大家好,我是飘雷。
有不少朋友和我一样,平时会在网上疯狂囤积各种电子书或干货文档,沉浸在下载了就等于学了的错觉中。
不过虽然获取信息的渠道和方式增多了,但吸收信息的效率毕竟还是有限,面对动辄几百页的长篇书籍,光是翻开目录就让人有些望而生畏,想要快速抓取核心知识点更是难上加难。
那有没有办法能提高我们的阅读和知识吸收效率呢?
有的兄弟,有的。
今天咱们就来看看如何在NAS上部署一款堪称读书神器的GitHub开源项目——ebook-to-mindmap。
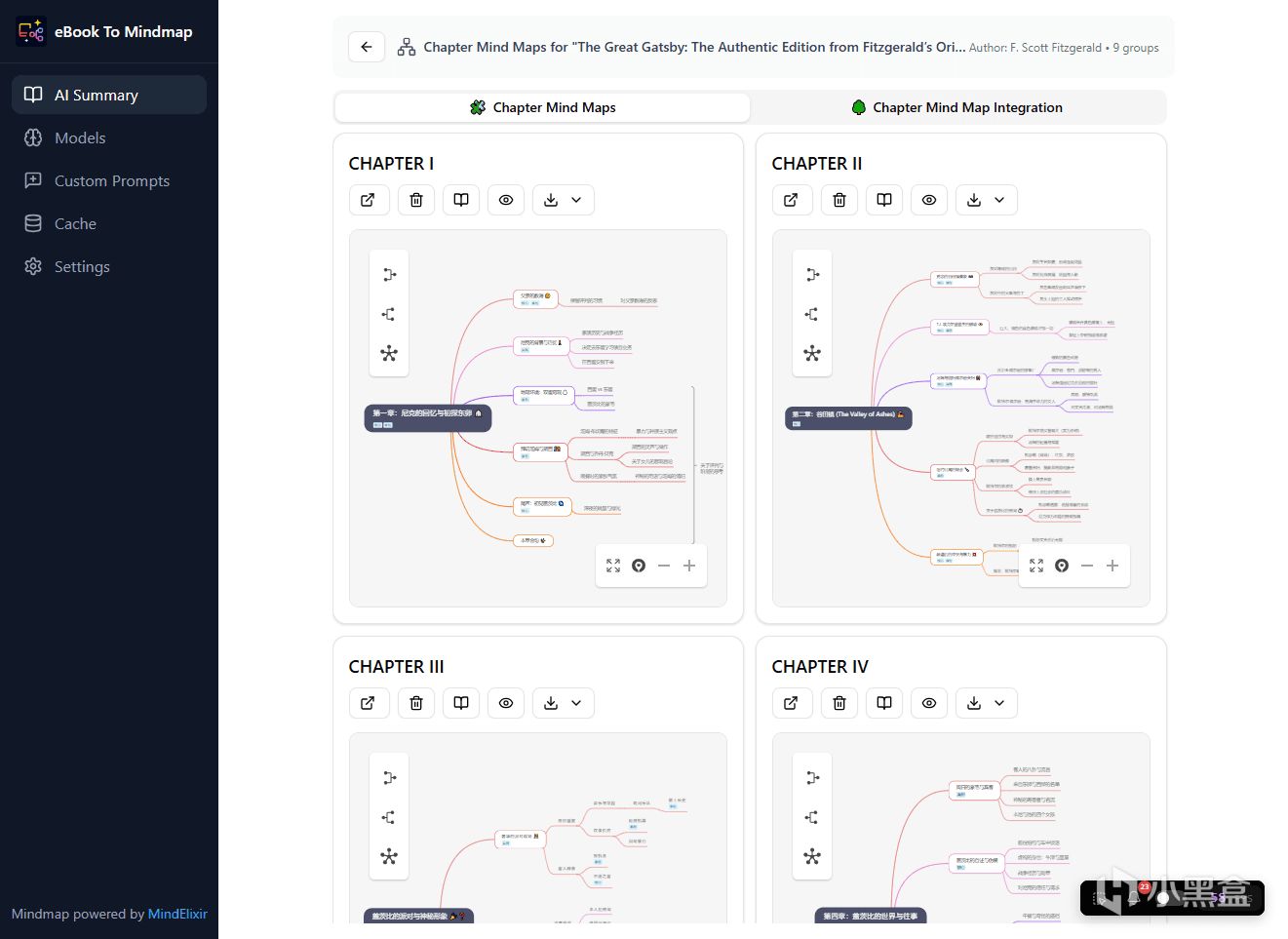
通过它,我们可以直接把电子书扔进去,利用AI大模型的力量,一键将晦涩冗长的书籍拆解成直观的思维导图和精炼的文字总结,让AI先替你把书给啃一遍。
废话不多说,我们直接进入正题。
一、什么是ebook-to-mindmap?
ebook-to-mindmap是由国内开发者SSShooter开发的一款基于AI技术的智能电子书解析工具。
它的核心功能就是提取PDF和EPUB电子书里的内容,交由AI大模型进行深度阅读和归纳,最终输出高度结构化的思维导图和文字总结。
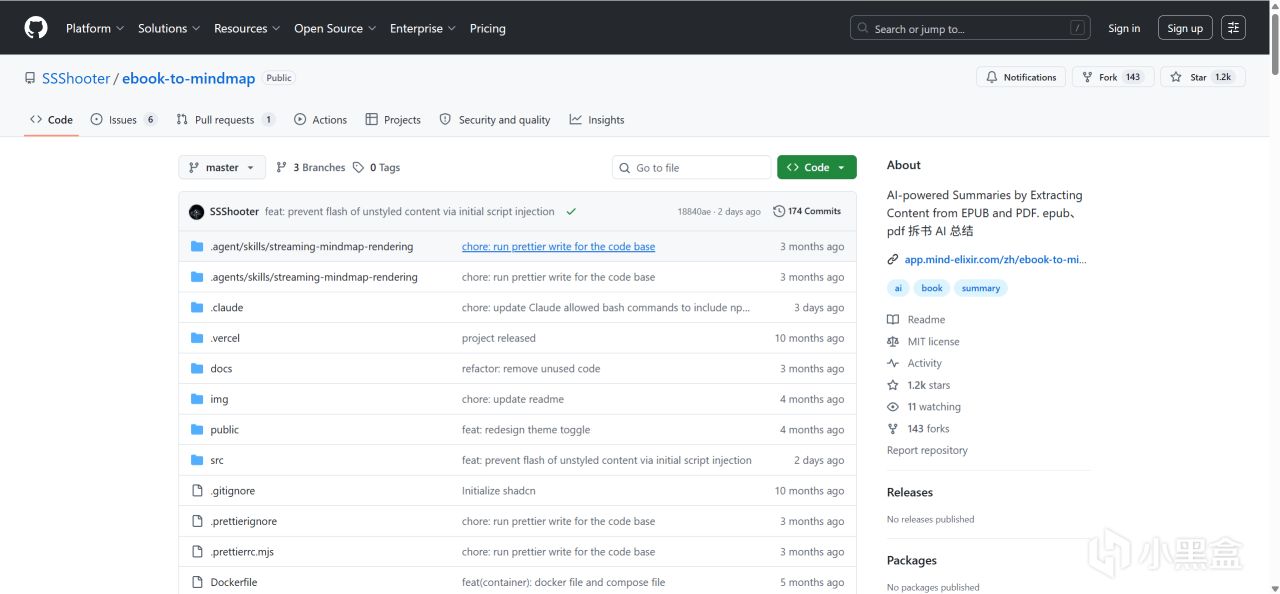
这款工具不仅采用了颜值非常高的UI设计,而且功能直击囤书党的痛点。
它支持接入DeepSeek、Google Gemini、OpenAI GPT等主流大模型,并且如果你的书字数较多,可以使用Gemini这种支持超长上下文的模型。
更关键的是,在解析电子书时,所有的AI请求都是从你的浏览器本地直接连接AI供应商的接口,不会经过任何第三方代理或中转服务器,最大程度地保护了你的个人隐私和数据安全。
此外它还有文字总结、章节思维导图、整书思维导图三大硬核处理模式,满足不同的场景需求,生成好的导图还可以随时离线查看。
就算在解析中途不小心关掉网页,它的智能缓存机制能让你下次直接从上次的位置继续处理,
如果你不满足于默认的总结方式,还能添加自定义提示词(Prompt),让AI以特定的口吻或侧重点来为你提炼知识点。
对于重度阅读爱好者和需要经常拆书的小说作者来说,将这款工具部署在自家的NAS上,就可以随时随地打开网页就能给电子书做AI深度拆解。
接下来,就让我一步步教大家如何在威联通NAS上部署这款神器吧!
二、部署流程
这里我们来展示如何在威联通NAS上使用Docker形式部署ebook-to-mindmap,用到的设备是威联通最新的8盘位旗舰新品Qu805。
由于目前项目作者还没有发布现成的Docker镜像,所以我们没法直接使用拉取镜像,需要利用NAS在本地自己构建(Build)一下进行部署。不过不用慌,操作过程也同样简单。
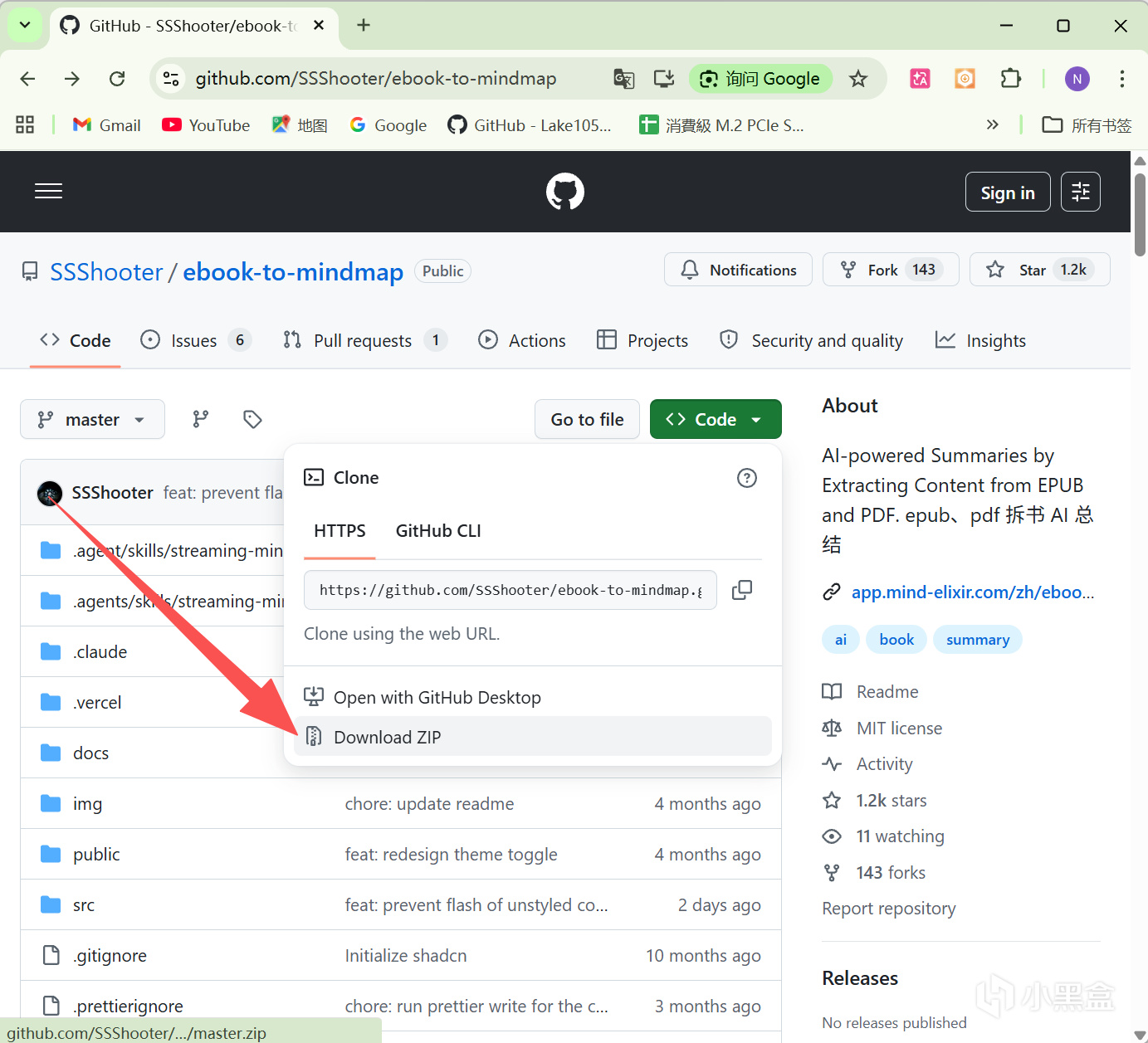
如图所示,我们需要先去GitHub下载打包后的项目文件ZIP压缩包,解压缩后能看到ebook-to-mindmap-master这个文件夹:
接下来将ebook-to-mindmap-master文件夹上传到NAS,同时为了简洁点儿,咱们可以选择修改一下文件夹名,比如这里我使用的地址是/share/Container/ebook-to-mindmap
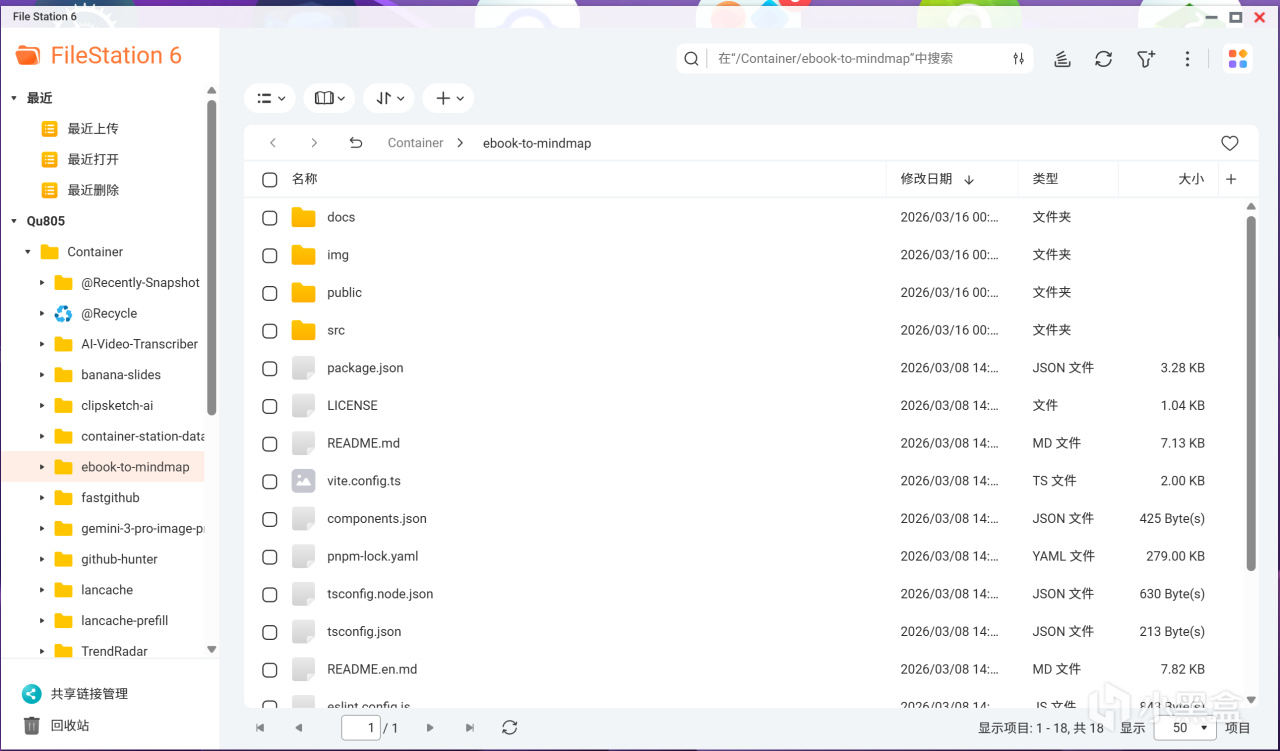
为了照顾不习惯使用SSH的朋友,接下来我们使用docker compose代码的方式直接部署。
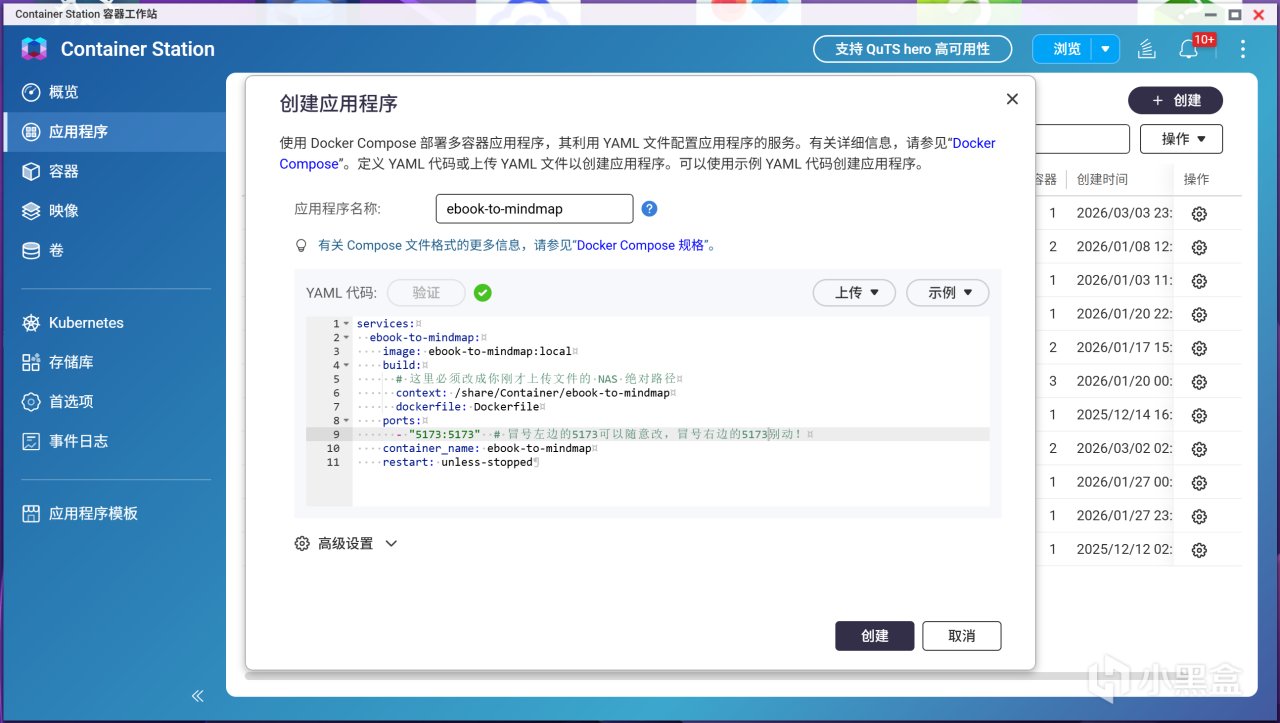
打开威联通 Container Station,点击左侧的「应用程序」,然后点击右侧黑色「创建」按钮,输入以下代码:
services:
ebook-to-mindmap:
image: ebook-to-mindmap:local
build:
# context这里必须改成你刚才上传文件的 NAS 绝对路径
context: /share/Container/ebook-to-mindmap
dockerfile: Dockerfile
ports:
- "5173:5173" # 冒号左边的5173可以随意改,冒号右边的5173别动!
container_name: ebook-to-mindmap
restart: unless-stopped
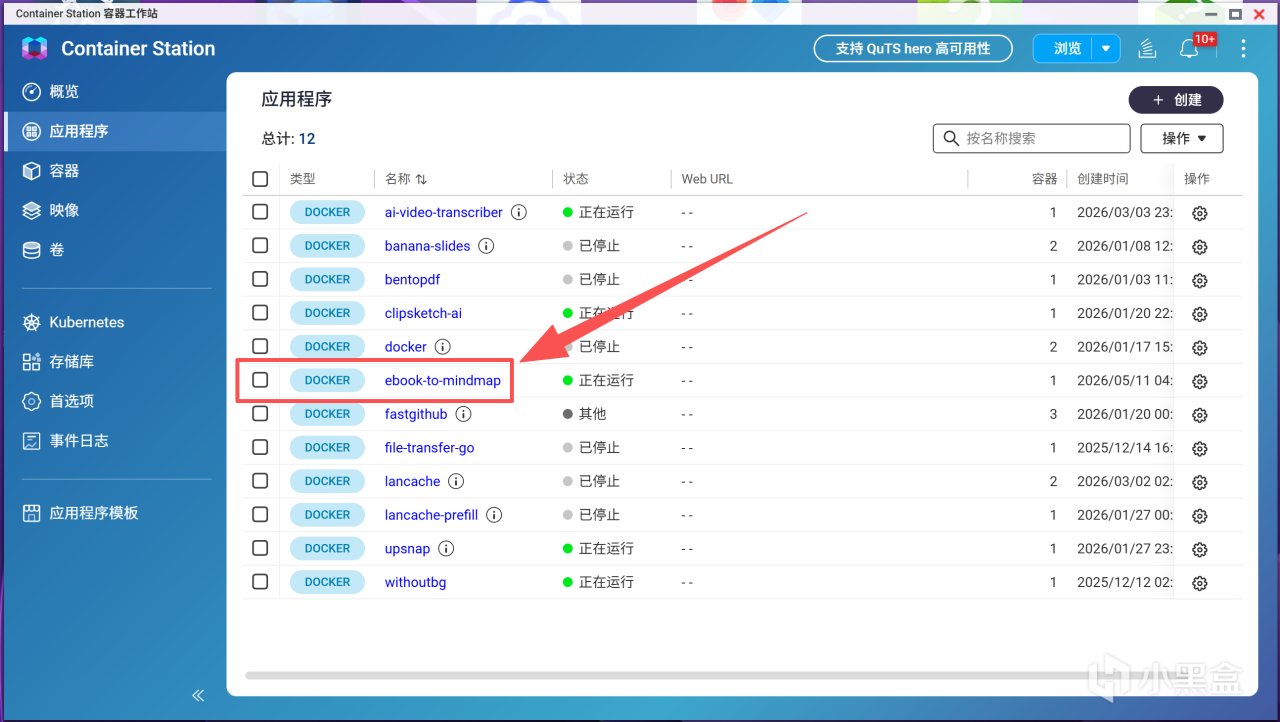
此时可以在Container Station中看到正在运行的容器:
三、使用方法
1.相关配置
ebook-to-mindmap部署完成后,我们只要在PC或者手机浏览器中输入 http://<NAS IP>:<端口号>,比如http://192.168.10.70:5173,就可以直接访问项目页面了。
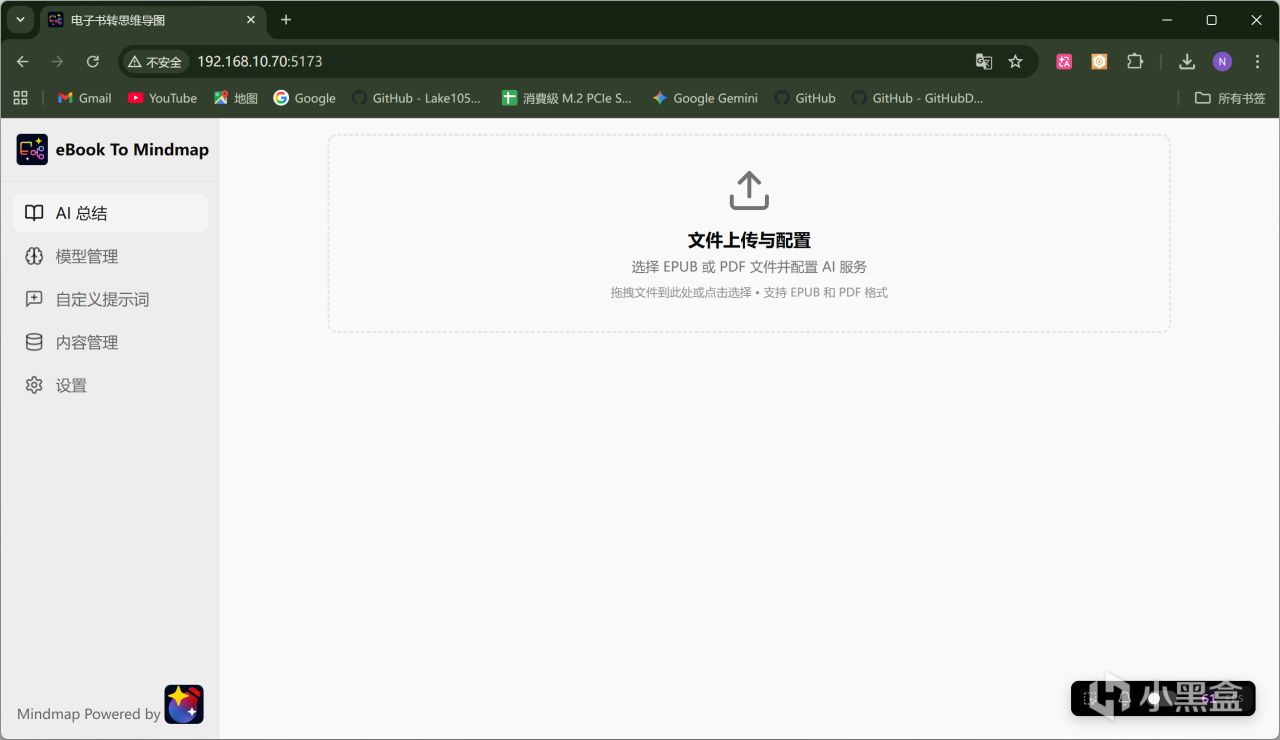
在正式使用前,我们首先需要设置使用的AI模型,依次点击「模型管理」——「添加模型」:
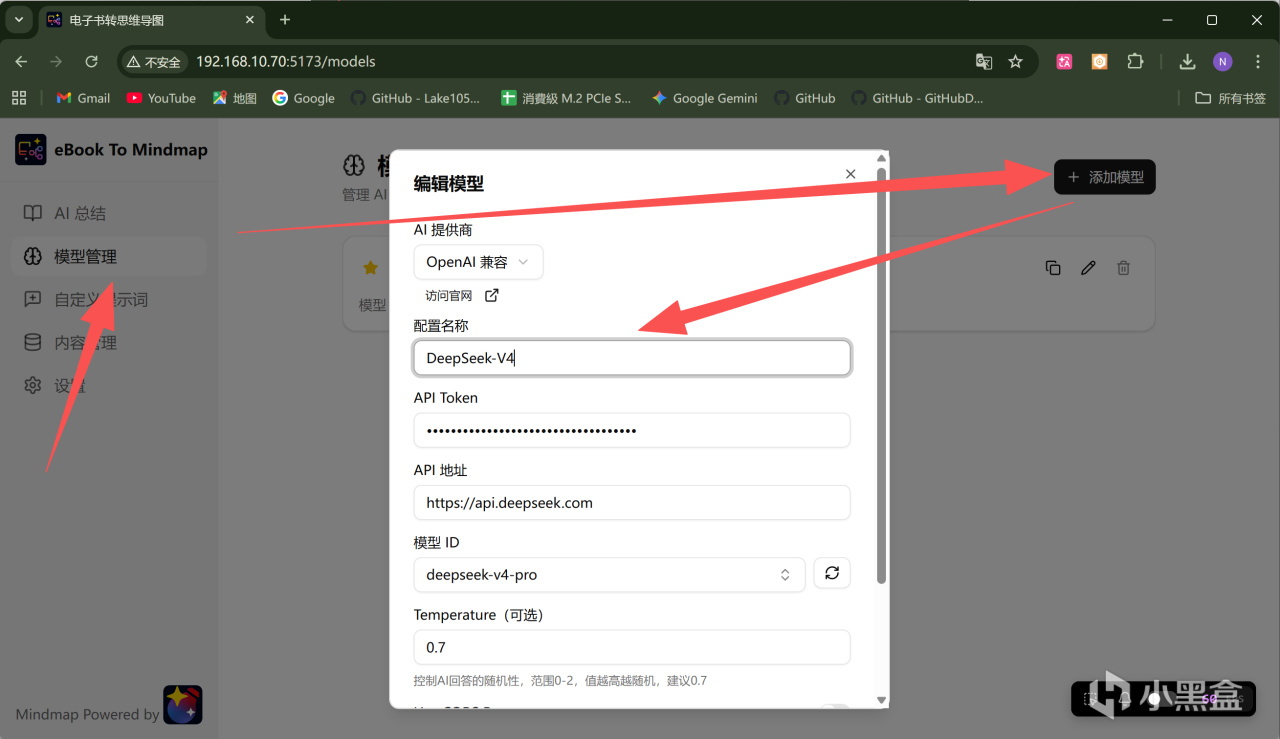
在AI提供商这里,可以选择Google、OpenAI等官方算力提供商,也可以选择Ollama等本地算力。这里我准备使用最新的DeepSeek V4模型,所以选择了OpenAI 兼容模式。
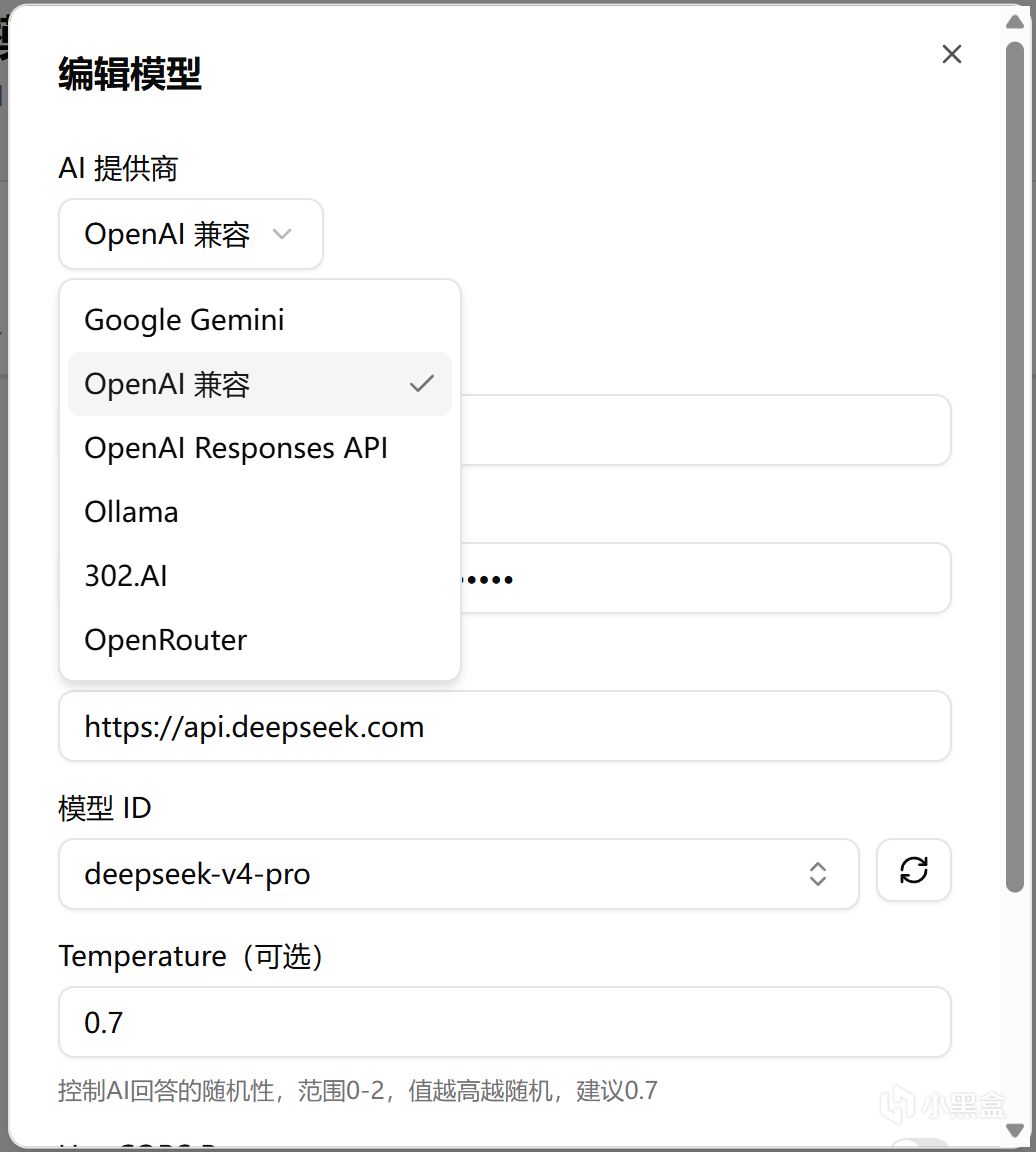
然后按照下图中的注释,配置名称可以自己随便写,API Token、API地址和模型ID,需要根据你的算力提供商的调用文档来填。
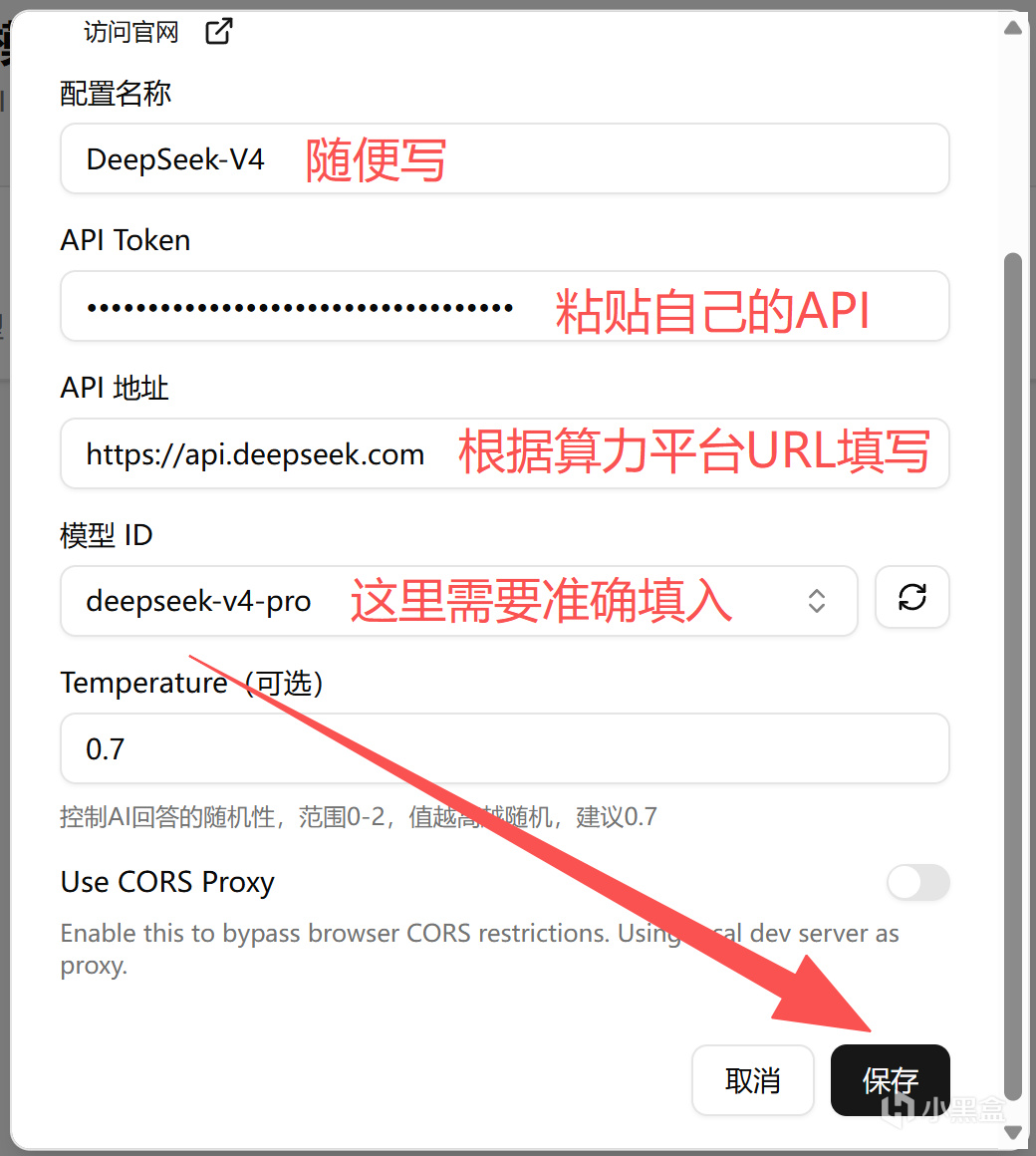
我自己是使用了DeepSeek官方URL,同时模型使用了最新的deepseek-v4-pro模型,设置完成后别忘了点击保存。
接下来我们在看看其他的设置选项,点击左侧的「设置」,可以配置界面语言、主题颜色和输出语言等等:
继续往下拉,在「处理模式」一栏,需要特别注意一下,项目作者提供了3个选项。
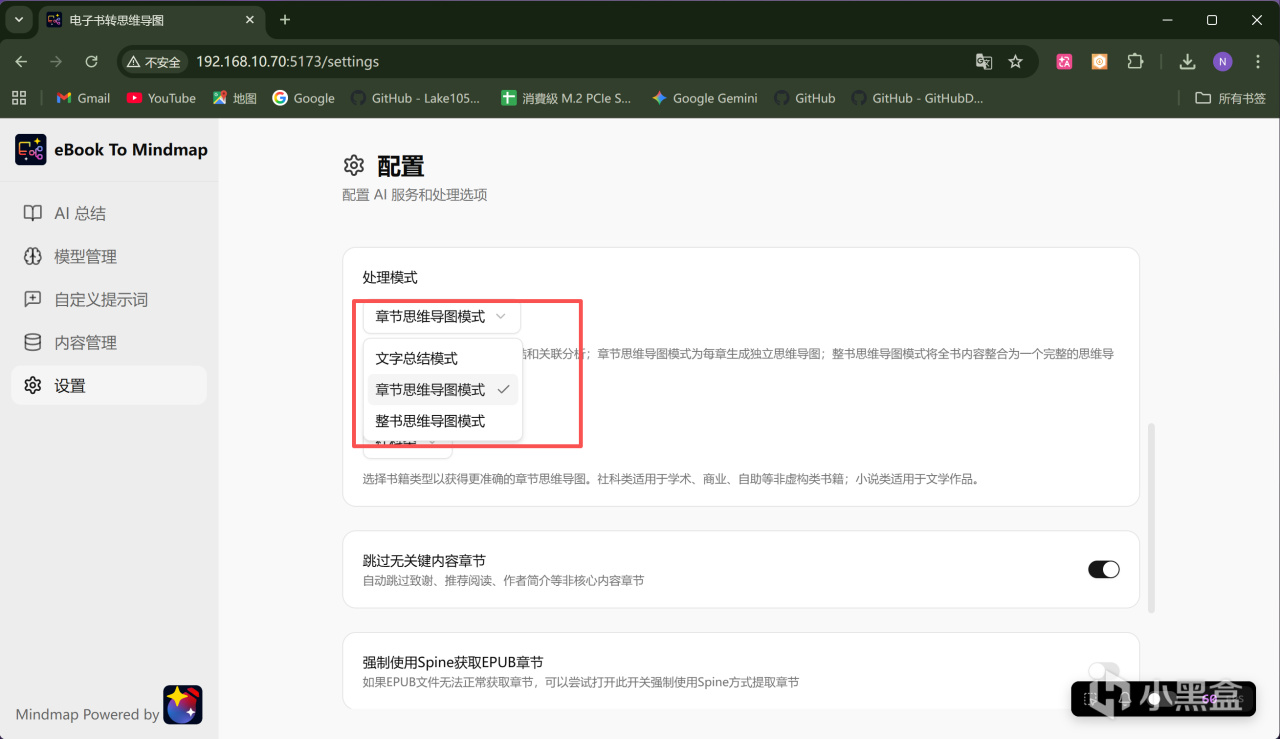
文字总结模式适合需要文字总结的场景,可以生成章节总结、分析章节关联、输出全书总结;
章节思维导图模式可以为每个章节生成独立的思维导图;
整书思维导图模式可以将整本书内容整合为一个完整的思维导图,但由于AI模型的上下文长度有限制,所以像几百万字的小说这种太长的内容可能会生成失败。
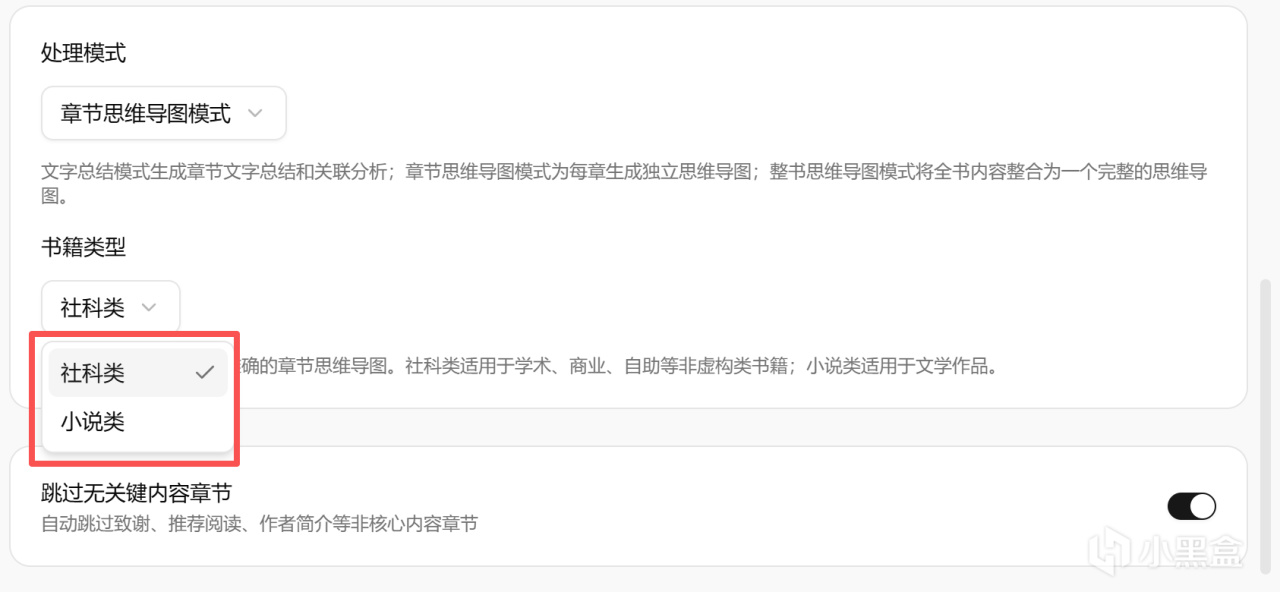
在书籍类型方面,也分为了小说类和正常社科类,可以根据实际场景来灵活选择:
2.使用演示
我们回到首页,点击「选择 EPUB 或 PDF 文件」按钮,然后上传需要处理的电子书文件:
比如我上传了一份2024年卫健委发布的《成人肥胖食养指南》PDF文件,可以看到会自动识别出文件中的各个章节,然后点击「开始解析」即可:
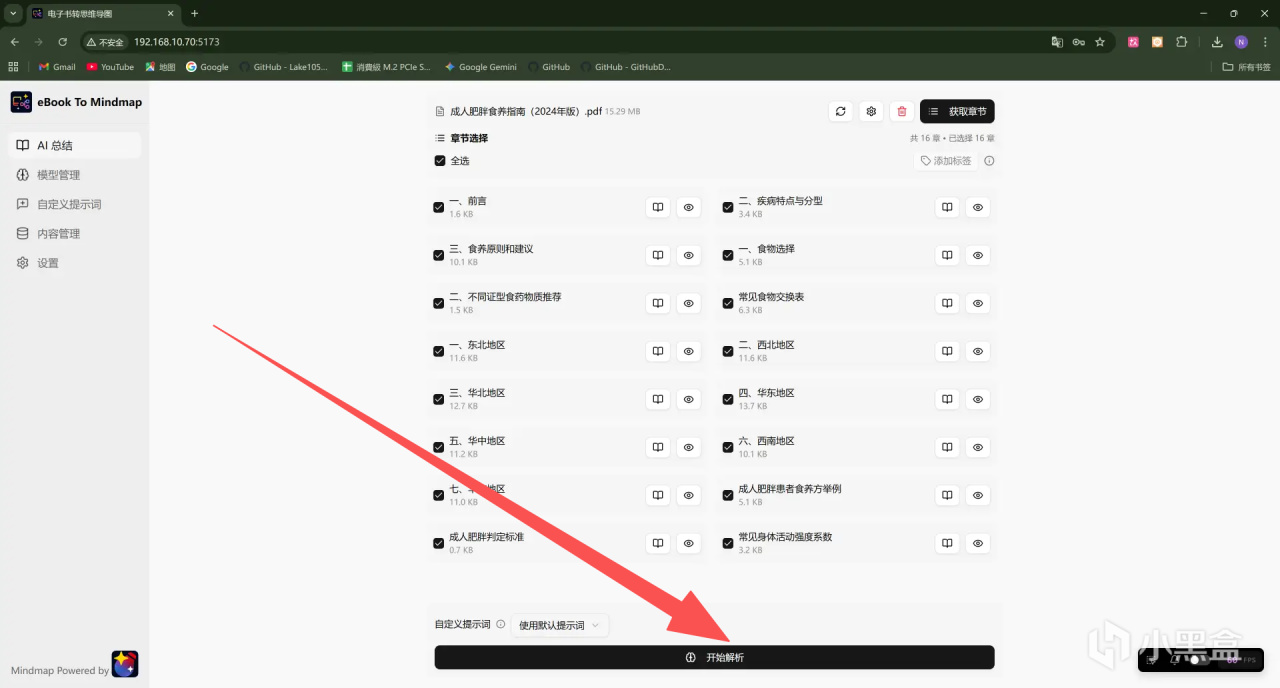
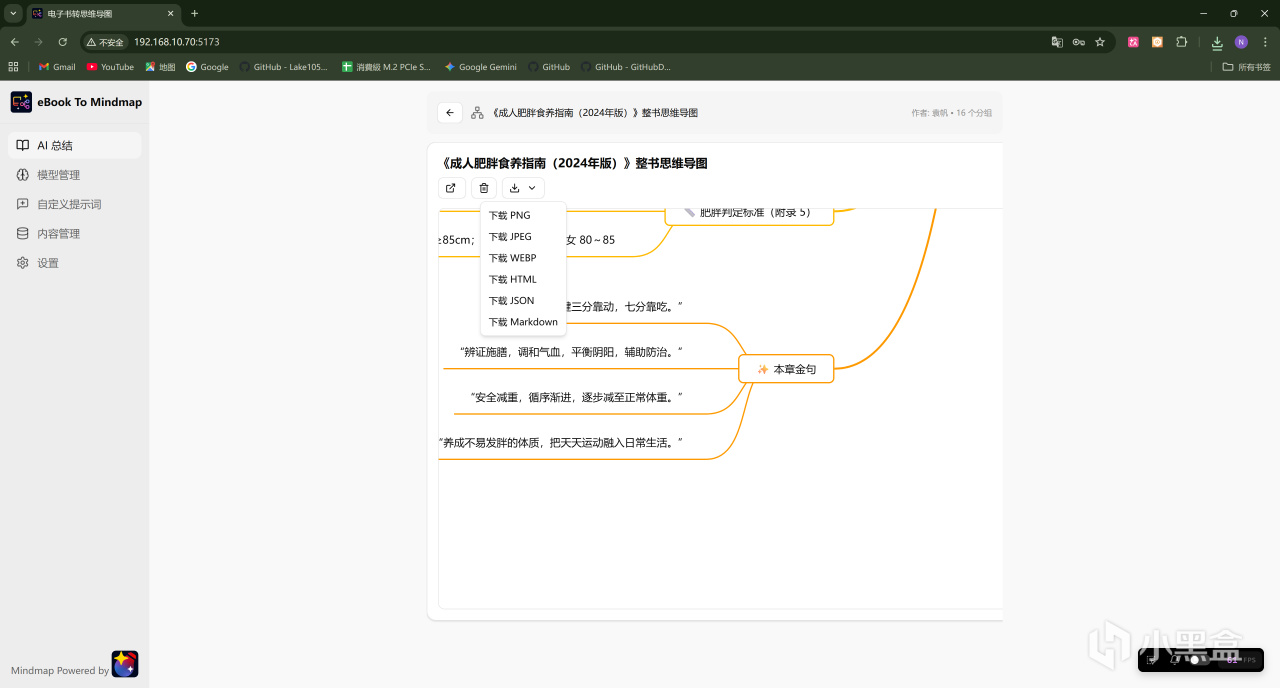
由于这份文件的字数不算太多,DeepSeek-V4一百万的上下文长度足够一次性解析,所以首先选择了整书模式试试,稍等一会儿解析完成后即可呈现全文的整体思维导图框架,并且可以下载成图片或者HTML、Markdown文件等格式:
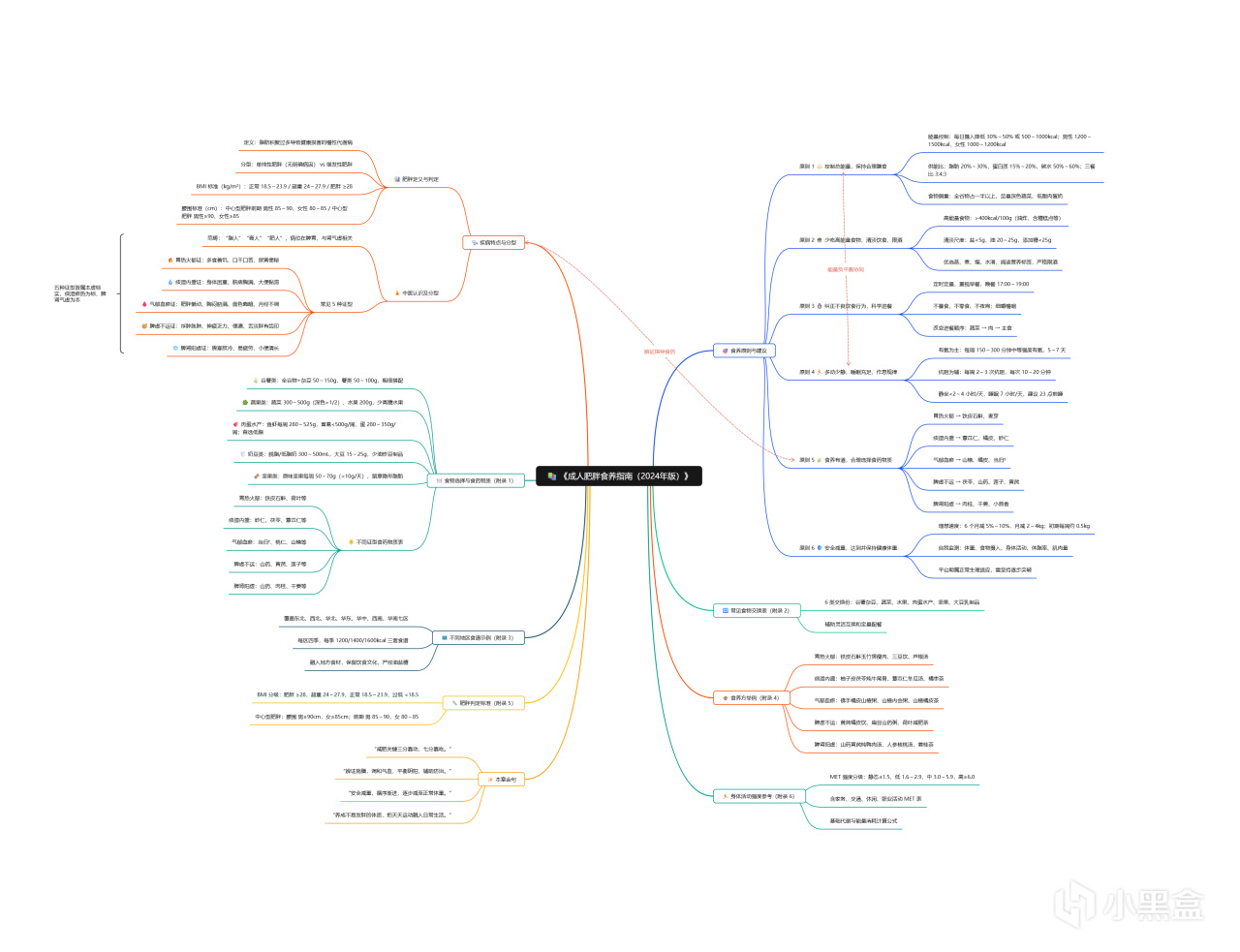
看看整体的思维导图的效果,还是挺不错的:
同时针对字数超过AI模型上下文限制的文档,我们可以选择章节思维导图模式来解析,每一章都会有单独的思维导图:
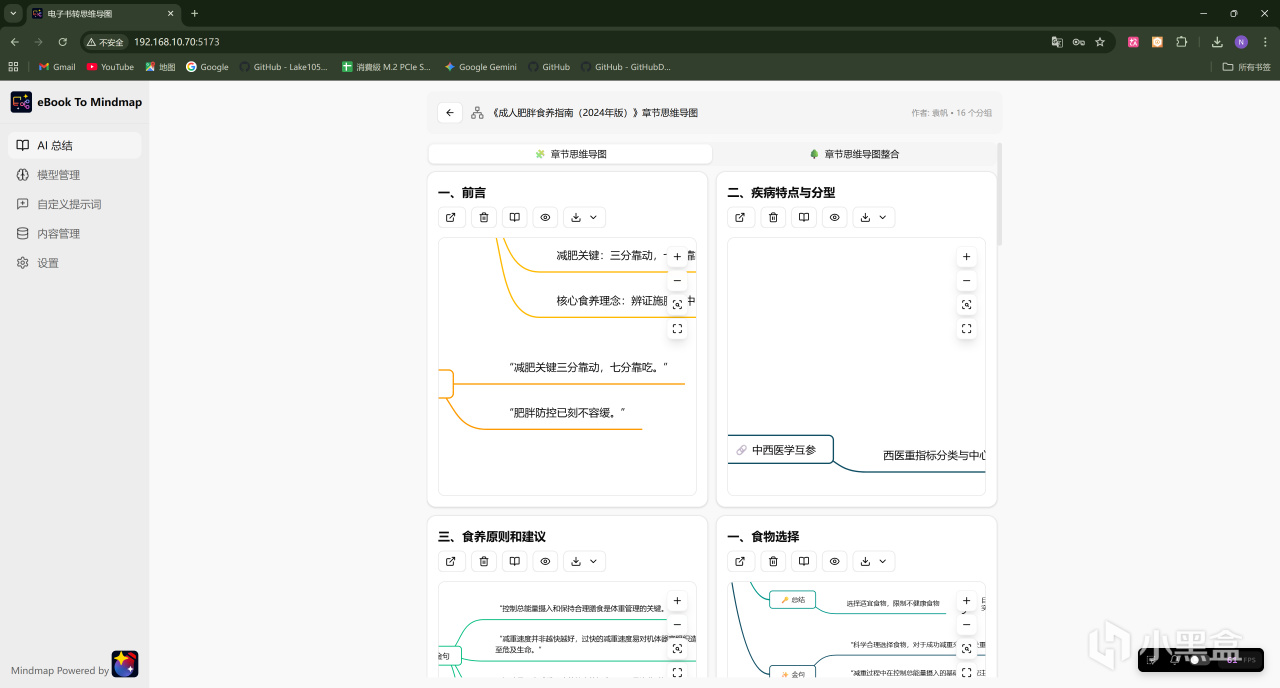
单章的思维导图肉眼可见要更加详细。
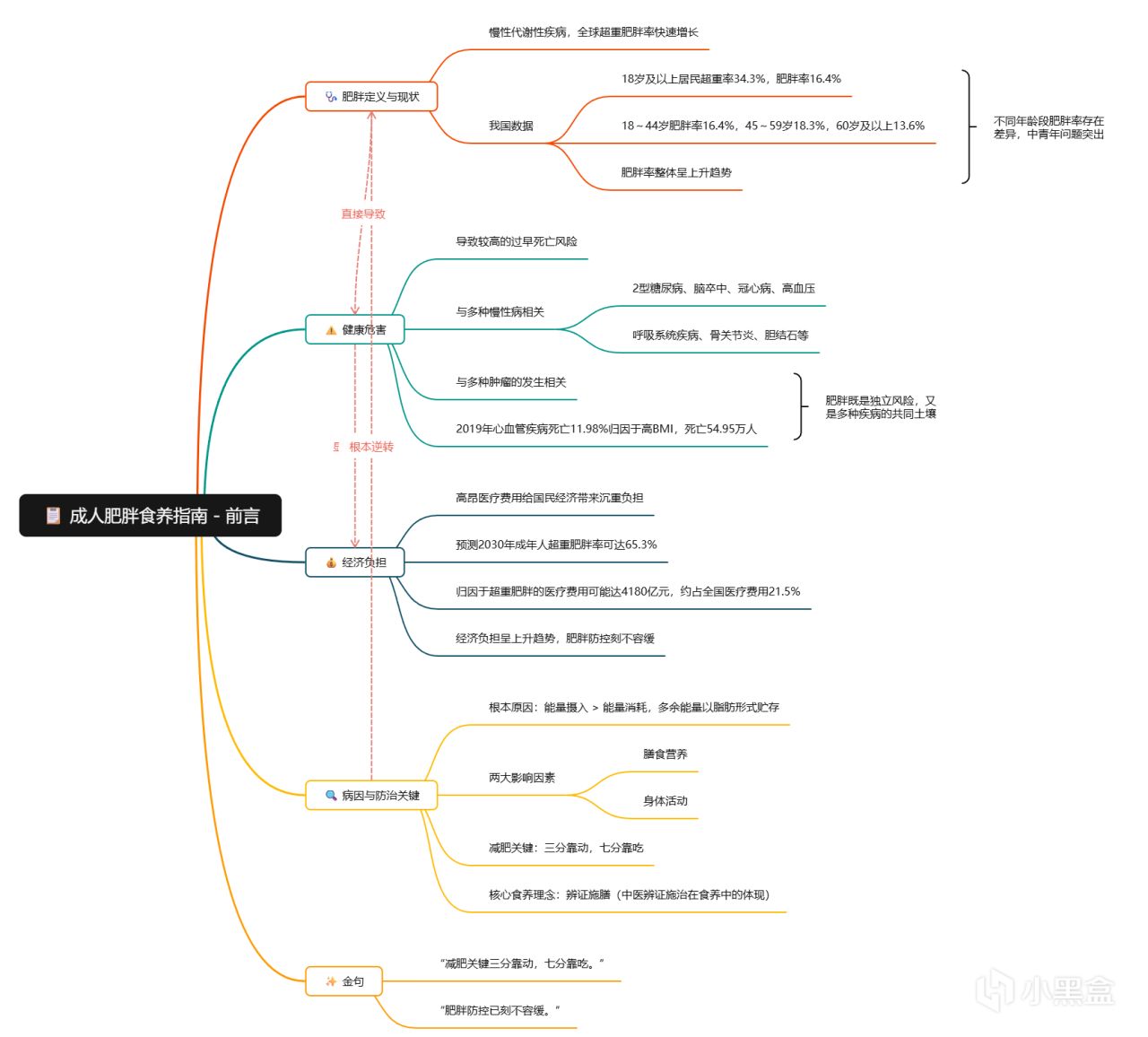
各章节都解析完成后,我们还可以使用它的章节思维导图整合功能,合并成一张更加详细的全文框架:
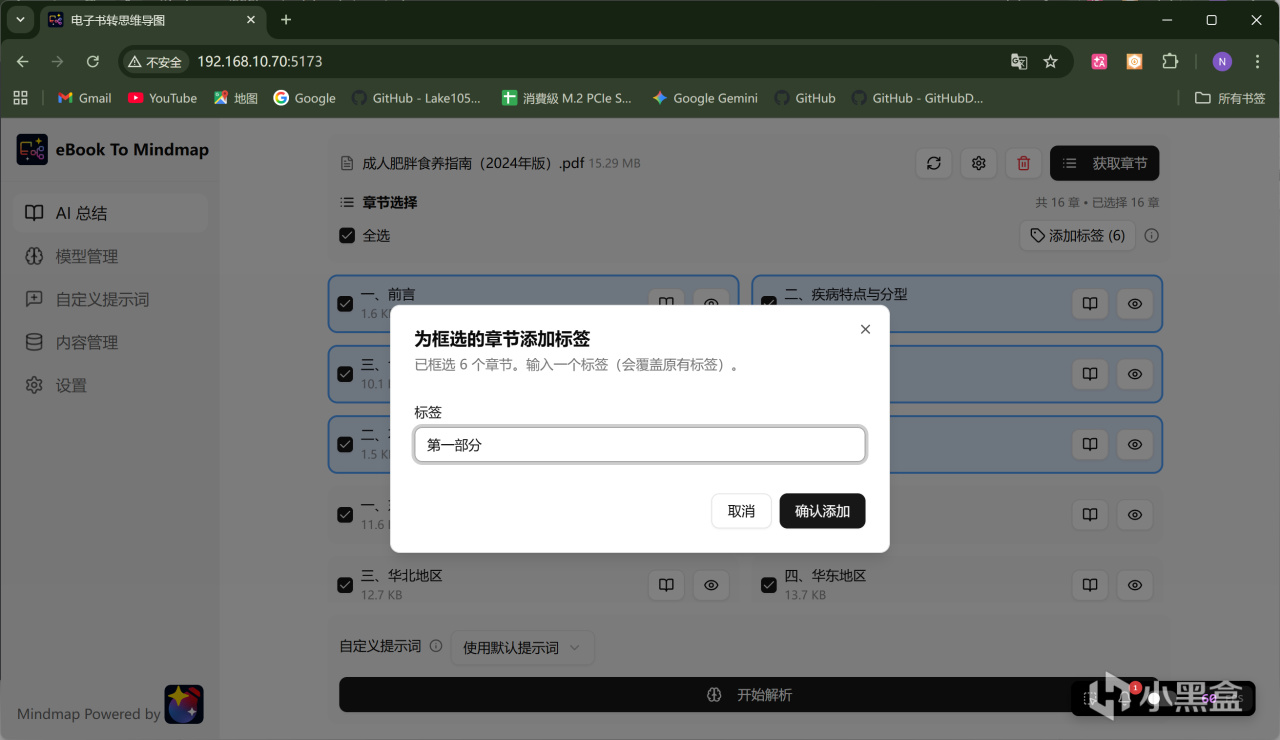
还有一个小技巧,对于内容较多的书籍,我们还可以将多个小章节合并为一个分组进行处理,这样可以生成更加结构化的结果:
在章节列表中可以用鼠标单击多选章节,选中后章节会有高亮边框。
点击列表顶部的「添加标签」按钮,输入分组名称,确认后选中的章节会被标记为同一组。
如果不需要分组,点击章节列表上已有的标签后的 "X" 图标即可移除。
总结
ebook-to-mindmap对于热爱折腾的NAS玩家、硬盘里塞满电子书却没时间看的仓储党,以及需要追求高效信息输入的科研工作者和职场人士来说,都非常适合。
它能一键将枯燥的长篇大论转化为直观的思维导图,直接把NAS变成我们的专属AI读书助理,从而帮助我们快速提取关键信息,完成信息框架的梳理工作,从全局脉络的角度来摄取知识。
这其中能提高多少效率,相信通过思维导图的朋友都懂。
那么以上就是本期的全部内容,如果大家在部署过程中遇到什么问题,欢迎在评论区留言交流,我们下期再见!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















