在 AI 圈看久了各种性能榜,你会发现一个奇怪但普遍的现象:
大家只在乎分数,没人太在乎模型到底是怎么做出来的,以及其推导思考的过程,就算它半路跳步、前后矛盾,只要答案对,也会选择性忽略,放到 X 平台晒分时照样一片叫好。
这次 DeepSeekMath-V2 出来,气质完全不一样,浑身上下一股“数学王子秦老师”的味道。

它不仅成绩好,同时还拥有了一个新的能力:能自己管(pua)自己。

DeepSeek 团队这回明显是想解决模型一个老毛病。
以前的数学能力,说是推理,其实更像是给你看看模型怎么思考的,然后你就发现模型:
如果能靠跳步省时间,那就跳。
你拿它做定理证明,它更多时候能让你怀疑人生。
所以 DeepSeek 干脆搞了一个验证器,模型写证明,验证器就挑刺。
挑完让模型自己改,改不好继续挑。
非常具有璃月特色,但效果确实粗暴有效。
模型写的推导链条不够严谨?删!
中间突然发散?打回重写!
缺步骤?补!
逻辑对不上?全盘重来。

最关键的是,它不是人工挑刺,而是让模型面对一个比自己更狠的“AI 老师”。验证不过的证明,会自动被收集成高难训练样本,再继续喂给验证器。验证器越来越挑剔,模型也被逼着越来越细致。
整套循环就是一个字:鞭策(狠狠地PUA!)
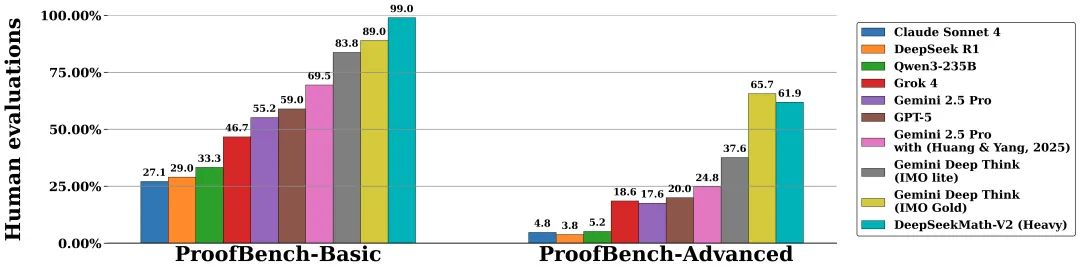
ProofBench 上它排得不高也正常,这基准测的是“像不像人写证明”,而 DeepSeek 这回目标根本不是模仿人,是让模型能把自己逼进一个逻辑闭环里,不靠人类兜底。
真正吓人的是实战数学竞赛的变化。

IMO 五题,CMO 五题,Putnam 118分。
以前模型刷题,有时候更像是搜索到套路,查到答案,或者依赖已见过的形式,现在它靠的是一个自己检查自己的过程。
这次的亮点不是分数,是它能做到:
写完一段推理后反过来挑自己的毛病,发现推导不稳能主动回去修步骤。
遇到无法确定的结论时会自我质疑,而不是瞎赌一个,最后面对用户的怒火时,偷偷嘀咕一声:我操,用户怒了。
这就是这次升级真正的价值:
模型第一次具备了“我不能糊弄过去”的意识。
你要知道,AI 数学里最大的问题,不是不会算,而是不会怀疑自己。人类数学家的强大,在于那种本能的敏感:感觉哪里不对。
而 LLM 最缺的就是这一点,DeepSeekMath-V2 的自验证机制,就是在给模型打这种“敏感度补丁”。
它开始把自己的输出当成对象,而不是结果。
它开始学会质疑,而不是跳过。
它开始知道推理链条比最终答案更重要。
数学 AI 的路,可能第一次从“刷题机器人”拐向“能解决没有答案的问题”的方向,长期看,这种自我鞭策能力比任何一次竞赛金牌都可怕得多。
你无法靠奖励分数训练模型去证一个还没被人类证明的猜想,但你可以训练它学会检查逻辑、平衡推理、审查自身漏洞,这才是它将来有机会碰未知问题的真正起点。
DeepSeekMath-V2 这次最大的变化,其实不是所谓的“推导能力”更强,而是开始对自己下狠手,会自我质疑改进了,“推导能力”只是其拥有此能力后带来的Buff。
它不仅输出结论,还会像个偏执的研究生一样,把自己的推理重新扫一遍、挑毛病、重写,再挑毛病、再重写。
这套“自证循环”听着有点疯,但效果确实不一样。
你不能再简单理解成“模型更强”——它更像是学会了把 证明当成第一性原则 去打磨。
也难怪现在开始有人担心:
以后 AI 会不会给你甩来一份三十页的推导,然后人类数学家愣在那里琢磨——
“我得不要审?审得过吗?要审多久?敢签不签字?出了锅算谁的?”
但如果三个月没人挑出问题,那到底算谁赢?
AI 是助手,还是主体?DeepSeek 把这个问题提前推到了前台。
它的开源,不是为了秀一次分数,而是把数学 AI 的核心矛盾直接亮出来:
如果模型永远不审查自己的推理,人类要怎么信?但如果它审查到开始怀疑人生,我们又要怎么用?
此次的进步,不是更快、不是更大,而是更能反省。
而这种反省,说不定比任何“超越人类”的榜单都更关键。
至于这条路最终会不会把模型逼成一个每天怀疑自己定理的数学神经病?
说真的,挺值得继续看下去。
我是 CyberImmortal,关注我们,带你畅游AI世界!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















