昨天,OpenAI 正式推出 GPT-Image-v2(ChatGPT Images 2.0)。

啊不對,是這張:
本次更新後,所有用戶可以使用上最新的 GPT Image v2 模型,如果你是訂閱了 20刀及以上的付費計劃的用戶,還可以用上帶思考的完全體 GPT Image v2。

這次更新,沒有大張旗鼓的發佈會,但其模型的實際出圖效果,卻迅速在整個圈子,甚至是圈外引起了極高的討論度。
(在此之前,上週v2就在Lmarena盲測了,無敵手的狀態)

這是繼GPT Image 1.5之後的又一次重大迭代,也是 OpenAI 自 Sora 宣佈關閉之後,在視覺領域的一次重要反擊。
現在,OpenAI 帶着 GPT Image v2 殺回來了。
先說最直觀的一點:文字渲染能力大提升。
以前生成帶文字的海報、UI界面、信息圖、菜單、廣告牌的時候,模型經常出現黃 tint 色偏、文字扭曲、亂碼等問題。
現在這些毛病基本沒了。

無論中英文還是其他語言,文字都能清晰、準確、自然地呈現在圖像裏。
手寫文字也不在話下(內容還不是亂寫的):

儘管進步巨大,但官方博客任然寫得很低調:

其次是真實世界理解能力極大提升。
模型對現實物理、佈局、邏輯的理解明顯更強了。
現在它能輕鬆生成完整的信息圖、各種截圖、產品原型、地圖、UI界面等結構化內容,邏輯一致性極高。
這裏我直接讓GPT來生成一張截圖,顯然,這對它來說基本沒有難度:
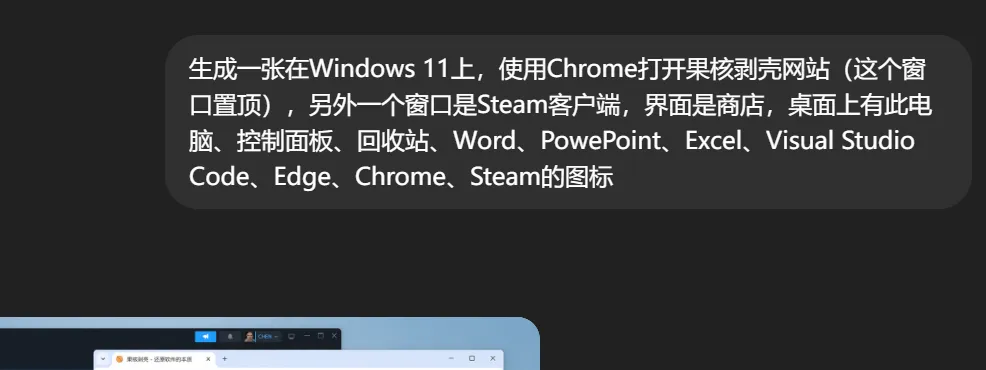
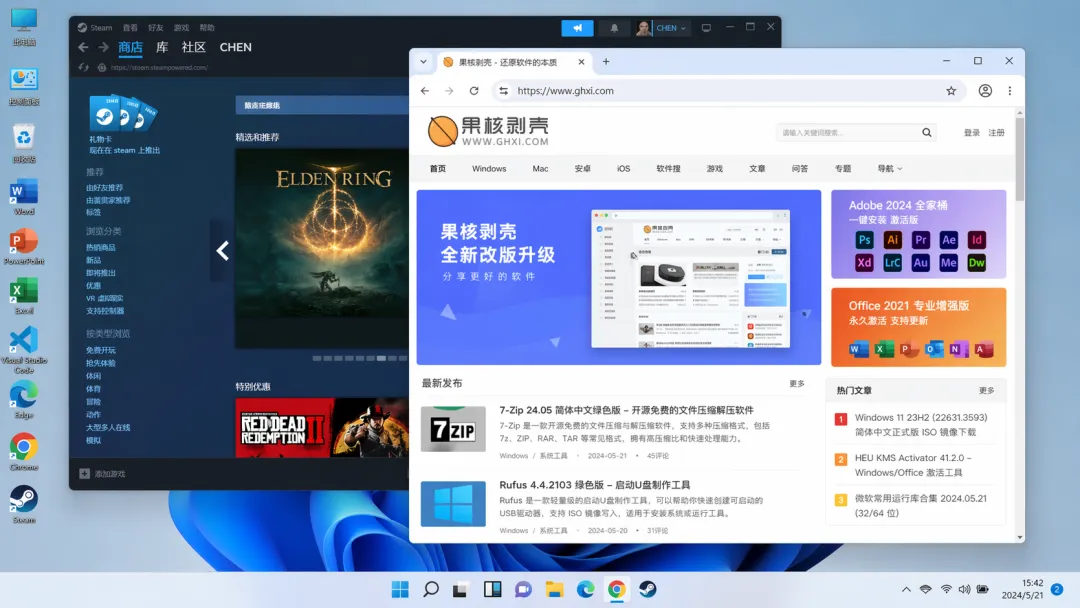
以前需要反覆調整prompt才能勉強接近的效果,現在簡單一段描述就能得到一個比較好的輸出。
最恐怖的一點,是它幾乎不需要複雜的提示詞就能生成高質量圖片。
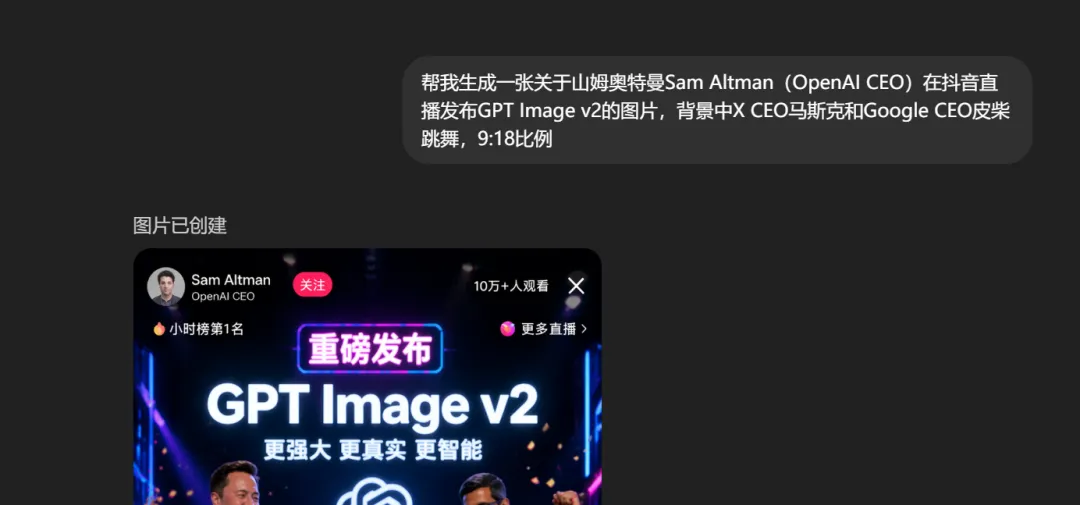
例如本文的第一張,奧特曼直播,也是 Image v2 一句話生成的:
最近潛兵戰鬥爽,也試了試一句話生成潛兵的截圖:

還可以讓牢大賣紅茶:

以前圖像生成還是“Prompt工程”的時代,不會搓高質量prompt的人,給他再好的模型,生成出來的圖片效果也是一言難盡。
現在這個門檻基本消失了——你隨便甩一句自然語言,它就能理解你的意圖,生成邏輯清晰、細節豐富的圖像。
這一點纔是真正把圖像生成從專業玩家遊戲變成大衆日常工具的關鍵變化。
這些實測讓我明顯感覺到,Image v2 在指令遵循和真實世界理解上的進步非常大。
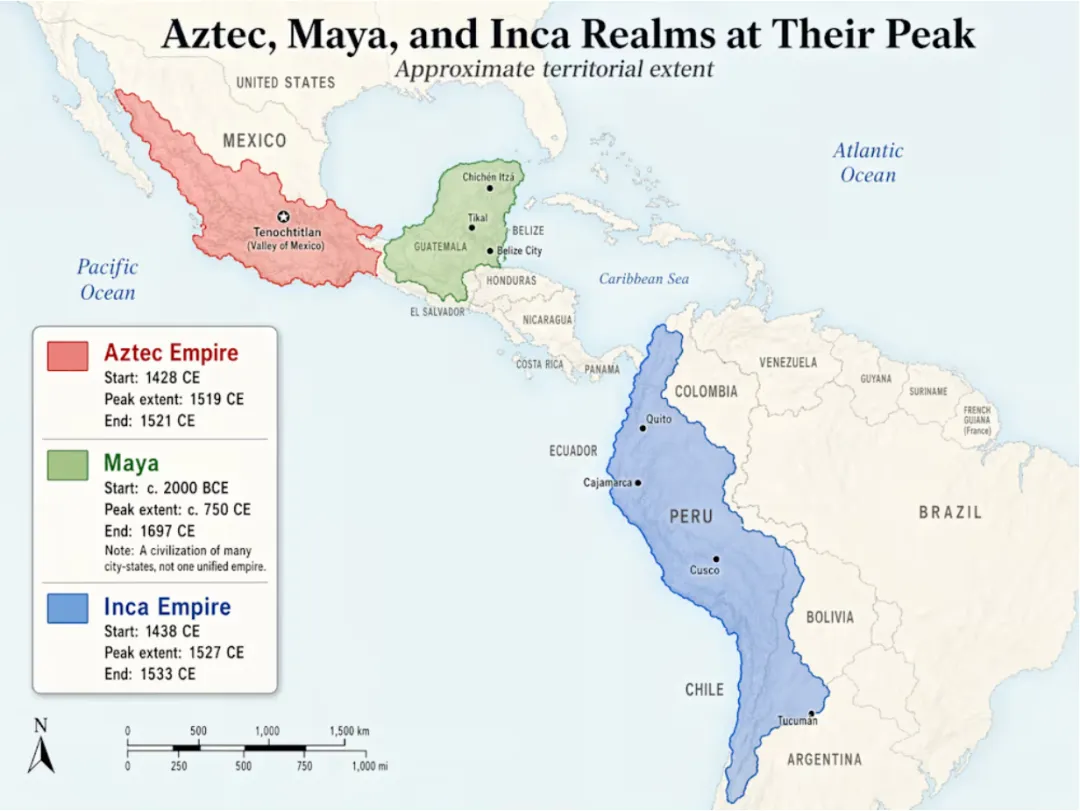
Image v2生成的阿茲特克、瑪雅、印加帝國在其鼎盛期的地圖
門檻降低之後,影響是雙面的。
一方面,普通用戶能更輕鬆地生成高質量圖像,創意門檻大幅下降;
另一方面,惡意用途的風險也隨之而來:假截圖、假廣告、假聊天記錄、假新聞圖片的製作成本會變得極低,辨別難度大幅增加,這對社會、媒體和監管提出了前所未有的要求。(而這,只是我們立馬就能想到的惡意用途之一)
以後這張“截圖”是不是AI生成的,可能真的會成爲一個問題。
從技術競爭的角度看,Imagev2 已經在性能和用戶體驗上樹立了一個新的標杆。
谷歌的香蕉系列,此時又顯得像過時模型一樣
AI還在全速狂奔,Imagev2 也只是在這段時間內領先。
但 Imagev2 的領先,不只是一次迭代,更是一種趨勢的宣告——圖像生成正在從專業玩家的工具,真正走向大衆日常的創造力助推器。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















