Google 这次算是直接给开源社区投下了一颗炸弹,
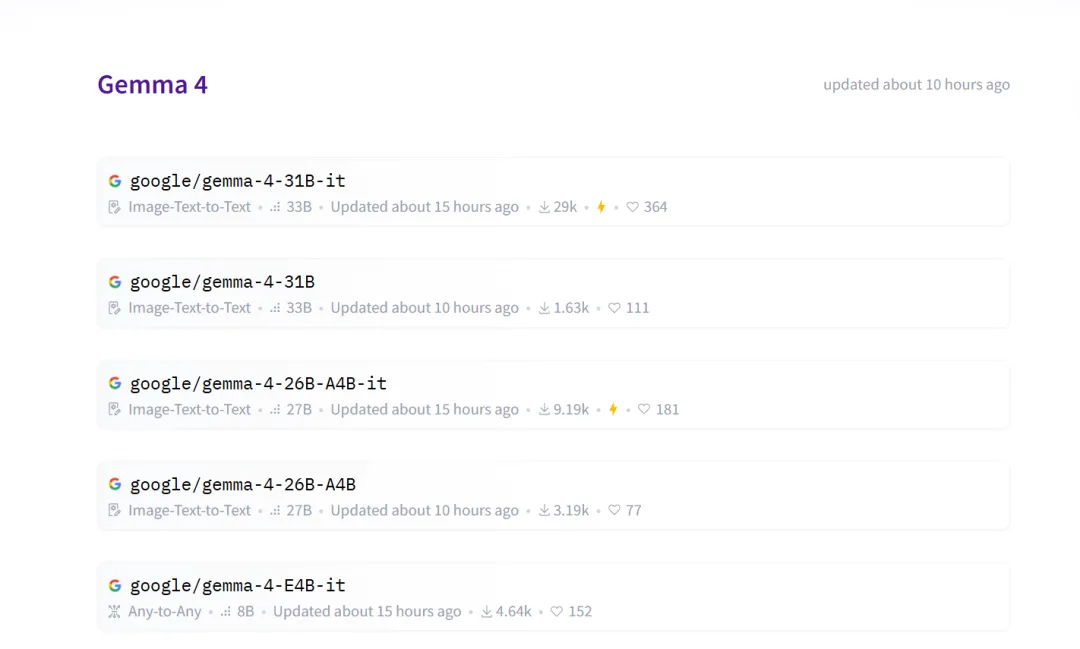
4月2日,今天凌晨,Google 推出了 Gemma 4 系列,一次性推出四个规格:

E2B、E4B、26B A4B MoE、31B Dense。
从最轻量的手机端侧,到高性能GPU和工作站,全覆盖。
并且,这次 Google 把开源许可证直接切换成了 Apache 2.0,对商用也很友好。显然,从 Google 这次的阵仗来看,他们是重视起了 Gemma 的开源的生态。

这次的 Gemma 4 系列中,最让人眼前一亮的是那两款小模型。
E2B 和 E4B 有效参数分别只有 2.3B 和 4.5B,却支持原生音频输入,还能跑 Agent工作流、函数调用、结构化输出等。
意思就是,以后普通安卓手机稍微操作操作,就能本地跑一个真正能干活的AI助手,不用每次都连云端。
大模型这边也给力。
26B MoE 和 31B Dense 在 Arena AI 开放模型榜单分别排到第6和第3。
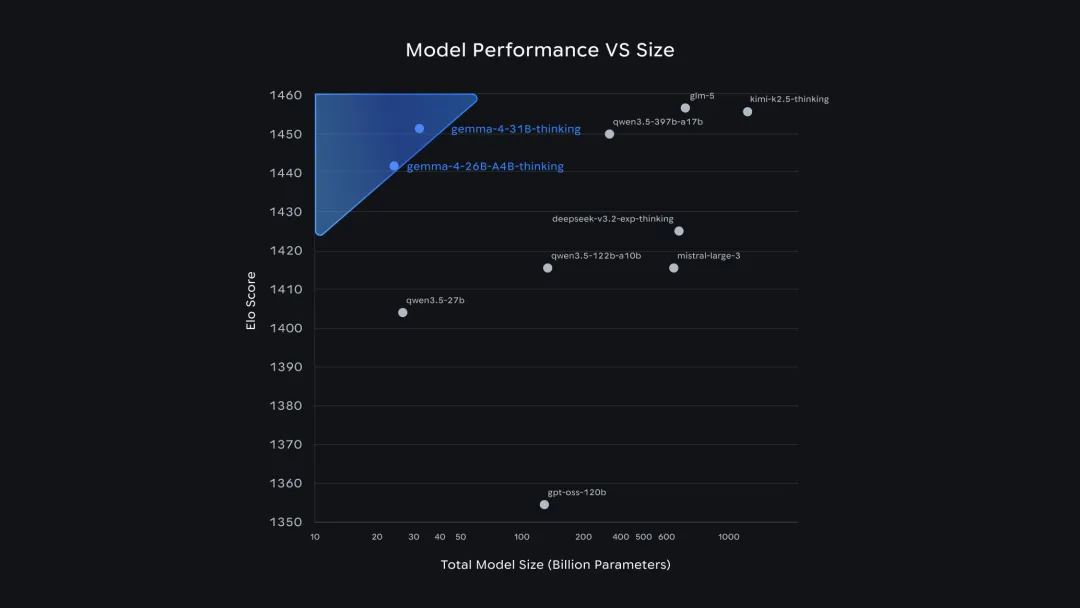
同时其上下文窗口分别达到了 128K 和 256K,在编程、推理、多模态处理能力都拉满。
Google 这次为了方便开发者使用,直接把它们扔到Hugging Face、Ollama、Vertex AI Model Garden等社区,随便拉取。
Demis Hassabis(Google DeepMind联合创始人兼 CEO)亲自下场发帖,用的词是“best open models in the world for their respective sizes(全世界最佳开源模型,大小均有)”。
GoogleDeepMind和Google官方账号也同步推文,阵仗不小。
再说这次 Gemma 切换到Apache 2.0,这是 Gemma 系列最重要的一次转变。

以前还有各种自定义限制,现在彻底放开,开发者可以随便商用、修改、分发。
Google 这次明显是冲着本地AI生态去的,以后不管是做手机端Agent、笔记本本地工具,还是企业内部部署,Google 为大家提供了新的选择。
Gemma4 31B Dense在笔记本GPU上处理复杂推理任务时,表现已经能和一些闭源大模型正面刚。
Google这波操作,把本地AI的门槛又往下拉了一大截。
以前大家总觉得顶级开源模型离手机还很远,现在 E2B/E4B 直接把多模态Agent塞进了口袋。
当然,可能有人会想,在具体的模型上一向不太喜欢搞开源的 Google,这次为什么突然这么大方?是真心想把开源生态做大,还是为了抢占生态位?
不管答案是什么,但眼下的结果都一样——普通用户和开发者能用到的本地AI能力,又上了一个台阶。
Gemma 4 四连发,把“手机也能跑顶级开源AI”这件事变成了现实。
接下来就看开发者怎么把这些模型真正用起来了。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















