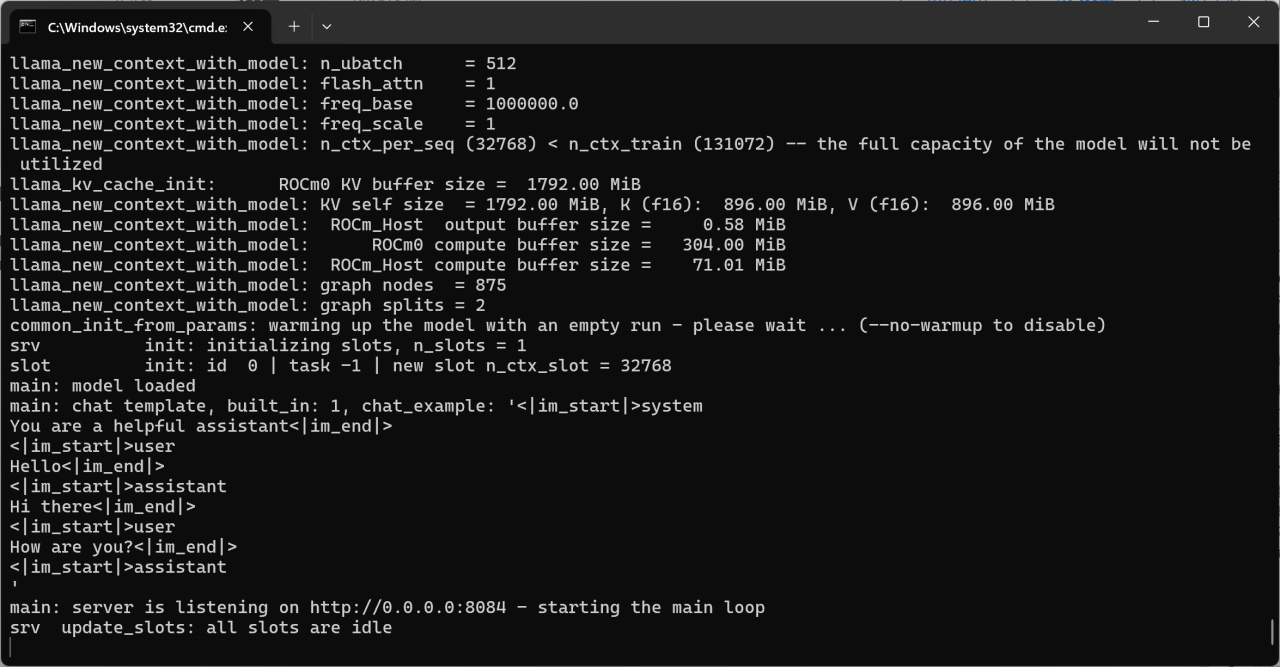
服务器启动完毕
以https://github.com/Dooy/chatgpt-web-midjourney-proxy项目为例,进入项目前端后将API接口和API Key(上面没设置所以此处不需要)设置好并保存。
项目体验地址,可直接打开:https://vercel.ddaiai.com/#/chat/1002
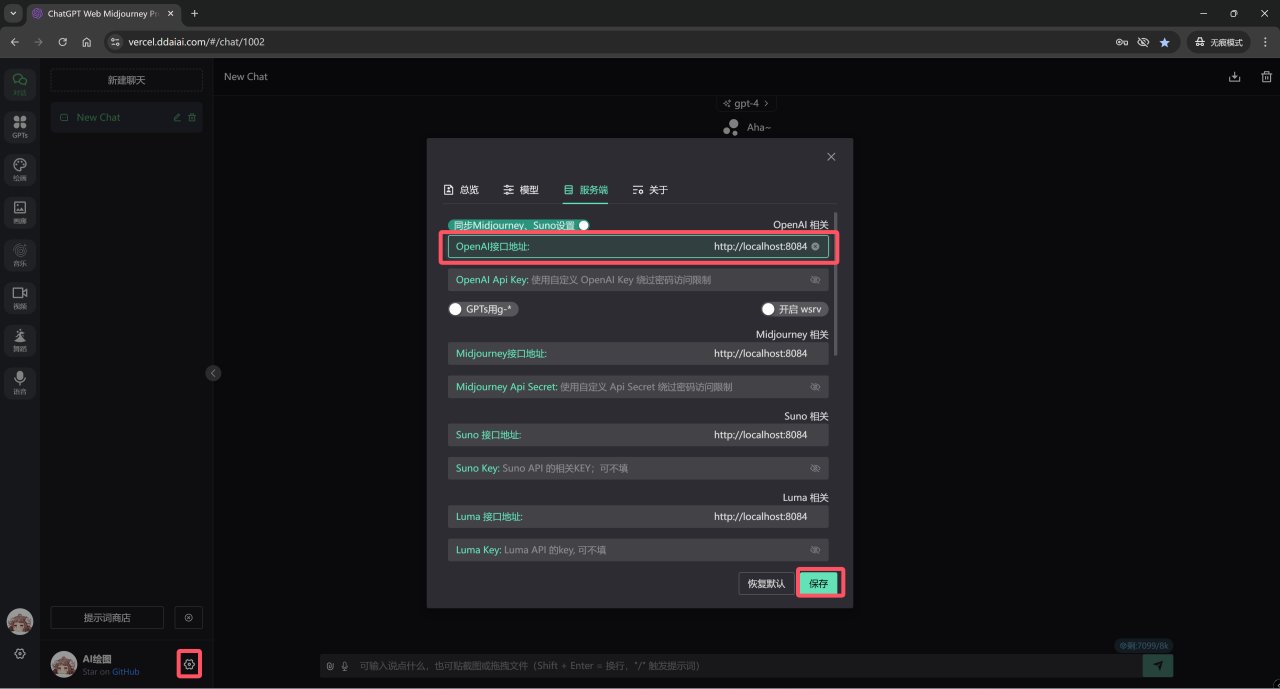
设置API
设置好之后就可以直接进行对话,不需要特地指定模型名字,任何模型名字(包括默认的gpt-4)都会被直接忽略掉:
运行测试
可以看到6750GRE的生成速度是足够快的(后台数据在50token/s左右),并且为压缩动图大小我将帧率限制在了4帧/s,而实际使用的时候是非常流畅的。
到此,你已经成功地将大模型运行在了你的AMD GPU上,同时成功通过API进行了监听,上面的项目是一个最典型的例子,任何可以设置OpenAI API的项目均可以以你本地的这个大模型为后端进行运行,从此在大量使用的时候不再为API大量付费,并将数据牢牢握在自己的手中,更不需要为此去买一张性能少量提升价格却巨幅增加的N卡。
2.使用LLaMA Factory进行微调
尽管上面介绍了量化的诸多好处,但是量化的模型是无法直接进行训练和微调的,要对大语言模型进行微调,依然需要使用其原始的形式。介于我的GPU只有20G的显存,本文将以4B的MiniCPM 3.0为例,介绍如何通过LLaMA Factory对大模型进行微调。
此部分教程基于MiniCPM的官方文档,有基础的读者可自行阅读:
https://modelbest.feishu.cn/wiki/PpUrwsmDAiAAoEk8jc8cnBh7nOh
要进行下面的操作,你应该已经按照上一篇教程中的内容在WSL中安装好了AMD提供的PyTorch并进行了后续的配置,若还没有完成基础环境配置的读者请阅读上一篇教程:
【教程】A卡用户Windows下AI运行完全指南-基础环境篇
考虑到效率,此教程以上篇教程中WSL中的环境为例,不对Zluda如何配置进行介绍。
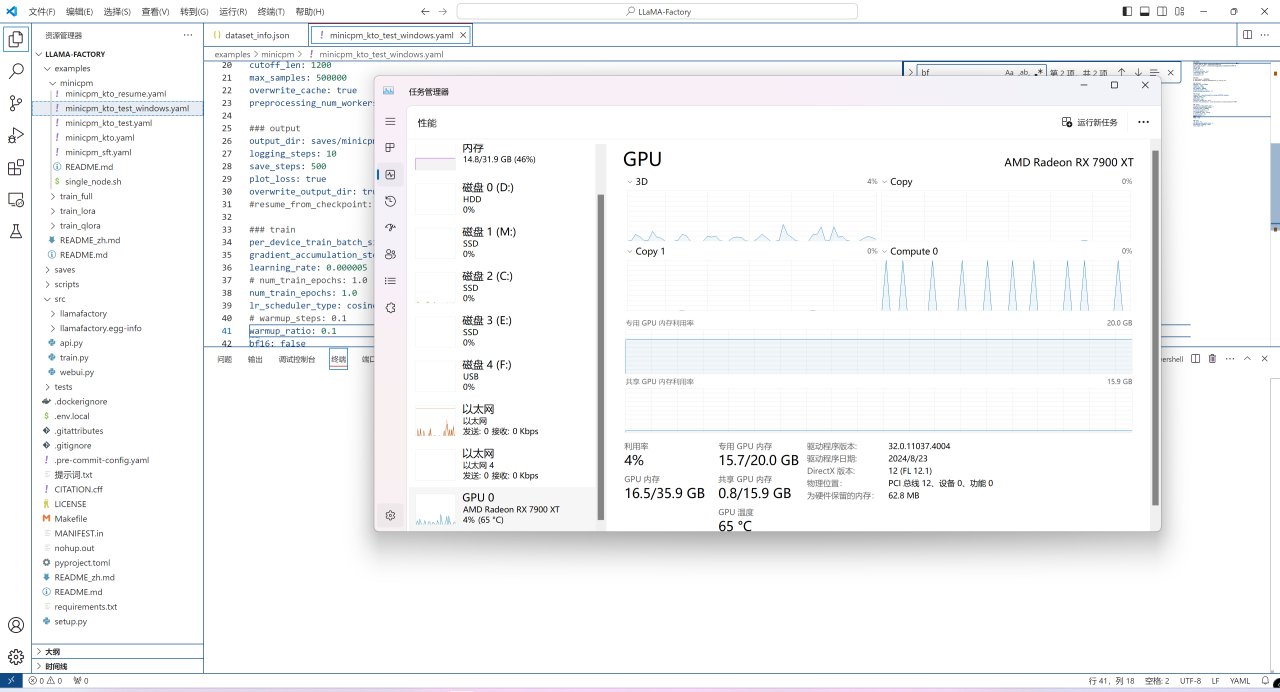
Zluda尽管能够成功运行,但是效率不足
首先进入WSL中,cd到你认为合适的目录,运行以下命令clone源码:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
尽管可以直接在已安装好的环境上进行操作,但为了避免重复安装PyTorch,我这里选择从基础环境clone一份环境,请自行将以下指令的目标和源替换为自己的路径:
conda create --prefix /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/llama-factory --clone /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/torch310
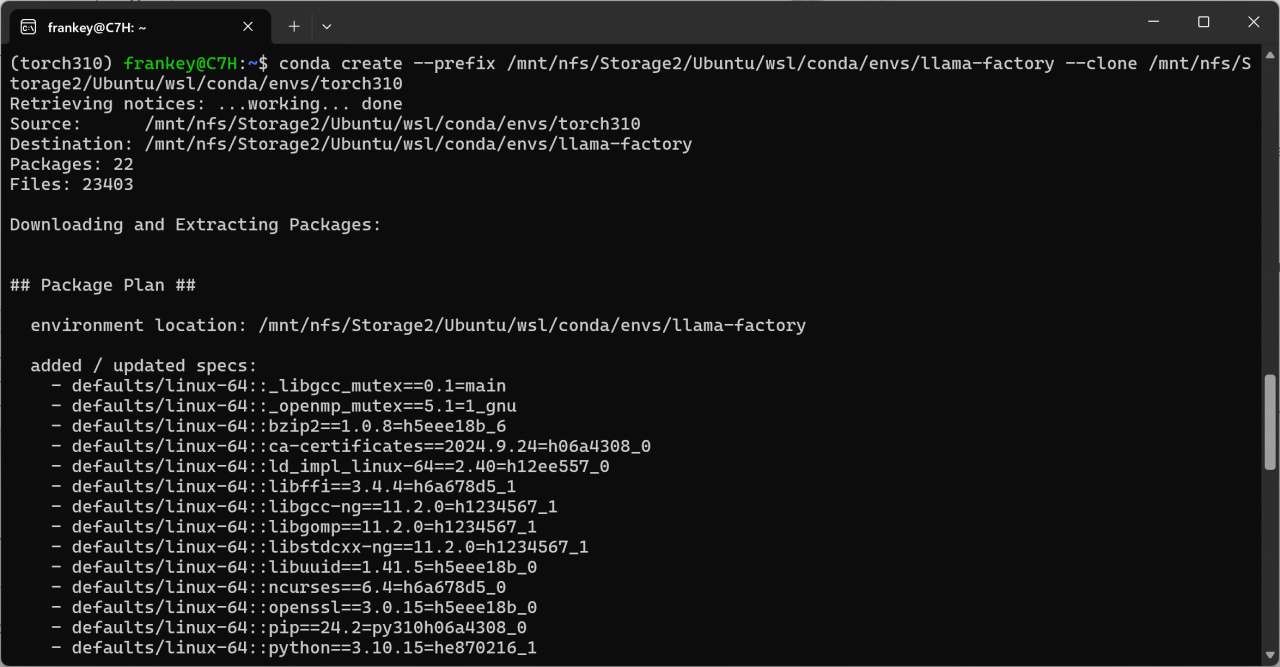
克隆已有PyTorch的基础环境
之后,为方便修改代码和配置文件,直接使用VS Code打开WSL中的文件夹,首先安装VS Code:
https://code.visualstudio.com/download
选择System Installer (x64)
选择System Installer (x64)
安装好后会提示设置语言为中文,之后打开商店安装Remote - SSH远程资源管理器(如果刚才没设置中文的话也可以在商店里面搜索Chinese来安装)。
安装远程资源管理器
之后安装WSL拓展:
安装WSL拓展
之后在远程资源管理器中切换为WSL目标,并选择“在当前窗口中连接”:
切换为WSL目标
在当前窗口中连接
之后选择菜单栏-文件-打开文件夹,打开LLaMA-Factory的源码目录,点击setup.py,在extra_require中找到torch一行并按Ctrl+K+C注释掉:
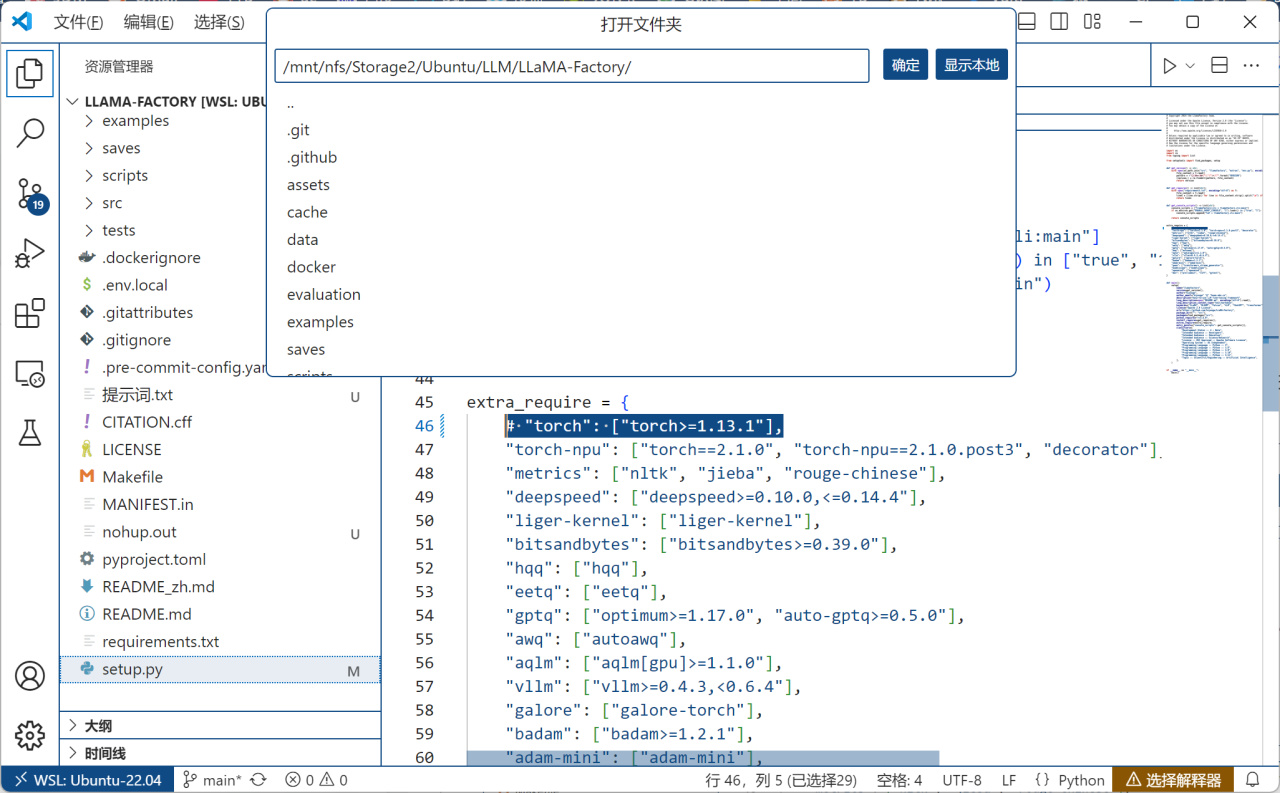
防止重复安装PyTorch
菜单-终端-新建终端打开一个WSL中的终端:
新建终端
切换到刚才克隆的环境中(自行替换为你自己的路径):
conda activate /mnt/nfs/Storage2/Ubuntu/wsl/conda/envs/llama-factory
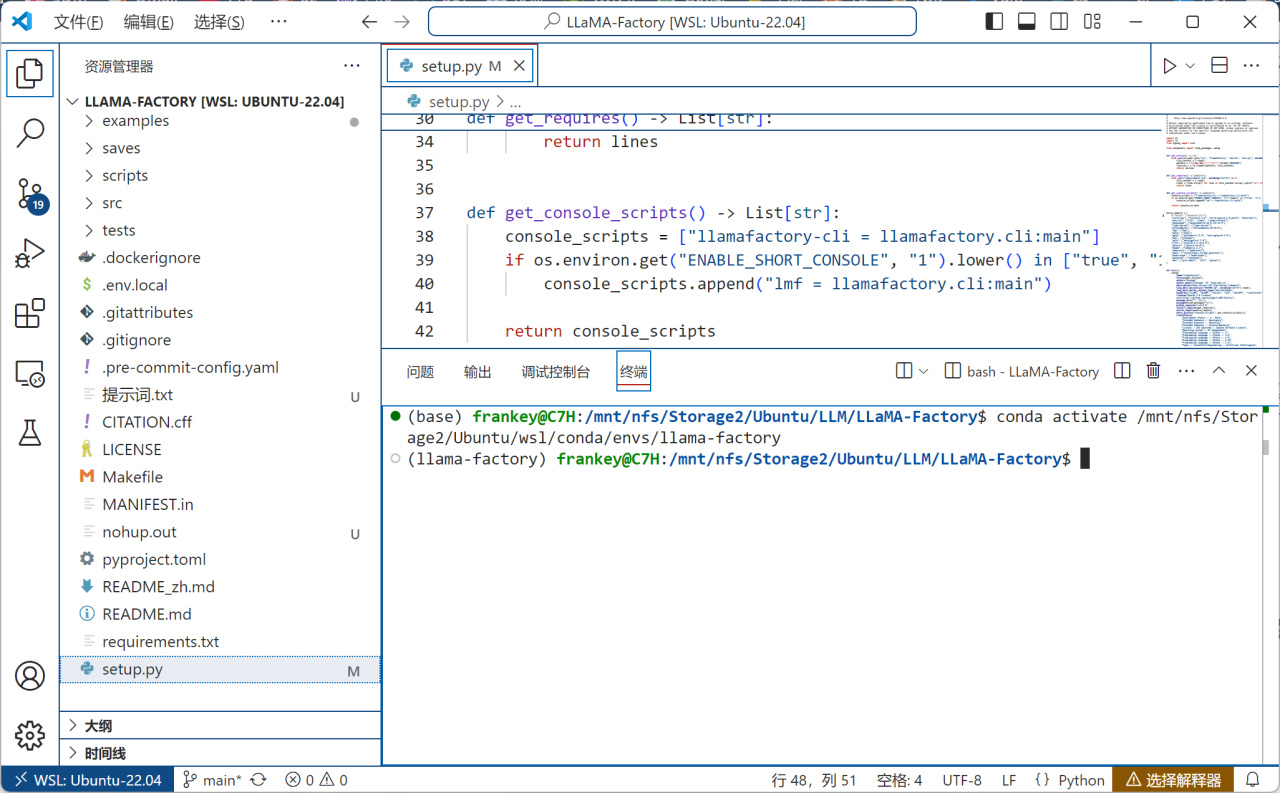
切换环境
运行以下命令安装LLaMA Factory所需要的PyTorch以外的其他环境:
pip install -e ".[metrics]"
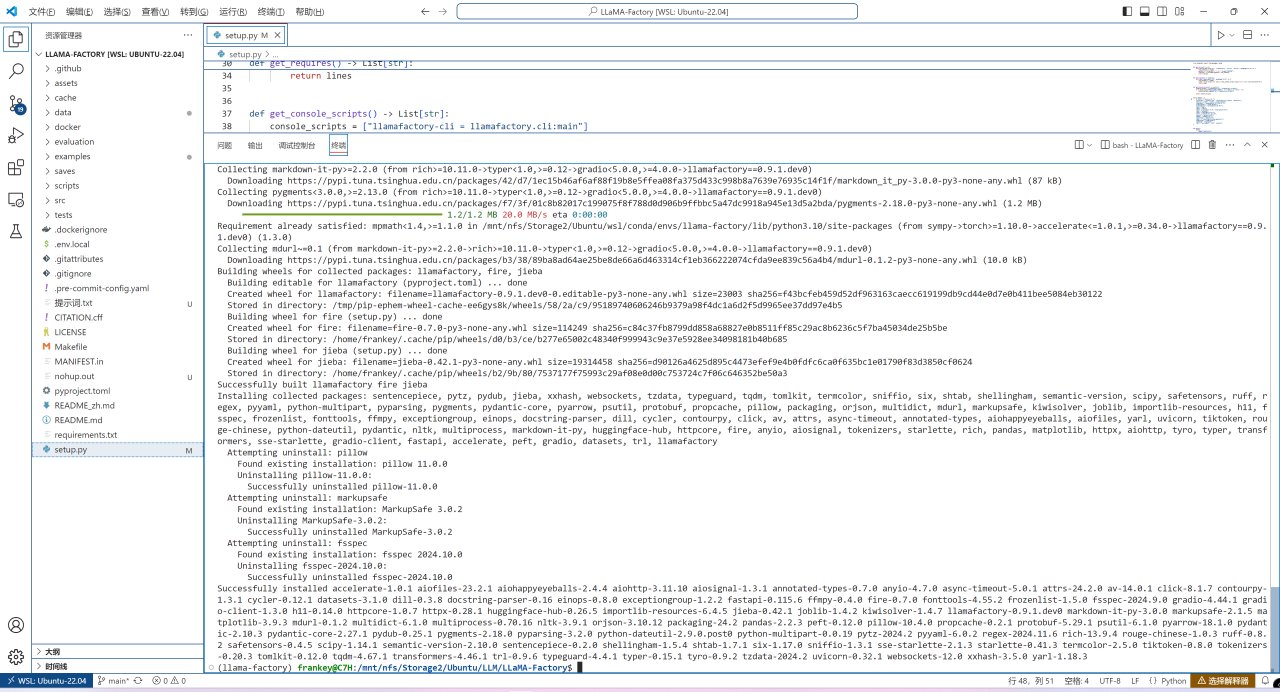
其他环境的安装
暂时离开LLaMA Factory,新开一个终端在你认为合适的目录将MiniCPM相关的代码clone下来:
git clone https://github.com/OpenBMB/MiniCPM.git
之后回到原来的终端,将微调的相关配置和代码复制到LLaMA-Factory的对应目录中:
cd LLaMA-Factory/examples
mkdir minicpm
# 以下代码中的/your/path要改成你的MiniCPM代码和LLaMA-Factory路径
cp -r /your/path/MiniCPM/finetune/llama_factory_example/* /your/path/LLaMA-Factory/examples/minicpm
复制微调配置
之后准备好你的数据集,刚才复制的文件中提供了dpo、kto和sft三种格式的数据格式示例:
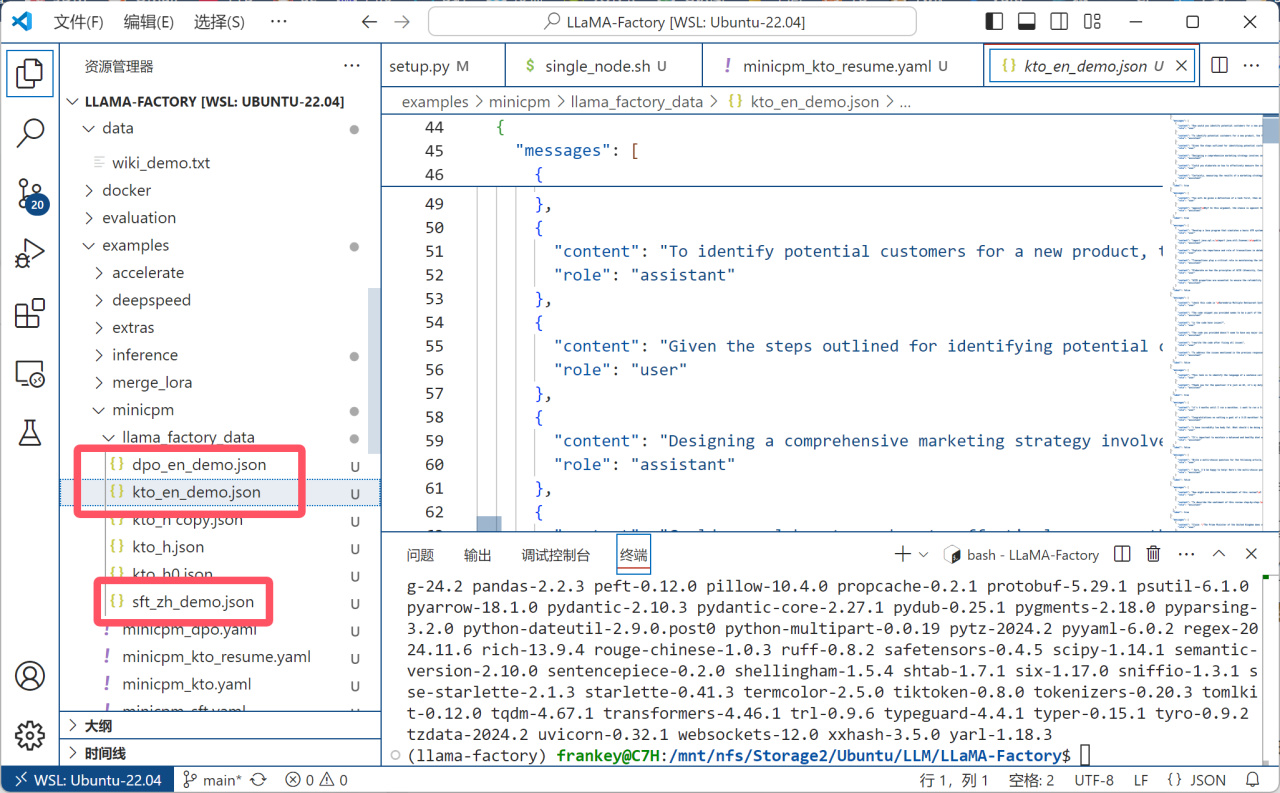
数据格式示例
这里以kto格式为例进行演示,具体介绍详见上面贴出的官方文档链接,其主要特点为每个问题和回复都可以有一个true(好的),或者false(不好的评价):
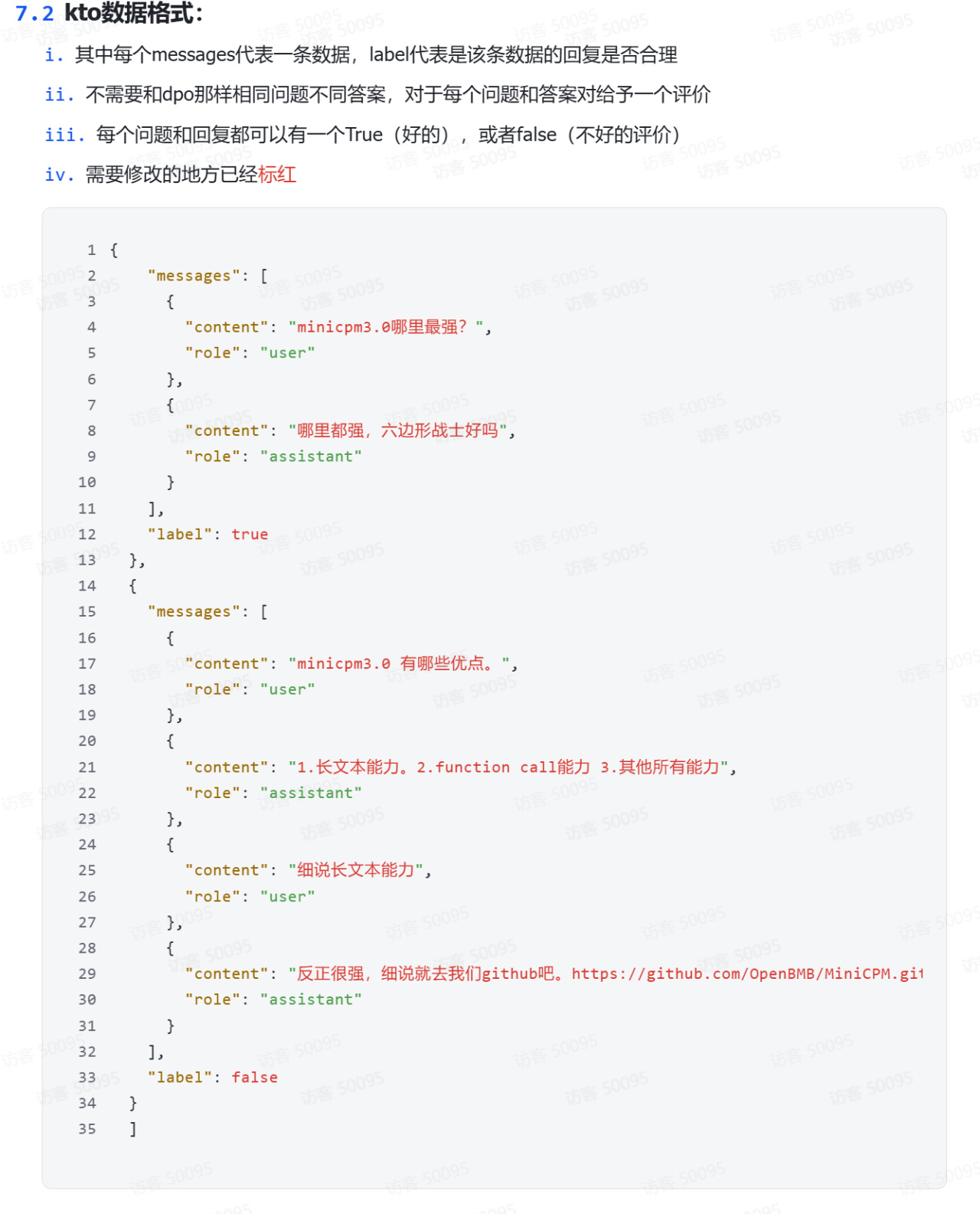
kto格式数据集
我在此处自己爬取并制作了一个具有750组对话的数据集,各位可根据自己的需求自行准备数据集,也可以只给几组简单的"你是谁"的对话,这同样是有效果的。
数据集
之后在llama_factory/data/dataset_info.json中添加数据集信息,保证dataset_info.json中能找到你的数据集:
"数据集名字": {
"file_name": "/改成/你刚才创建的/数据集/的位置.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"kto_tag": "label"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
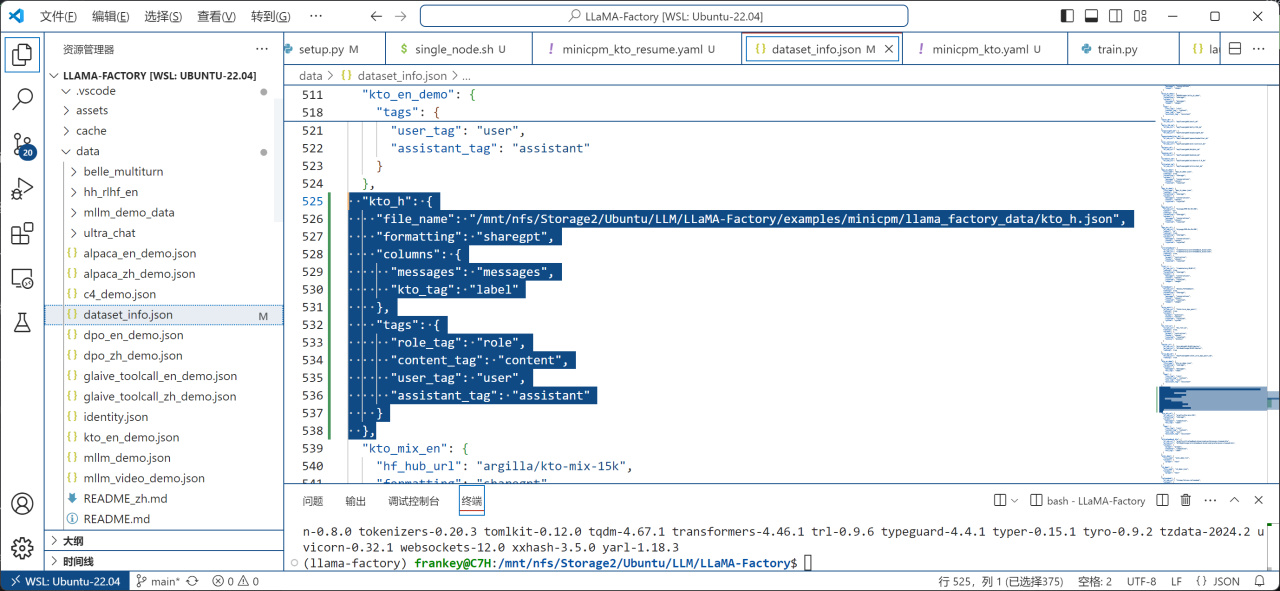
添加数据集信息
之后按照上文中的方式,通过huggingface-cli下载openbmb/MiniCPM3-4B到你指定的目录,唯一不同的是,做为Linux,你需要运行以下指令来设置镜像地址环境变量:
export HF_ENDPOINT=https://hf-mirror.com
模型下载完成后,即可对训练配置进行修改,从之前复制的examples/minicpm/minicpm_kto.yaml示例中再复制一个新的配置文件,并做如下改动:
将model_name_or_path设置为你刚才从HuggingFace下载模型权重的目录;
将finetuning_type从full改为lora;
添加lora_target参数并设置为all;
注释掉kto_ftx参数;
注释掉ddp_timeout参数;
注释掉deepspeed参数;
将dataset从kto_harmless修改为你刚刚在llama_factory/data/dataset_info.json中设置的数据集名字;
将template从cpm修改为cpm3;
将output_dir修改为你想将Lora权重保存在的目录;
将per_device_train_batch_size从4改为1以防止显存不足;
将gradient_accumulation_steps从4改为1;
将num_train_epochs从1改为你想要的迭代次数(走过你一整个数据集的次数);
将warmup_steps参数改为warmup_ratio,否则会报错;
将per_device_eval_batch_size从16改为1以防显存不足。
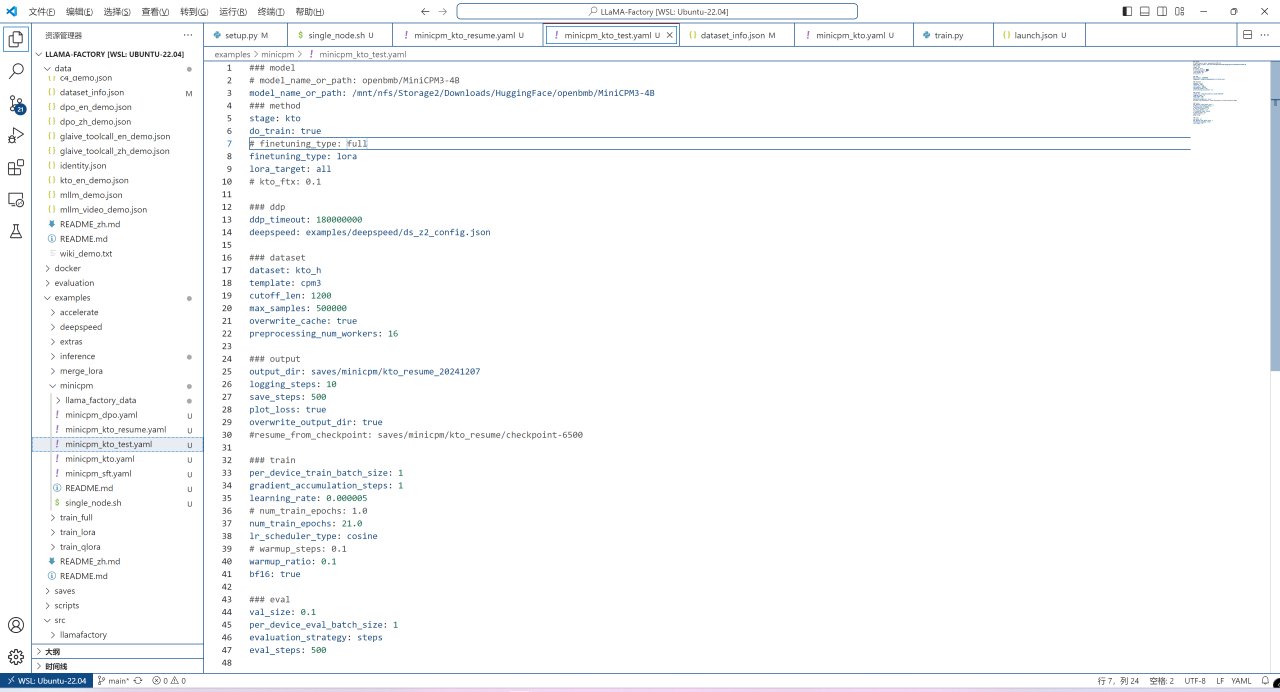
修改训练配置文件
之后选择菜单-运行-添加配置,选择"Python Debugger",再选择"带有参数的Python文件":
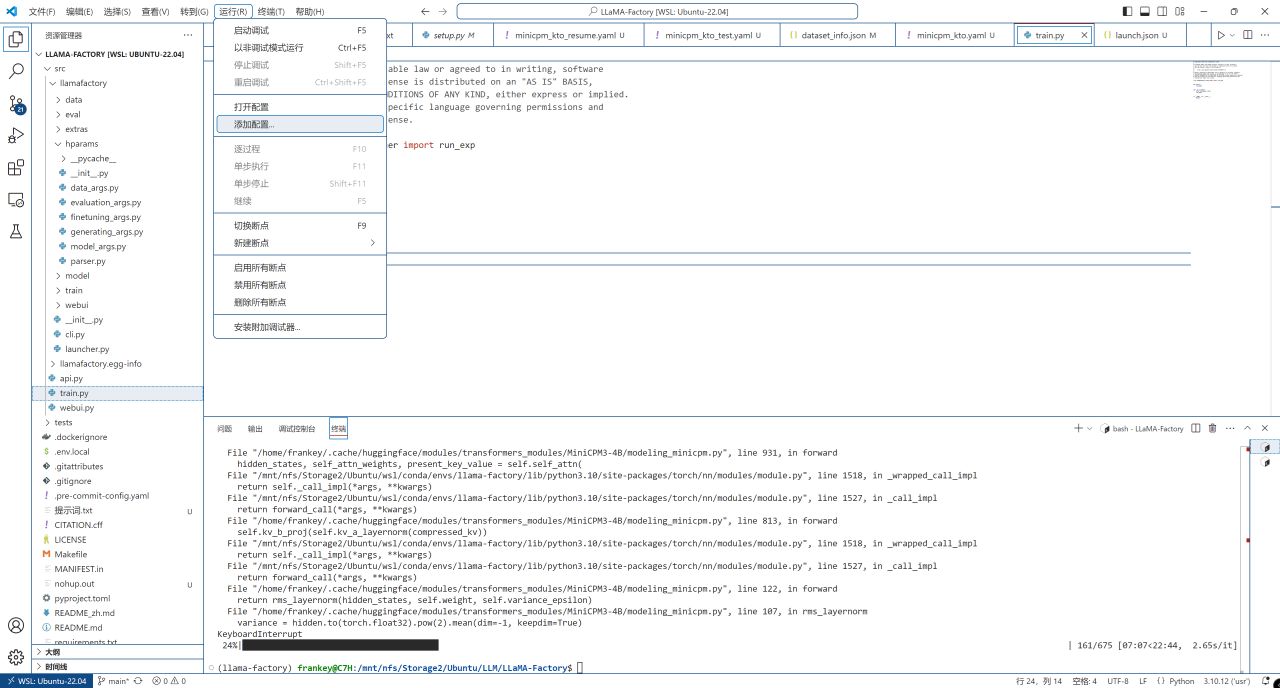
添加配置

带有参数的Python文件
之后如下图,将program改为${workspaceFolder}/src/train.py,再将args改为你刚才创建的配置文件的位置:
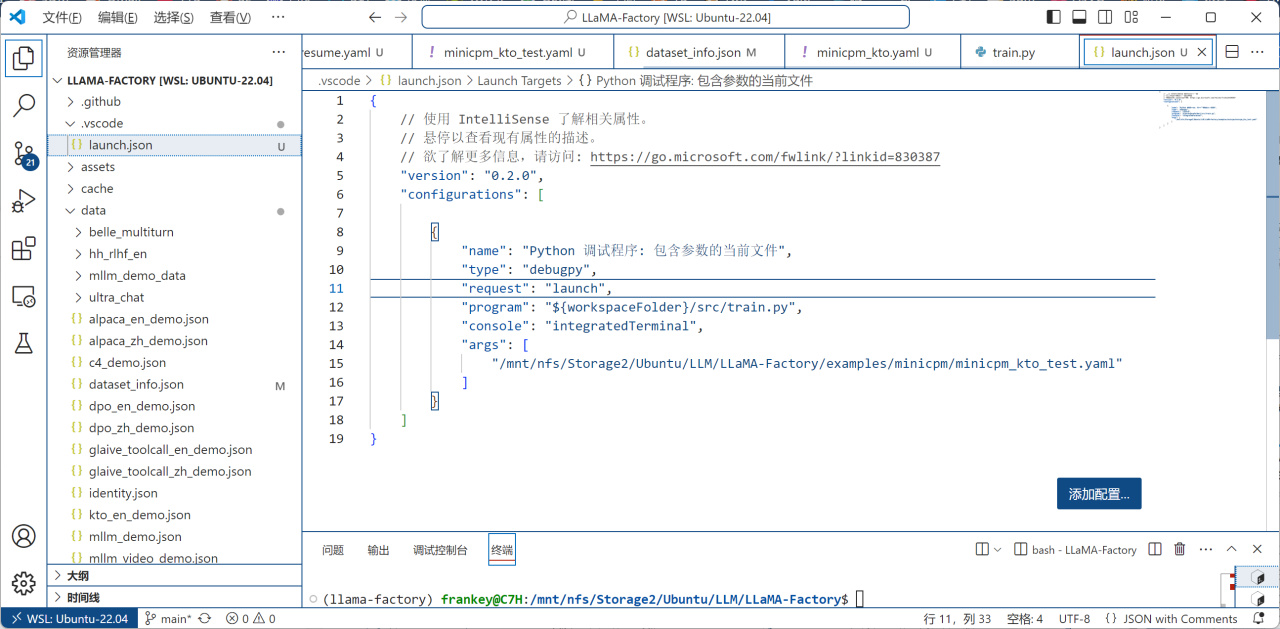
运行配置
之后打开src/train.py,在右下角选择解释器,选择前面创建的那个conda环境:
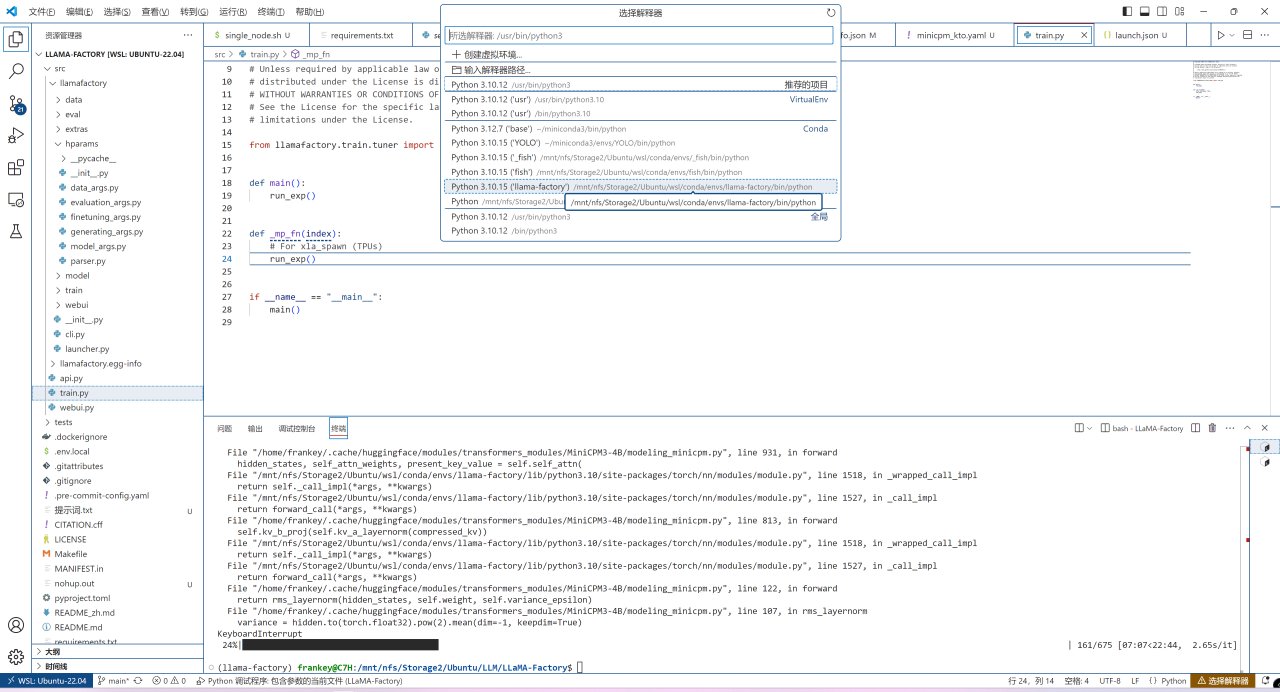
选择conda环境
点击运行-以非调试模式运行:
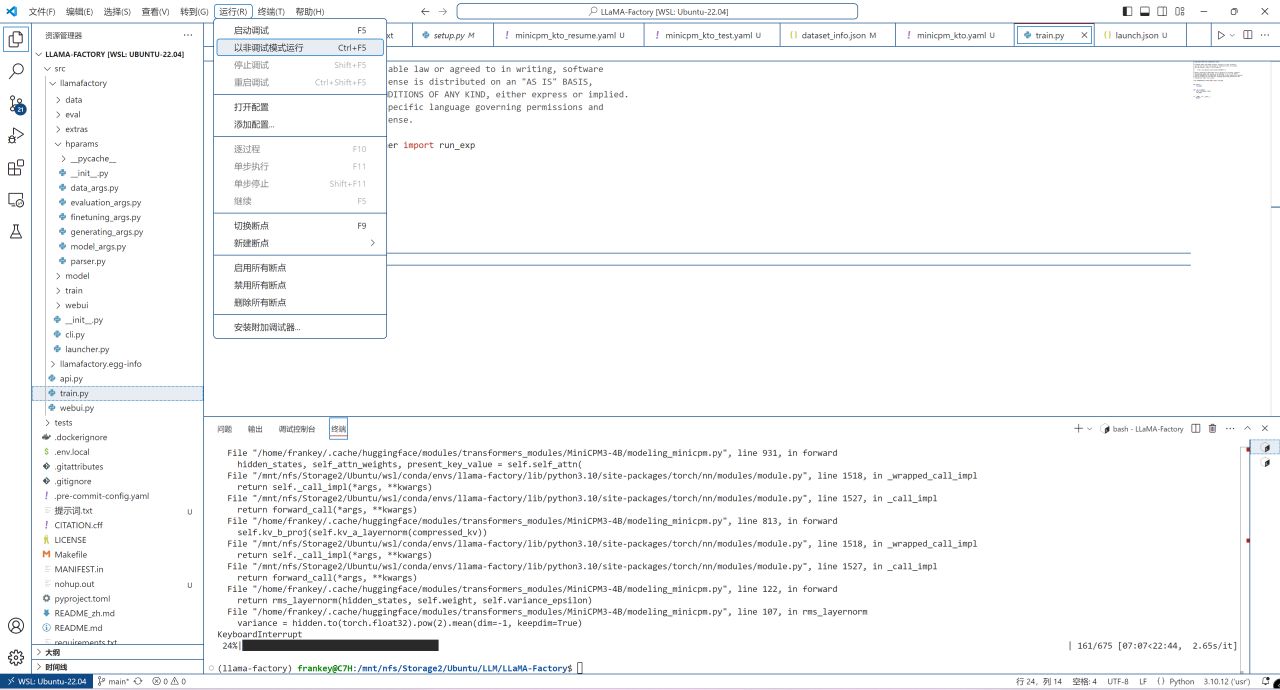
正式运行训练
若提示缺少任何依赖的话,新开一个终端切换到环境直接安装即可,这不会很多。
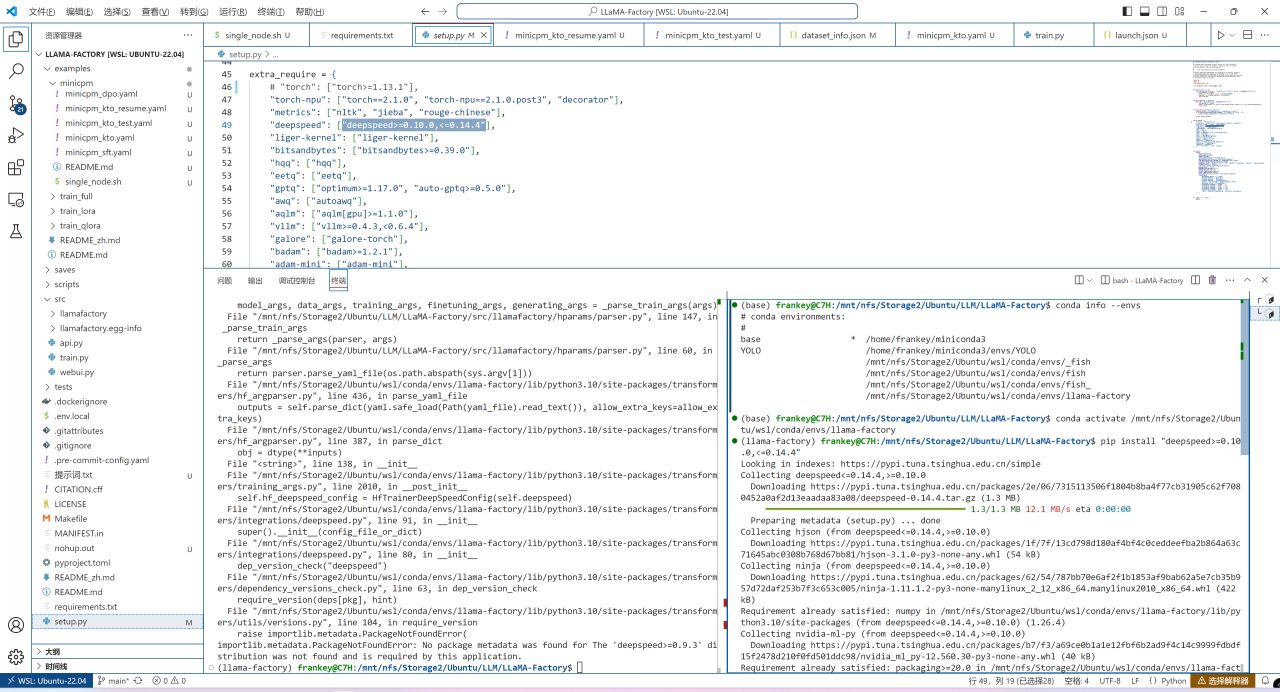
安装遗漏的依赖
此时微调就已经正常开始了,7900XT做为一张20GB显存的显卡,其能够微调的极限大概也就是40亿参数的模型了,各位可根据自己的显存自行选择模型:
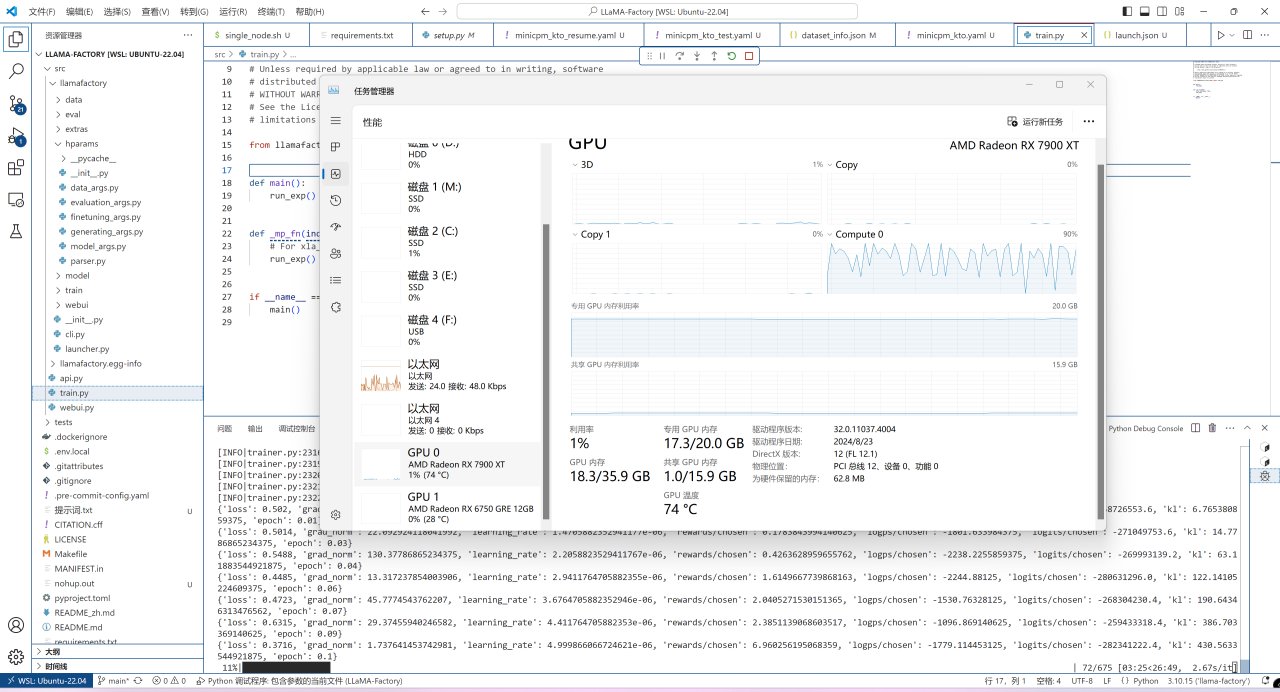
微调训练中的模型
微调结束后的权重和其他文件将保存在刚才的训练配置文件中的output_dir中:
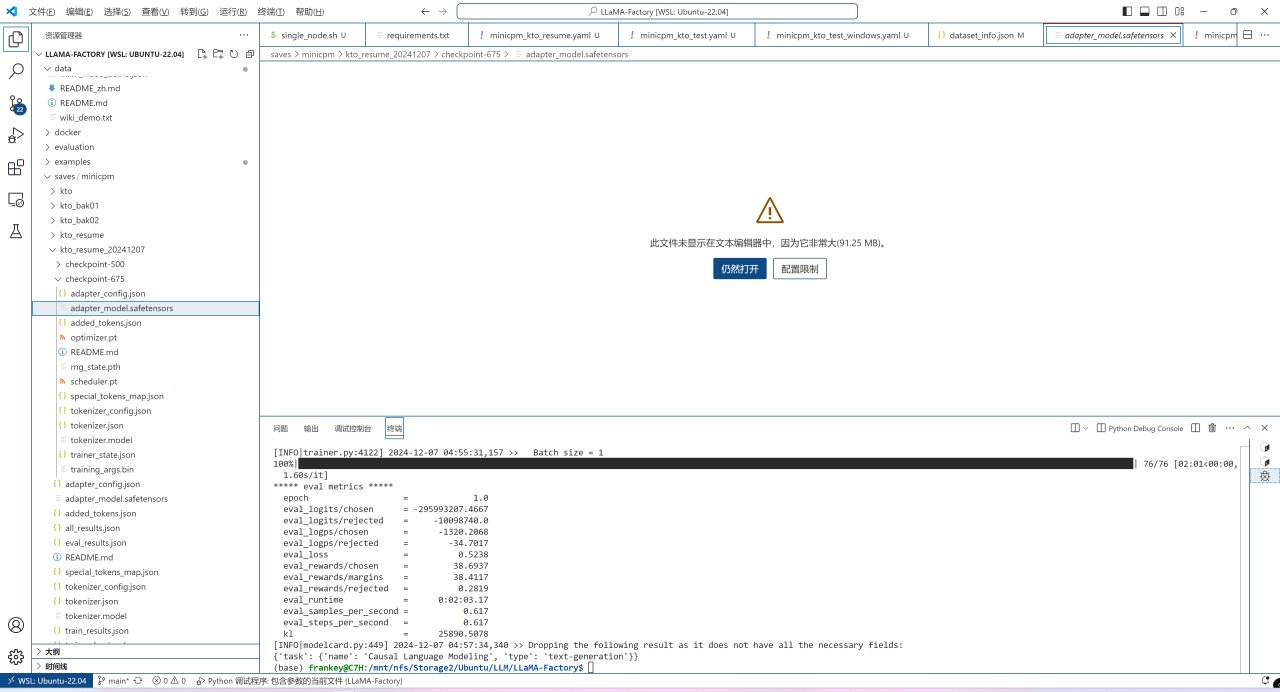
微调训练后的文件
之后则是合并lora权重到原权重中,复制一份examples/merge_lora/llama3_lora_sft.yaml到原目录,将复制的文件名称改为minicpm_merge.yaml,打开后做如下修改:
将model_name_or_path修改为你之前从HuggingFace下载模型权重的目录;
将adapter_name_or_path修改为刚才训练完成的output_dir;
将template修改为cpm3;
将export_dir修改为你要将合并后的模型保存到的位置。
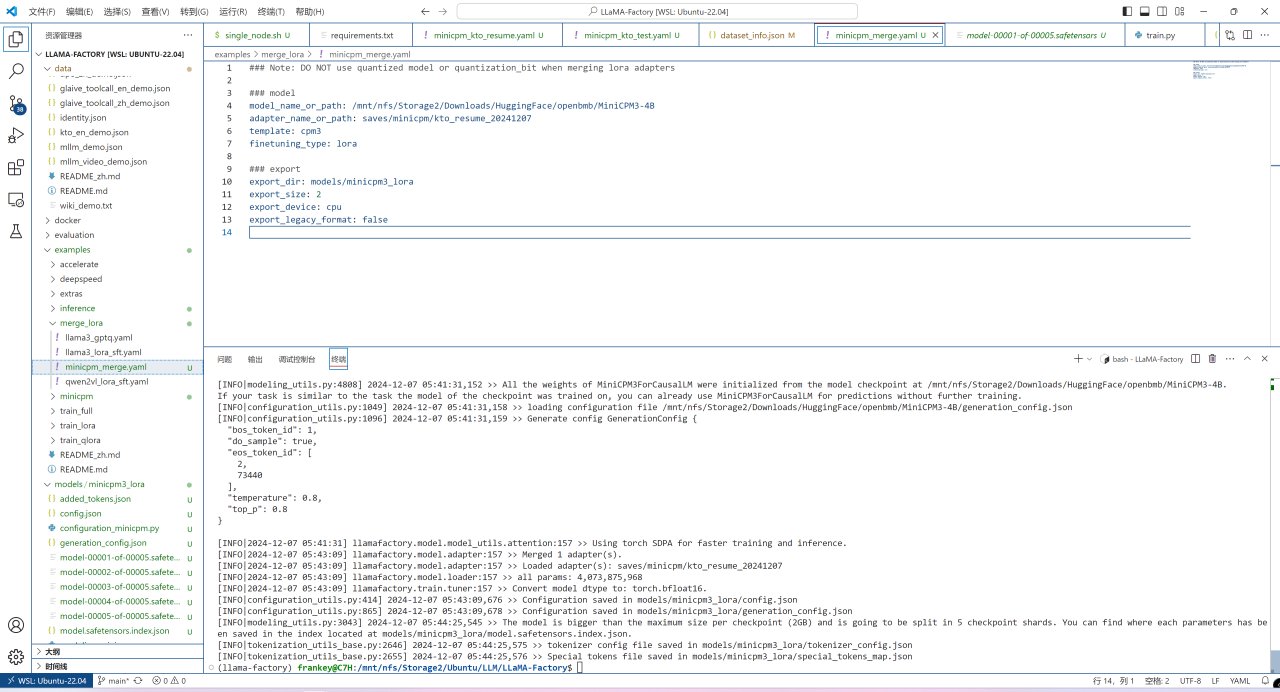
模型合并配置文件
之后运行如下指令正式开始合并:
llamafactory-cli export examples/merge_lora/minicpm_merge.yaml
合并完成后的文件会以safetensors的形式保存在上面设置的输出目录中:
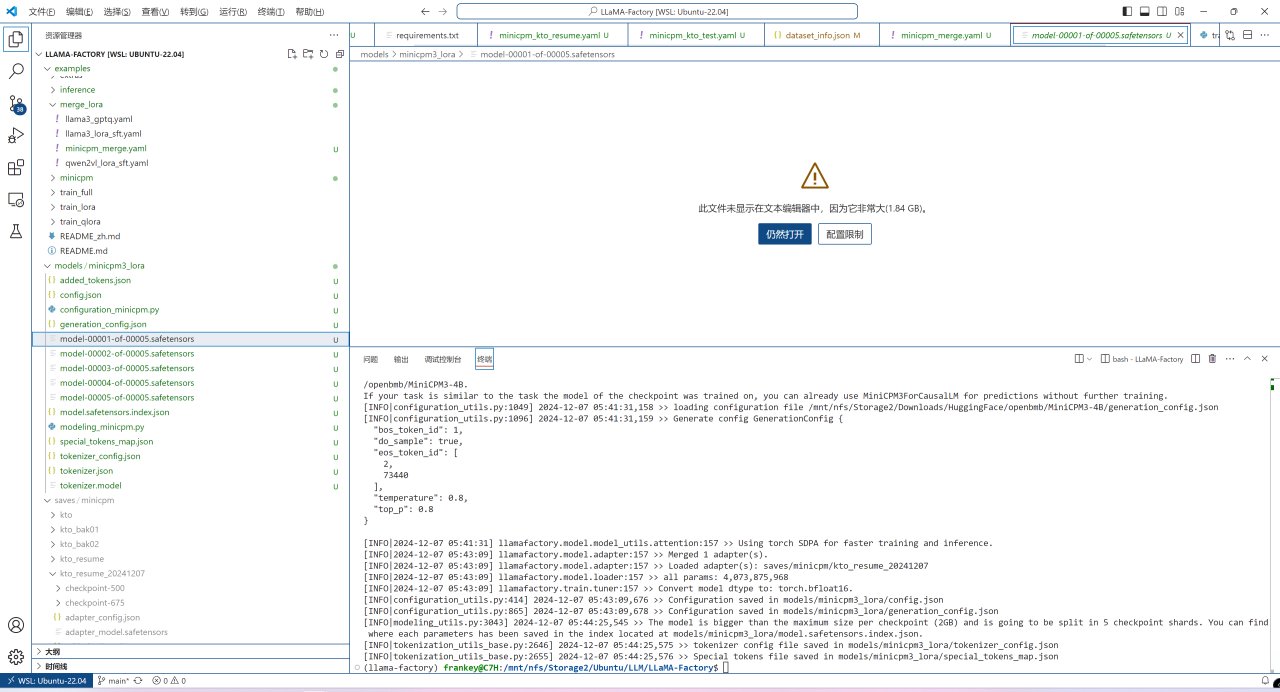
合并完成后的文件
此时WSL中的工作已经结束,切换到Windows中llama.cpp的目录,准备将safetensors转换为gguf。
首先新建一个conda环境并切换到该环境,运行如下指令安装llama.cpp的python相关程序(主要为转换)的代码,由于我们仅在此环境进行转换,无需运行推理,故此处的PyTorch版本可直接使用其默认的CPU的版本。
pip install -r requirements.txt
之后运行如下指令将safetensors转换为gguf,记得把输入目录和输出路径改为你自己的:
python convert_hf_to_gguf.py J:\Ubuntu\LLM\LLaMA-Factory\models\minicpm3_lora --outtype bf16 --outfile J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora.gguf
转换完成后输出目录就会出现我们需要的gguf文件:
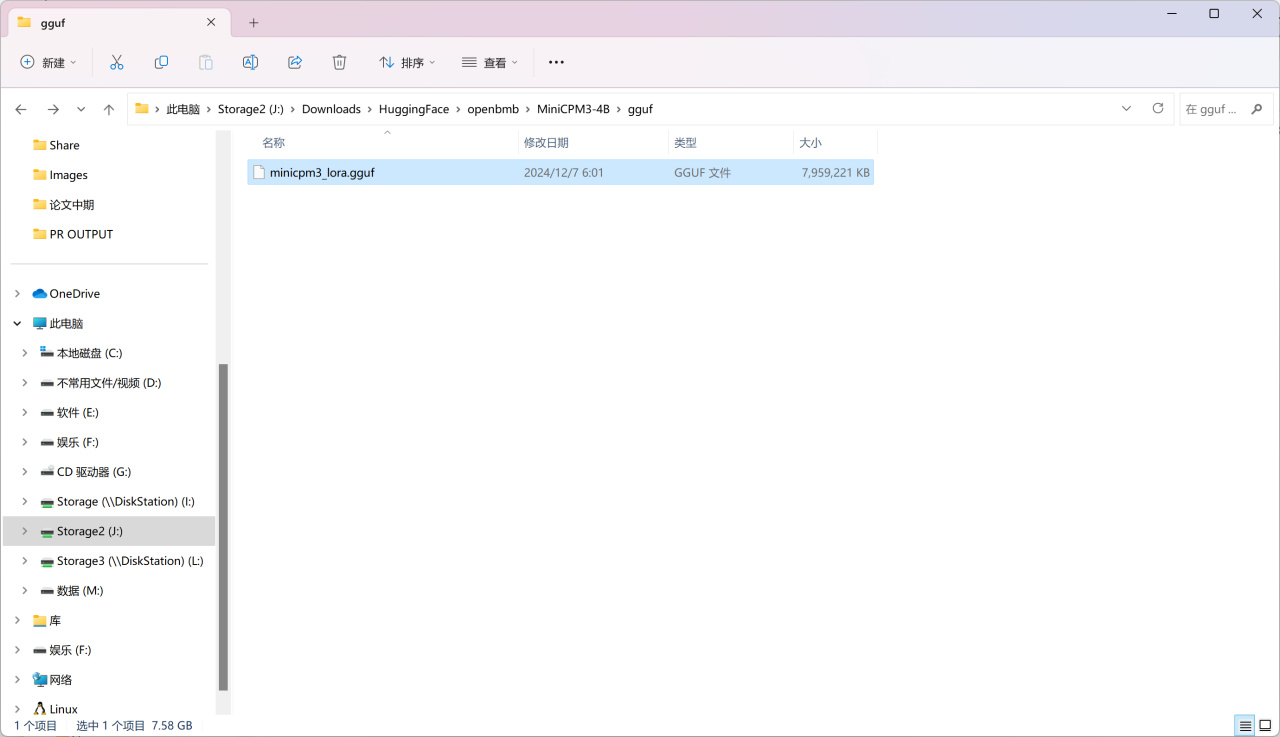
输出的gguf
之后运行如下指令来量化模型,依旧需要将输入和输出路径换为你自己的,另外此处的精度是q8_0,你也可以根据自己的需要进行更改:
"./build/bin/llama-quantize.exe" J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora.gguf J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora_q8_0.gguf q8_0
之后运行量化后的模型,依旧需要把路径改成你自己的,测试完全成功,需要注意的是,不同于上面的Qwen2.5,这里-fa参数需要移除掉以禁用flash attention,否则会输出乱码:
"./build/bin/llama-server.exe" -m J:\Downloads\HuggingFace\openbmb\MiniCPM3-4B\gguf\minicpm3_lora_q8_0.gguf --port 8084 -a qwen -ngl 80 -n -2 -mg 0 -sm none --host 0.0.0.0
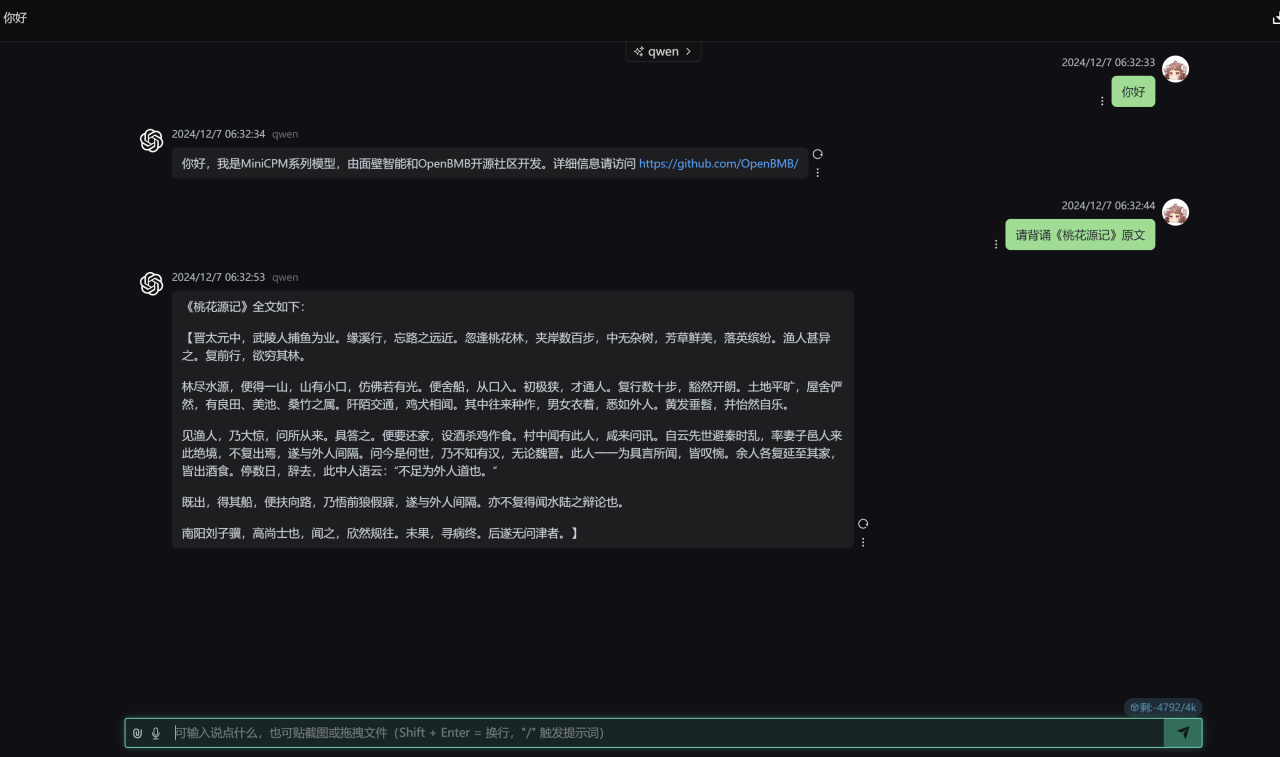
运行量化后的Lora模型
到此为止,本篇教程完全结束。如果你跟着操作到了这里,那么恭喜你,你已经可以用一张AMD GPU完成从微调训练到转换再到量化最后到推理的完整流程,彻底把模型掌握在自己的手中。从此,你手中的A卡不止可以用来玩游戏,至少在AI方面,他成为了一个高性价比的生产力工具。接下来我将继续发布有限显存下A卡运行AI绘画大模型(FLUX.1)的教程,同时语音克隆和其他模型也在日程之内,而有了这两篇教程的基础,剩余的教程将变得十分简单,各位敬请期待。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















