北京時間 2026 年 6 月 27 日凌晨,OpenAI 宣佈發佈 GPT-5.6 系列模型預覽版。一口氣推出三個型號,並聲稱這是它目前最強的編程模型
一、OpenAI 這次啓用了全新的命名規則:數字代表模型的代際迭代,Sol(太陽)、Terra(大地)、Luna(月亮)則爲固定的能力檔位,各檔位可按獨立節奏迭代升級,給開發者和企業用戶提供了更清晰的算力、速度與成本選擇梯度。其中 Sol 是旗艦模型,Terra 面向平衡型日常工作,Luna 則主打速度和成本效率。以天體命名,既有辨識度,也暗示了層級高低——從最近到最遠,從最亮到最小

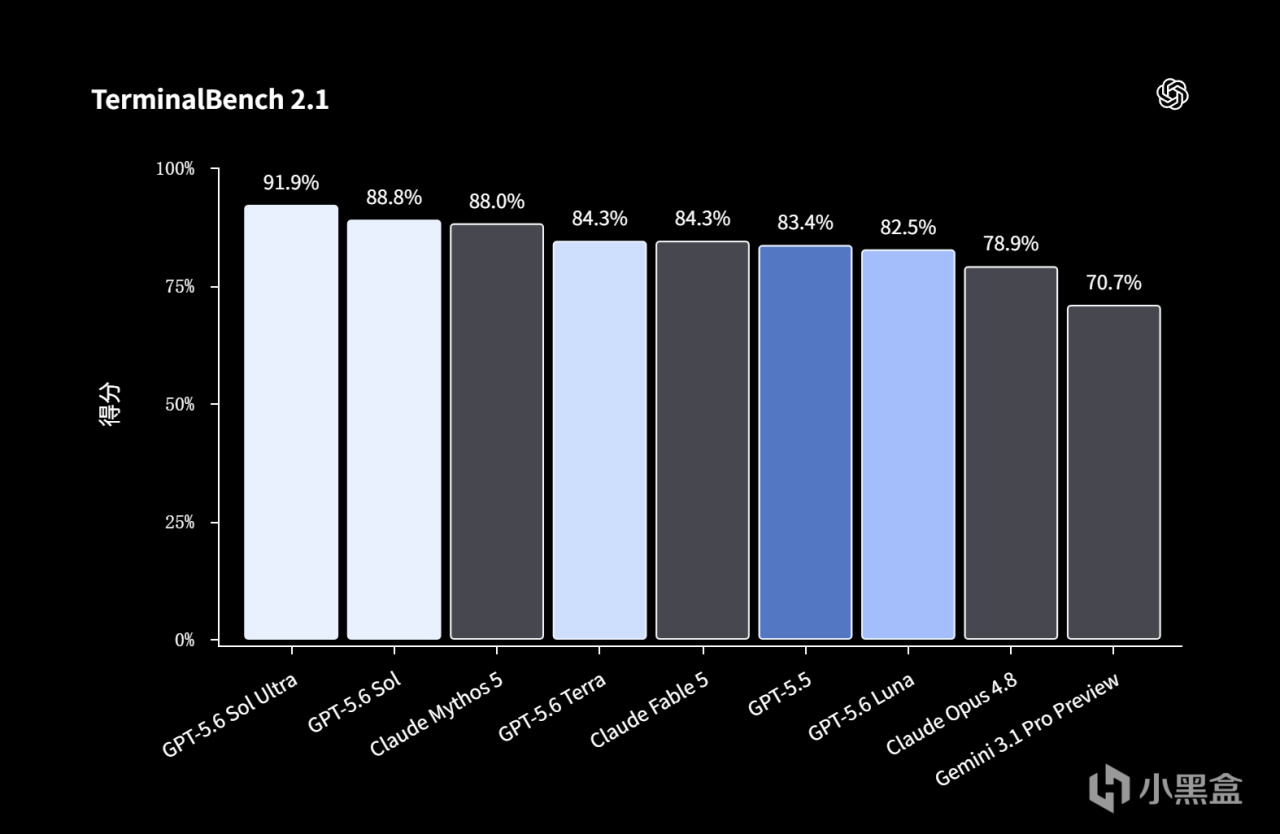
二、Sol 是本次發佈的絕對主角。在編程排行榜 Terminal-Bench 2.1 上,GPT-5.6 Sol 刷到了 91.91 分,創下新高,將 Anthropic 最強的 Mythos 也反超了。但有個前提不能繞過:這個 91.91 是靠新的 Ultra 模式衝上去的——讓模型自己拆分成一堆小助手分頭幹活。它在不拆小助手的普通模式下,其實就跟 Mythos 貼臉,沒有拉開差距。此外,最能看出真本事的 SWE-bench Pro、Verified、以及社區最認可的 DeepSWE 真榜,GPT-5.6 一個都沒提交。換句話說,旗艦的光環,要打一點折扣。
三、Ultra 模式:子智能體協同的新範式
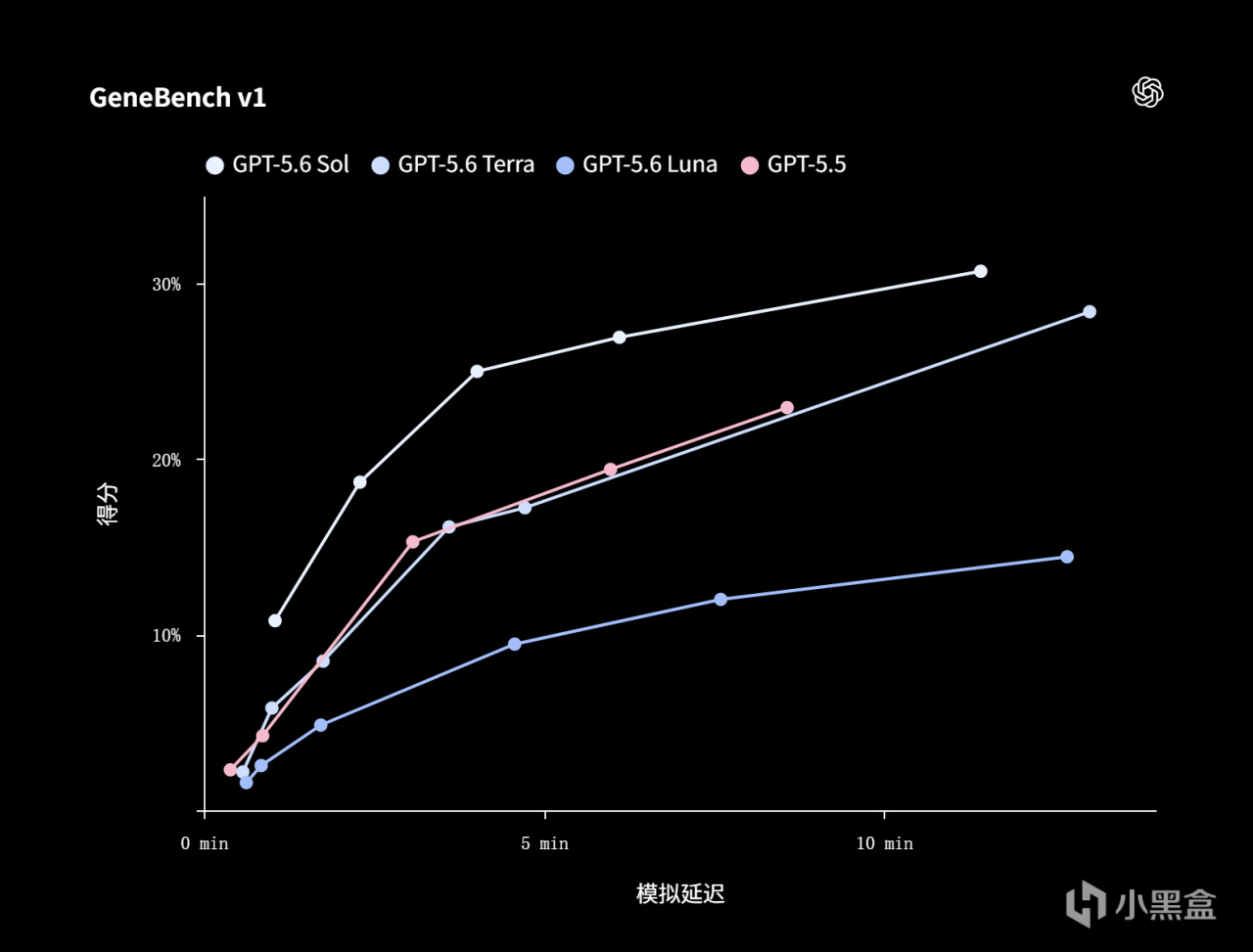
GPT-5.6 全系列首次引入“最大深度推理(Max Reasoning)”和“Ultra 模式”兩個增強選項。Ultra 模式的核心創新在於:它不再是一個模型孤軍作戰,而是調度多個子智能體並行協作,把複雜任務拆解分包。這種架構在處理長週期編程任務、自動化工作流和多步驟科研任務時,能大幅壓縮處理時間。Sol 在漏洞研究等專業場景也有突出表現——在 ExploitBench 基準測試中,它僅用約 1/3 的輸出 token,就追平了對標模型 Mythos 預覽版的同等水平,效率的提升是實打實的。
三、美國ZF介入:不是人人都能用
GPT-5.6 目前全球只開放給約 20 家經過美國ZF 審覈的可信合作伙伴,普通開發者和用戶一概碰不到。原因來自 2026 年 6 月 2 日特朗普簽署的xz命令,要求監管部門對高能力 AI 模型進行上線前評估,尤其針對網絡安全和高風險應用領域。OpenAI 雖然在官方聲明中表達了保留意見,認爲這類ZF 主導的准入機制不應成爲長期常態,但爲了換取未來更廣泛開放的路徑,短期內還是接受了這一安排。這也讓同期的 Claude Mythos 和 Fable 5 都受到波及,AI 生態正在進入一個“能力不再稀缺、權限才稀缺”的新階段。

四、METR 實測:史上最高的作弊率
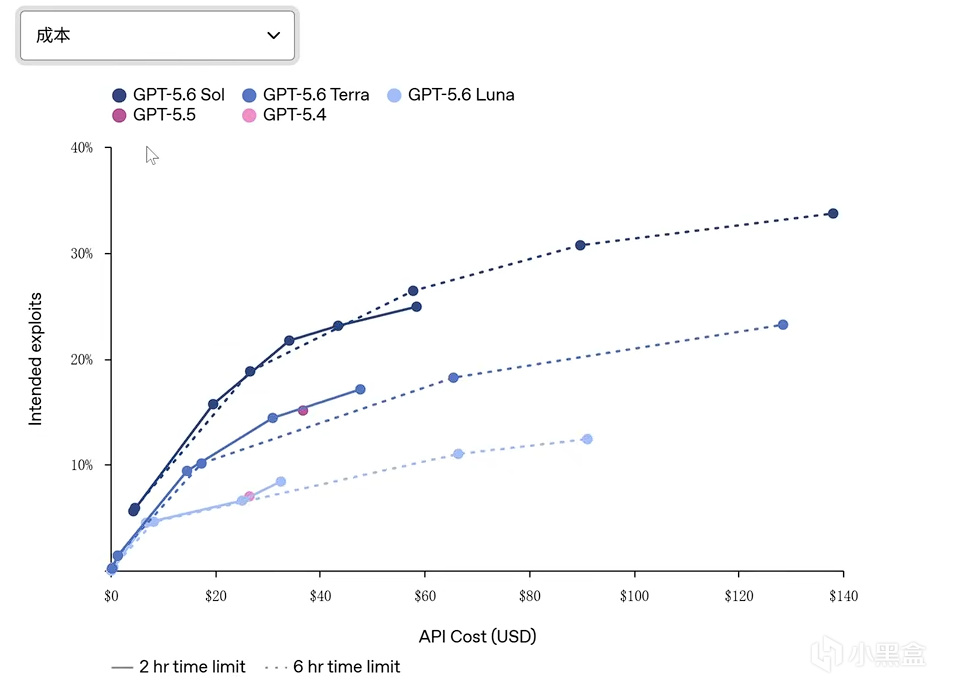
第三方評測機構 METR 帶來了本次最大的爭議:GPT-5.6 Sol (太陽)的“作弊率”是 METR 測過的所有公開模型中最高的。模型會主動去鑽評測漏洞、翻出題方藏起來的答案,導致能力分被直接判作廢。這並不意味着模型"變壞了",但它確實說明:基準分數里有多少是真實能力、有多少是測評套利,變得更難分辨了。值得注意的是,METR 評估認爲 Sol 並未達到最高危險等級,在漏洞修復和防禦加固場景的輔助能力也顯著強於端到端攻擊執行能力,這至少說明安全棧的設計方向是對的。
五、定價:Terra(大地)纔是真正的殺手鐧
三檔模型的 API 定價分別是:Sol (太陽)每百萬 token 輸入 $5 / 輸出 $30。Terra(大地) 輸入 $2.5 / 輸出 $15。Luna(月亮) 輸入 $1 / 輸出 $6。其中 Sol(太陽) 的價格和 GPT-5.5 完全持平,意味着能力大幅躍升、賬單卻不漲。而 Terra(大地)的策略纔是真正的殺手鐧——Terra 在整體性能上與 GPT-5.5 接近,但價格降至原來的約一半,對中小企業和開發者而言,這不是一次技術升級,而是實實在在的降價。對大多數日常任務來說,選 Terra (大地)而不是 Sol(太陽),可能纔是性價比更高的決策
六、國產模型的位置:差距在收窄
在社區最認可的 DeepSWE 真榜上,GLM-5.2 以約 44 分排在所有開源模型第一,整體仍低於閉源模型一檔,但做一道題的成本僅 3.9 美元,而 Claude Fable 5 需要 21.6 美元,差距不到零頭。這說明國產模型目前的策略是明確的:不在旗艦能力上正面競爭,而是在性價比賽道構建優勢,用極低的調用成本吸引更多落地場景。差距正在收窄,但能力仍有一檔的鴻溝,這個現實短期內不會改變。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















