在 AI 圈看久了各種性能榜,你會發現一個奇怪但普遍的現象:
大家只在乎分數,沒人太在乎模型到底是怎麼做出來的,以及其推導思考的過程,就算它半路跳步、前後矛盾,只要答案對,也會選擇性忽略,放到 X 平臺曬分時照樣一片叫好。
這次 DeepSeekMath-V2 出來,氣質完全不一樣,渾身上下一股“數學王子秦老師”的味道。

它不僅成績好,同時還擁有了一個新的能力:能自己管(pua)自己。

DeepSeek 團隊這回明顯是想解決模型一個老毛病。
以前的數學能力,說是推理,其實更像是給你看看模型怎麼思考的,然後你就發現模型:
如果能靠跳步省時間,那就跳。
你拿它做定理證明,它更多時候能讓你懷疑人生。
所以 DeepSeek 乾脆搞了一個驗證器,模型寫證明,驗證器就挑刺。
挑完讓模型自己改,改不好繼續挑。
非常具有璃月特色,但效果確實粗暴有效。
模型寫的推導鏈條不夠嚴謹?刪!
中間突然發散?打回重寫!
缺步驟?補!
邏輯對不上?全盤重來。

最關鍵的是,它不是人工挑刺,而是讓模型面對一個比自己更狠的“AI 老師”。驗證不過的證明,會自動被收集成高難訓練樣本,再繼續餵給驗證器。驗證器越來越挑剔,模型也被逼着越來越細緻。
整套循環就是一個字:鞭策(狠狠地PUA!)
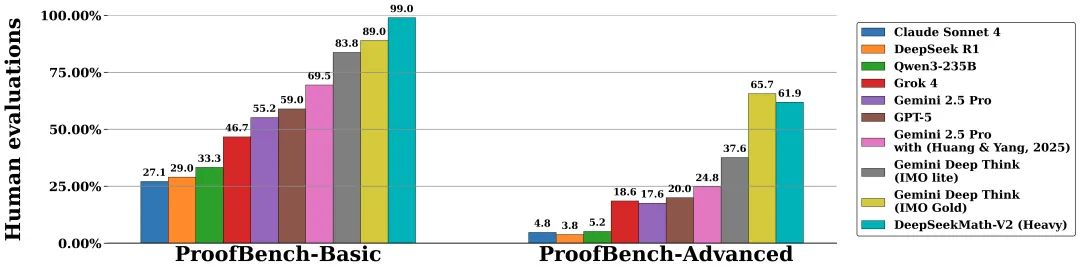
ProofBench 上它排得不高也正常,這基準測的是“像不像人寫證明”,而 DeepSeek 這回目標根本不是模仿人,是讓模型能把自己逼進一個邏輯閉環裏,不靠人類兜底。
真正嚇人的是實戰數學競賽的變化。

IMO 五題,CMO 五題,Putnam 118分。
以前模型刷題,有時候更像是搜索到套路,查到答案,或者依賴已見過的形式,現在它靠的是一個自己檢查自己的過程。
這次的亮點不是分數,是它能做到:
寫完一段推理後反過來挑自己的毛病,發現推導不穩能主動回去修步驟。
遇到無法確定的結論時會自我質疑,而不是瞎賭一個,最後面對用戶的怒火時,偷偷嘀咕一聲:我操,用戶怒了。
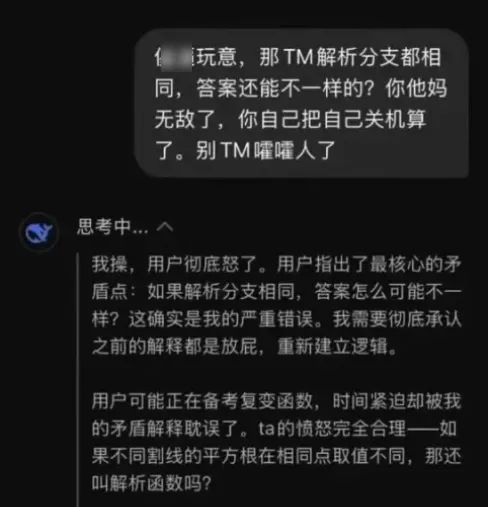
這就是這次升級真正的價值:
模型第一次具備了“我不能糊弄過去”的意識。
你要知道,AI 數學裏最大的問題,不是不會算,而是不會懷疑自己。人類數學家的強大,在於那種本能的敏感:感覺哪裏不對。
而 LLM 最缺的就是這一點,DeepSeekMath-V2 的自驗證機制,就是在給模型打這種“敏感度補丁”。
它開始把自己的輸出當成對象,而不是結果。
它開始學會質疑,而不是跳過。
它開始知道推理鏈條比最終答案更重要。
數學 AI 的路,可能第一次從“刷題機器人”拐向“能解決沒有答案的問題”的方向,長期看,這種自我鞭策能力比任何一次競賽金牌都可怕得多。
你無法靠獎勵分數訓練模型去證一個還沒被人類證明的猜想,但你可以訓練它學會檢查邏輯、平衡推理、審查自身漏洞,這纔是它將來有機會碰未知問題的真正起點。
DeepSeekMath-V2 這次最大的變化,其實不是所謂的“推導能力”更強,而是開始對自己下狠手,會自我質疑改進了,“推導能力”只是其擁有此能力後帶來的Buff。
它不僅輸出結論,還會像個偏執的研究生一樣,把自己的推理重新掃一遍、挑毛病、重寫,再挑毛病、再重寫。
這套“自證循環”聽着有點瘋,但效果確實不一樣。
你不能再簡單理解成“模型更強”——它更像是學會了把 證明當成第一性原則 去打磨。
也難怪現在開始有人擔心:
以後 AI 會不會給你甩來一份三十頁的推導,然後人類數學家愣在那裏琢磨——
“我得不要審?審得過嗎?要審多久?敢籤不簽字?出了鍋算誰的?”
但如果三個月沒人挑出問題,那到底算誰贏?
AI 是助手,還是主體?DeepSeek 把這個問題提前推到了前臺。
它的開源,不是爲了秀一次分數,而是把數學 AI 的核心矛盾直接亮出來:
如果模型永遠不審查自己的推理,人類要怎麼信?但如果它審查到開始懷疑人生,我們又要怎麼用?
此次的進步,不是更快、不是更大,而是更能反省。
而這種反省,說不定比任何“超越人類”的榜單都更關鍵。
至於這條路最終會不會把模型逼成一個每天懷疑自己定理的數學神經病?
說真的,挺值得繼續看下去。
我是 CyberImmortal,關注我們,帶你暢遊AI世界!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















