
过去一年里,阿里巴巴 旗下的 Qwen 团队交出的成绩单不可谓不耀眼。
从 Qwen2.5 到 Qwen3,从 Wan 2.2 到尚未开源的 Wan 2.6,多条技术路线并行推进,模型矩阵迅速铺开,呈现出百花齐放的态势。
还没来得及细细体验春节期间开源的 Qwen 3.5 大模型时,Qwen 团队又在昨天一口气开源了多款小模型,再次刷新了节奏与产出效率。
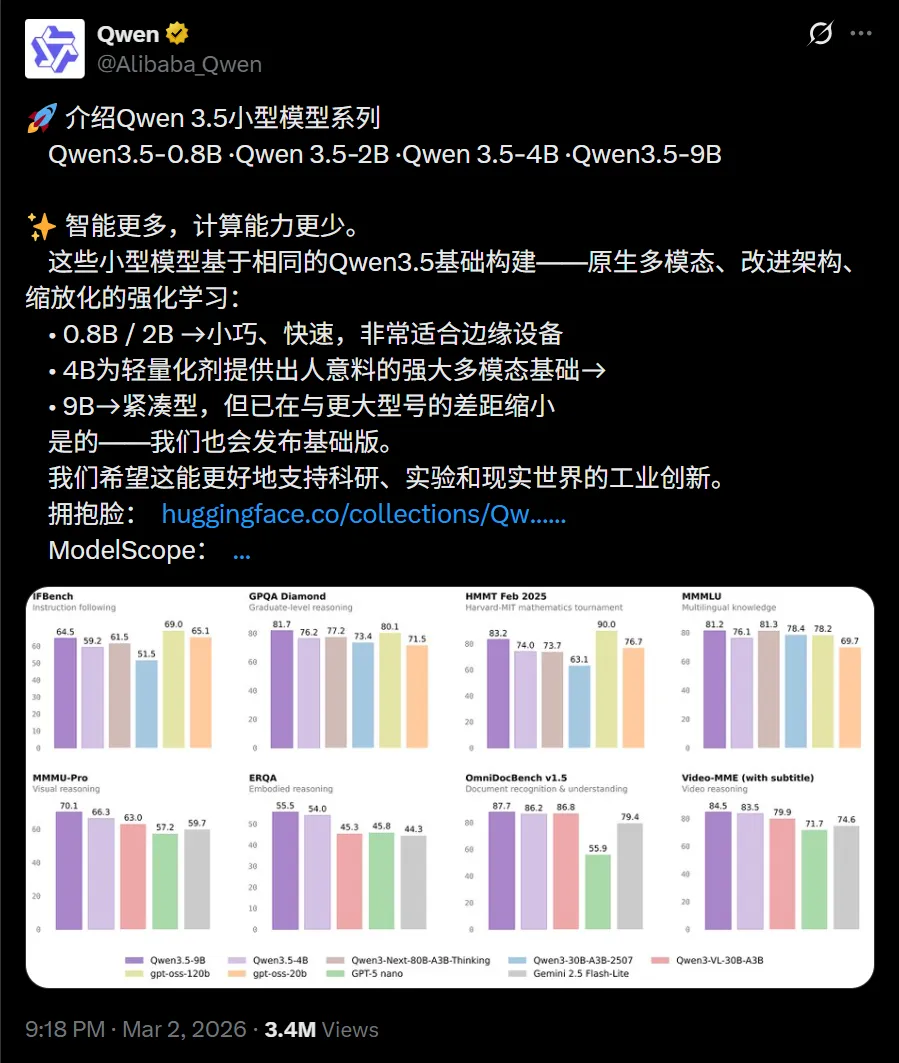
他们直接把 Qwen 3.5 系列的小模型全线开源:0.8B、2B、4B、9B四个尺寸一次性推出,指令版和基础版都有,协议也是较为宽松的 Apache 2.0 开源协议,谁都能下载、商用、修改(但是该协议有明确的专利保护)。
就在模型公布的同时,各平台也跟得很快。
Ollama、Unsloth 这些部署工具当日已经跟上,社区下载量在24小时内就冲了上去。
按常理来说,小模型其实没啥看头——受制于参数限制,其总体智力跟大模型完全没办法比,用起来给人一种笨笨的感觉。
但是这次 Qwen 的这批小模型可不一样,这波他们终于把多模态能力从云端拉到了本地,甚至就连拥有 Gork 的 Elon Musk 也在 Qwen 官方帖下面称赞了一句“惊人的智能密度。”
模型本身的设计思路很清晰:原生多模态。
文本、图像、视频,三种输入直接融合处理,上下文窗口默认26万token,还能扩展到100万,并且在架构做了优化,还加了大规模强化学习和 Thinking模式,模型现在能像人一样一步步拆解问题,然后去思考再慢慢输出结果。
Qwen:说归说,不服我们跑个分看看?
不跑不知道,一跑吓一跳。
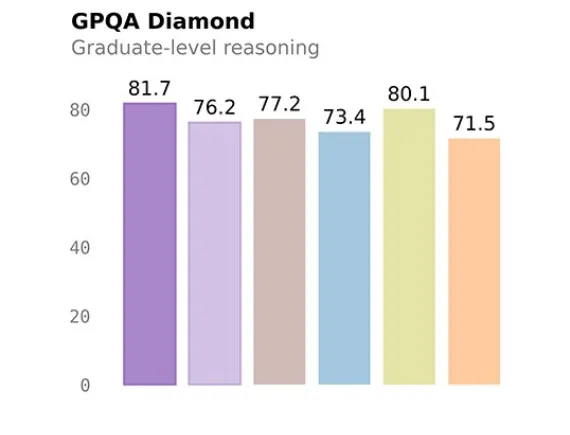
9B版本在GPQA Diamond拿到81.7分,直接超过了OpenAI 开源的120B模型。

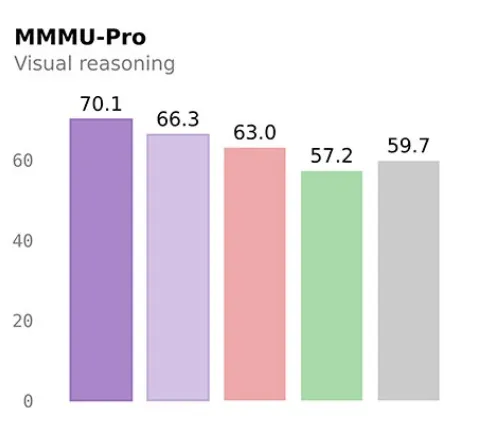
视觉基准MMMU-Pro跑到70.1,比GPT-5-Nano高了十几个点。
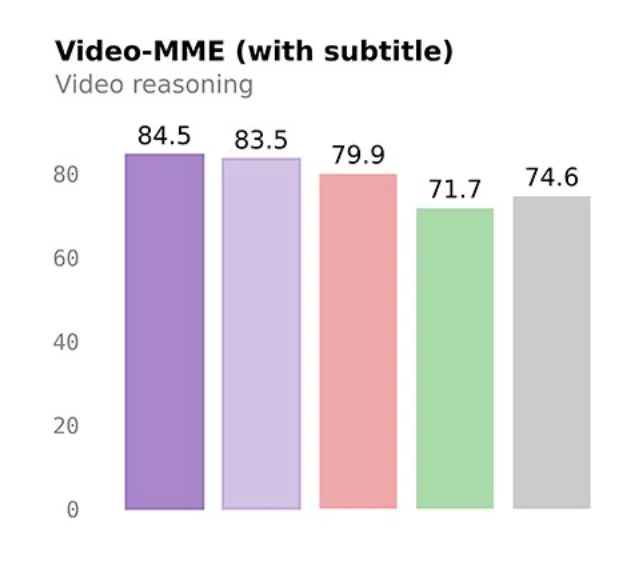
视频理解VideoMME达到84.5分,长上下文LongBench v2也有55.2。
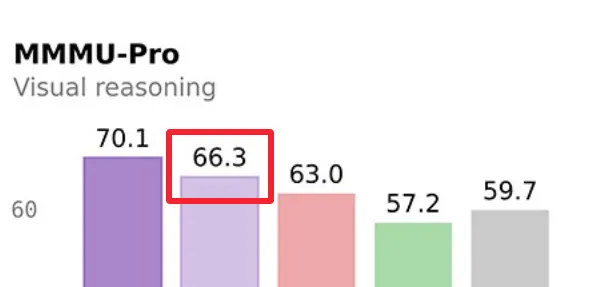
整体来看,9B已经把前代30B甚至80B的部分能力追平或者反超,4B版本也不弱,MMMU-Pro 66.3分,差不多摸到上一代更大模型的边。
更关键的是参数效率。
9B用13.5倍的参数压缩,依然在多项硬指标上干翻闭源竞品,这意味着同样的算力,能跑出以前大模型才有的效果。
0.8B和2B更是极致轻量,专门为手机、边缘设备、电量有限敏感场景准备,4B则成了轻量智能体的好底座。
消息一出,各方反应来得特别快。
除了前面提到的 Elon Musk,社区里声音更多。
有人试了9B版本后说,本地就能同时处理视频、图像、代码和长文本,感觉像随身带了个全能小助理。

4B版本被拉去做轻量Agent,表现也超出预期。
0.8B和2B则被直接塞进边缘设备,大家开始讨论工业巡检、手机端视频分析这些以前想都不敢想的场景。
下载量和星标涨得飞快,说明真正用起来的人已经不少。
这批模型的出现,把开源多模态的门槛直接踩到底。
以前只有大厂闭源模型才能稳稳处理的视频理解和多模态Agent,现在普通开发者也能本地跑,隐私部署成本暴跌,数据不用再上云,中小企业和个人开发者一下子多了一堆新选择。
国内的开源小模型的生态也在快速成型,软件彻底免费,后面靠硬件和应用场景赚钱的路子越来越清楚。
再往长远看,这事的影响可能超出很多人预期。
小模型把参数护城河继续压缩,封闭大模型曾经靠规模取胜,现在效率和开源速度成了新战场。

262K原生上下文加上视频能力,让轻量Agent真正有可能进入端到端自主工作流,放在以前需要多步人工干预的任务,现在本地就能串起来。
当然,也有人会问,西方闭源模型会不会很快反击?它们会不会拿出更强的Nano版来应对?中美开源赛道会不会因为这波加速,彻底进入白热化?
这些问题现在还没答案,但Qwen 3.5这批小模型已经把讨论推到了台面上,Musk 那句“惊人的智能密度”其实点出了核心:
参数少,却把能力密度做到极致。
这不只是技术参数的胜利,更是整个开源生态的一次集体加速。
AI 的下一步,到底是继续堆参数,还是把聪明塞进更小的设备里?
好戏刚开,拭目以待。

更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















