在大模型狂飙突进的时代,我们一直以为,像deepseek、ChatGPT这样的AI助手越聊越聪明,只要喂得够多、聊得够久,它们就能“越聊越懂你”。然而,一项由 Salesforce AI Research、卡内基梅隆大学(CMU)与微软研究院联合发布的最新研究却颠覆了这一常识。
他们在一篇题为《LLMs Get Lost In Multi-Turn Conversation》的论文中揭示:大型语言模型在多轮对话中表现得更差,准确率甚至可能下降 39%。
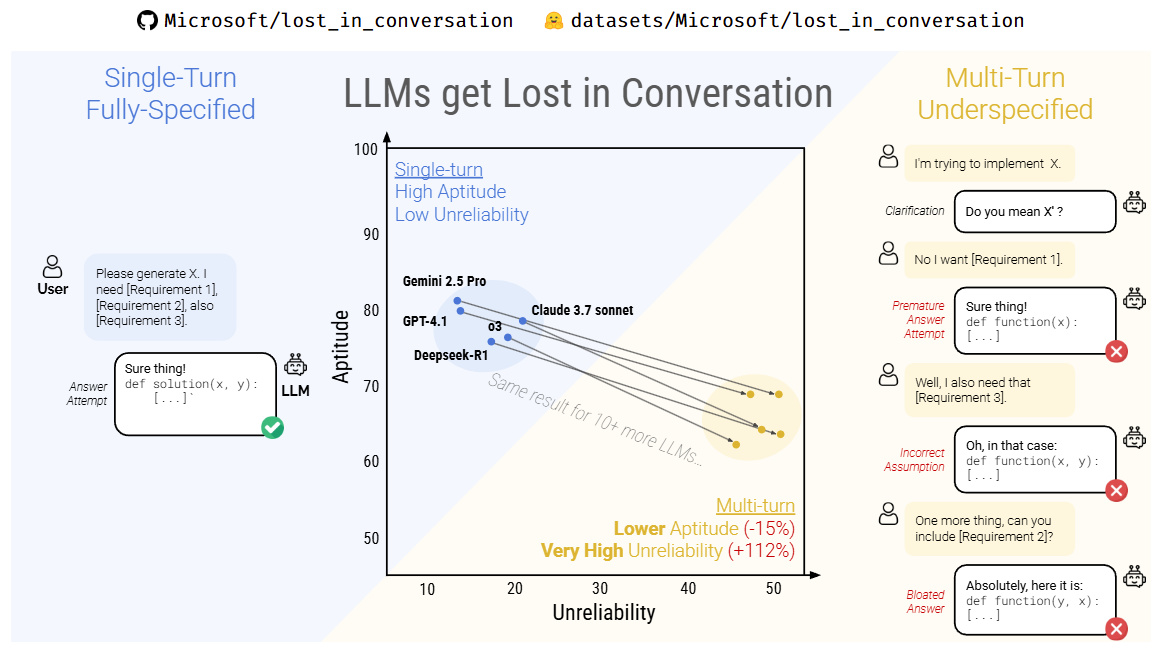
该研究通过系统性实验,模拟了人类与AI进行连续多轮交流的真实场景。结果发现:
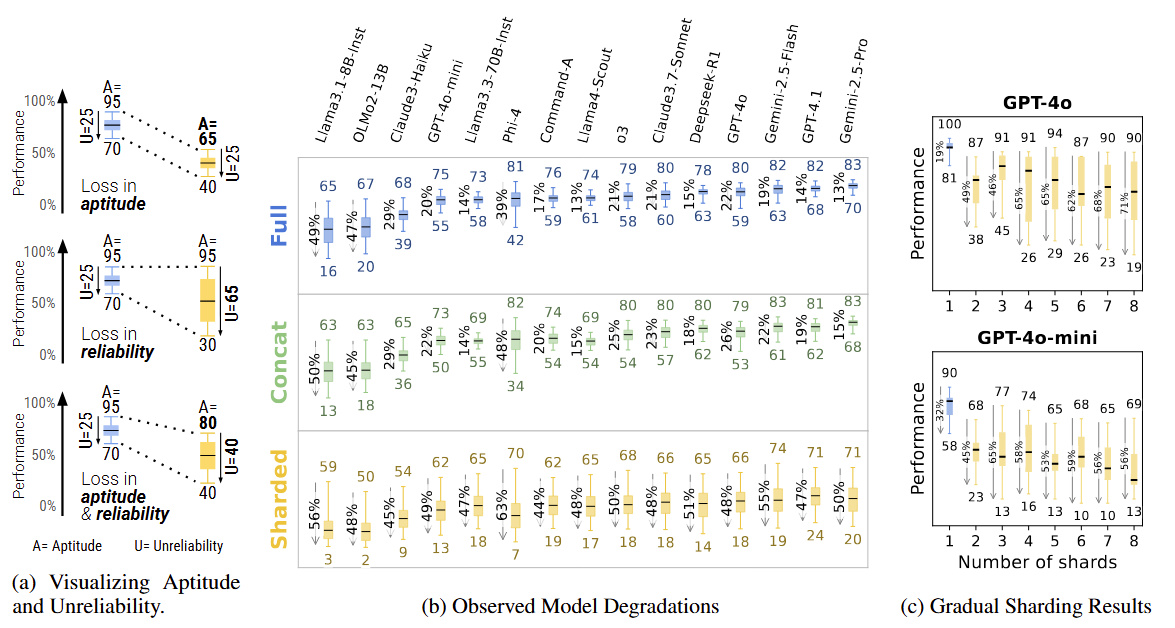
在完成相同任务时,多轮对话中的模型表现明显劣于单轮对话
随着对话轮次增加,模型出现偏差、误解和逻辑跳跃的概率急剧上升
一旦模型在前几轮对话中产生“错误假设”,它很难自我纠偏,而是沿着错误轨道一路跑偏到底。
这种现象,被研究者戏称为,大模型在对话中“迷路"了。
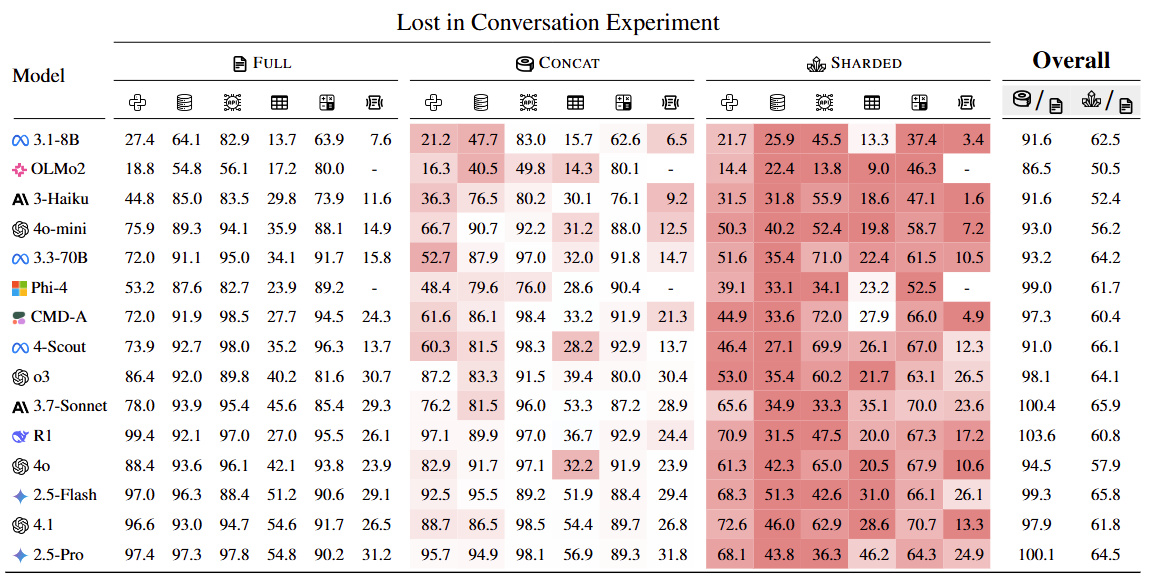
论文进一步指出,当前主流大模型(如deepseek R1、GPT-4、Claude等)在对话初期会建立一种“隐性推理路径”。如果最初对用户意图的判断有误,后续的对话往往不会质疑或修正这个判断,反而会固化并放大它。
简单来说:你越说,它越离谱。
例如,如果你早期的问题语义含糊,模型可能会作出错误理解。哪怕你在后续尝试纠正,它也常常“听不进去”,仍旧基于原始误解继续生成内容,甚至给出看似自洽却南辕北辙的结论。
论文来源:https://arxiv.org/pdf/2505.06120
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















