在大模型狂飆突進的時代,我們一直以爲,像deepseek、ChatGPT這樣的AI助手越聊越聰明,只要喂得夠多、聊得夠久,它們就能“越聊越懂你”。然而,一項由 Salesforce AI Research、卡內基梅隆大學(CMU)與微軟研究院聯合發佈的最新研究卻顛覆了這一常識。
他們在一篇題爲《LLMs Get Lost In Multi-Turn Conversation》的論文中揭示:大型語言模型在多輪對話中表現得更差,準確率甚至可能下降 39%。
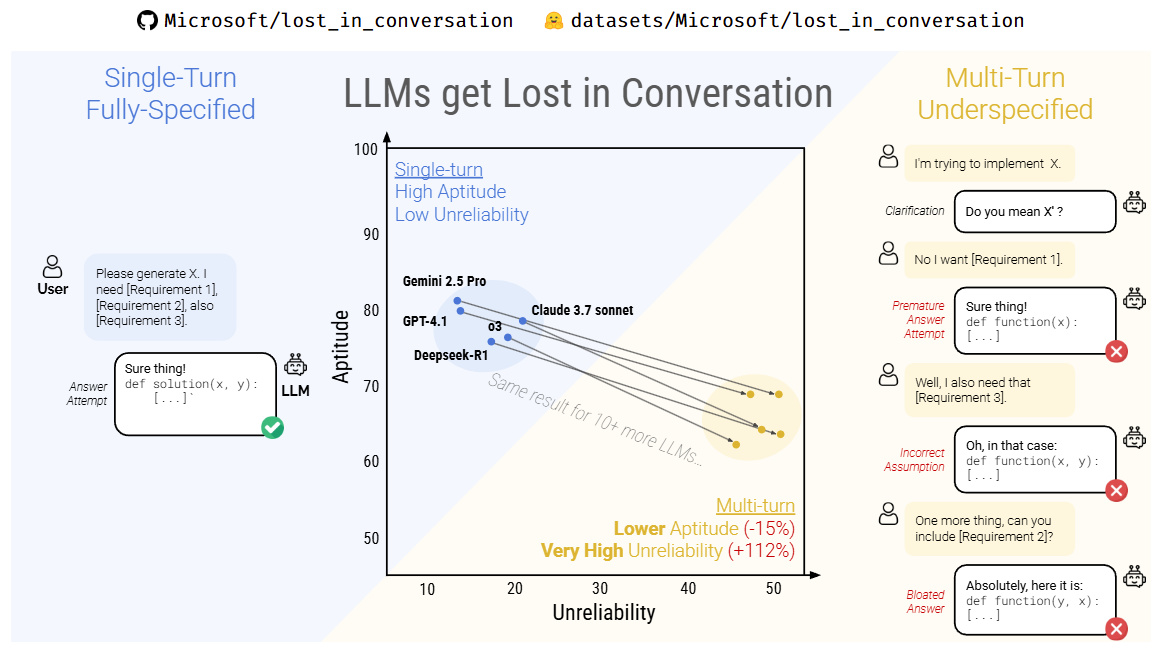
該研究通過系統性實驗,模擬了人類與AI進行連續多輪交流的真實場景。結果發現:
在完成相同任務時,多輪對話中的模型表現明顯劣於單輪對話
隨着對話輪次增加,模型出現偏差、誤解和邏輯跳躍的概率急劇上升
一旦模型在前幾輪對話中產生“錯誤假設”,它很難自我糾偏,而是沿着錯誤軌道一路跑偏到底。
這種現象,被研究者戲稱爲,大模型在對話中“迷路"了。
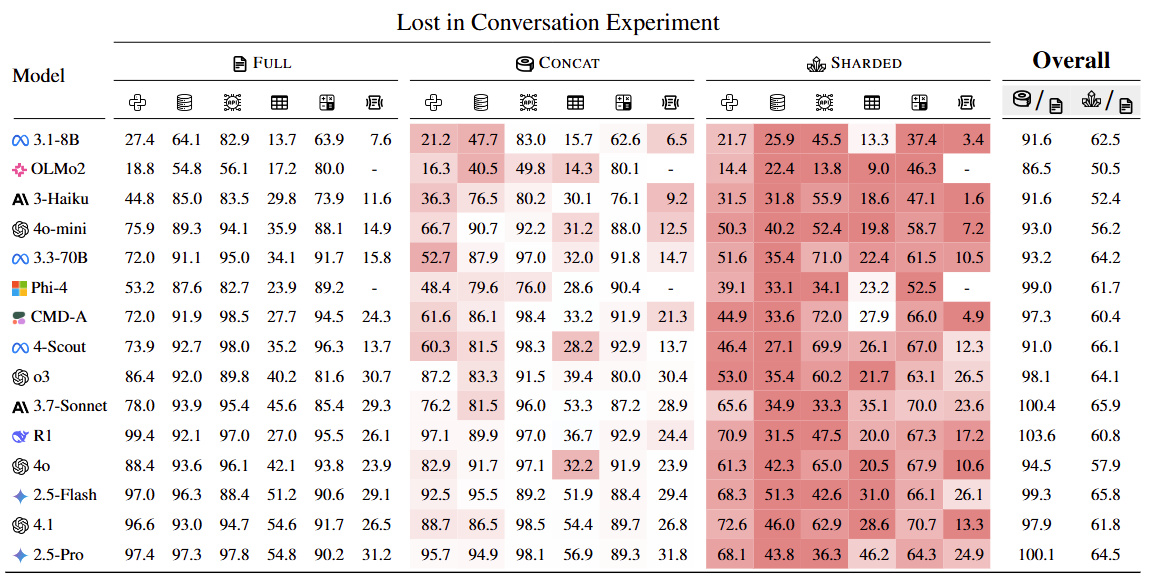
論文進一步指出,當前主流大模型(如deepseek R1、GPT-4、Claude等)在對話初期會建立一種“隱性推理路徑”。如果最初對用戶意圖的判斷有誤,後續的對話往往不會質疑或修正這個判斷,反而會固化並放大它。
簡單來說:你越說,它越離譜。
例如,如果你早期的問題語義含糊,模型可能會作出錯誤理解。哪怕你在後續嘗試糾正,它也常常“聽不進去”,仍舊基於原始誤解繼續生成內容,甚至給出看似自洽卻南轅北轍的結論。
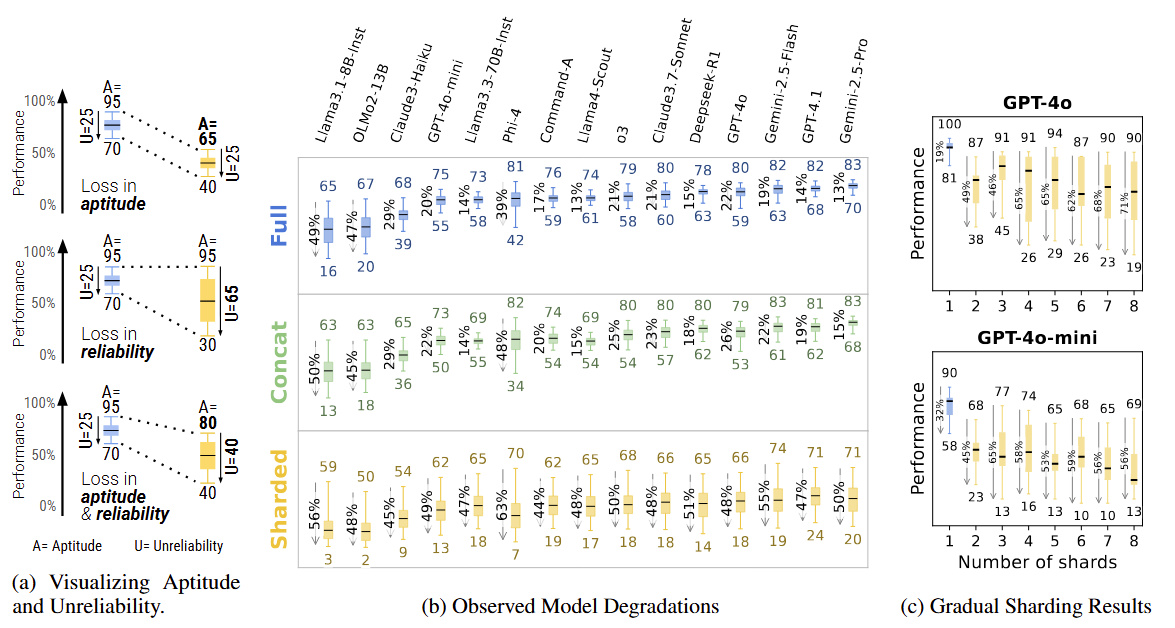
論文來源:https://arxiv.org/pdf/2505.06120
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com










![[更新中]2025年TGA遊戲獲獎者公佈](https://imgheybox1.max-c.com/bbs/2025/11/17/61a8c589e82b3c57915bbb69a822828d.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)





