大家好,我是飄雷。
有不少朋友和我一樣,平時會在網上瘋狂囤積各種電子書或乾貨文檔,沉浸在下載了就等於學了的錯覺中。
不過雖然獲取信息的渠道和方式增多了,但吸收信息的效率畢竟還是有限,面對動輒幾百頁的長篇書籍,光是翻開目錄就讓人有些望而生畏,想要快速抓取核心知識點更是難上加難。
那有沒有辦法能提高我們的閱讀和知識吸收效率呢?
有的兄弟,有的。
今天咱們就來看看如何在NAS上部署一款堪稱讀書神器的GitHub開源項目——ebook-to-mindmap。
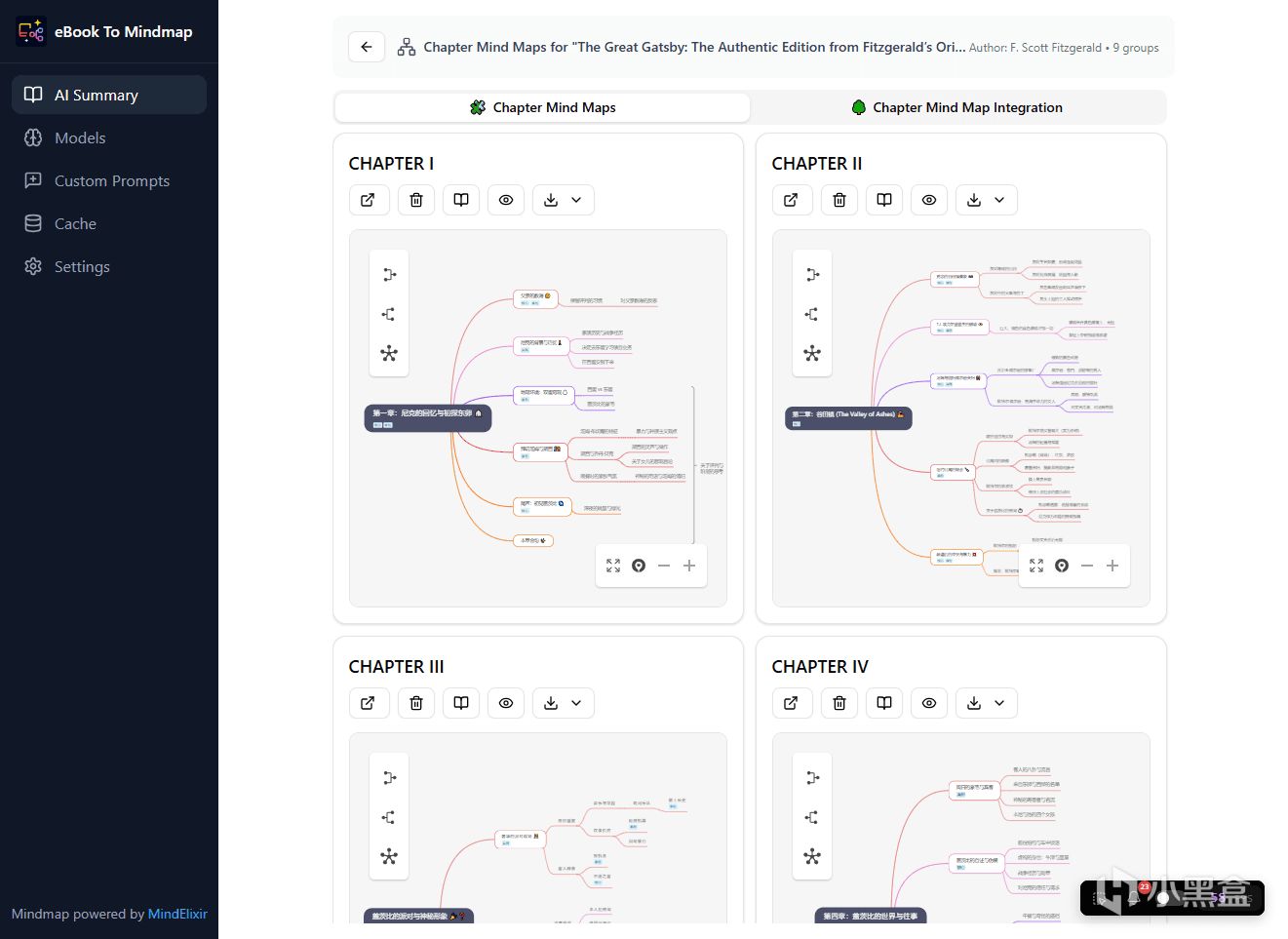
通過它,我們可以直接把電子書扔進去,利用AI大模型的力量,一鍵將晦澀冗長的書籍拆解成直觀的思維導圖和精煉的文字總結,讓AI先替你把書給啃一遍。
廢話不多說,我們直接進入正題。
一、什麼是ebook-to-mindmap?
ebook-to-mindmap是由國內開發者SSShooter開發的一款基於AI技術的智能電子書解析工具。
它的核心功能就是提取PDF和EPUB電子書裏的內容,交由AI大模型進行深度閱讀和歸納,最終輸出高度結構化的思維導圖和文字總結。
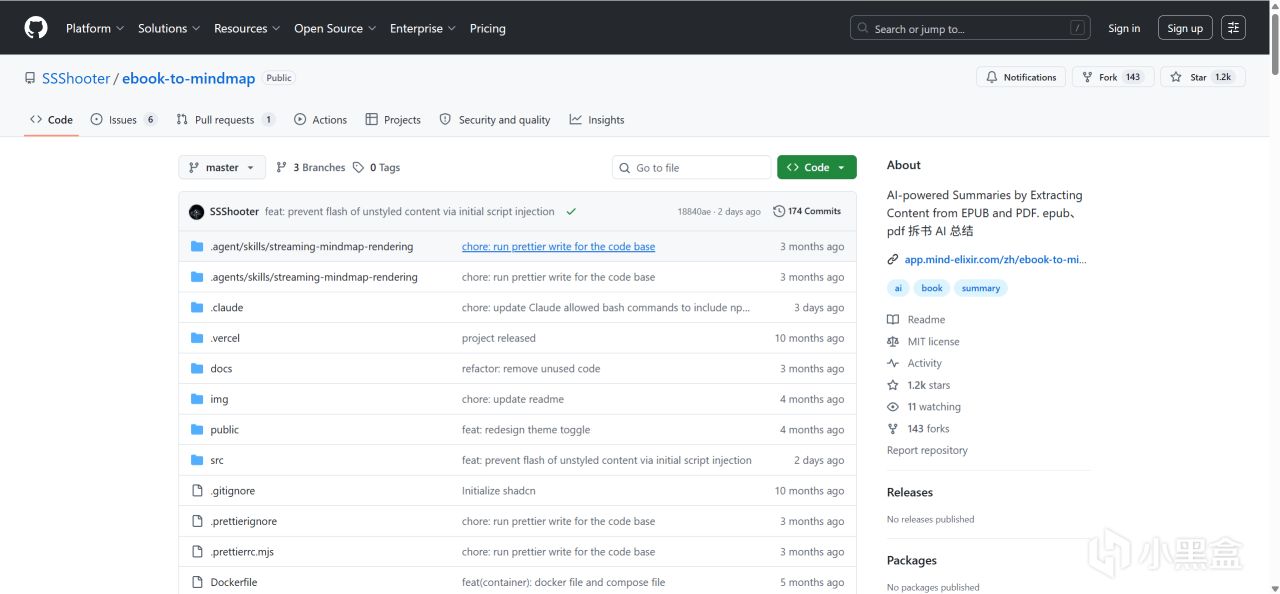
這款工具不僅採用了顏值非常高的UI設計,而且功能直擊囤書黨的痛點。
它支持接入DeepSeek、Google Gemini、OpenAI GPT等主流大模型,並且如果你的書字數較多,可以使用Gemini這種支持超長上下文的模型。
更關鍵的是,在解析電子書時,所有的AI請求都是從你的瀏覽器本地直接連接AI供應商的接口,不會經過任何第三方代理或中轉服務器,最大程度地保護了你的個人隱私和數據安全。
此外它還有文字總結、章節思維導圖、整書思維導圖三大硬核處理模式,滿足不同的場景需求,生成好的導圖還可以隨時離線查看。
就算在解析中途不小心關掉網頁,它的智能緩存機制能讓你下次直接從上次的位置繼續處理,
如果你不滿足於默認的總結方式,還能添加自定義提示詞(Prompt),讓AI以特定的口吻或側重點來爲你提煉知識點。
對於重度閱讀愛好者和需要經常拆書的小說作者來說,將這款工具部署在自家的NAS上,就可以隨時隨地打開網頁就能給電子書做AI深度拆解。
接下來,就讓我一步步教大家如何在威聯通NAS上部署這款神器吧!
二、部署流程
這裏我們來展示如何在威聯通NAS上使用Docker形式部署ebook-to-mindmap,用到的設備是威聯通最新的8盤位旗艦新品Qu805。
由於目前項目作者還沒有發佈現成的Docker鏡像,所以我們沒法直接使用拉取鏡像,需要利用NAS在本地自己構建(Build)一下進行部署。不過不用慌,操作過程也同樣簡單。
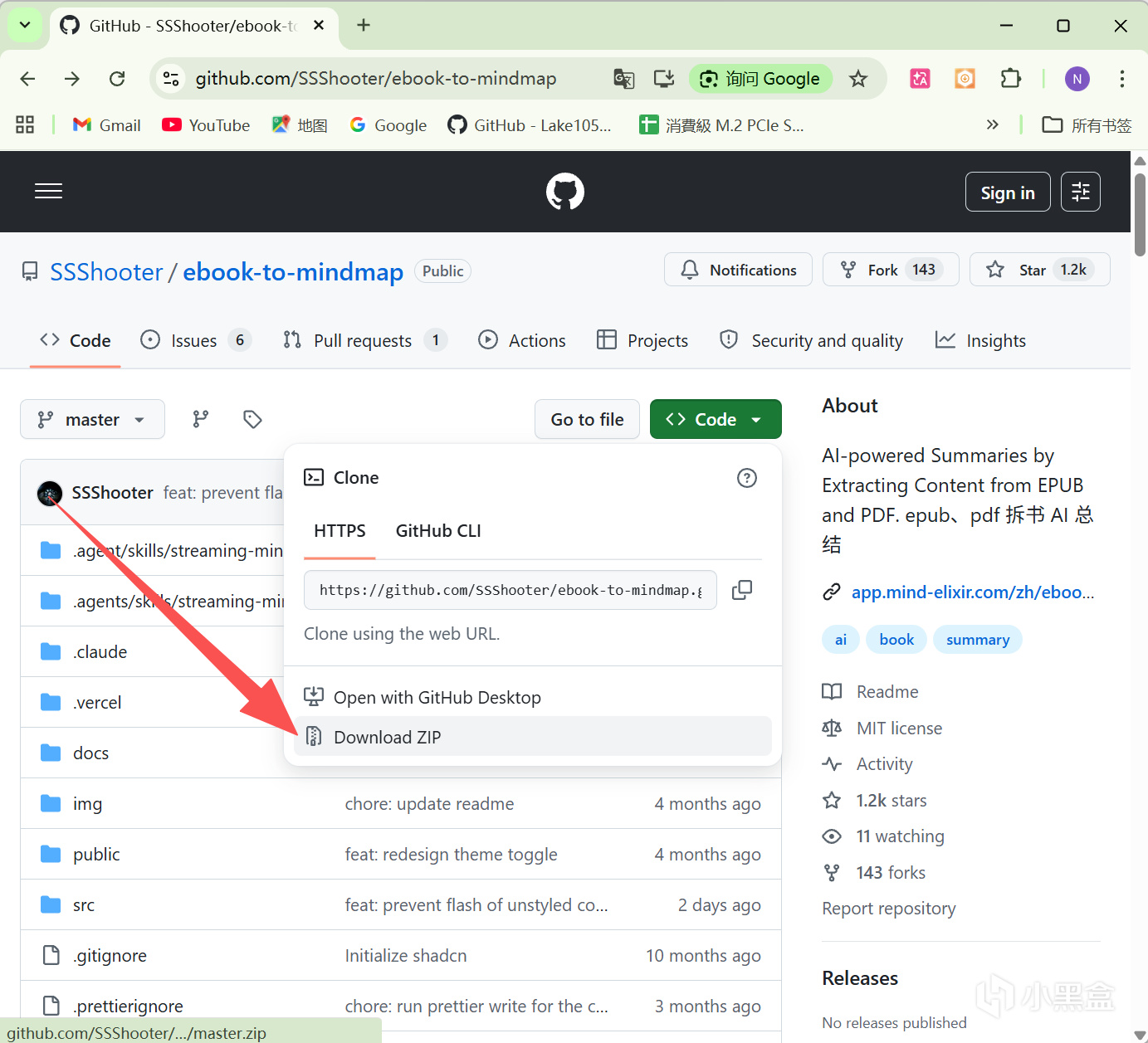
如圖所示,我們需要先去GitHub下載打包後的項目文件ZIP壓縮包,解壓縮後能看到ebook-to-mindmap-master這個文件夾:
接下來將ebook-to-mindmap-master文件夾上傳到NAS,同時爲了簡潔點兒,咱們可以選擇修改一下文件夾名,比如這裏我使用的地址是/share/Container/ebook-to-mindmap
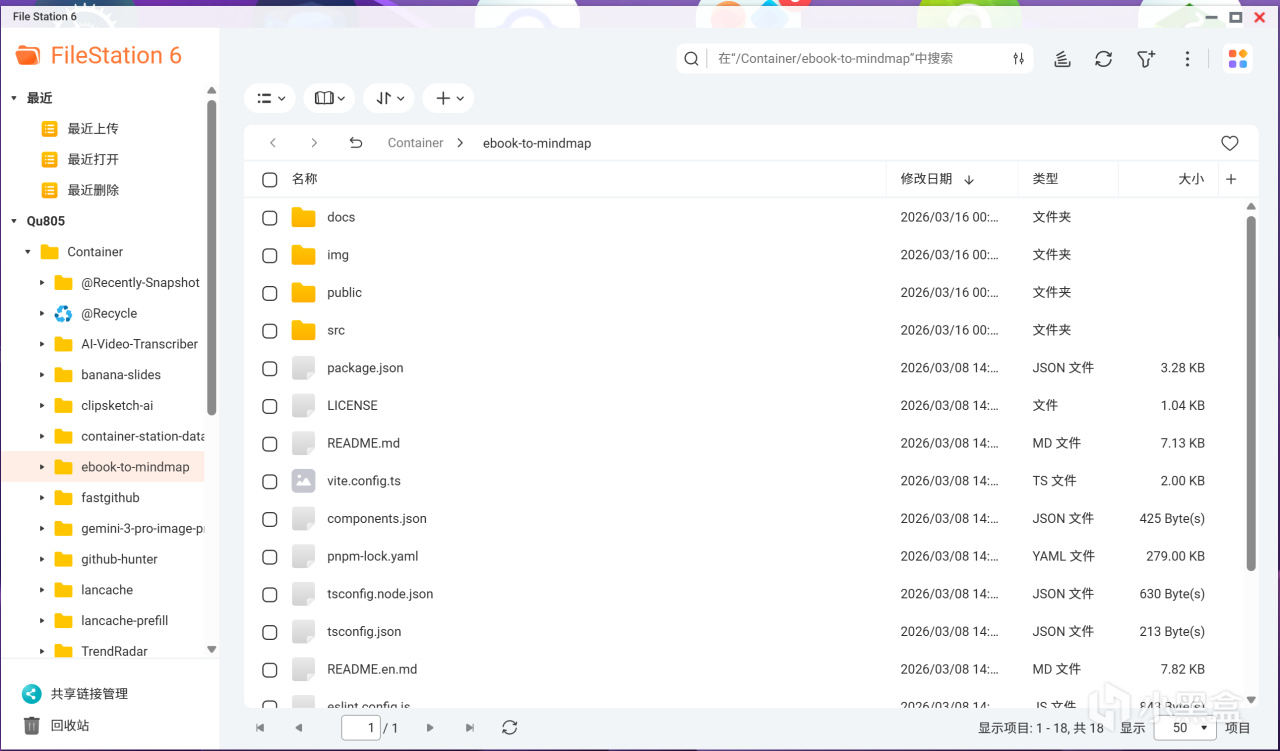
爲了照顧不習慣使用SSH的朋友,接下來我們使用docker compose代碼的方式直接部署。
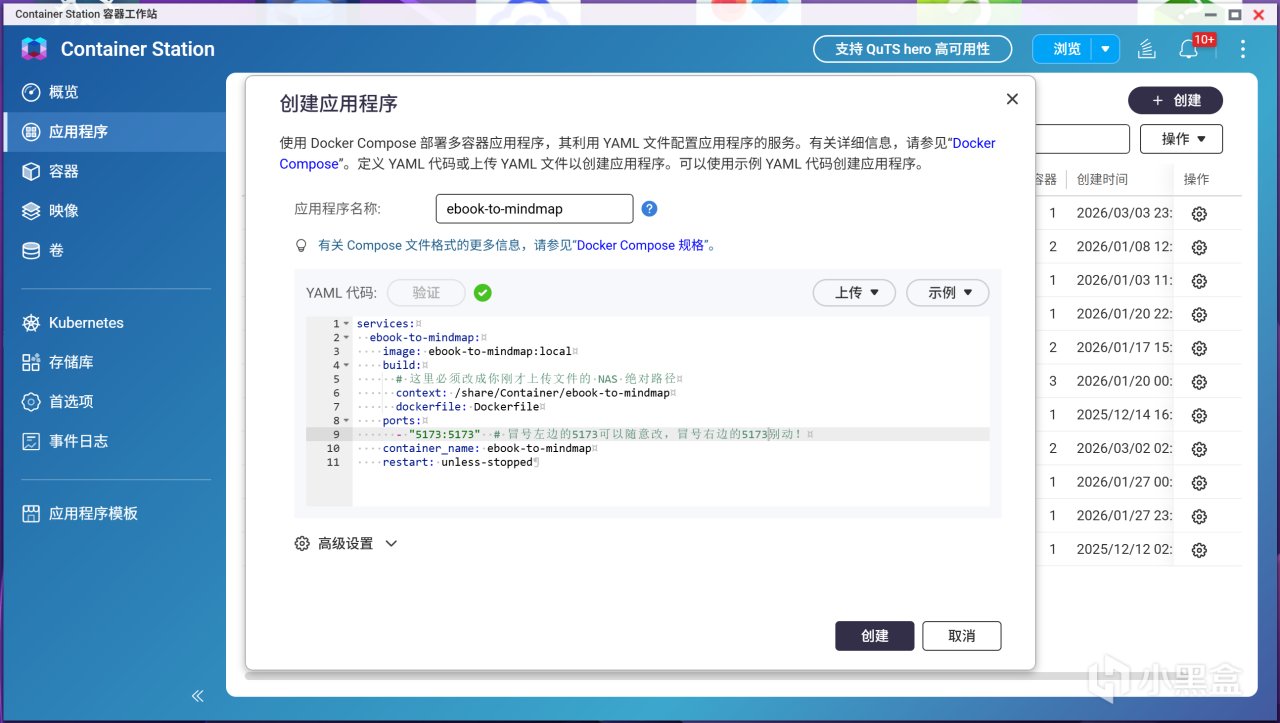
打開威聯通 Container Station,點擊左側的「應用程序」,然後點擊右側黑色「創建」按鈕,輸入以下代碼:
services:
ebook-to-mindmap:
image: ebook-to-mindmap:local
build:
# context這裏必須改成你剛纔上傳文件的 NAS 絕對路徑
context: /share/Container/ebook-to-mindmap
dockerfile: Dockerfile
ports:
- "5173:5173" # 冒號左邊的5173可以隨意改,冒號右邊的5173別動!
container_name: ebook-to-mindmap
restart: unless-stopped
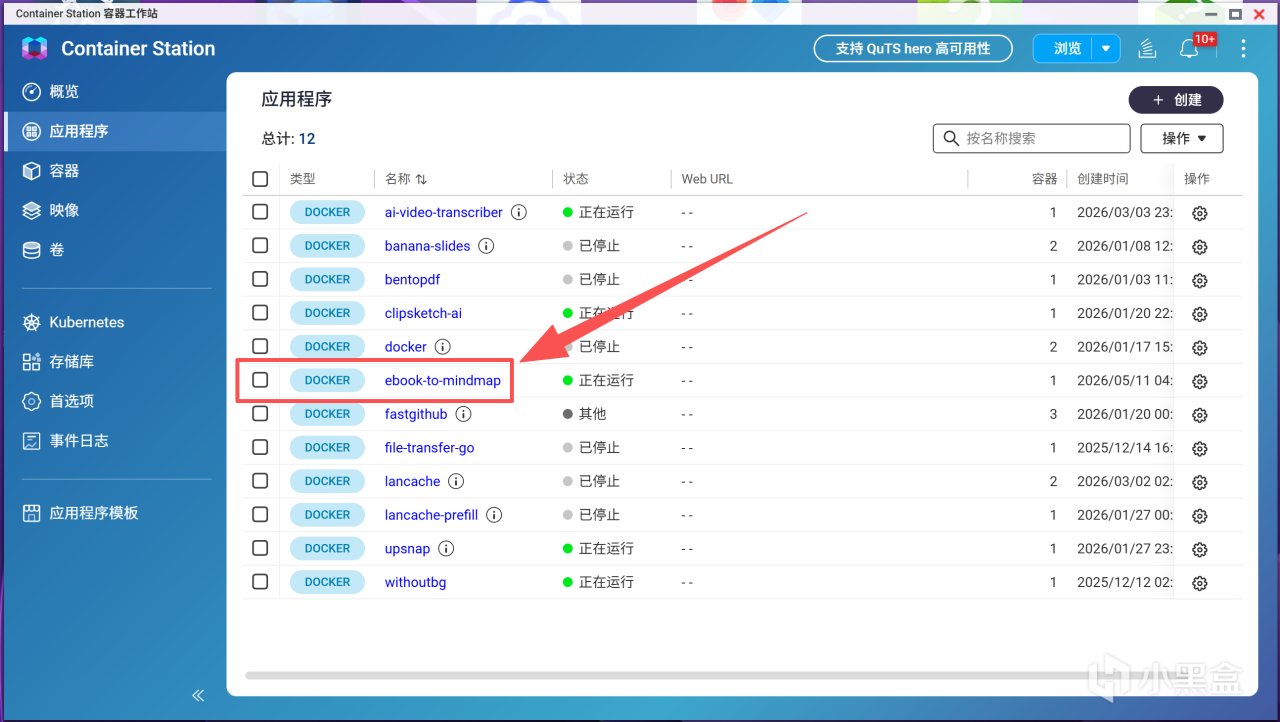
此時可以在Container Station中看到正在運行的容器:
三、使用方法
1.相關配置
ebook-to-mindmap部署完成後,我們只要在PC或者手機瀏覽器中輸入 http://<NAS IP>:<端口號>,比如http://192.168.10.70:5173,就可以直接訪問項目頁面了。
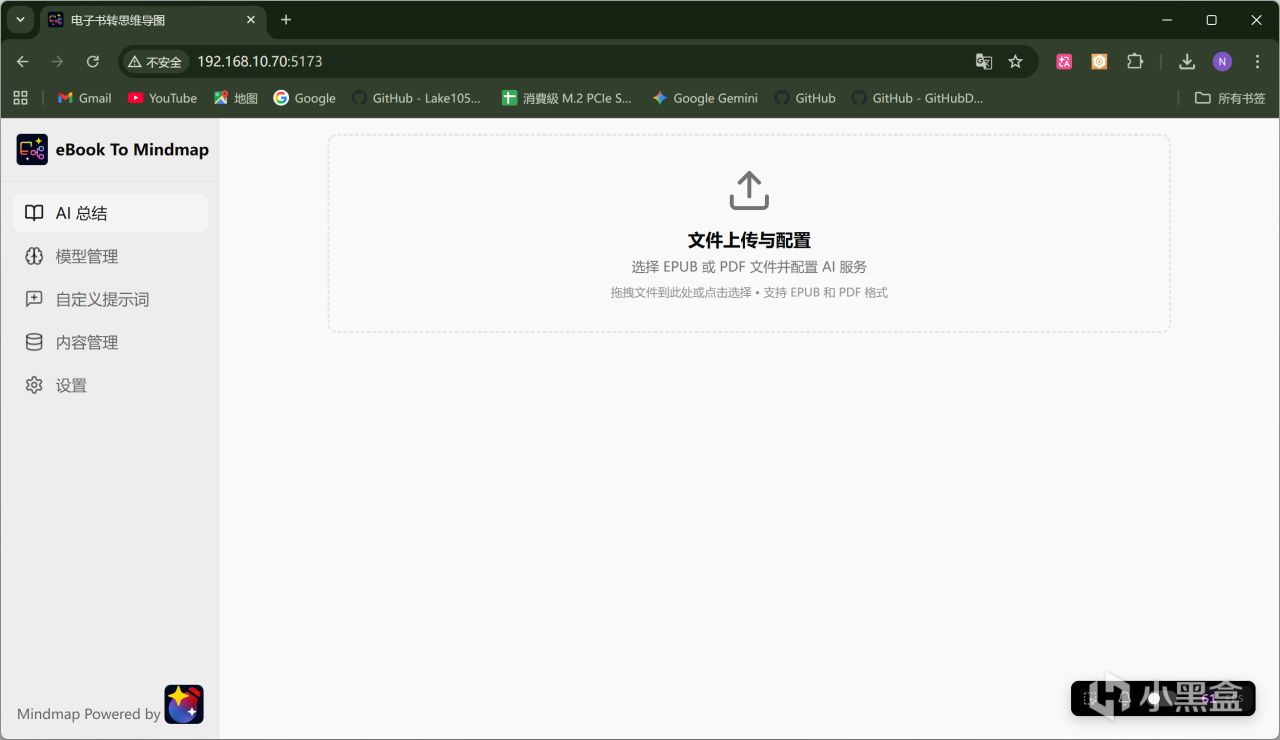
在正式使用前,我們首先需要設置使用的AI模型,依次點擊「模型管理」——「添加模型」:
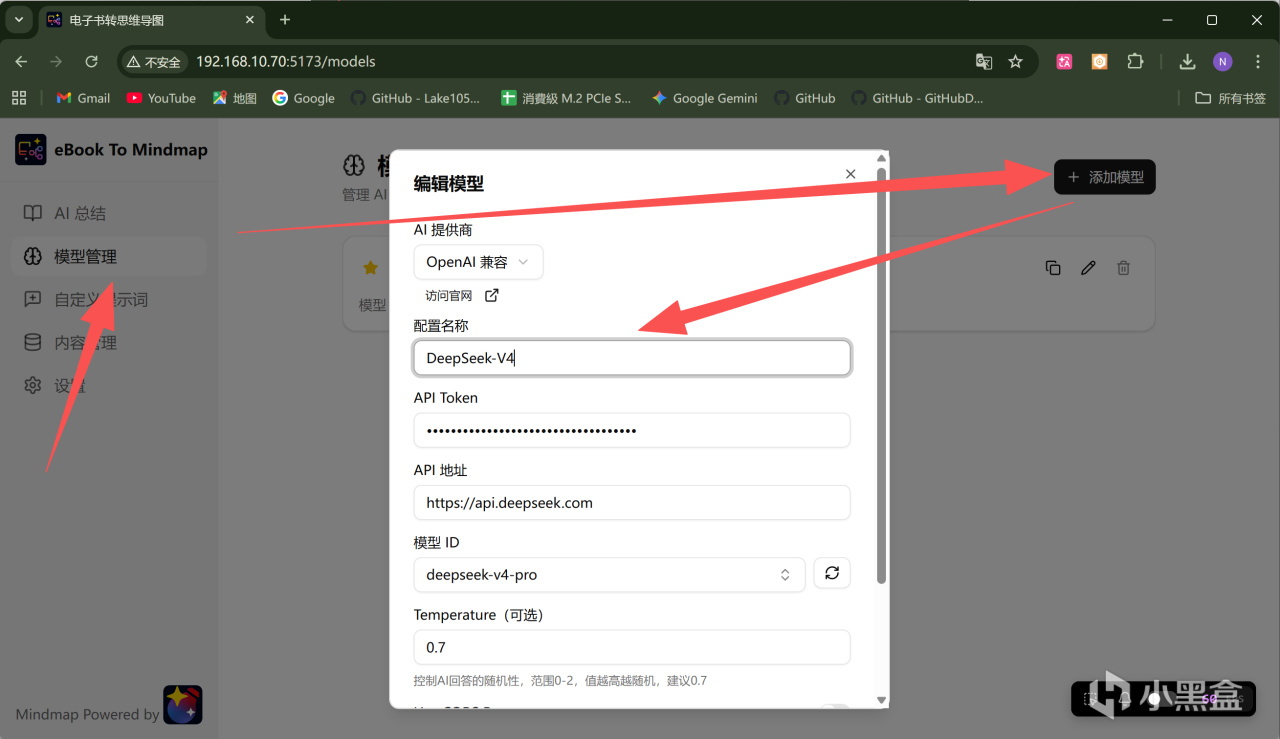
在AI提供商這裏,可以選擇Google、OpenAI等官方算力提供商,也可以選擇Ollama等本地算力。這裏我準備使用最新的DeepSeek V4模型,所以選擇了OpenAI 兼容模式。
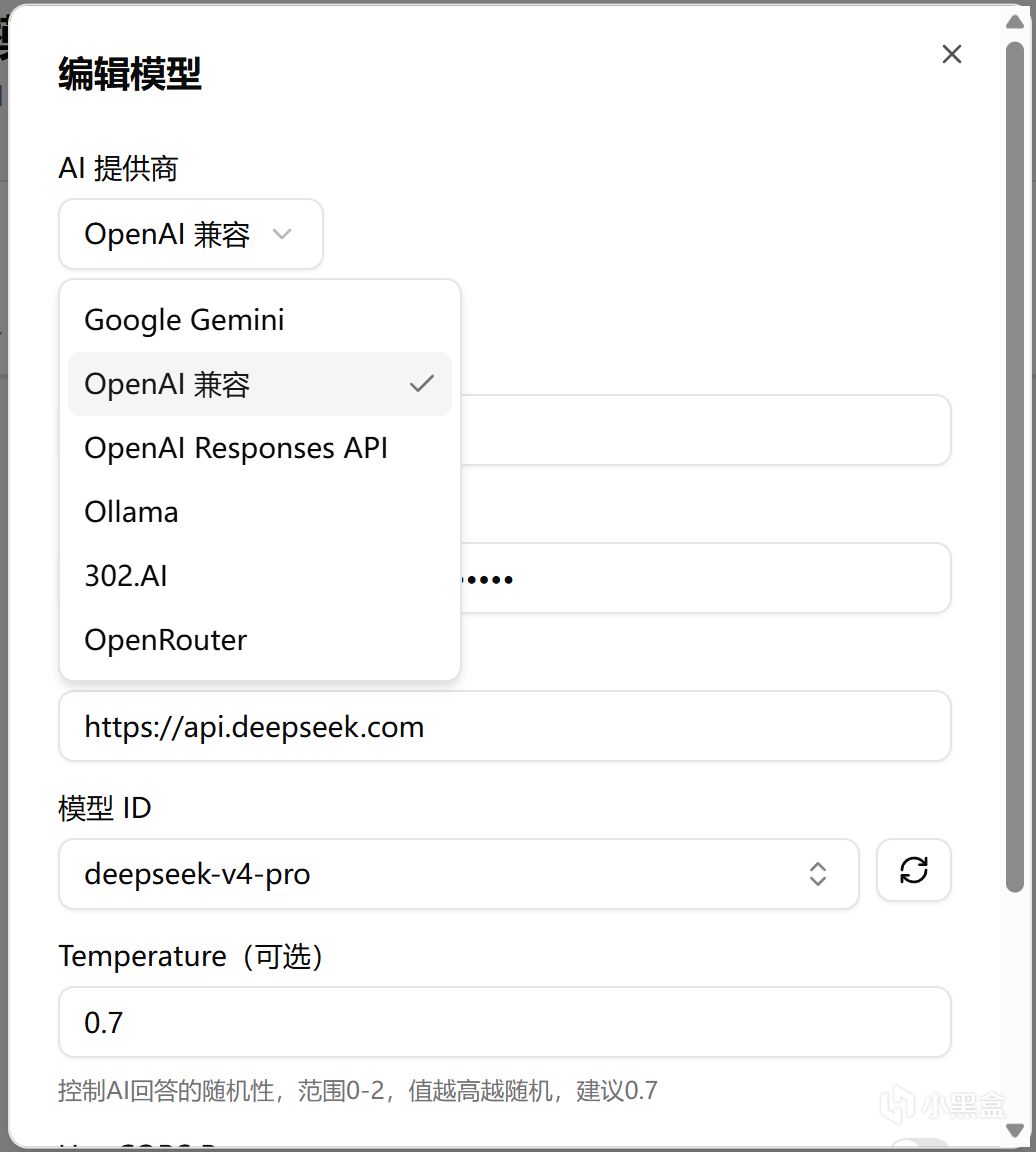
然後按照下圖中的註釋,配置名稱可以自己隨便寫,API Token、API地址和模型ID,需要根據你的算力提供商的調用文檔來填。
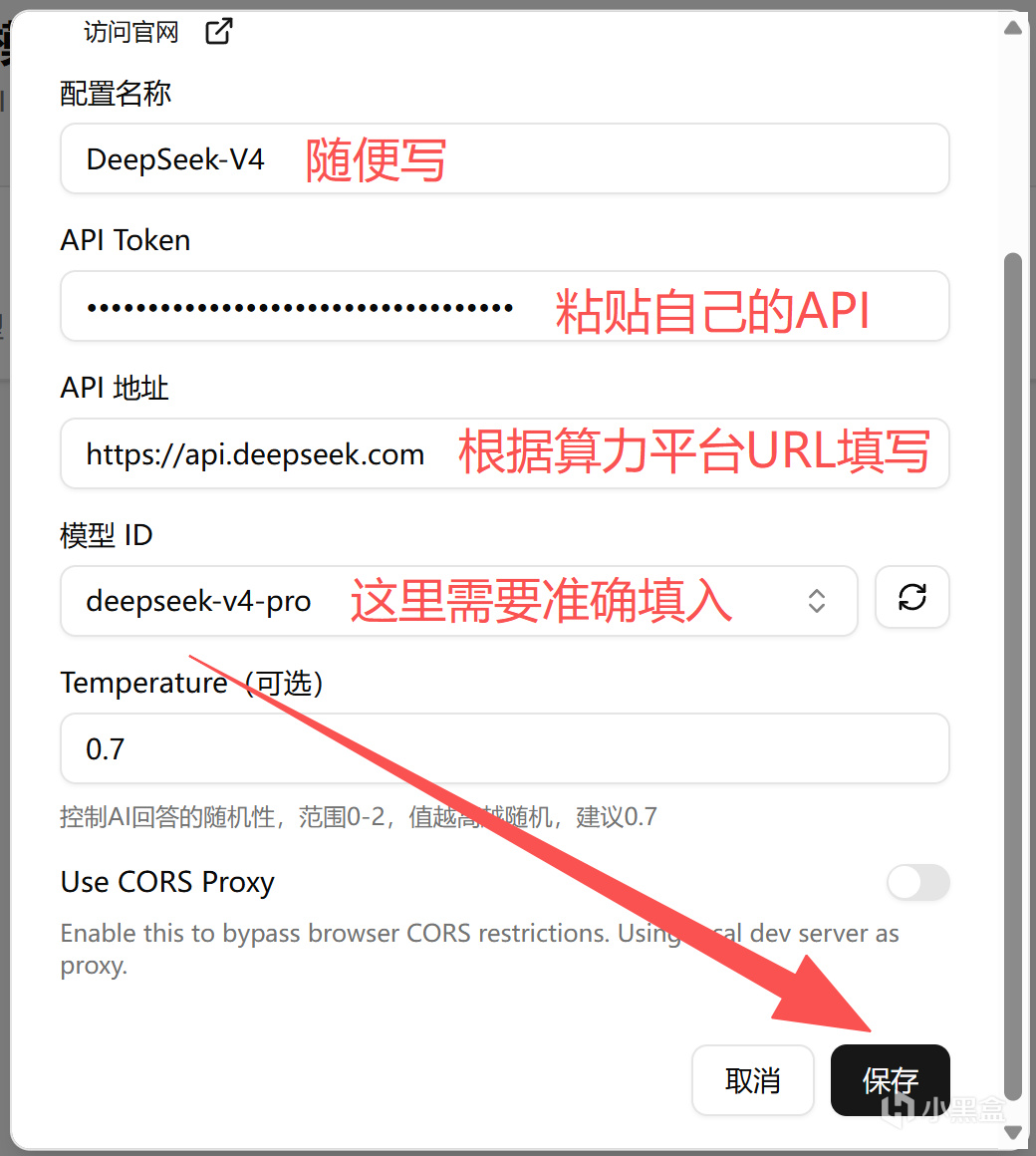
我自己是使用了DeepSeek官方URL,同時模型使用了最新的deepseek-v4-pro模型,設置完成後別忘了點擊保存。
接下來我們在看看其他的設置選項,點擊左側的「設置」,可以配置界面語言、主題顏色和輸出語言等等:
繼續往下拉,在「處理模式」一欄,需要特別注意一下,項目作者提供了3個選項。
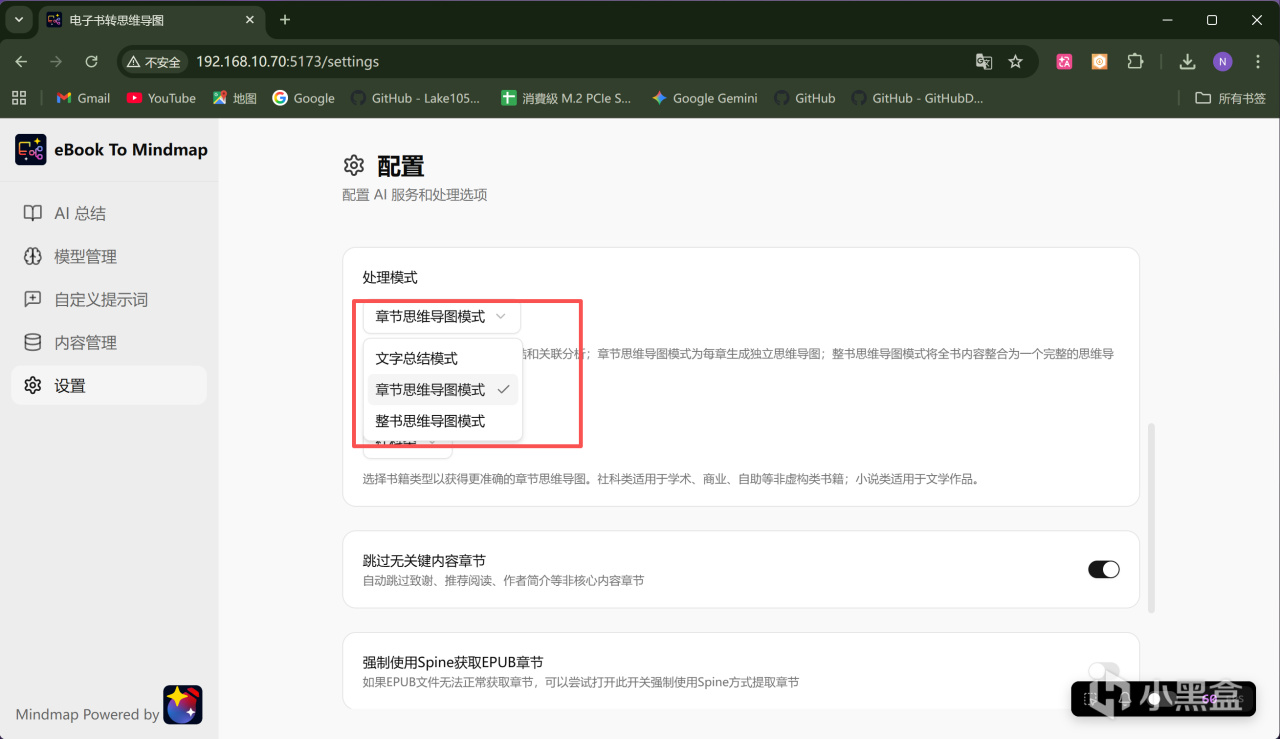
文字總結模式適合需要文字總結的場景,可以生成章節總結、分析章節關聯、輸出全書總結;
章節思維導圖模式可以爲每個章節生成獨立的思維導圖;
整書思維導圖模式可以將整本書內容整合爲一個完整的思維導圖,但由於AI模型的上下文長度有限制,所以像幾百萬字的小說這種太長的內容可能會生成失敗。
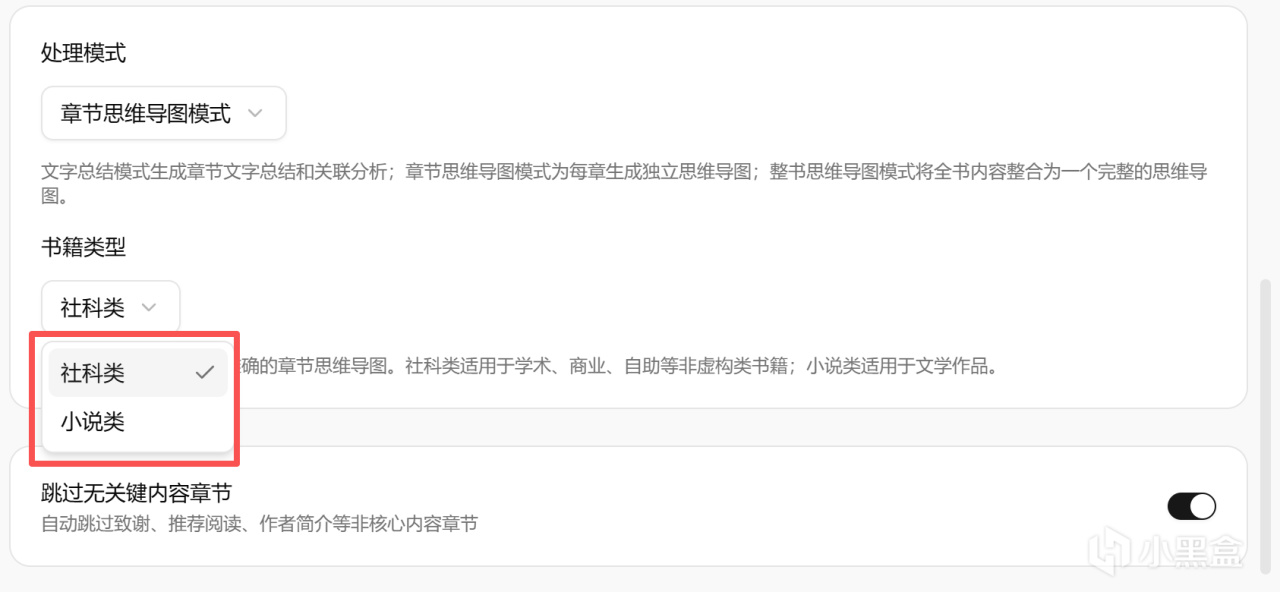
在書籍類型方面,也分爲了小說類和正常社科類,可以根據實際場景來靈活選擇:
2.使用演示
我們回到首頁,點擊「選擇 EPUB 或 PDF 文件」按鈕,然後上傳需要處理的電子書文件:
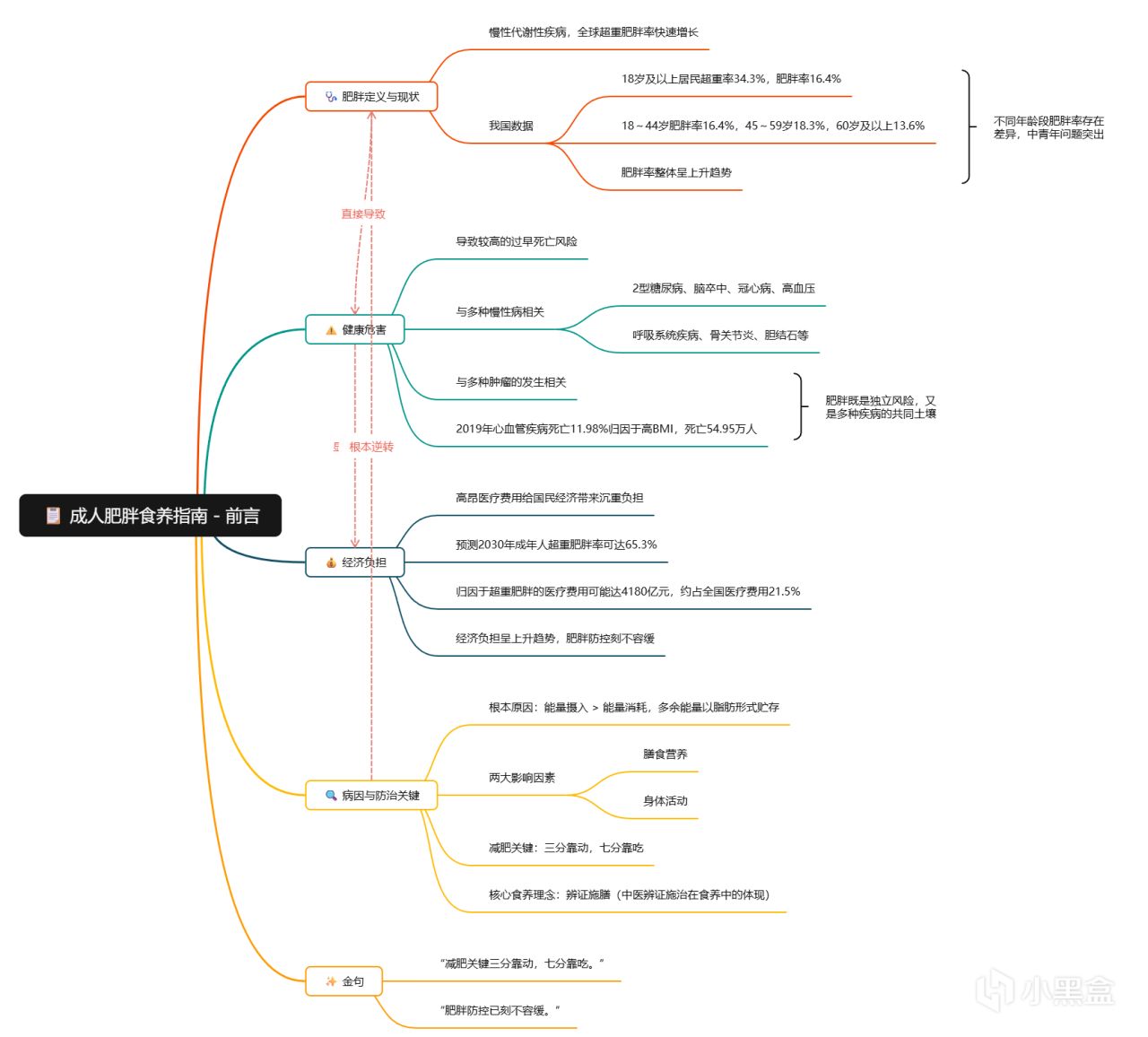
比如我上傳了一份2024年衛健委發佈的《成人肥胖食養指南》PDF文件,可以看到會自動識別出文件中的各個章節,然後點擊「開始解析」即可:
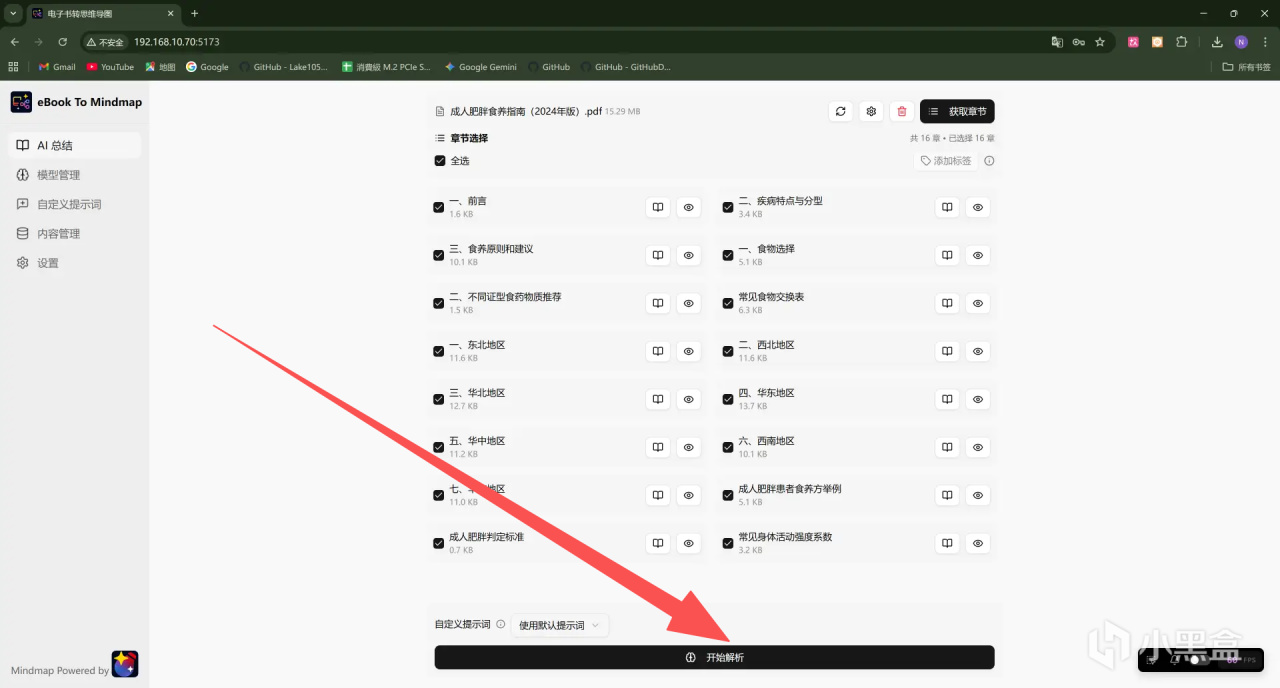
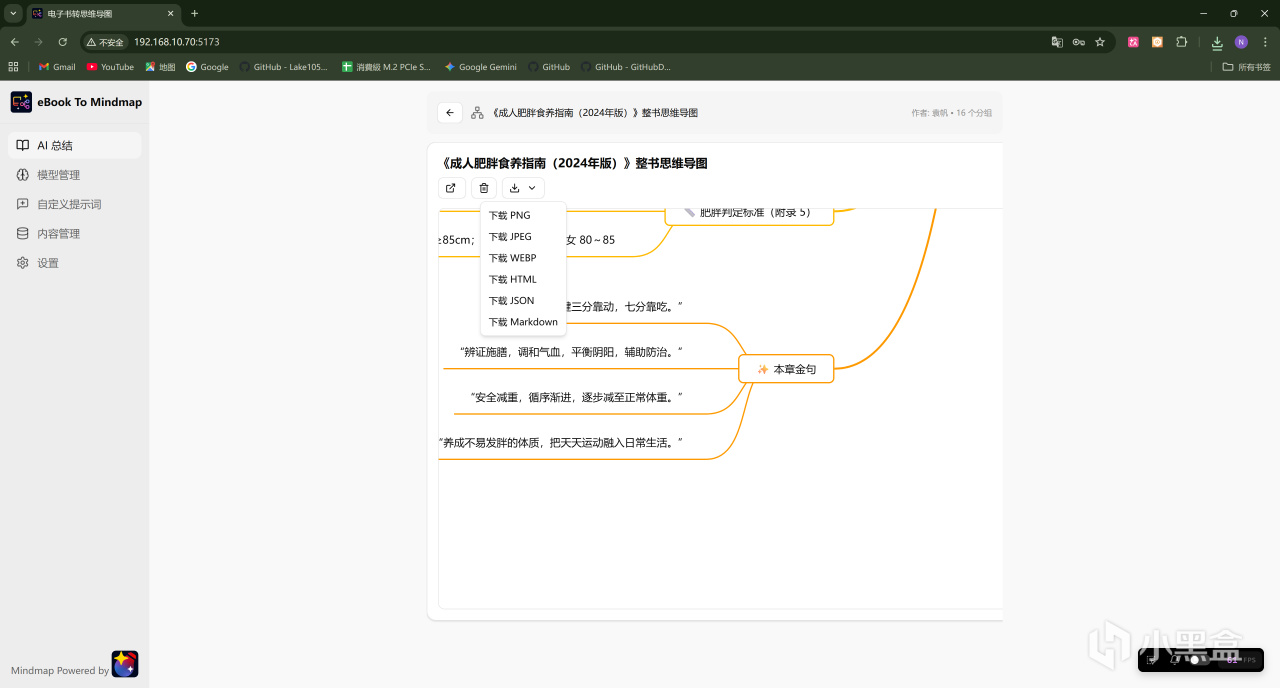
由於這份文件的字數不算太多,DeepSeek-V4一百萬的上下文長度足夠一次性解析,所以首先選擇了整書模式試試,稍等一會兒解析完成後即可呈現全文的整體思維導圖框架,並且可以下載成圖片或者HTML、Markdown文件等格式:
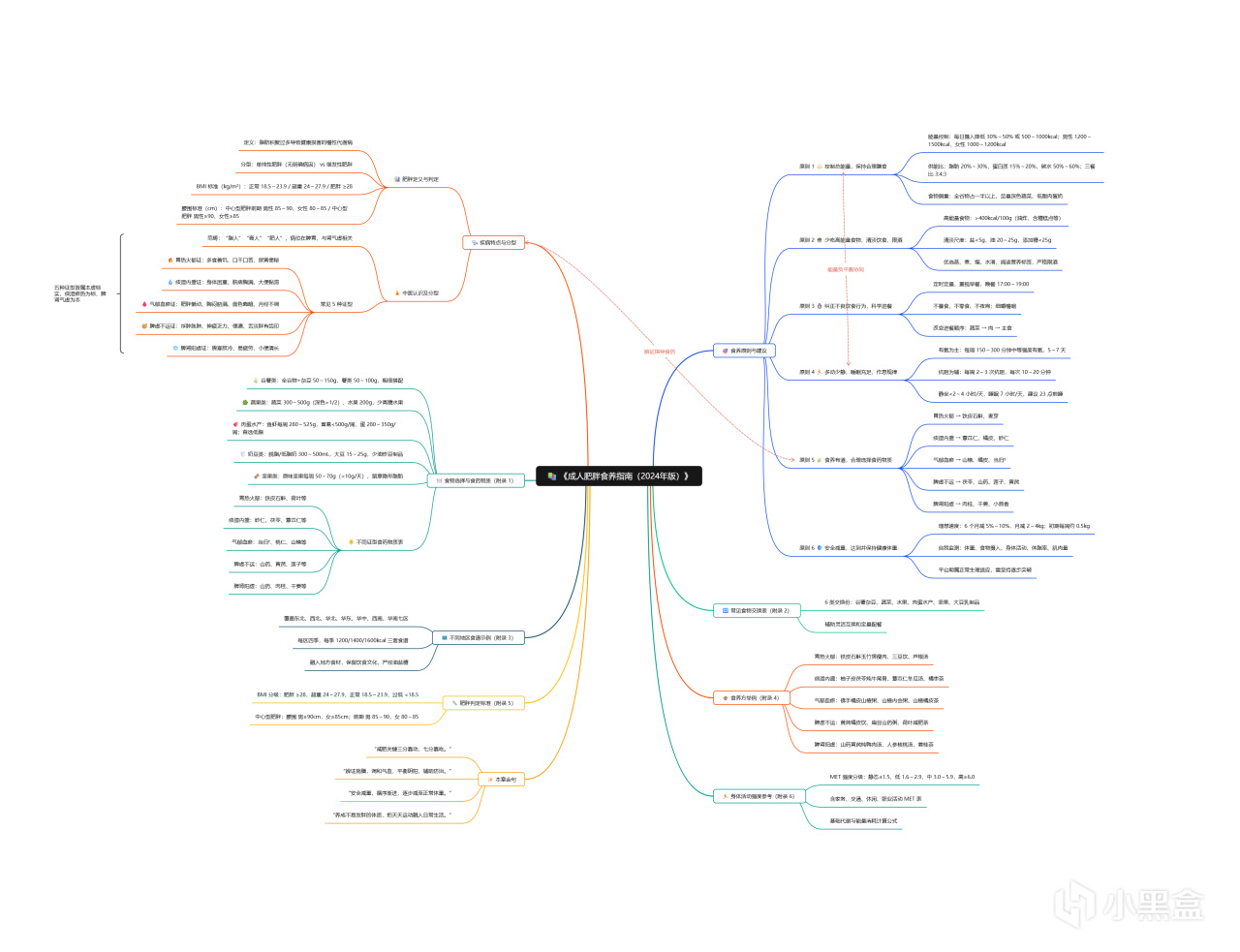
看看整體的思維導圖的效果,還是挺不錯的:
同時針對字數超過AI模型上下文限制的文檔,我們可以選擇章節思維導圖模式來解析,每一章都會有單獨的思維導圖:
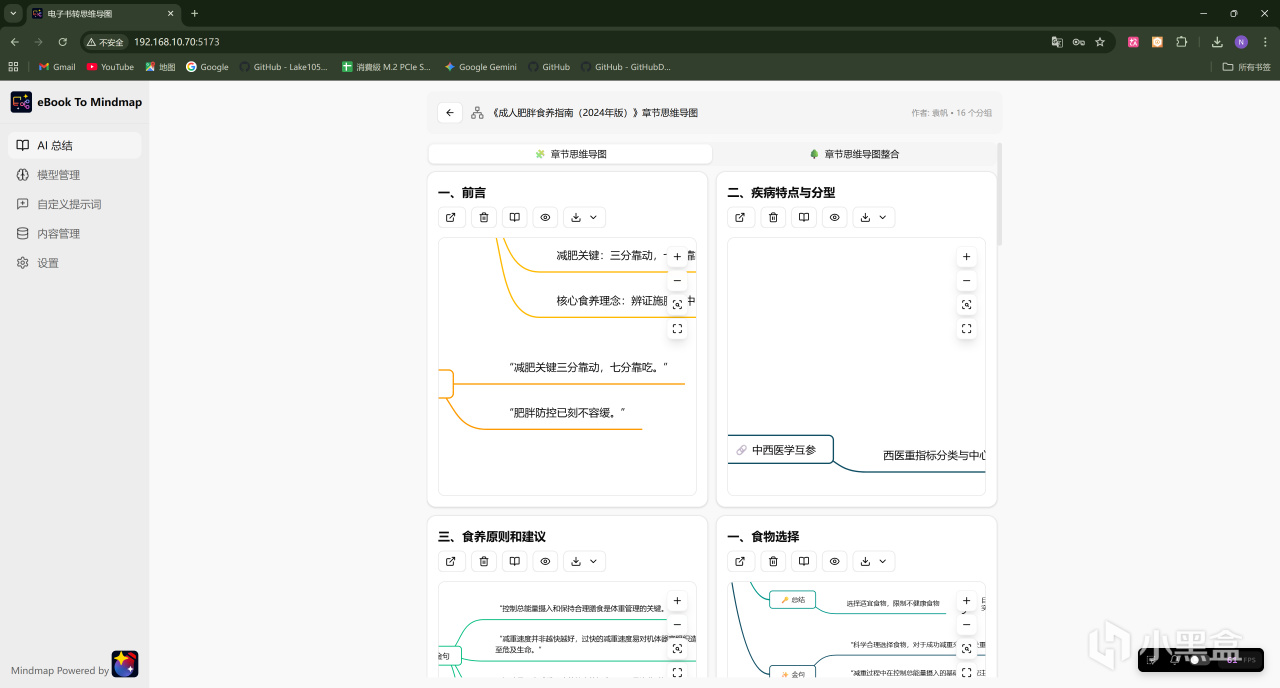
單章的思維導圖肉眼可見要更加詳細。
各章節都解析完成後,我們還可以使用它的章節思維導圖整合功能,合併成一張更加詳細的全文框架:
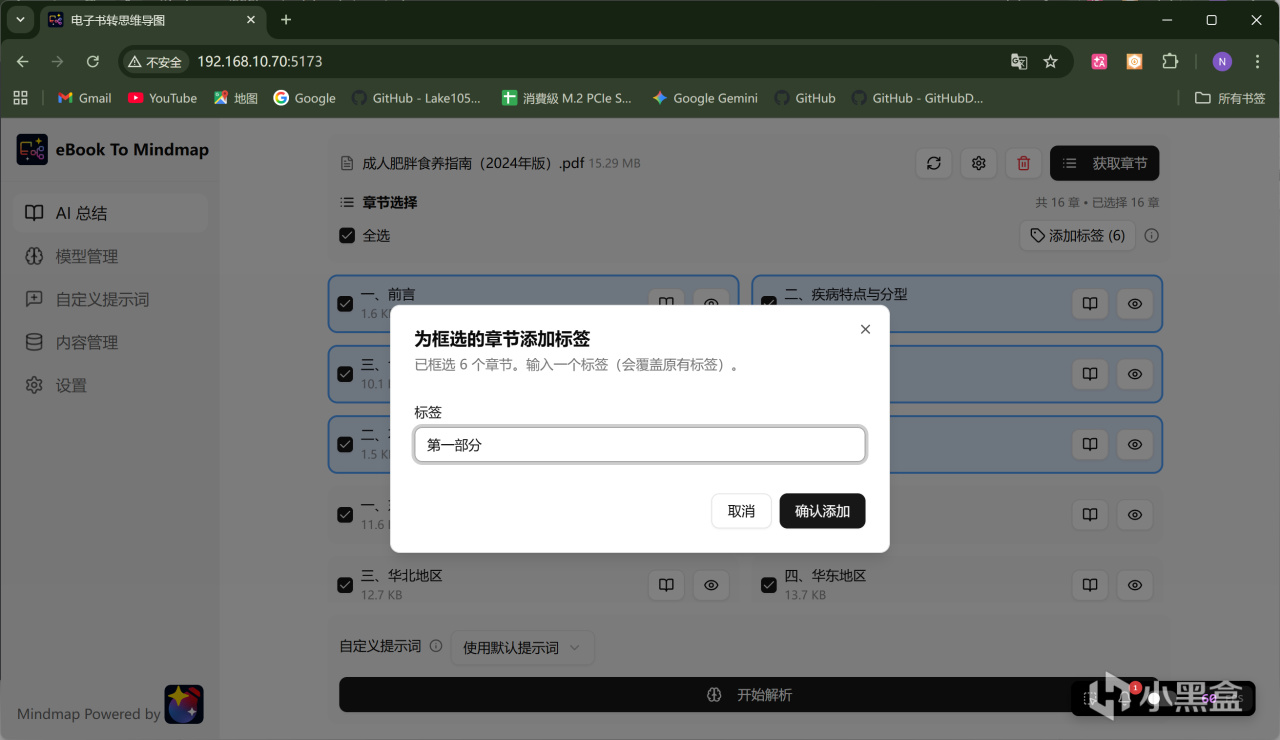
還有一個小技巧,對於內容較多的書籍,我們還可以將多個小章節合併爲一個分組進行處理,這樣可以生成更加結構化的結果:
在章節列表中可以用鼠標單擊多選章節,選中後章節會有高亮邊框。
點擊列表頂部的「添加標籤」按鈕,輸入分組名稱,確認後選中的章節會被標記爲同一組。
如果不需要分組,點擊章節列表上已有的標籤後的 "X" 圖標即可移除。
總結
ebook-to-mindmap對於熱愛折騰的NAS玩家、硬盤裏塞滿電子書卻沒時間看的倉儲黨,以及需要追求高效信息輸入的科研工作者和職場人士來說,都非常適合。
它能一鍵將枯燥的長篇大論轉化爲直觀的思維導圖,直接把NAS變成我們的專屬AI讀書助理,從而幫助我們快速提取關鍵信息,完成信息框架的梳理工作,從全局脈絡的角度來攝取知識。
這其中能提高多少效率,相信通過思維導圖的朋友都懂。
那麼以上就是本期的全部內容,如果大家在部署過程中遇到什麼問題,歡迎在評論區留言交流,我們下期再見!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















