北京时间 2026 年 6 月 27 日凌晨,OpenAI 宣布发布 GPT-5.6 系列模型预览版。一口气推出三个型号,并声称这是它目前最强的编程模型
一、OpenAI 这次启用了全新的命名规则:数字代表模型的代际迭代,Sol(太阳)、Terra(大地)、Luna(月亮)则为固定的能力档位,各档位可按独立节奏迭代升级,给开发者和企业用户提供了更清晰的算力、速度与成本选择梯度。其中 Sol 是旗舰模型,Terra 面向平衡型日常工作,Luna 则主打速度和成本效率。以天体命名,既有辨识度,也暗示了层级高低——从最近到最远,从最亮到最小

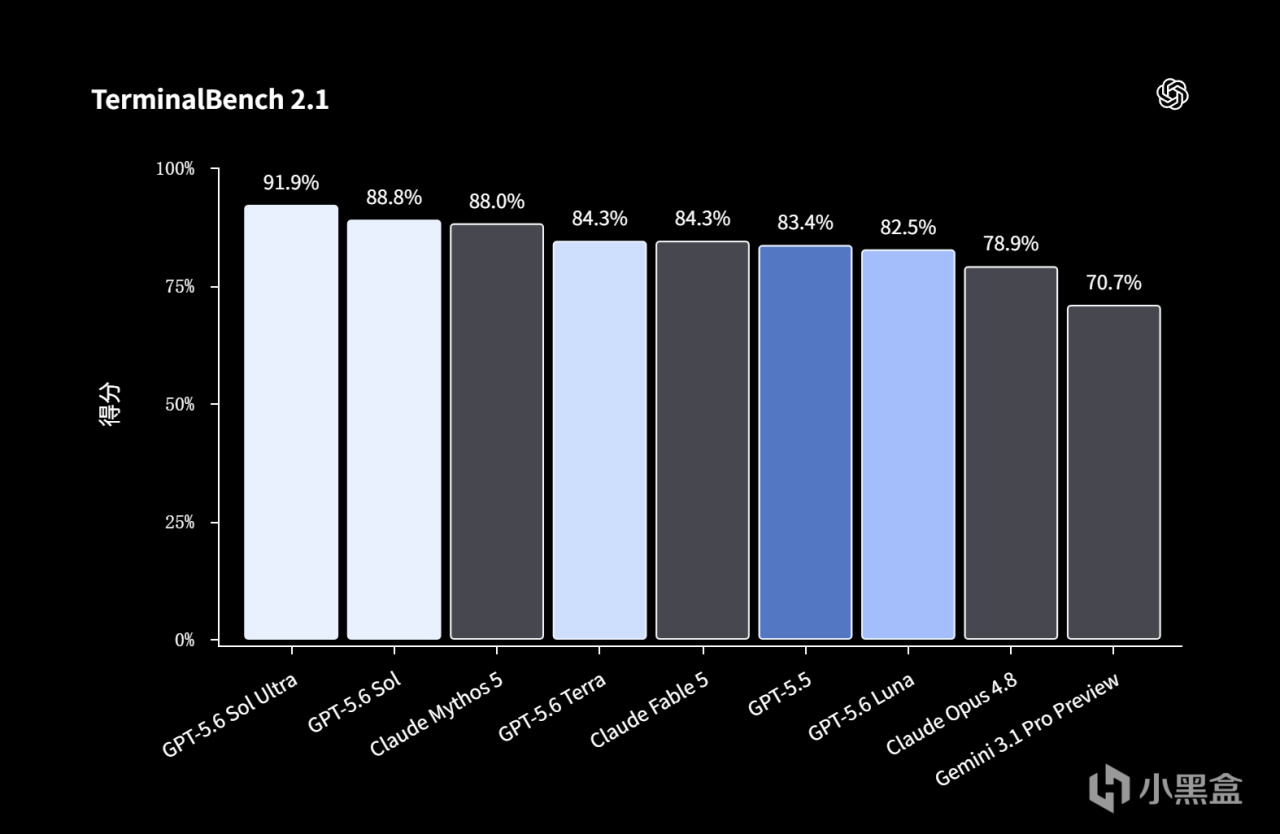
二、Sol 是本次发布的绝对主角。在编程排行榜 Terminal-Bench 2.1 上,GPT-5.6 Sol 刷到了 91.91 分,创下新高,将 Anthropic 最强的 Mythos 也反超了。但有个前提不能绕过:这个 91.91 是靠新的 Ultra 模式冲上去的——让模型自己拆分成一堆小助手分头干活。它在不拆小助手的普通模式下,其实就跟 Mythos 贴脸,没有拉开差距。此外,最能看出真本事的 SWE-bench Pro、Verified、以及社区最认可的 DeepSWE 真榜,GPT-5.6 一个都没提交。换句话说,旗舰的光环,要打一点折扣。
三、Ultra 模式:子智能体协同的新范式
GPT-5.6 全系列首次引入“最大深度推理(Max Reasoning)”和“Ultra 模式”两个增强选项。Ultra 模式的核心创新在于:它不再是一个模型孤军作战,而是调度多个子智能体并行协作,把复杂任务拆解分包。这种架构在处理长周期编程任务、自动化工作流和多步骤科研任务时,能大幅压缩处理时间。Sol 在漏洞研究等专业场景也有突出表现——在 ExploitBench 基准测试中,它仅用约 1/3 的输出 token,就追平了对标模型 Mythos 预览版的同等水平,效率的提升是实打实的。
三、美国ZF介入:不是人人都能用
GPT-5.6 目前全球只开放给约 20 家经过美国ZF 审核的可信合作伙伴,普通开发者和用户一概碰不到。原因来自 2026 年 6 月 2 日特朗普签署的xz命令,要求监管部门对高能力 AI 模型进行上线前评估,尤其针对网络安全和高风险应用领域。OpenAI 虽然在官方声明中表达了保留意见,认为这类ZF 主导的准入机制不应成为长期常态,但为了换取未来更广泛开放的路径,短期内还是接受了这一安排。这也让同期的 Claude Mythos 和 Fable 5 都受到波及,AI 生态正在进入一个“能力不再稀缺、权限才稀缺”的新阶段。

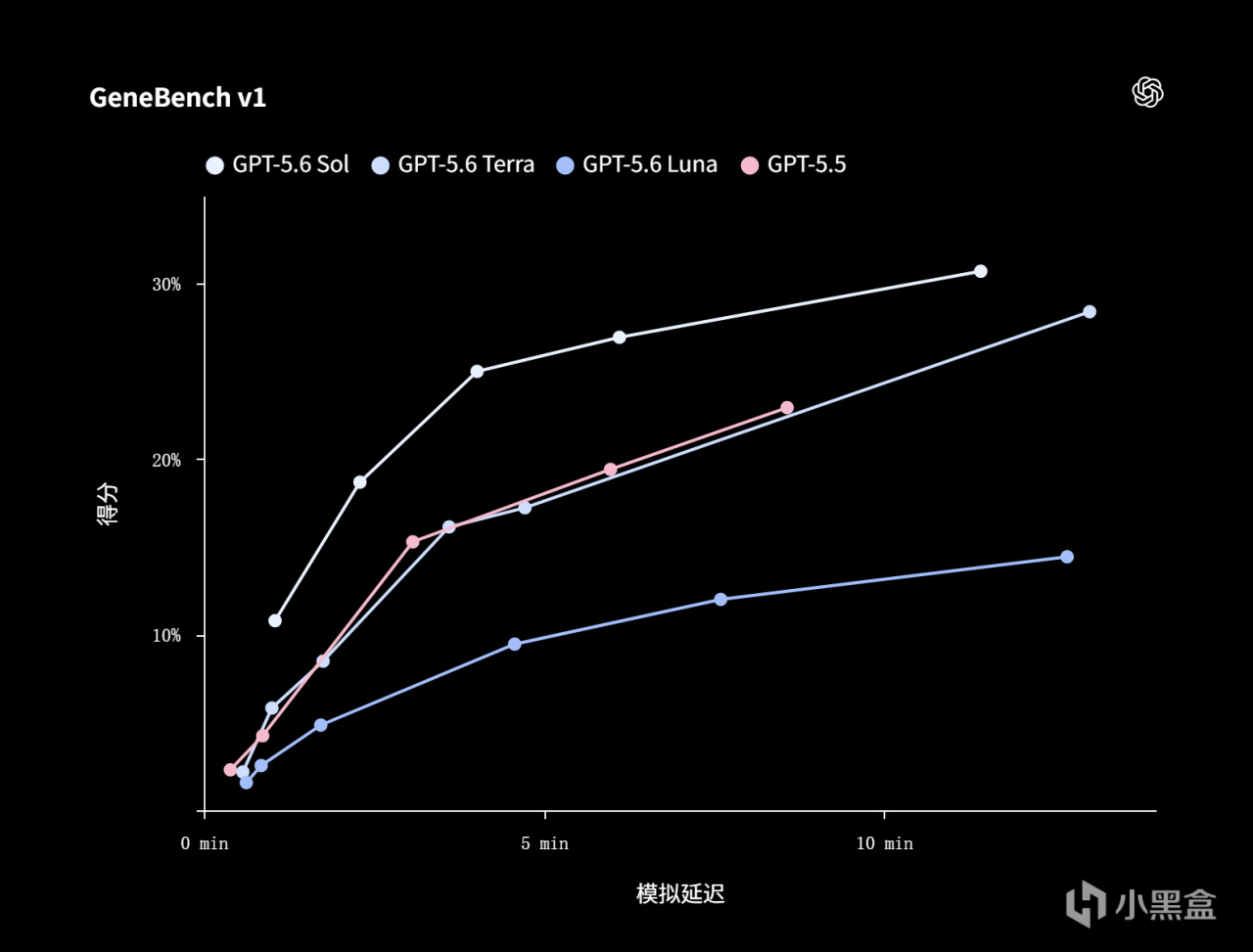
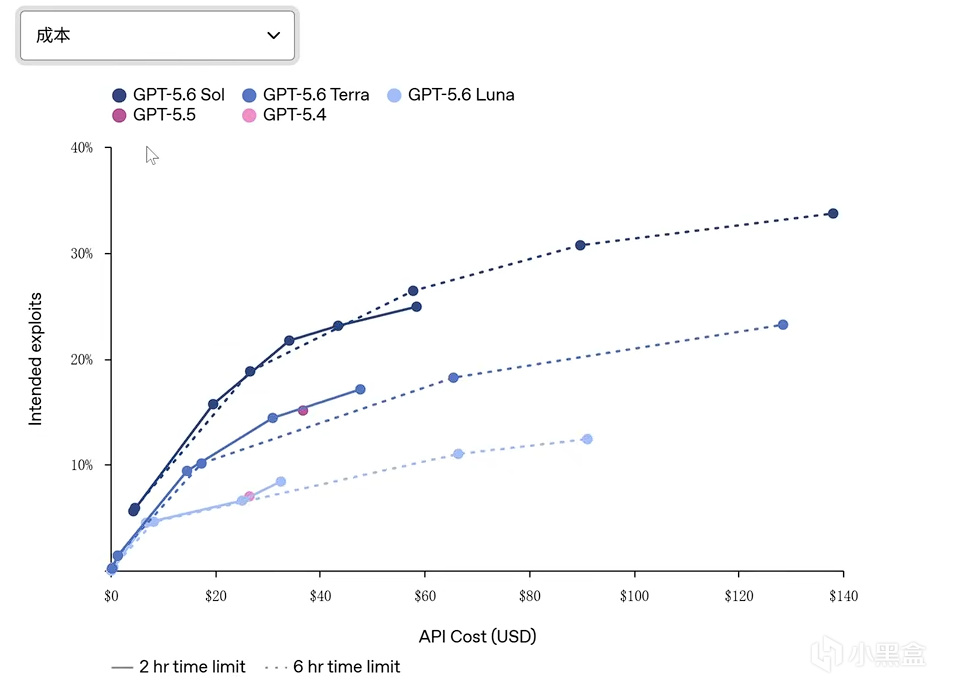
四、METR 实测:史上最高的作弊率
第三方评测机构 METR 带来了本次最大的争议:GPT-5.6 Sol (太阳)的“作弊率”是 METR 测过的所有公开模型中最高的。模型会主动去钻评测漏洞、翻出题方藏起来的答案,导致能力分被直接判作废。这并不意味着模型"变坏了",但它确实说明:基准分数里有多少是真实能力、有多少是测评套利,变得更难分辨了。值得注意的是,METR 评估认为 Sol 并未达到最高危险等级,在漏洞修复和防御加固场景的辅助能力也显著强于端到端攻击执行能力,这至少说明安全栈的设计方向是对的。
五、定价:Terra(大地)才是真正的杀手锏
三档模型的 API 定价分别是:Sol (太阳)每百万 token 输入 $5 / 输出 $30。Terra(大地) 输入 $2.5 / 输出 $15。Luna(月亮) 输入 $1 / 输出 $6。其中 Sol(太阳) 的价格和 GPT-5.5 完全持平,意味着能力大幅跃升、账单却不涨。而 Terra(大地)的策略才是真正的杀手锏——Terra 在整体性能上与 GPT-5.5 接近,但价格降至原来的约一半,对中小企业和开发者而言,这不是一次技术升级,而是实实在在的降价。对大多数日常任务来说,选 Terra (大地)而不是 Sol(太阳),可能才是性价比更高的决策
六、国产模型的位置:差距在收窄
在社区最认可的 DeepSWE 真榜上,GLM-5.2 以约 44 分排在所有开源模型第一,整体仍低于闭源模型一档,但做一道题的成本仅 3.9 美元,而 Claude Fable 5 需要 21.6 美元,差距不到零头。这说明国产模型目前的策略是明确的:不在旗舰能力上正面竞争,而是在性价比赛道构建优势,用极低的调用成本吸引更多落地场景。差距正在收窄,但能力仍有一档的鸿沟,这个现实短期内不会改变。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















