
過去一年裏,阿里巴巴 旗下的 Qwen 團隊交出的成績單不可謂不耀眼。
從 Qwen2.5 到 Qwen3,從 Wan 2.2 到尚未開源的 Wan 2.6,多條技術路線並行推進,模型矩陣迅速鋪開,呈現出百花齊放的態勢。
還沒來得及細細體驗春節期間開源的 Qwen 3.5 大模型時,Qwen 團隊又在昨天一口氣開源了多款小模型,再次刷新了節奏與產出效率。
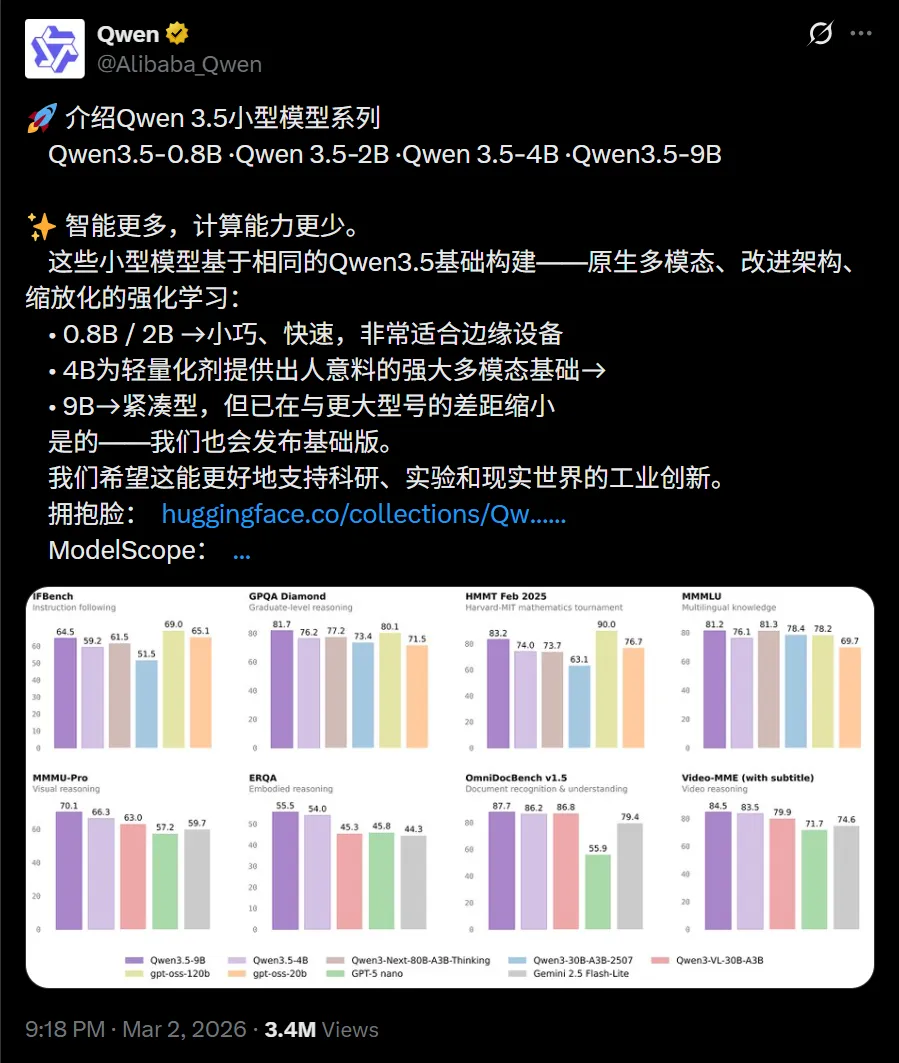
他們直接把 Qwen 3.5 系列的小模型全線開源:0.8B、2B、4B、9B四個尺寸一次性推出,指令版和基礎版都有,協議也是較爲寬鬆的 Apache 2.0 開源協議,誰都能下載、商用、修改(但是該協議有明確的專利保護)。
就在模型公佈的同時,各平臺也跟得很快。
Ollama、Unsloth 這些部署工具當日已經跟上,社區下載量在24小時內就衝了上去。
按常理來說,小模型其實沒啥看頭——受制於參數限制,其總體智力跟大模型完全沒辦法比,用起來給人一種笨笨的感覺。
但是這次 Qwen 的這批小模型可不一樣,這波他們終於把多模態能力從雲端拉到了本地,甚至就連擁有 Gork 的 Elon Musk 也在 Qwen 官方帖下面稱讚了一句“驚人的智能密度。”
模型本身的設計思路很清晰:原生多模態。
文本、圖像、視頻,三種輸入直接融合處理,上下文窗口默認26萬token,還能擴展到100萬,並且在架構做了優化,還加了大規模強化學習和 Thinking模式,模型現在能像人一樣一步步拆解問題,然後去思考再慢慢輸出結果。
Qwen:說歸說,不服我們跑個分看看?
不跑不知道,一跑嚇一跳。
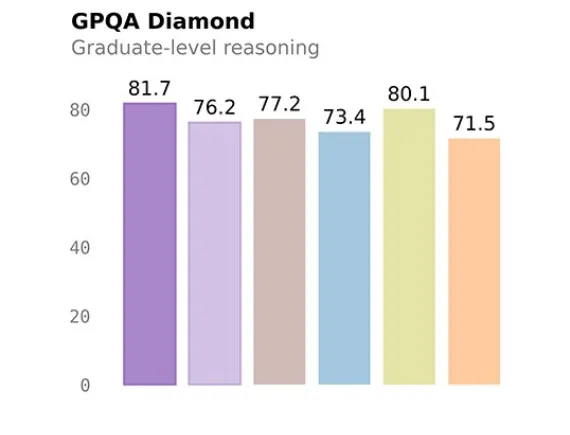
9B版本在GPQA Diamond拿到81.7分,直接超過了OpenAI 開源的120B模型。

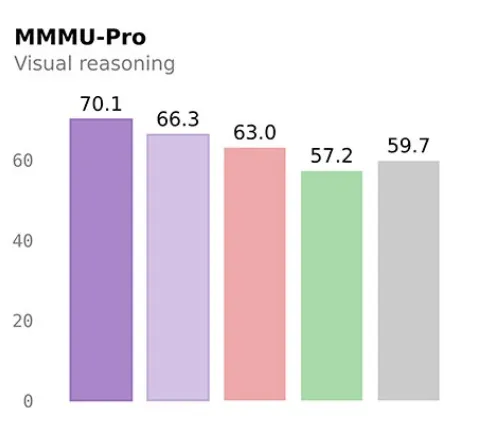
視覺基準MMMU-Pro跑到70.1,比GPT-5-Nano高了十幾個點。
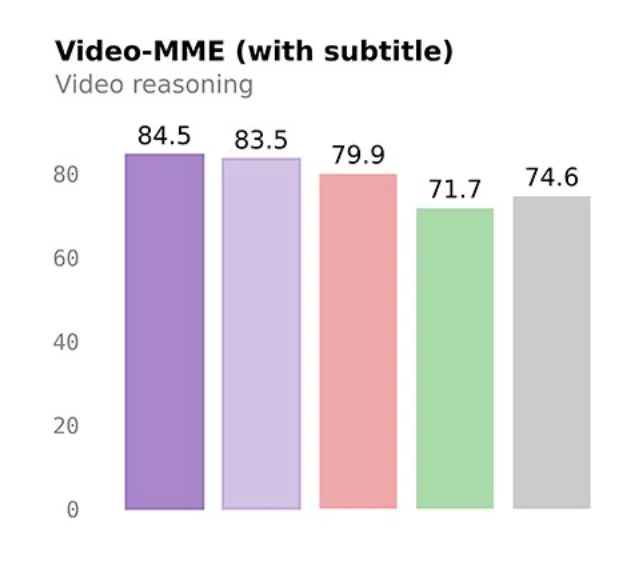
視頻理解VideoMME達到84.5分,長上下文LongBench v2也有55.2。
整體來看,9B已經把前代30B甚至80B的部分能力追平或者反超,4B版本也不弱,MMMU-Pro 66.3分,差不多摸到上一代更大模型的邊。
更關鍵的是參數效率。
9B用13.5倍的參數壓縮,依然在多項硬指標上幹翻閉源競品,這意味着同樣的算力,能跑出以前大模型纔有的效果。
0.8B和2B更是極致輕量,專門爲手機、邊緣設備、電量有限敏感場景準備,4B則成了輕量智能體的好底座。
消息一出,各方反應來得特別快。
除了前面提到的 Elon Musk,社區裏聲音更多。
有人試了9B版本後說,本地就能同時處理視頻、圖像、代碼和長文本,感覺像隨身帶了個全能小助理。

4B版本被拉去做輕量Agent,表現也超出預期。
0.8B和2B則被直接塞進邊緣設備,大家開始討論工業巡檢、手機端視頻分析這些以前想都不敢想的場景。
下載量和星標漲得飛快,說明真正用起來的人已經不少。
這批模型的出現,把開源多模態的門檻直接踩到底。
以前只有大廠閉源模型才能穩穩處理的視頻理解和多模態Agent,現在普通開發者也能本地跑,隱私部署成本暴跌,數據不用再上雲,中小企業和個人開發者一下子多了一堆新選擇。
國內的開源小模型的生態也在快速成型,軟件徹底免費,後面靠硬件和應用場景賺錢的路子越來越清楚。
再往長遠看,這事的影響可能超出很多人預期。
小模型把參數護城河繼續壓縮,封閉大模型曾經靠規模取勝,現在效率和開源速度成了新戰場。

262K原生上下文加上視頻能力,讓輕量Agent真正有可能進入端到端自主工作流,放在以前需要多步人工干預的任務,現在本地就能串起來。
當然,也有人會問,西方閉源模型會不會很快反擊?它們會不會拿出更強的Nano版來應對?中美開源賽道會不會因爲這波加速,徹底進入白熱化?
這些問題現在還沒答案,但Qwen 3.5這批小模型已經把討論推到了檯面上,Musk 那句“驚人的智能密度”其實點出了核心:
參數少,卻把能力密度做到極致。
這不只是技術參數的勝利,更是整個開源生態的一次集體加速。
AI 的下一步,到底是繼續堆參數,還是把聰明塞進更小的設備裏?
好戲剛開,拭目以待。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















