
双击支持一下啦,顺便求个电🥰
总而言之就是,游戏体积大和爆显存在NTC普及以后应该是过去式了,如果旧游戏也做适配那就更完美了,4060在1k下可以获得基本不占性能的显存占用降低,2k稍微占一些,显卡性能比4060强的依次影响降低。
开头依然介绍什么是 RTX 神经纹理压缩
RTX 神经纹理压缩(NTC)是一种基于机器学习的纹理(现代游戏的存储空间和显存占用的最大头)压缩与解压缩方案。
在 DirectX 12 中它支持三种运行模式:加载时推理、采样时推理、反馈时推理;在 Vulkan 中不支持反馈时推理,仅开放前两种模式。
——————————————————————
在采样时推理模式下,每个纹理像素会在需要时才被解压。NTC 是确定性算法,并非生成式技术。为减少画面瑕疵,技术会采用 随机纹理过滤(STF)引入随机性,生成过滤后的纹理。
50系架构显卡的点采样纹理过滤速率提升一倍,因此在这类显卡上运行速度尤为出色。
采样时推理是大众认知中神经纹理压缩的核心形态,它能最大幅度降低显存占用,但也会带来一定性能开销,对部分中低端显卡不够友好。——————————————————————
好在低端硬件也有对应的适配方案(下面两个)。——————————————————————
加载时推理会在游戏或地图加载阶段解压 NTC 纹理,并同步转码为块压缩格式(BCn),整个解压过程完全在 GPU 上完成。实际表现上,它的性能与传统块压缩纹理持平,没有额外性能损耗,同时能大幅缩减纹理的磁盘占用与 PCIe 总线传输量。
缺点是相比块压缩纹理,无法进一步降低显存占用。
——————————————————————
反馈时推理借助采样器反馈机制,仅解压渲染当前画面所需的纹理块。该模式是前两者的折中方案,能显著降低显存占用(但幅度不及采样时推理),性能也介于两者之间。
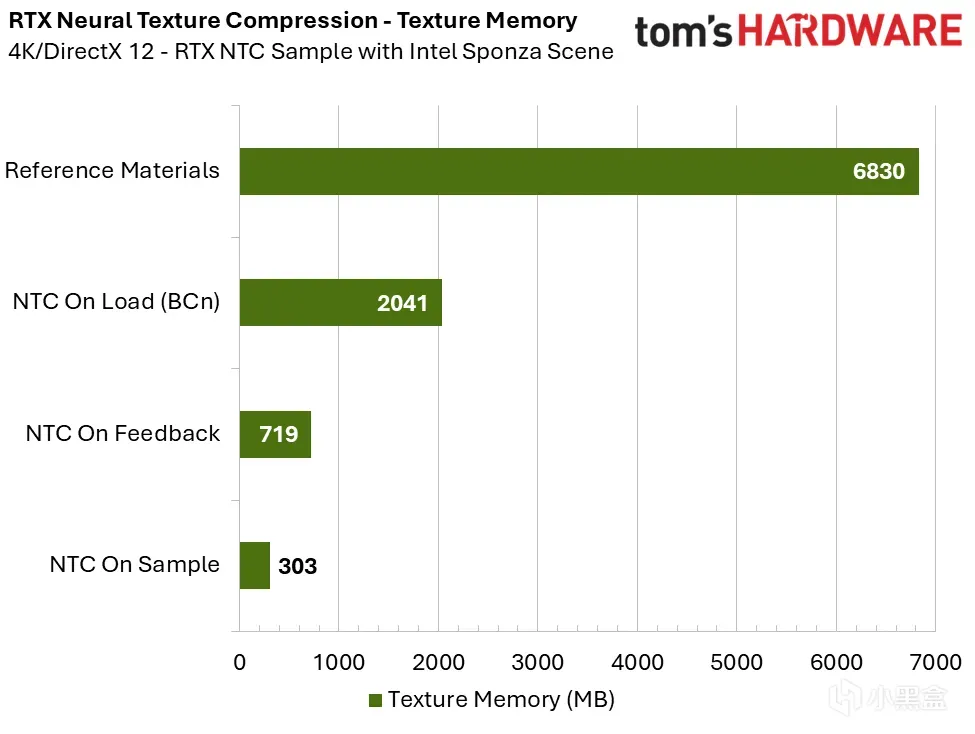
最上为现有渲染,往下依次为加载、反馈、采样时推理
为什么要用神经纹理压缩?
神经纹理压缩的压缩比远高于 BCn 等传统格式,同时支持高通道数材质,单次可处理最多 16 个通道,而传统块压缩仅支持 1–4 通道图像。
实测数据显示,对比转码为块压缩格式的加载时推理模式,采样时推理可将纹理显存需求降低 85%。
不仅如此,采样时推理生成的画面比 BCn 转码纹理更接近原始参考画质,几乎与未压缩纹理完全一致。
不过该模式也存在局限:上述优质画面均在开启 DLSS 的前提下实现。
随机纹理过滤(STF)会引入随机性,若不开启抗锯齿,画面会出现大量噪点。
DLSS 可以完全消除这类噪点,TAA 时间抗锯齿能大幅改善但无法彻底清除。采样时推理强制启用 STF,因此必须搭配抗锯齿(优先 DLSS)才能获得最佳画质。

这项技术优势明显,但性能开销如何?
下面在 GitHub 官方 NTC 示例程序中,对多款显卡进行了测试。
加载时推理将 NTC 纹理转码为 BCn,与传统块压缩相比零性能开销;而采样时推理需要实时执行神经解码,会在所有显卡上产生性能成本,理想情况下这一开销应尽可能小。
——————————————————————
各显卡实测结果
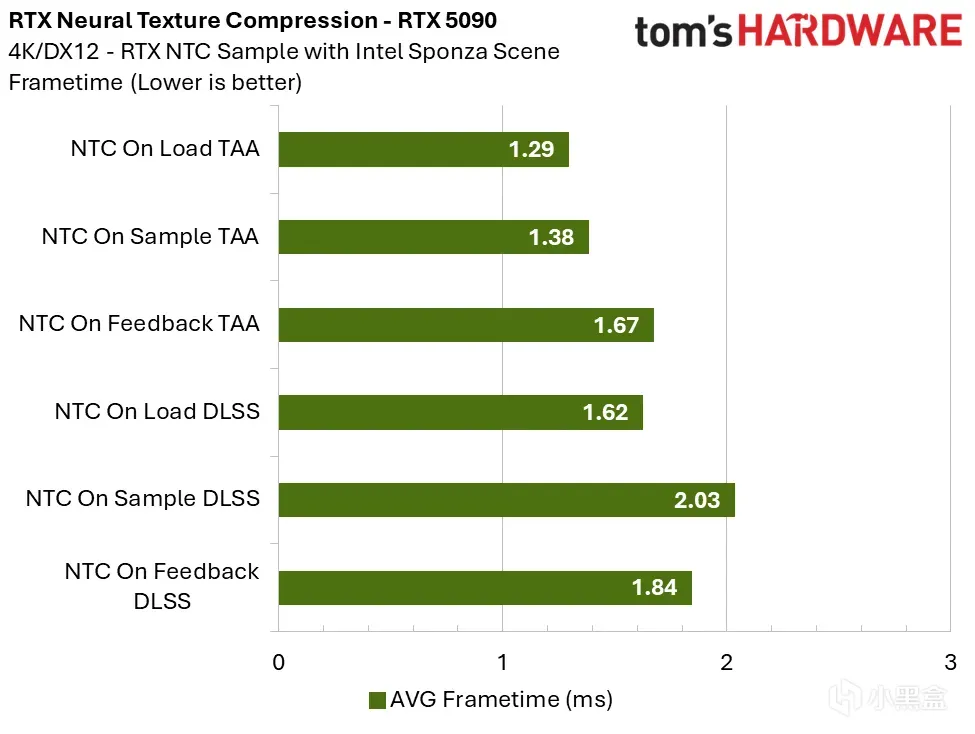
RTX 5090:4K 分辨率下,采样时推理搭配 TAA 的帧时间开销极低;开启 DLSS 会小幅增加张量核心负载,但在真实游戏中,DLSS 低分辨率渲染仍能带来整体性能收益。
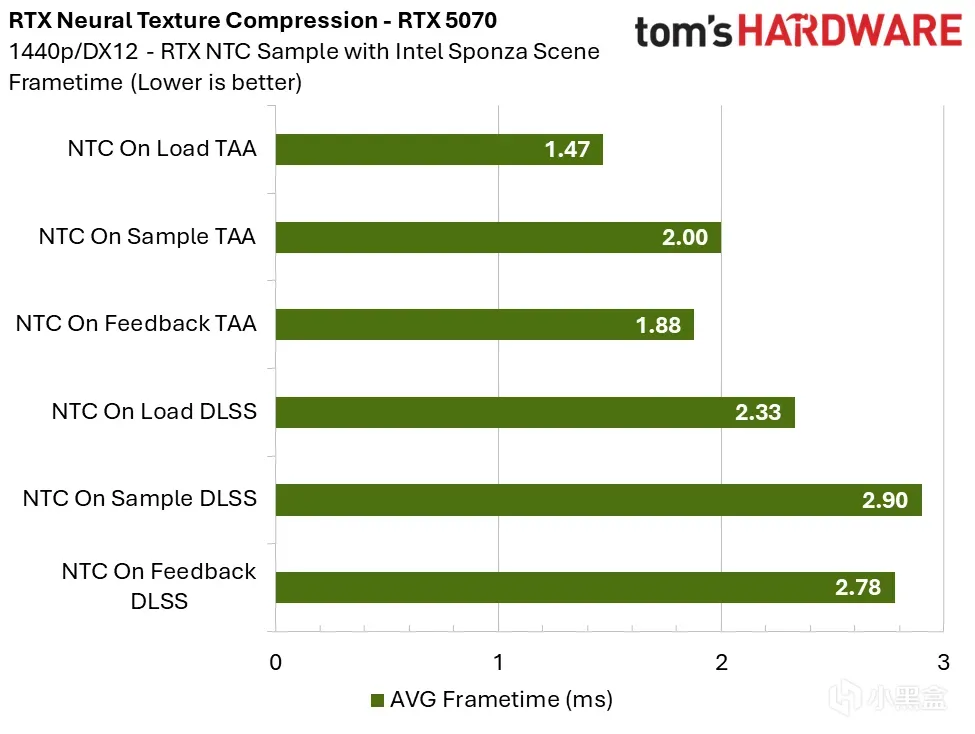
RTX 5070:2K 分辨率下,采样时推理开销约 0.50–0.70ms;4K 下约 1.20ms。
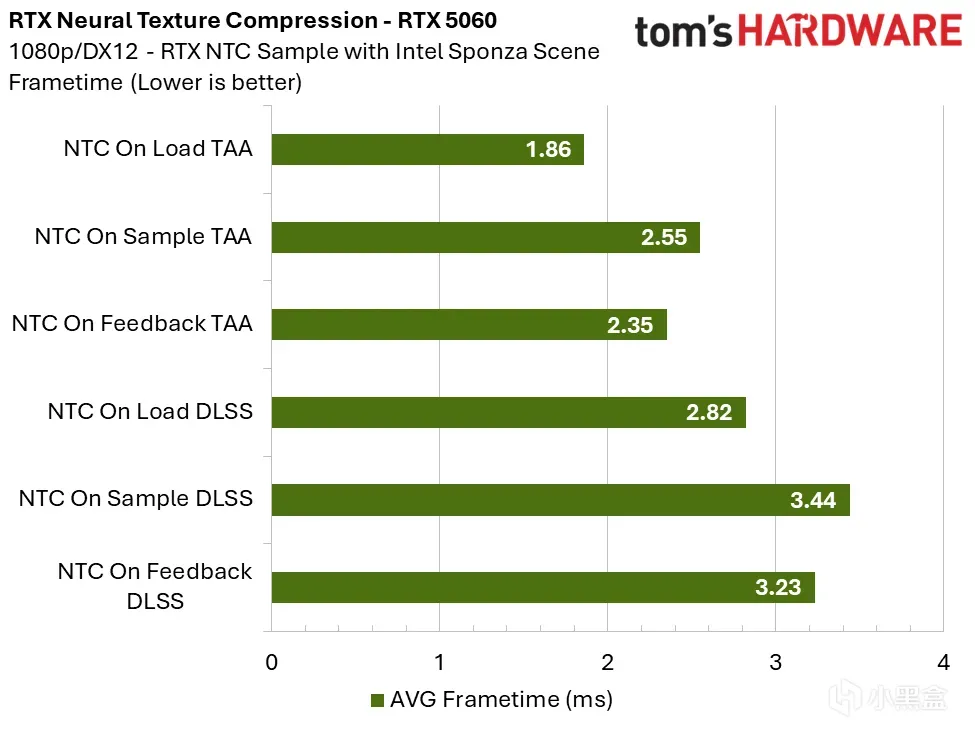
RTX 5060:1080p 下开销 0.60–0.70ms;2K 下超 1ms,4K 下接近 2ms。
RTX 4060 笔记本显卡:1080p 下开销约 0.70–0.85ms,接近 1ms。对于 8GB 显存的笔记本显卡,若显存吃紧、降低纹理画质后帧率仍充足,采样时推理仍有实用价值。
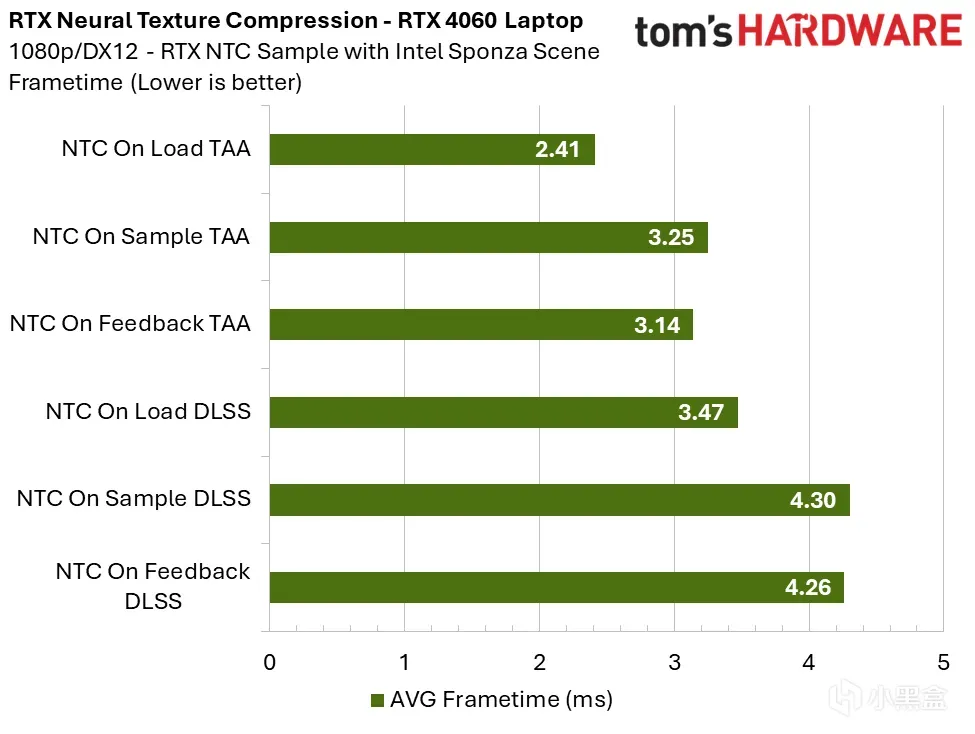
我的注解:
20~40ms 系统总延迟是整条链路的总和,多 1~2ms 几乎感觉不到,但这里是渲染延迟
帧率 ↔ 帧时间 换算
60 帧 = 每帧 16.67ms
144 帧 = 每帧 ~6.94ms
240 帧 = 每帧 ~4.17ms
GPU 渲染一帧本身就只有几毫秒到十几毫秒
为什么多 1ms 就很严重?
因为这 1ms 是纯额外开销,是在原本的渲染时间上硬加的。
144Hz 高刷游戏
GPU 原本渲染一帧需要 7ms
NTC 多加 1ms → 变成 8ms
帧率直接从 144fps → 125fps
直接掉 近 20 帧
4K 3A 游戏,刚好跑 60 帧
原本一帧 16.67ms
多加 1ms → 17.67ms
帧率从 60 → 56.6fps
跌破流畅线
为什么到 2ms 就说 “吃力”?
尤其对 RTX 5060、RTX 4060 这种中端 / 入门卡:它们本身算力就弱,高分辨率(2K/4K)下,渲染一帧本来就接近满载,比如一帧要15~20ms,再加 2ms,帧率掉得更狠。



英伟达 NTC 开发者在YTB评论区的回复:
各模式适配什么显卡?
采样时推理仅适合高端旗舰显卡;加载时推理会转码为 BCn,仅缩减硬盘 / 下载体积,不优化显存。显卡能否流畅运行采样时推理,取决于游戏具体实现(材质通道、着色器复杂度等),英伟达也在持续优化推理效率。
游戏中如何落地 NTC?
游戏可内置 NTC 纹理,提供加载 / 反馈模式与采样模式的选项,玩家根据自身硬件性能选择。
简单判断标准:如果一款游戏因显存不足必须降低纹理画质,但降质后帧率过剩,就非常适合开启采样时推理。
同时游戏无需对所有纹理使用 NTC,可单纹理独立控制,画质损失明显的纹理可保留原始格式。
实际游戏与测试示例的表现差异?
采样时推理明显慢于零开销的加载时推理,但真实游戏有大量不受 NTC 影响的渲染通道,整体帧时间差距会被稀释。同架构显卡的两种模式相对性能差异相近。若显卡显存耗尽,加载时推理完全无效,因为它不会减少工作集显存占用。
随机纹理过滤(STF)的影响
采样时推理强制开启 STF,关闭抗锯齿会出现明显噪点,DLSS 可完全消除,TAA 仅能部分改善;参考模式与加载模式可手动开关 STF。
渲染技术的未来一瞥
神经纹理压缩能在不牺牲画质的前提下实现极高压缩比,部分场景下画质甚至优于传统块压缩格式,不损失性能且大幅缩减游戏体积,同时也支持 AMD、英特尔显卡。(这两家也做了同款技术)
神经纹理压缩注定会在未来实时图形领域扮演关键角色,对未来显卡的规格影响也是决定性的
一如之前评论区的盒友们对3G显存6060的调侃———
但毕竟还有这么多旧游戏,所以最坏的结果应该是硬件显存增长再次放缓,60系和50系同定位显卡显存可能不会有太大变化。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














![内地电影2026一季度&清明档票房反向创纪录[cube_菜doge]你,许可吗?](https://imgheybox1.max-c.com/web/bbs/2026/04/11/835def678e41b5dbd26068609d2ce252.png?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)

