Google 這次算是直接給開源社區投下了一顆炸彈,
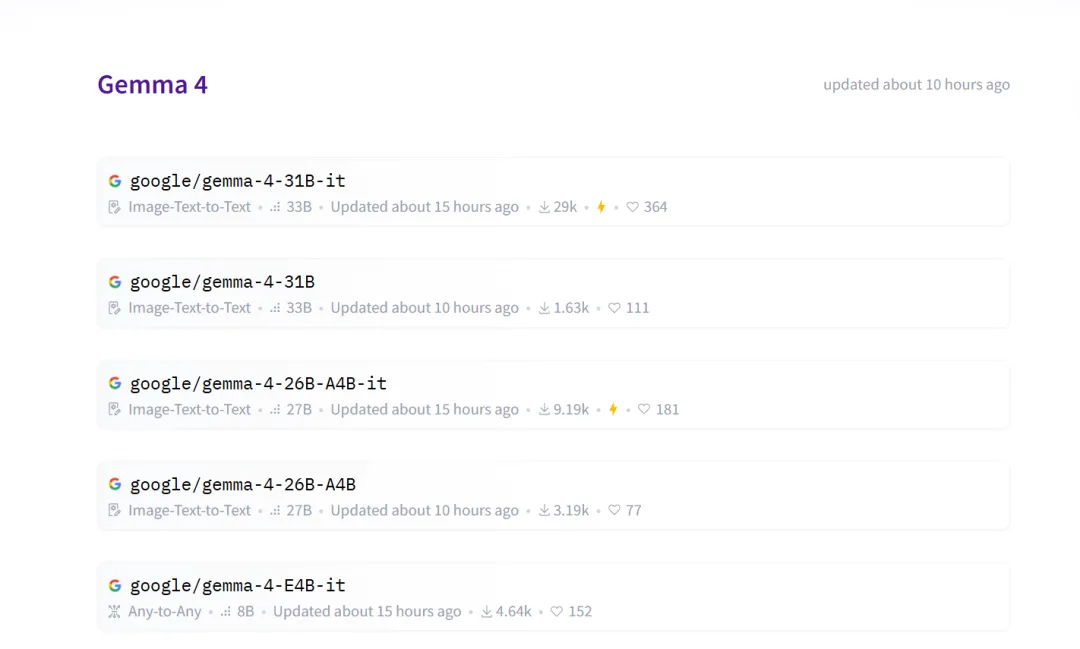
4月2日,今天凌晨,Google 推出了 Gemma 4 系列,一次性推出四個規格:

E2B、E4B、26B A4B MoE、31B Dense。
從最輕量的手機端側,到高性能GPU和工作站,全覆蓋。
並且,這次 Google 把開源許可證直接切換成了 Apache 2.0,對商用也很友好。顯然,從 Google 這次的陣仗來看,他們是重視起了 Gemma 的開源的生態。

這次的 Gemma 4 系列中,最讓人眼前一亮的是那兩款小模型。
E2B 和 E4B 有效參數分別只有 2.3B 和 4.5B,卻支持原生音頻輸入,還能跑 Agent工作流、函數調用、結構化輸出等。
意思就是,以後普通安卓手機稍微操作操作,就能本地跑一個真正能幹活的AI助手,不用每次都連雲端。
大模型這邊也給力。
26B MoE 和 31B Dense 在 Arena AI 開放模型榜單分別排到第6和第3。
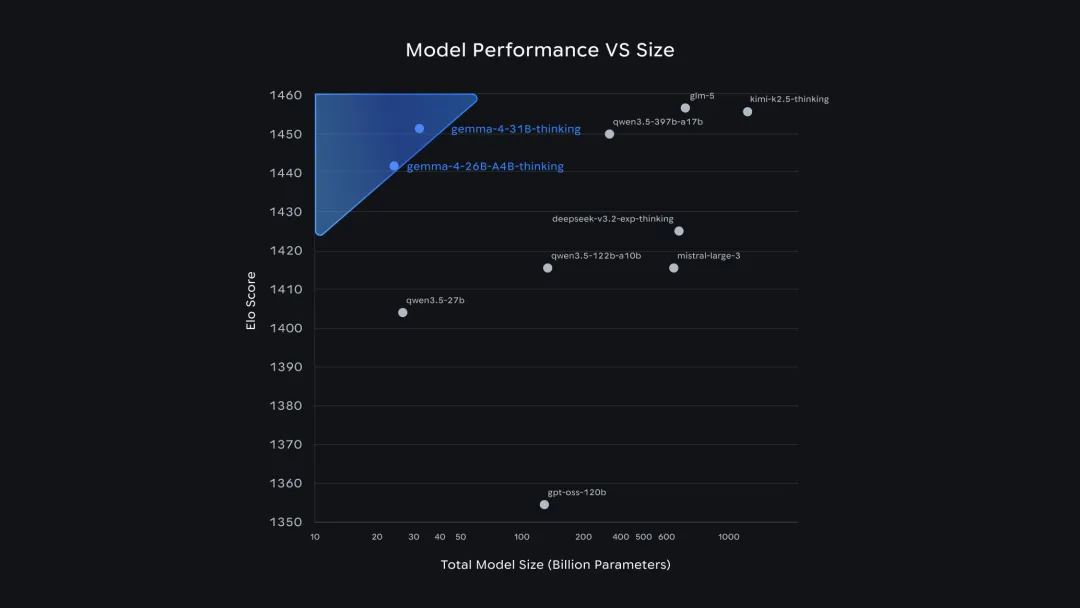
同時其上下文窗口分別達到了 128K 和 256K,在編程、推理、多模態處理能力都拉滿。
Google 這次爲了方便開發者使用,直接把它們扔到Hugging Face、Ollama、Vertex AI Model Garden等社區,隨便拉取。
Demis Hassabis(Google DeepMind聯合創始人兼 CEO)親自下場發帖,用的詞是“best open models in the world for their respective sizes(全世界最佳開源模型,大小均有)”。
GoogleDeepMind和Google官方賬號也同步推文,陣仗不小。
再說這次 Gemma 切換到Apache 2.0,這是 Gemma 系列最重要的一次轉變。

以前還有各種自定義限制,現在徹底放開,開發者可以隨便商用、修改、分發。
Google 這次明顯是衝着本地AI生態去的,以後不管是做手機端Agent、筆記本本地工具,還是企業內部部署,Google 爲大家提供了新的選擇。
Gemma4 31B Dense在筆記本GPU上處理複雜推理任務時,表現已經能和一些閉源大模型正面剛。
Google這波操作,把本地AI的門檻又往下拉了一大截。
以前大家總覺得頂級開源模型離手機還很遠,現在 E2B/E4B 直接把多模態Agent塞進了口袋。
當然,可能有人會想,在具體的模型上一向不太喜歡搞開源的 Google,這次爲什麼突然這麼大方?是真心想把開源生態做大,還是爲了搶佔生態位?
不管答案是什麼,但眼下的結果都一樣——普通用戶和開發者能用到的本地AI能力,又上了一個臺階。
Gemma 4 四連發,把“手機也能跑頂級開源AI”這件事變成了現實。
接下來就看開發者怎麼把這些模型真正用起來了。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















