兄弟们,前段时候OpenClaw 确实挺火,它不只是能聊天,还能帮我们读文件、整理资料、执行任务,用起来确实挺有意思。
且除了使用云端模型外,本地部署模型玩一玩也是可以的。
比如用 Ollama 或者 LM Studio 在本地跑大模型,再让 OpenClaw 调用它们,既能省下部分 Token 成本,也能把模型和数据留在自己电脑上。

不过我感觉好像说起本地部署AI大模型基本上都在强调显存,但针对系统内存,好像很少有人认真测试过。我就有个疑问,内存对模型运行影响有多大?是提升速度还是决定能不能跑?显存不够时,内存会不会成为决定模型上线的关键?
为了这次测试,我准备了 6 组不同容量的新乐士屠龙勇士 DDR5 6000 CL28 内存,容量覆盖 16GB 至 128GB,总价值超过 27000 元。该系列采用海力士 A-die 原厂颗粒,主打高频、低时序与稳定表现,适合用于本地 AI、多任务与高负载场景测试。

本次测试尽量控制其他变量,仅调整内存容量。除内存容量外,测试平台、软件环境、模型版本和测试问题均保持一致。本地部署工具使用 LM Studio,测试模型分别为 Qwen3.5-9B 和 Qwen3.5-27B。

测试平台:
cpu为ultra7 265k
GPU为9070xt 16GB
主板为微星Z890刀锋钛
内存条为新乐士屠龙勇士6000CL28 A-die

准备了两个测试内容:
一个是针对LM Studio的问题:
假设你的抽屉里有 12 只红色袜子、8 只蓝色袜子和 6 只白色袜子。房间里一片漆黑,你看不见颜色。
请分步计算:你最少需要拿出多少只袜子,才能百分之百保证凑出一双“同色”的袜子?
如果要保证凑出“三只颜色相同”的袜子,逻辑又是怎样的?
请详细推导过程,并给出最终答案。
另一个是让open claw执行实操任务
读取我桌面的会议记录,并写一篇会议内容总结放在我桌面的办公文件夹中
测试项目:
1.内存占用/GB
2.回复问题总耗时/s
3.输出速度多少token/s
4.openclaw执行任务总耗时/s

下面测试开始,首先上场的模型是千问3.5 9B,我们先测试 OpenClaw 执行任务的速度。内存容量:
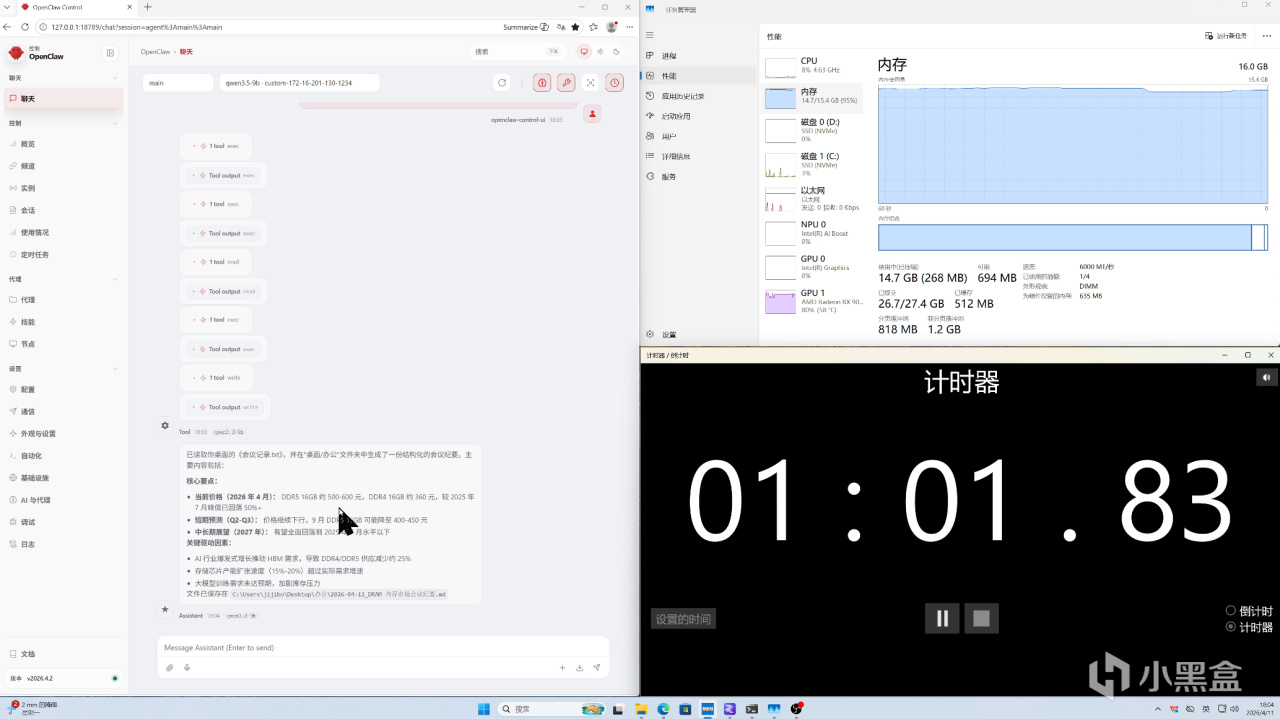
【16GB】
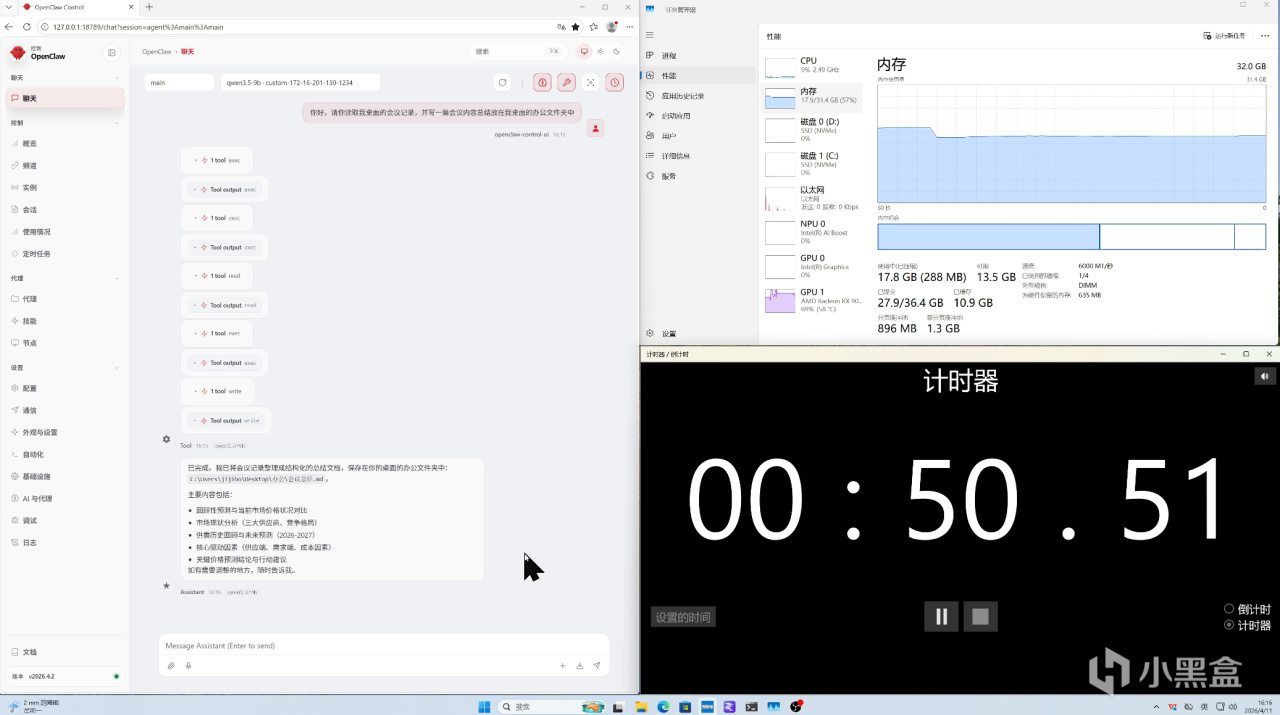
【32GB】
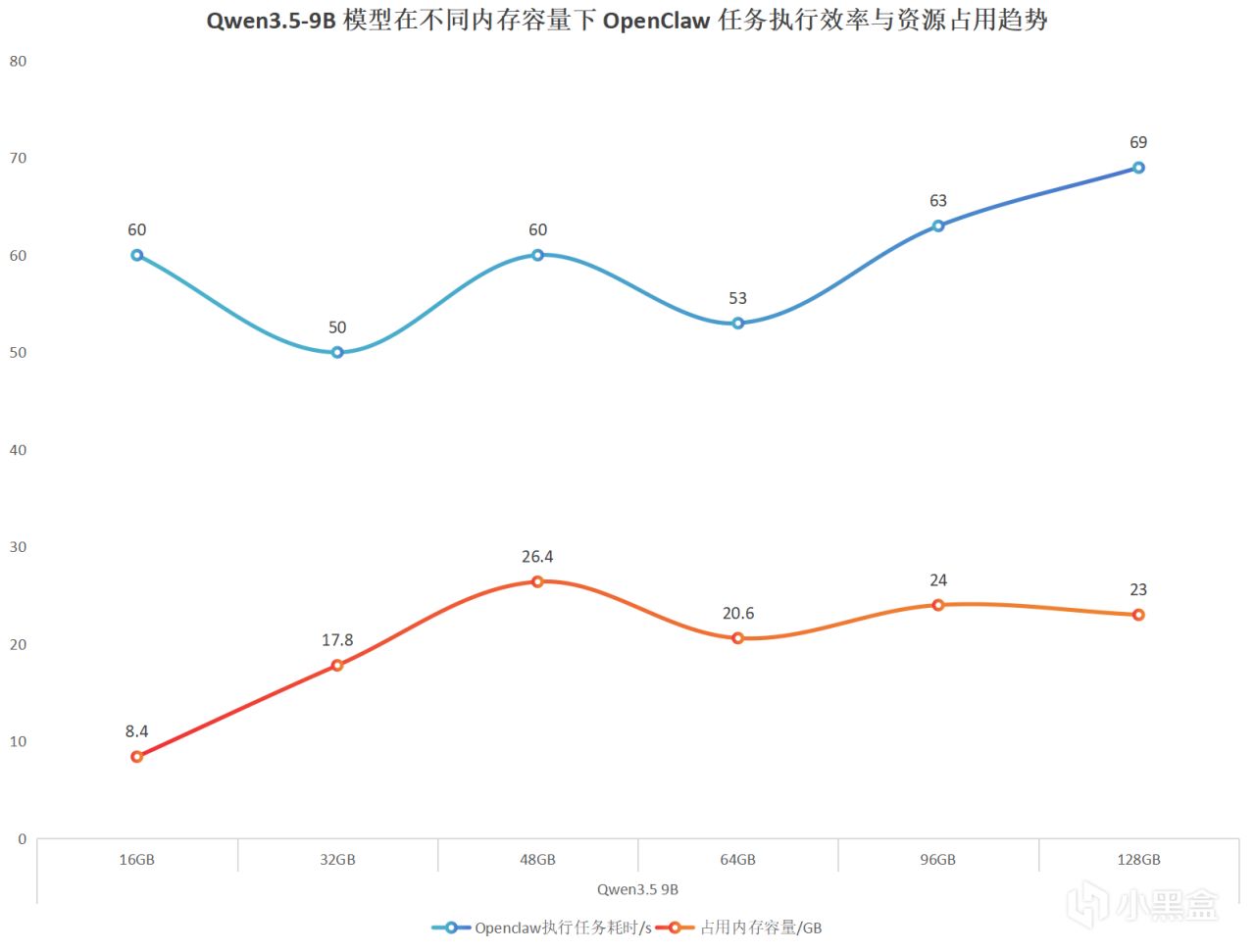
从测试结果来看,在显存充足的前提下,Qwen3.5-9B 执行 OpenClaw 任务的耗时并没有随着内存容量增加而持续下降。整体来看,任务耗时呈现波动变化,而不是“内存越大,推理越快”的线性趋势。但更大容量的内存,在实际使用中会提供更充足的系统余量。比如在运行 OpenClaw 的同时,浏览网页、打开其他软件等多任务操作,整体使用体验会更加从容。
下面我们来看看 LM Studio 的表现,
【16GB】
【32GB】
【48GB】
【64GB】
【96GB】
【128GB】
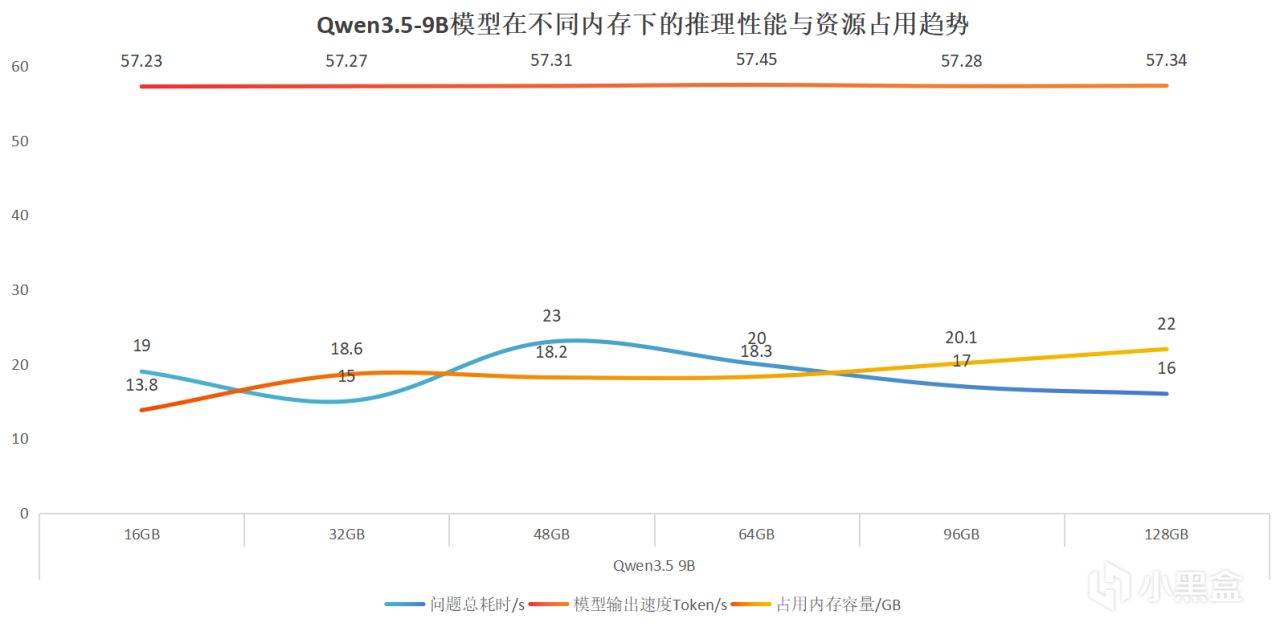
我们汇总数据可以看出,输出速度基本稳定在57token每秒左右,波动很小,问题总耗时也没有随着内存增加而明显下降。所以在显存充足的情况下,即便提升内存容量,推理速度也没有出现明显的线性提升,整体差异相对有限。
那么显存不够的情况下?当然,模型会部分加载至内存,也就是显存加内存协同。

时候内存容量越大,能尝试的模型上限就越高。为了量化不同内存容量对该极限场景性能的影响,我们还是来测一测。

依旧先看看龙虾的表现。
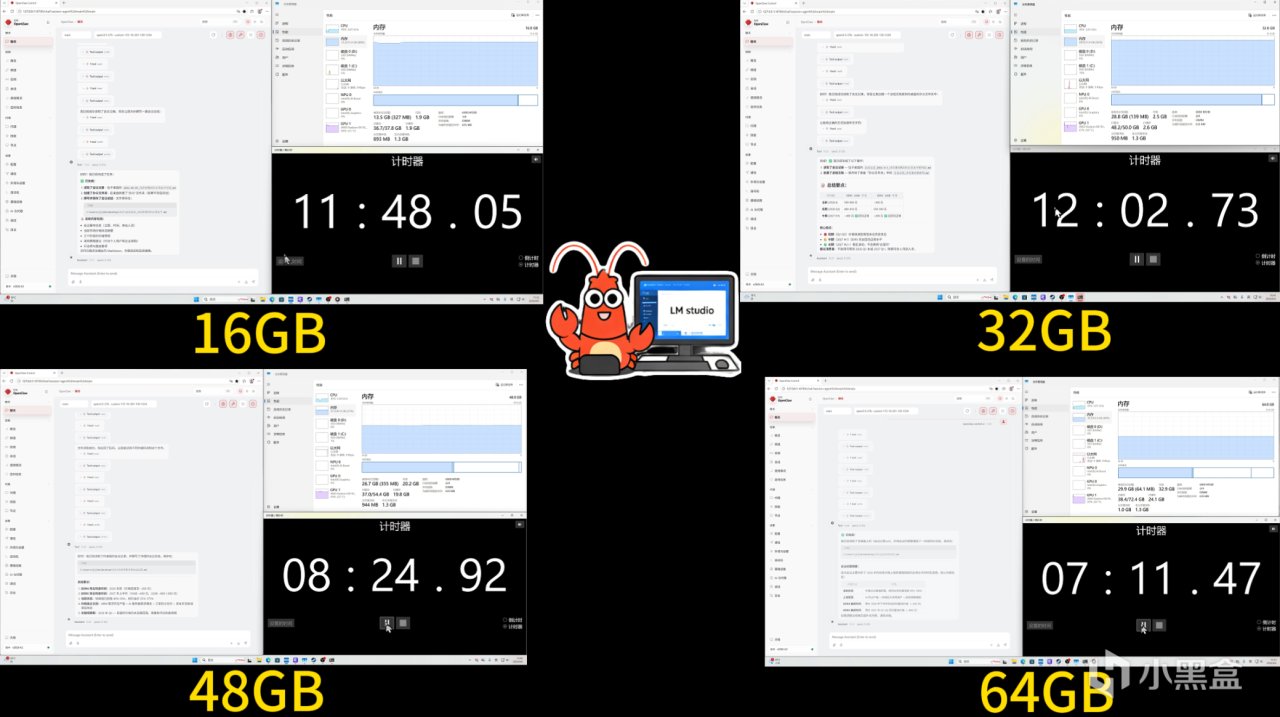
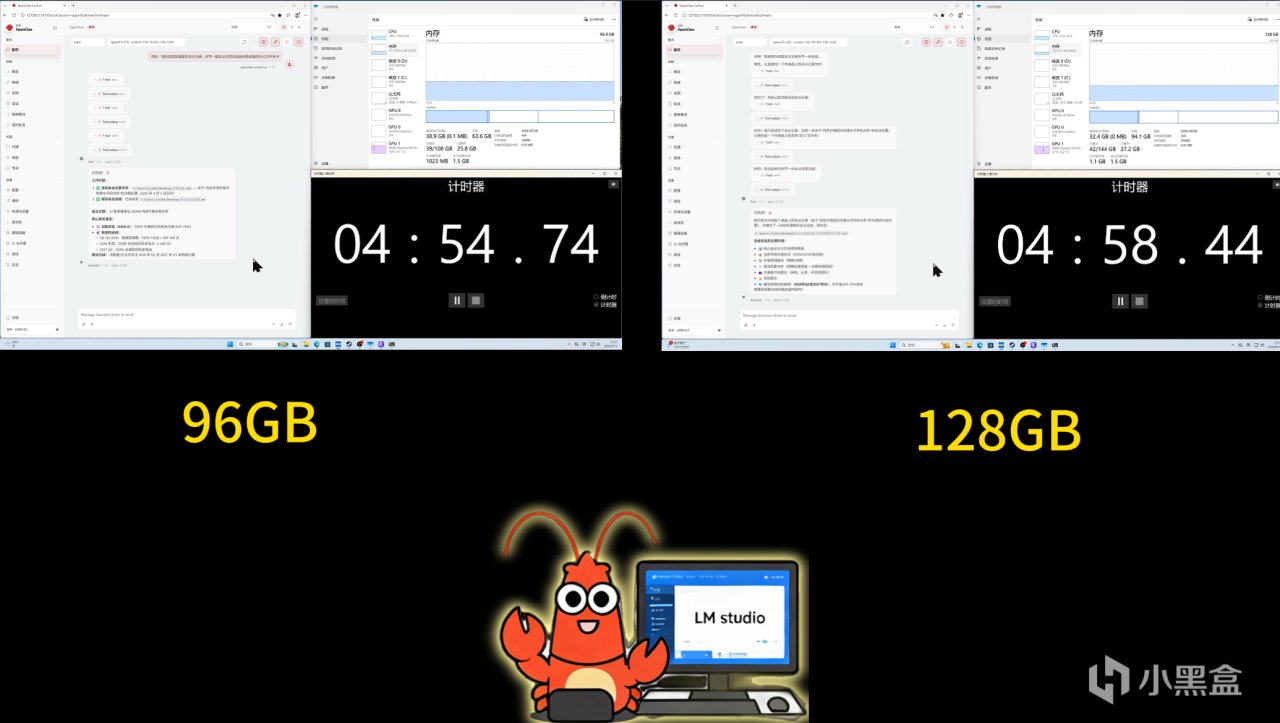
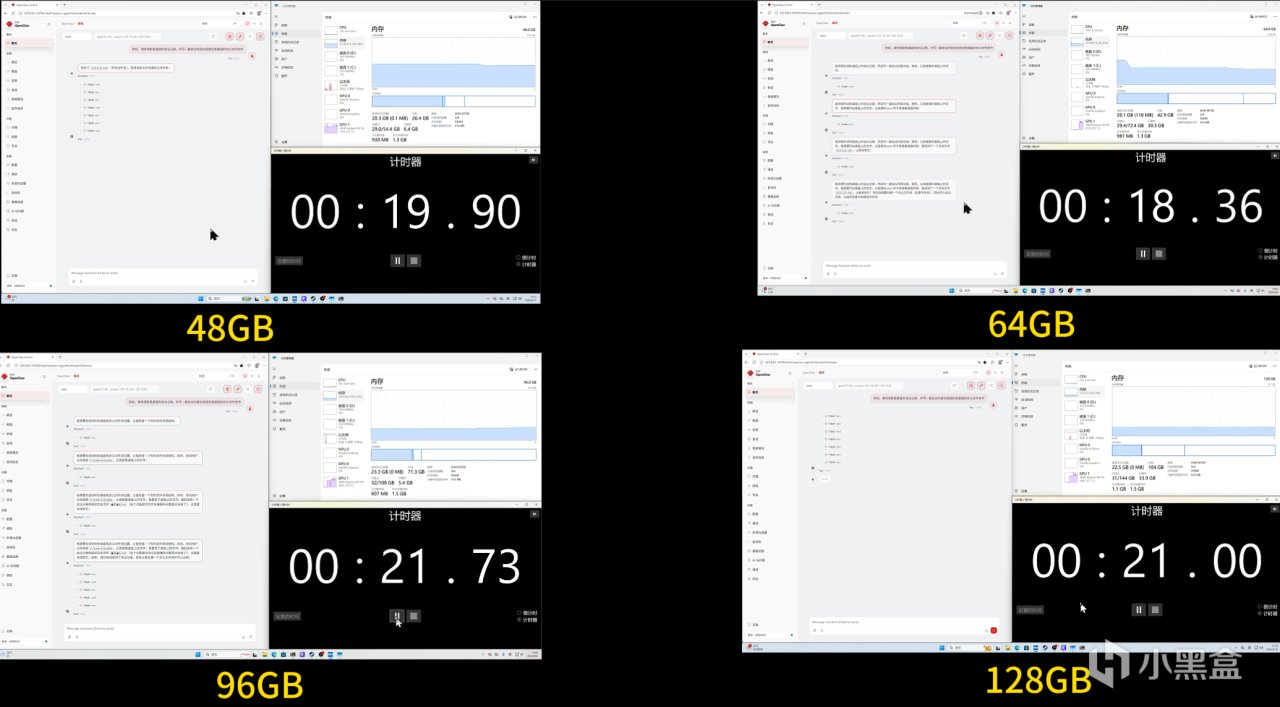
在千问27B这个场景下,由于模型规模已经超过显存容量,系统需要依赖内存参与运行。这时候不同内存容量之间的差异就非常明显了。
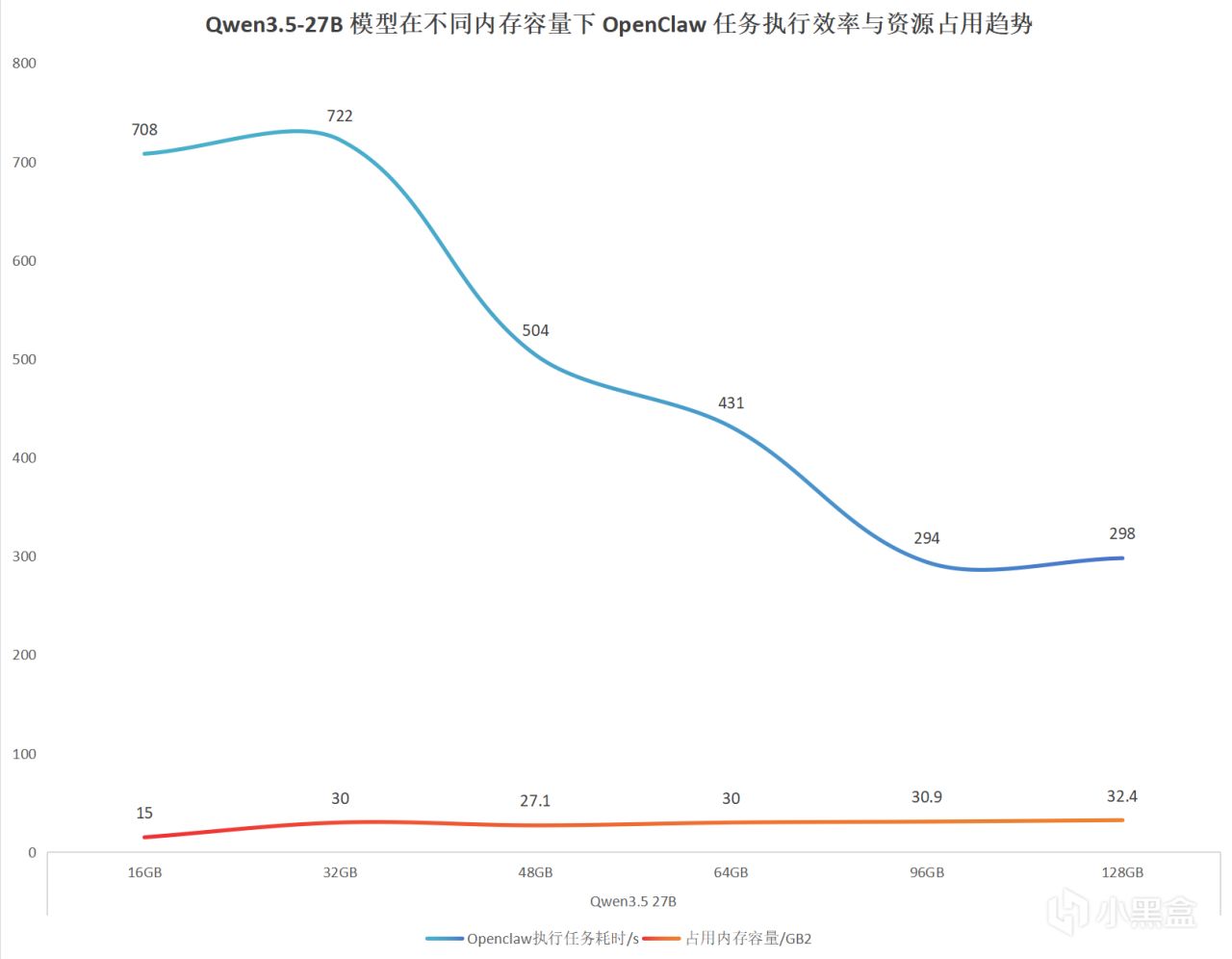
可以看到在16GB和32GB配置下,任务执行时间分别达到了708秒和722秒,整体表现较差,已经明显受到内存容量限制,进入了资源瓶颈区间。提升到48 GB 之后,总耗时下降到了504秒,得到了明显的改善。一直增加到后面的96 GB 都有很明显的提升。但到了128 GB 耗时反而和96 GB 差不多,可以看出性能已经进入相对稳定区间。
那 LM Studio呢?
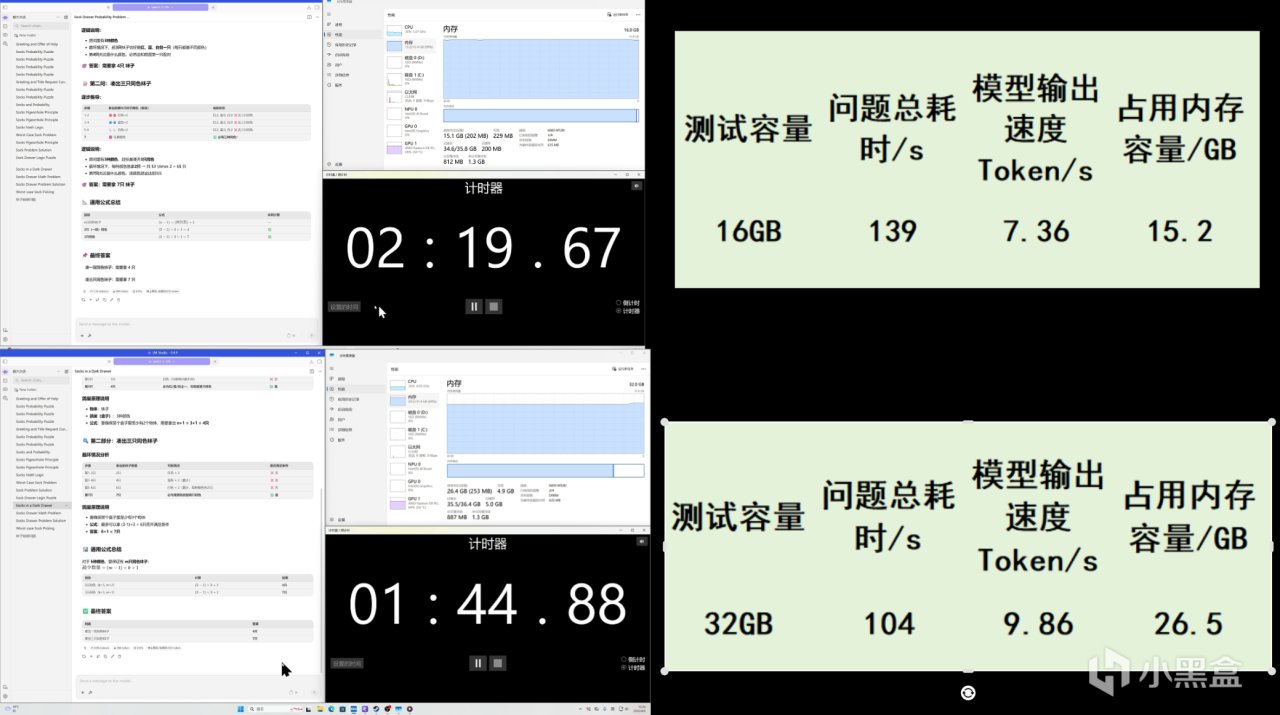
汇总数据我们可以看出,
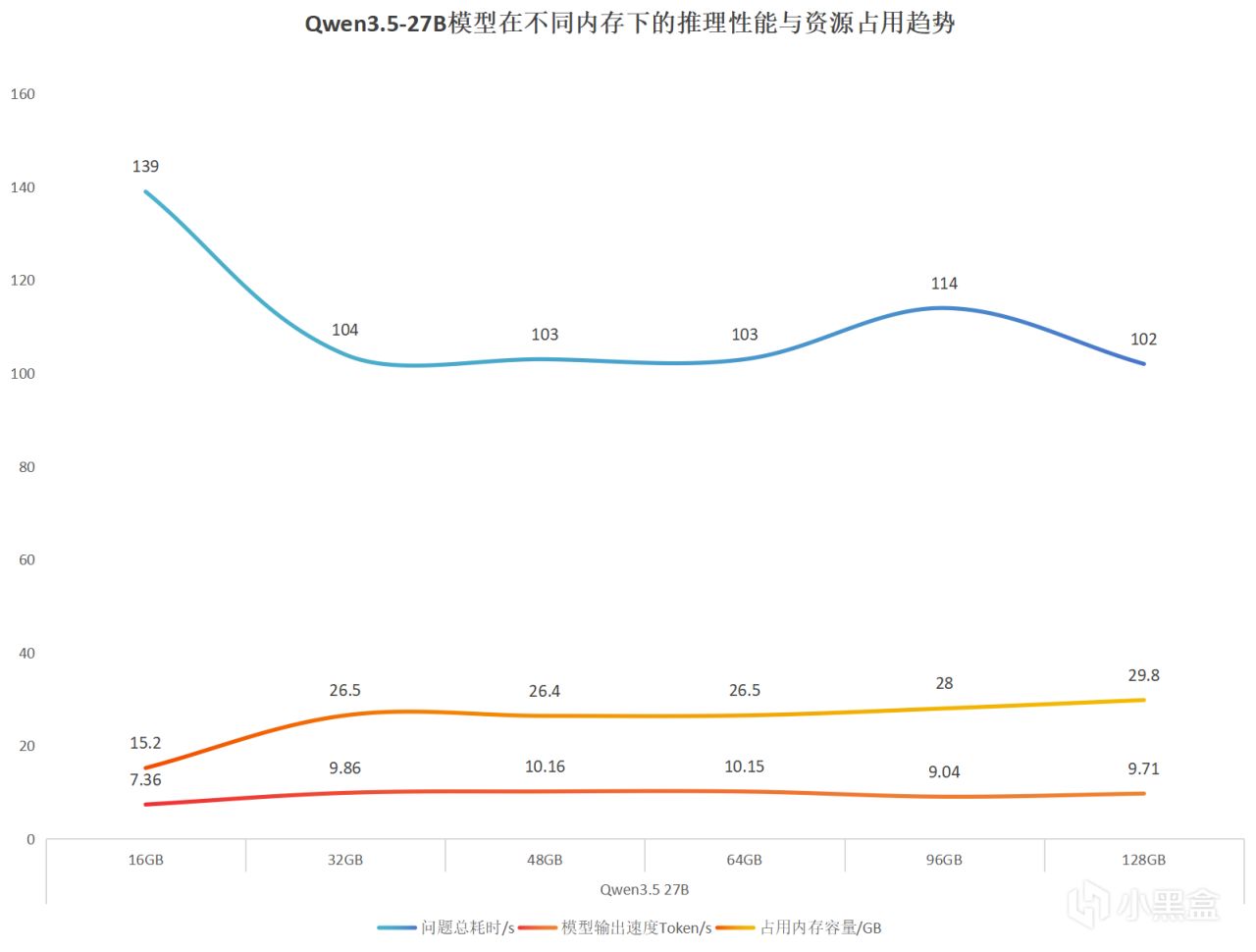
在16GB 容量下,会因模型内存需求不足导致性能严重下降。不过从32GB 开始,性能基本进入稳定区间。在网上提升容量对推理速度的帮助已经不明显了。
测试表明,如果只是运行中小规模模型,并且显存足够,那么内存容量满足基础需求即可,对推理性能的影响相对有限;但如果你希望在本地环境中尝试更大参数规模的模型,尤其是在显存只有8GB、12GB或16GB的情况下,内存容量就会成为一个更加关键的变量,合理提升内存配置可以在一定程度上提高模型的加载成功率,改善运行过程中的稳定性,同时拓宽可运行模型的规模范围;而在预算相对充足的前提下,在显卡显存之外搭配更大容量、性能表现更均衡的内存配置,也能够为本地AI部署提供更充足的资源空间,在面对更大模型或复杂任务时带来更加从容和稳定的整体使用体验;

例如本次测试所使用的SAMNIX新乐士屠龙勇士内存条,新乐士团队基于长期深耕内存领域的团队经验,在颗粒筛选与调校上更偏向高频与稳定性的平衡,采用海力士A-die原厂颗粒,并支持XMP与EXPO一键加载高性能参数,同时在散热设计上使用铝合金马甲配合导热结构,有助于在高负载运行环境中维持稳定表现,在实际的大模型推理与任务执行场景中,也更容易提供持续且可靠的运行支撑。
从这次测试结果来看,在本地部署AI模型的使用场景中,内存的作用已经不只是基础配置。在显存充足时,它对推理性能的影响相对有限;但在显存受限、需要依赖内存参与加载的情况下,内存容量会直接影响模型能否正常运行以及整体的稳定性表现,也在一定程度上决定了可尝试的模型规模范围。

感谢本次新乐士借测的内存条,有需要的可以看看:
京东新乐士官方旗舰店618专属福利抢先看,手把手教你薅尽优惠:低至5折限时秒杀,进店先领店铺专属优惠券满199-20元,满599-50元,再叠加店铺满1999减100元、多重优惠可同时使用,晒单更有10元京东E卡相赠;全程支持7天价保,不用担心买贵,放心入手无顾虑,还有京东官方正品保障,售后无忧,发货速度拉满,让你快速解锁装机新体验。


更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















