昨天,OpenAI 正式推出 GPT-Image-v2(ChatGPT Images 2.0)。

啊不对,是这张:
本次更新后,所有用户可以使用上最新的 GPT Image v2 模型,如果你是订阅了 20刀及以上的付费计划的用户,还可以用上带思考的完全体 GPT Image v2。

这次更新,没有大张旗鼓的发布会,但其模型的实际出图效果,却迅速在整个圈子,甚至是圈外引起了极高的讨论度。
(在此之前,上周v2就在Lmarena盲测了,无敌手的状态)

这是继GPT Image 1.5之后的又一次重大迭代,也是 OpenAI 自 Sora 宣布关闭之后,在视觉领域的一次重要反击。
现在,OpenAI 带着 GPT Image v2 杀回来了。
先说最直观的一点:文字渲染能力大提升。
以前生成带文字的海报、UI界面、信息图、菜单、广告牌的时候,模型经常出现黄 tint 色偏、文字扭曲、乱码等问题。
现在这些毛病基本没了。

无论中英文还是其他语言,文字都能清晰、准确、自然地呈现在图像里。
手写文字也不在话下(内容还不是乱写的):

尽管进步巨大,但官方博客任然写得很低调:

其次是真实世界理解能力极大提升。
模型对现实物理、布局、逻辑的理解明显更强了。
现在它能轻松生成完整的信息图、各种截图、产品原型、地图、UI界面等结构化内容,逻辑一致性极高。
这里我直接让GPT来生成一张截图,显然,这对它来说基本没有难度:
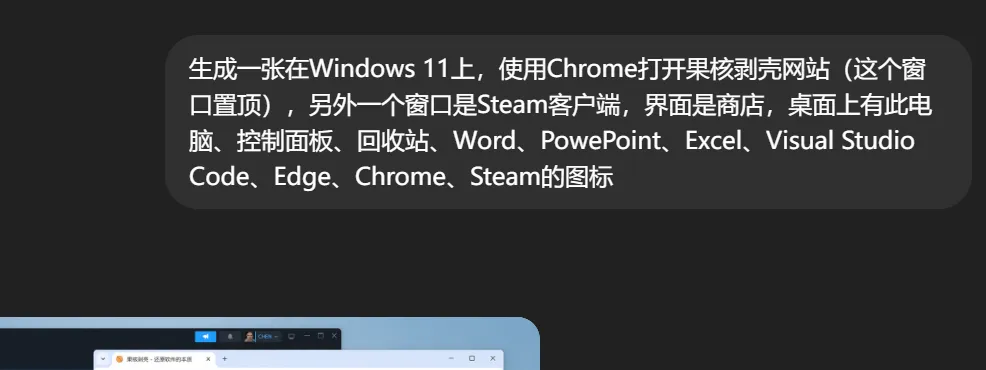
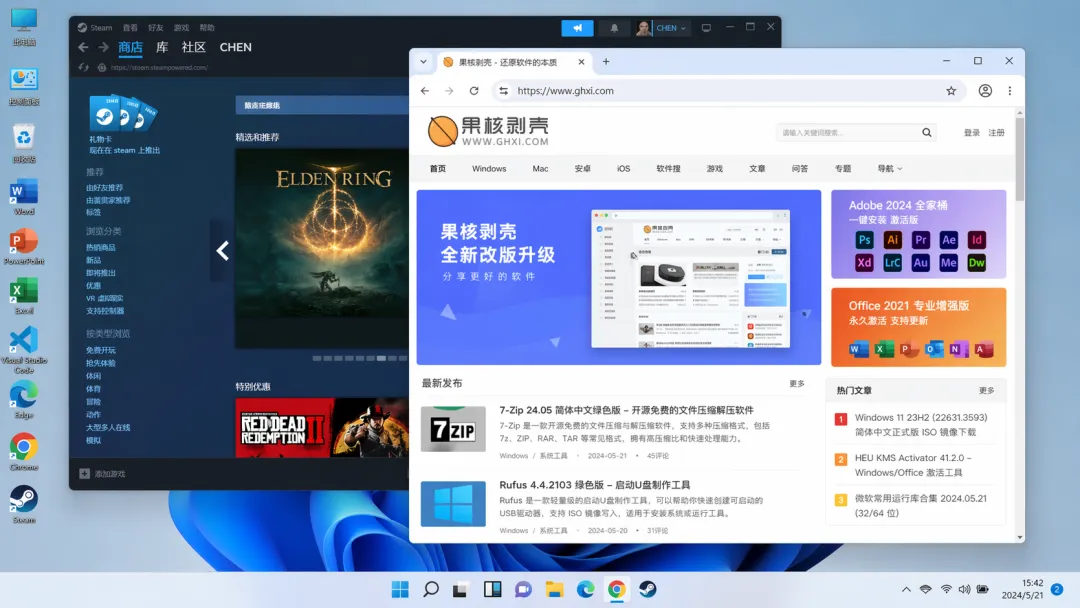
以前需要反复调整prompt才能勉强接近的效果,现在简单一段描述就能得到一个比较好的输出。
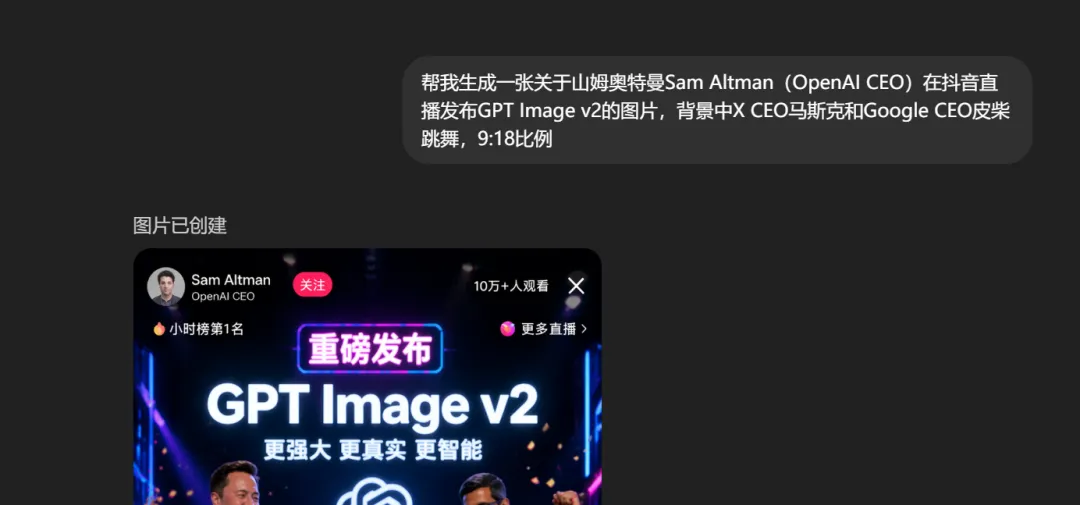
最恐怖的一点,是它几乎不需要复杂的提示词就能生成高质量图片。
例如本文的第一张,奥特曼直播,也是 Image v2 一句话生成的:
最近潜兵战斗爽,也试了试一句话生成潜兵的截图:

还可以让牢大卖红茶:

以前图像生成还是“Prompt工程”的时代,不会搓高质量prompt的人,给他再好的模型,生成出来的图片效果也是一言难尽。
现在这个门槛基本消失了——你随便甩一句自然语言,它就能理解你的意图,生成逻辑清晰、细节丰富的图像。
这一点才是真正把图像生成从专业玩家游戏变成大众日常工具的关键变化。
这些实测让我明显感觉到,Image v2 在指令遵循和真实世界理解上的进步非常大。
Image v2生成的阿兹特克、玛雅、印加帝国在其鼎盛期的地图
门槛降低之后,影响是双面的。
一方面,普通用户能更轻松地生成高质量图像,创意门槛大幅下降;
另一方面,恶意用途的风险也随之而来:假截图、假广告、假聊天记录、假新闻图片的制作成本会变得极低,辨别难度大幅增加,这对社会、媒体和监管提出了前所未有的要求。(而这,只是我们立马就能想到的恶意用途之一)
以后这张“截图”是不是AI生成的,可能真的会成为一个问题。
从技术竞争的角度看,Imagev2 已经在性能和用户体验上树立了一个新的标杆。
谷歌的香蕉系列,此时又显得像过时模型一样
AI还在全速狂奔,Imagev2 也只是在这段时间内领先。
但 Imagev2 的领先,不只是一次迭代,更是一种趋势的宣告——图像生成正在从专业玩家的工具,真正走向大众日常的创造力助推器。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















