兄弟們,前段時候OpenClaw 確實挺火,它不只是能聊天,還能幫我們讀文件、整理資料、執行任務,用起來確實挺有意思。
且除了使用雲端模型外,本地部署模型玩一玩也是可以的。
比如用 Ollama 或者 LM Studio 在本地跑大模型,再讓 OpenClaw 調用它們,既能省下部分 Token 成本,也能把模型和數據留在自己電腦上。

不過我感覺好像說起本地部署AI大模型基本上都在強調顯存,但針對系統內存,好像很少有人認真測試過。我就有個疑問,內存對模型運行影響有多大?是提升速度還是決定能不能跑?顯存不夠時,內存會不會成爲決定模型上線的關鍵?
爲了這次測試,我準備了 6 組不同容量的新樂士屠龍勇士 DDR5 6000 CL28 內存,容量覆蓋 16GB 至 128GB,總價值超過 27000 元。該系列採用海力士 A-die 原廠顆粒,主打高頻、低時序與穩定表現,適合用於本地 AI、多任務與高負載場景測試。

本次測試儘量控制其他變量,僅調整內存容量。除內存容量外,測試平臺、軟件環境、模型版本和測試問題均保持一致。本地部署工具使用 LM Studio,測試模型分別爲 Qwen3.5-9B 和 Qwen3.5-27B。

測試平臺:
cpu爲ultra7 265k
GPU爲9070xt 16GB
主板爲微星Z890刀鋒鈦
內存條爲新樂士屠龍勇士6000CL28 A-die

準備了兩個測試內容:
一個是針對LM Studio的問題:
假設你的抽屜裏有 12 只紅色襪子、8 只藍色襪子和 6 只白色襪子。房間裏一片漆黑,你看不見顏色。
請分步計算:你最少需要拿出多少隻襪子,才能百分之百保證湊出一雙“同色”的襪子?
如果要保證湊出“三隻顏色相同”的襪子,邏輯又是怎樣的?
請詳細推導過程,並給出最終答案。
另一個是讓open claw執行實操任務
讀取我桌面的會議記錄,並寫一篇會議內容總結放在我桌面的辦公文件夾中
測試項目:
1.內存佔用/GB
2.回覆問題總耗時/s
3.輸出速度多少token/s
4.openclaw執行任務總耗時/s

下面測試開始,首先上場的模型是千問3.5 9B,我們先測試 OpenClaw 執行任務的速度。內存容量:
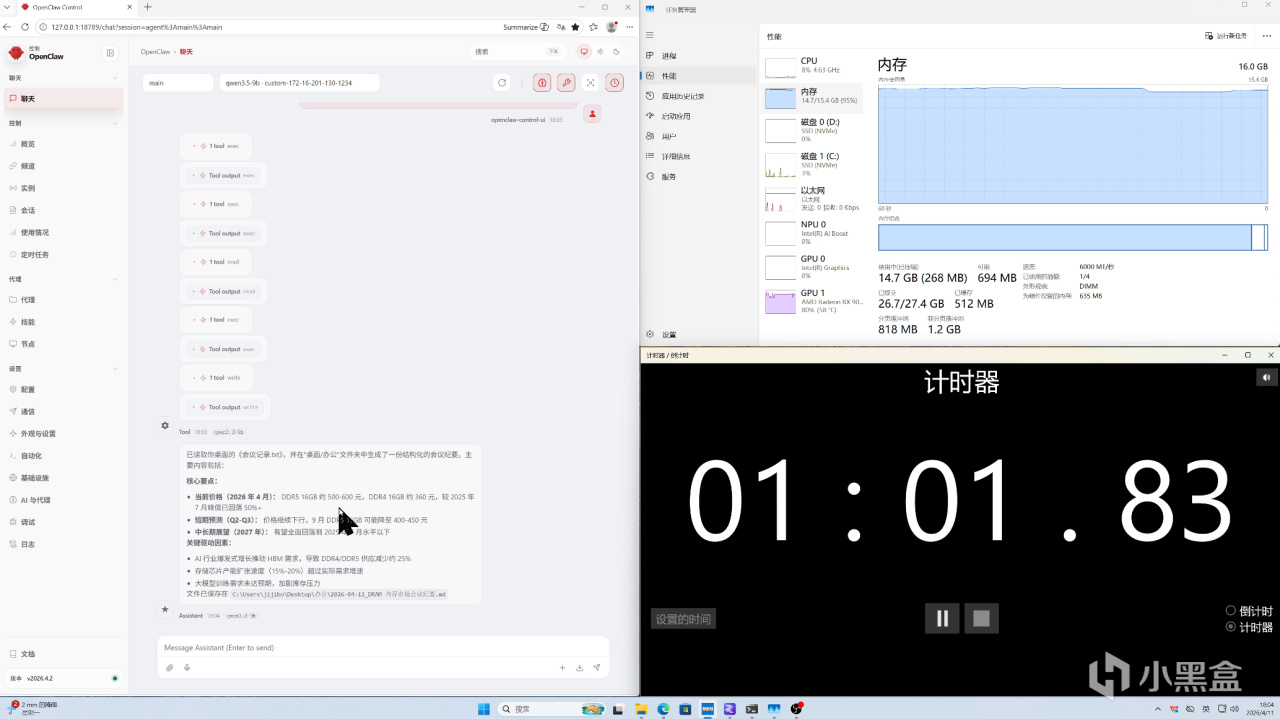
【16GB】
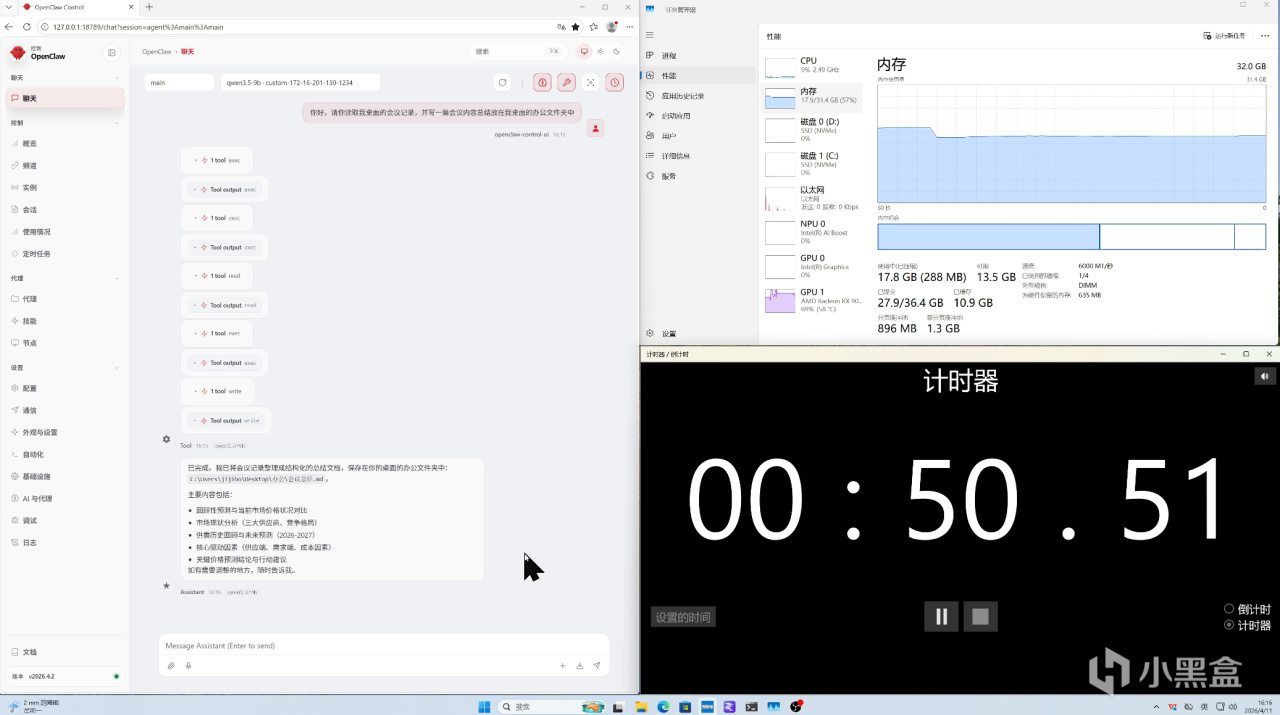
【32GB】
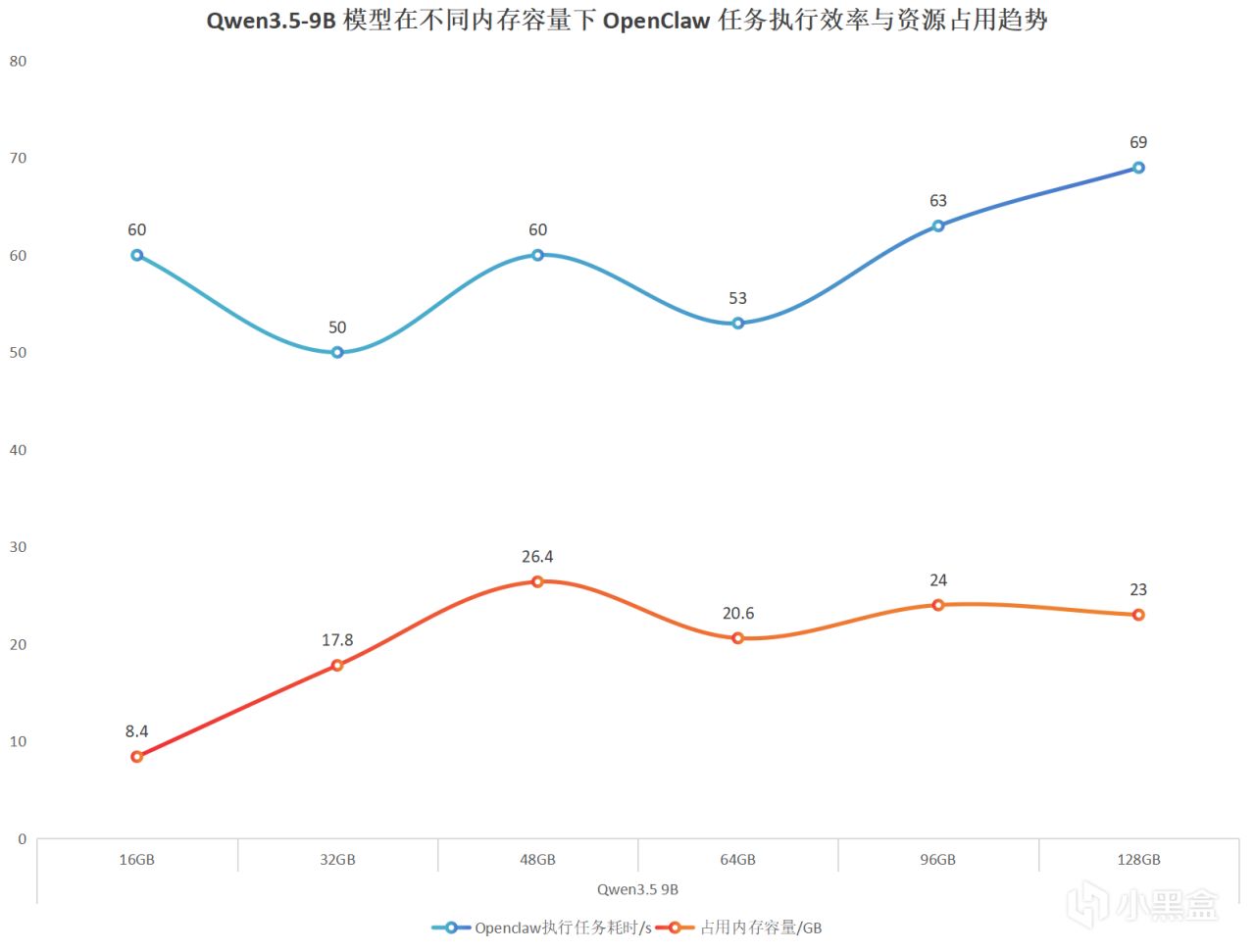
從測試結果來看,在顯存充足的前提下,Qwen3.5-9B 執行 OpenClaw 任務的耗時並沒有隨着內存容量增加而持續下降。整體來看,任務耗時呈現波動變化,而不是“內存越大,推理越快”的線性趨勢。但更大容量的內存,在實際使用中會提供更充足的系統餘量。比如在運行 OpenClaw 的同時,瀏覽網頁、打開其他軟件等多任務操作,整體使用體驗會更加從容。
下面我們來看看 LM Studio 的表現,
【16GB】
【32GB】
【48GB】
【64GB】
【96GB】
【128GB】
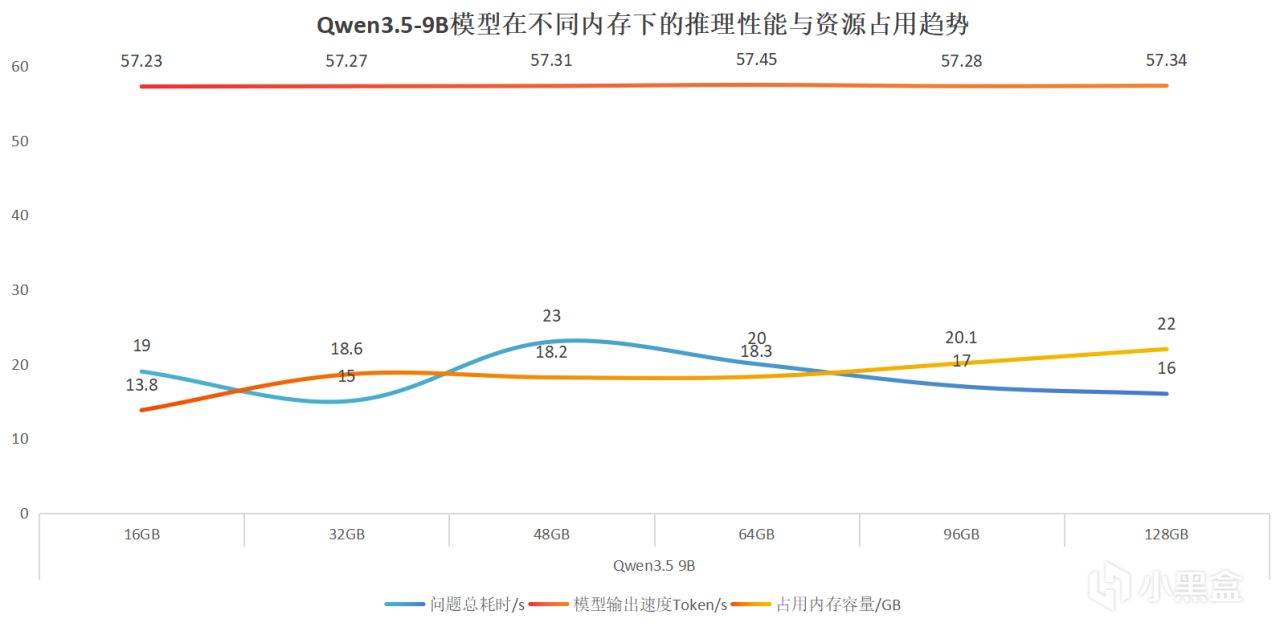
我們彙總數據可以看出,輸出速度基本穩定在57token每秒左右,波動很小,問題總耗時也沒有隨着內存增加而明顯下降。所以在顯存充足的情況下,即便提升內存容量,推理速度也沒有出現明顯的線性提升,整體差異相對有限。
那麼顯存不夠的情況下?當然,模型會部分加載至內存,也就是顯存加內存協同。

時候內存容量越大,能嘗試的模型上限就越高。爲了量化不同內存容量對該極限場景性能的影響,我們還是來測一測。

依舊先看看龍蝦的表現。
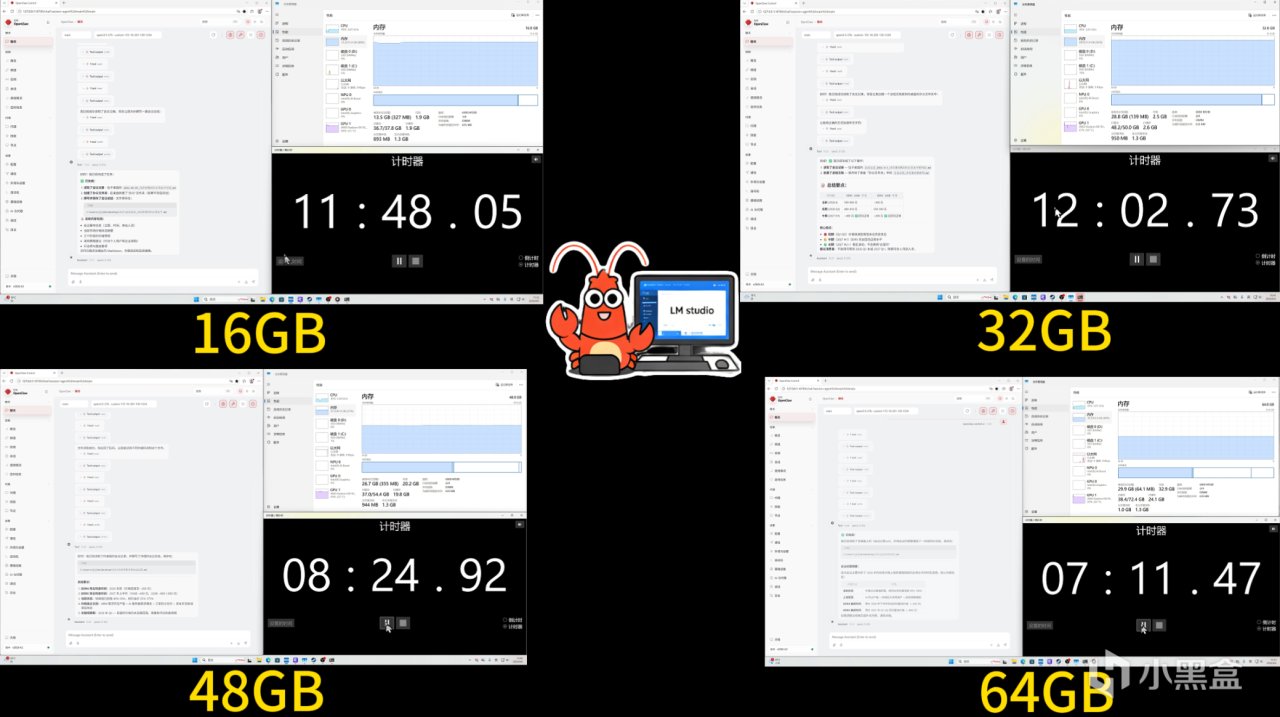
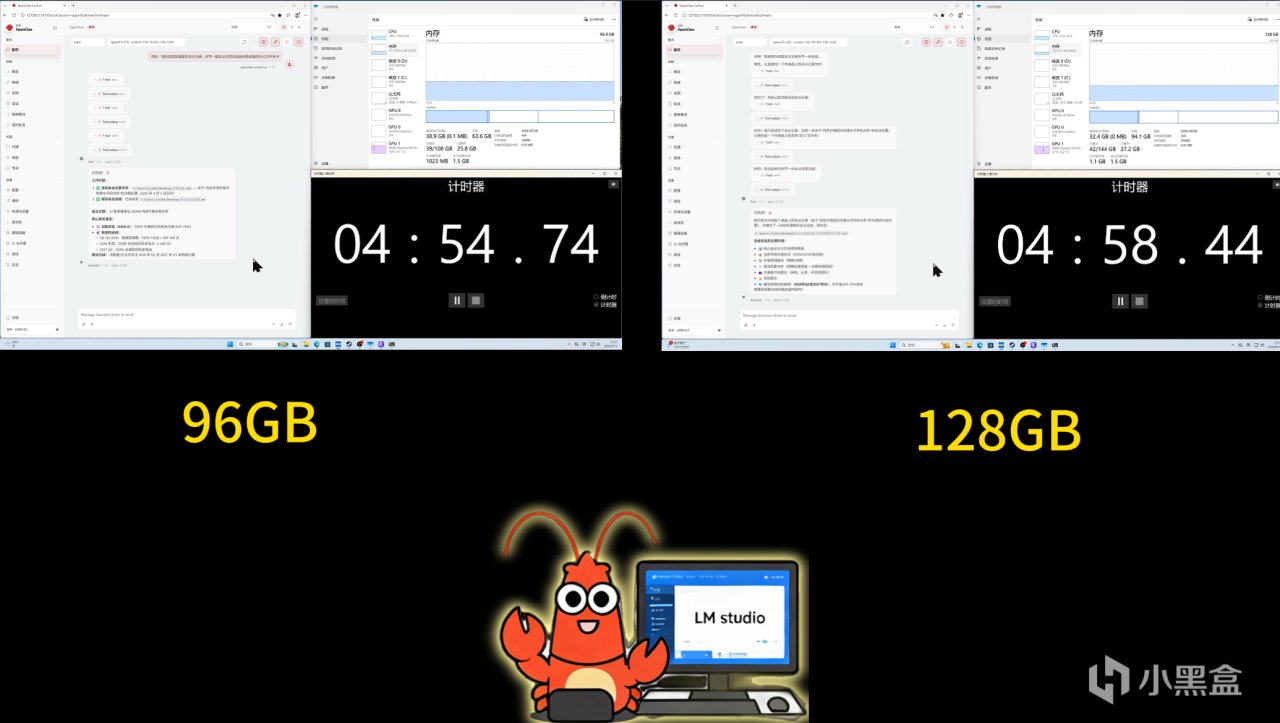
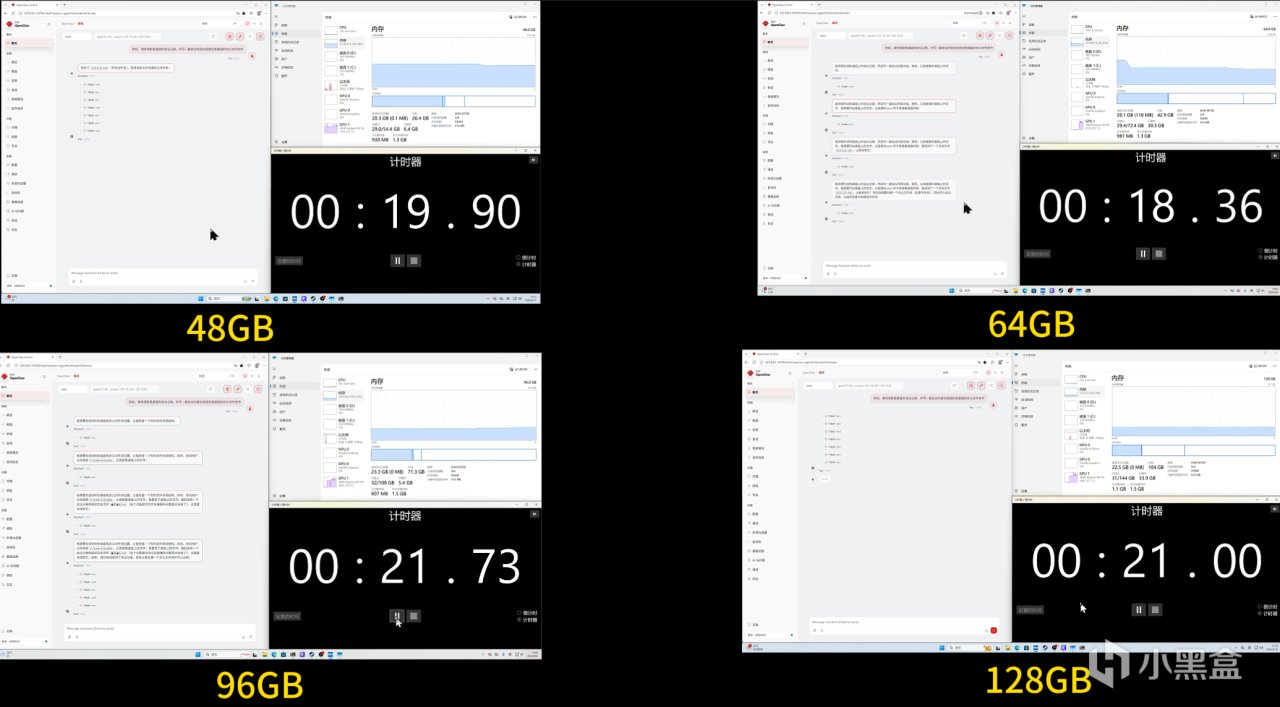
在千問27B這個場景下,由於模型規模已經超過顯存容量,系統需要依賴內存參與運行。這時候不同內存容量之間的差異就非常明顯了。
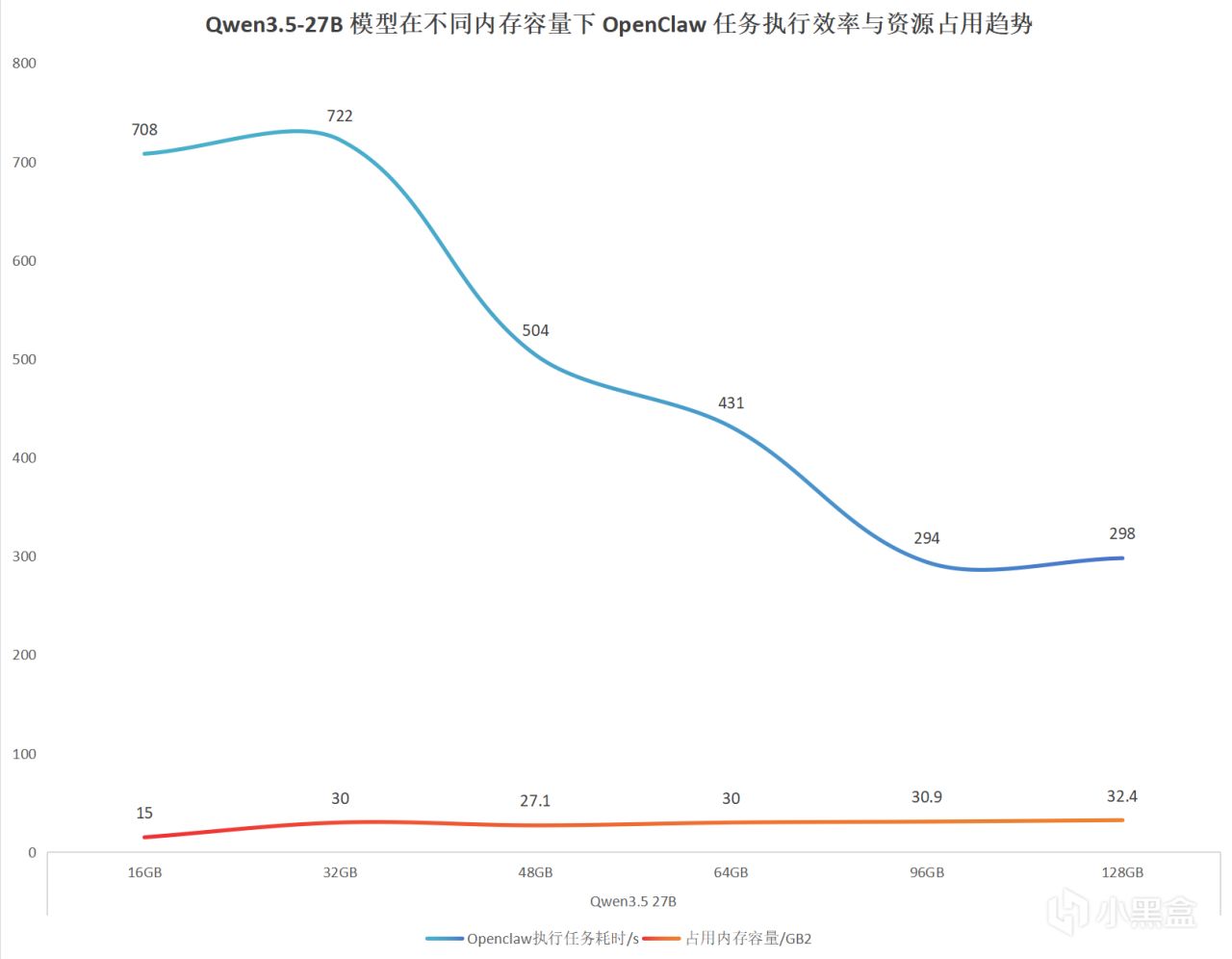
可以看到在16GB和32GB配置下,任務執行時間分別達到了708秒和722秒,整體表現較差,已經明顯受到內存容量限制,進入了資源瓶頸區間。提升到48 GB 之後,總耗時下降到了504秒,得到了明顯的改善。一直增加到後面的96 GB 都有很明顯的提升。但到了128 GB 耗時反而和96 GB 差不多,可以看出性能已經進入相對穩定區間。
那 LM Studio呢?
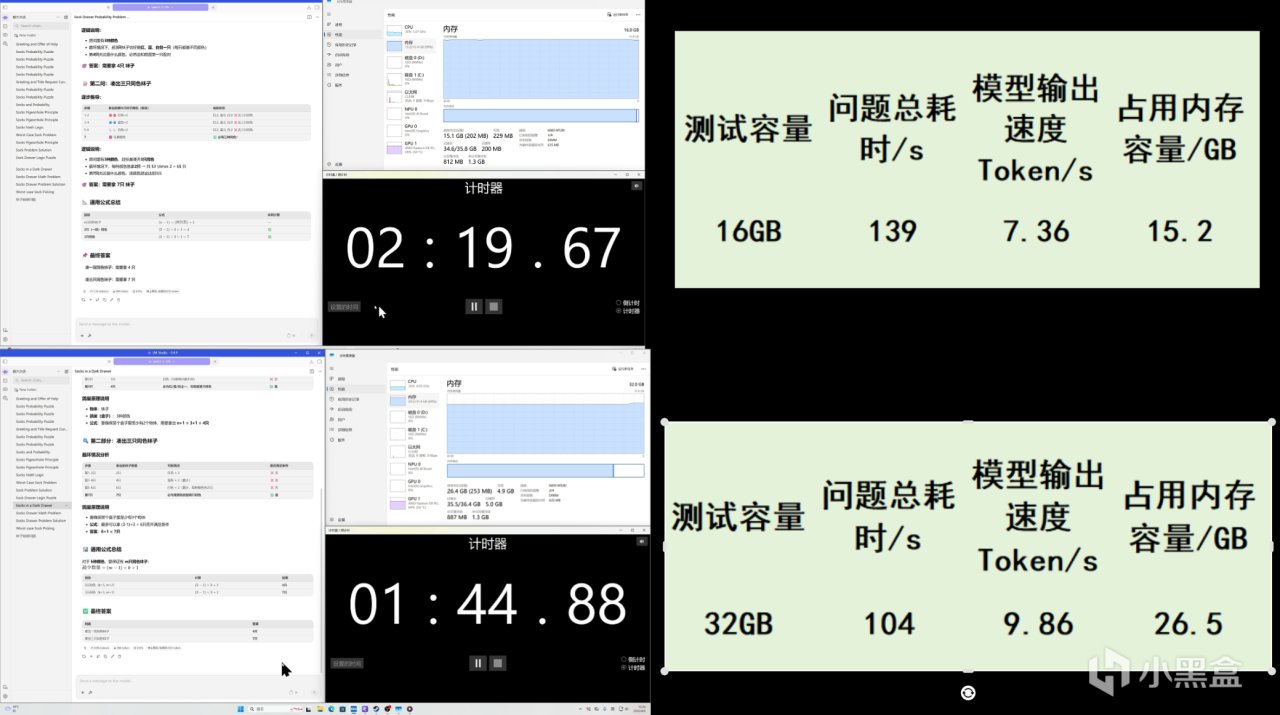
彙總數據我們可以看出,
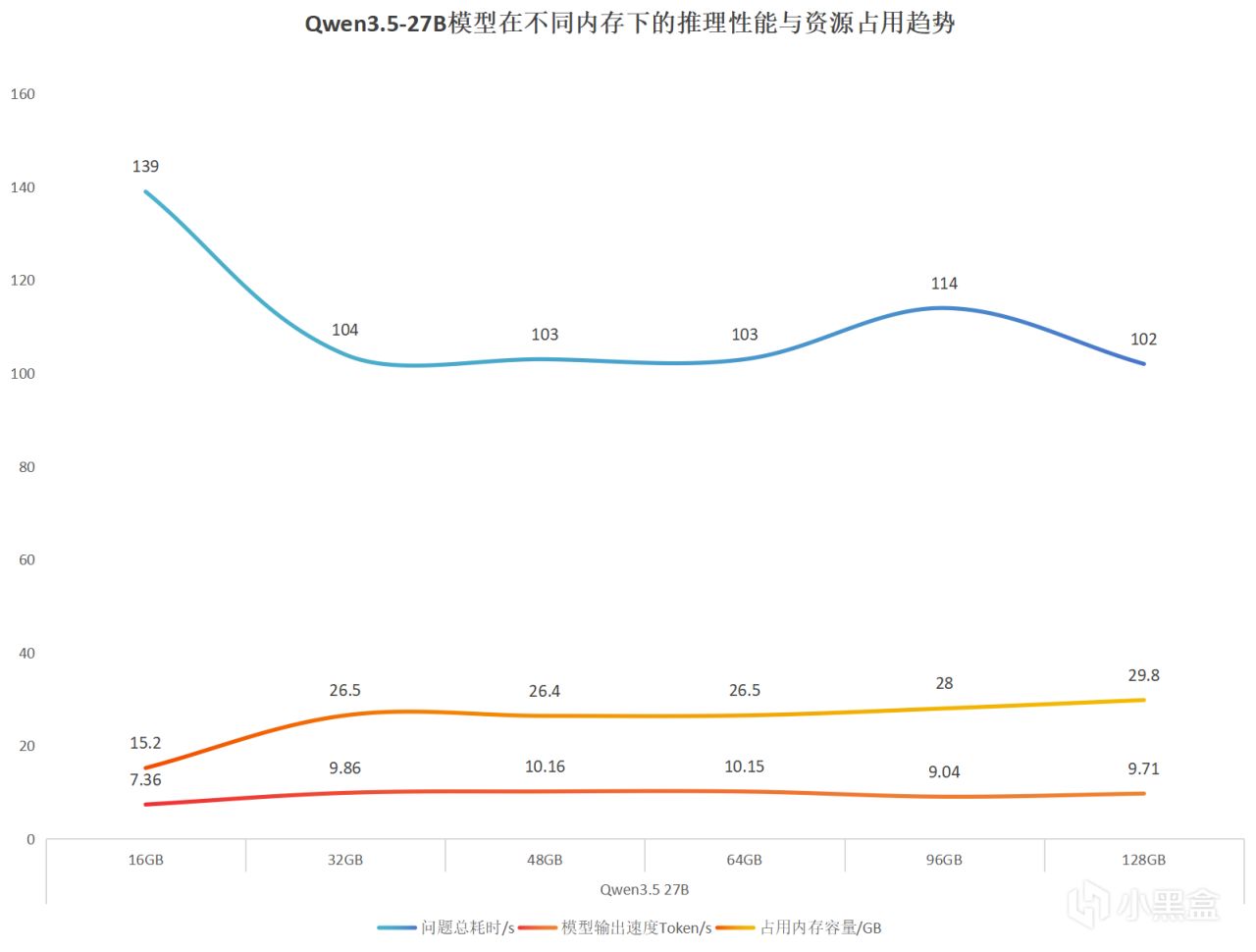
在16GB 容量下,會因模型內存需求不足導致性能嚴重下降。不過從32GB 開始,性能基本進入穩定區間。在網上提升容量對推理速度的幫助已經不明顯了。
測試表明,如果只是運行中小規模模型,並且顯存足夠,那麼內存容量滿足基礎需求即可,對推理性能的影響相對有限;但如果你希望在本地環境中嘗試更大參數規模的模型,尤其是在顯存只有8GB、12GB或16GB的情況下,內存容量就會成爲一個更加關鍵的變量,合理提升內存配置可以在一定程度上提高模型的加載成功率,改善運行過程中的穩定性,同時拓寬可運行模型的規模範圍;而在預算相對充足的前提下,在顯卡顯存之外搭配更大容量、性能表現更均衡的內存配置,也能夠爲本地AI部署提供更充足的資源空間,在面對更大模型或複雜任務時帶來更加從容和穩定的整體使用體驗;

例如本次測試所使用的SAMNIX新樂士屠龍勇士內存條,新樂士團隊基於長期深耕內存領域的團隊經驗,在顆粒篩選與調校上更偏向高頻與穩定性的平衡,採用海力士A-die原廠顆粒,並支持XMP與EXPO一鍵加載高性能參數,同時在散熱設計上使用鋁合金馬甲配合導熱結構,有助於在高負載運行環境中維持穩定表現,在實際的大模型推理與任務執行場景中,也更容易提供持續且可靠的運行支撐。
從這次測試結果來看,在本地部署AI模型的使用場景中,內存的作用已經不只是基礎配置。在顯存充足時,它對推理性能的影響相對有限;但在顯存受限、需要依賴內存參與加載的情況下,內存容量會直接影響模型能否正常運行以及整體的穩定性表現,也在一定程度上決定了可嘗試的模型規模範圍。

感謝本次新樂士借測的內存條,有需要的可以看看:
京東新樂士官方旗艦店618專屬福利搶先看,手把手教你薅盡優惠:低至5折限時秒殺,進店先領店鋪專屬優惠券滿199-20元,滿599-50元,再疊加店鋪滿1999減100元、多重優惠可同時使用,曬單更有10元京東E卡相贈;全程支持7天價保,不用擔心買貴,放心入手無顧慮,還有京東官方正品保障,售後無憂,發貨速度拉滿,讓你快速解鎖裝機新體驗。


更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















