1993年的一個下午,黃仁勳與兩位朋友,坐在硅谷一家Denny's餐廳閒聊,打算創立英偉達時——他們僅僅只希望打造一款能夠提升計算機遊戲體驗的圖形芯片。
但誰能想到,三十年後,這家公司會成爲5萬億美元市值的AI巨頭。而今天凌晨即將發佈的三季度財報,甚至能成爲全球股市的晴雨表。

如果我們回顧英偉達的歷史,會發現黃仁勳的轉型絕非偶然,
從遊戲到AI,遊戲在技術發展中所扮演的角色也非常重要,
今天就用這篇萬字長文一起來看看英偉達的故事。

黃仁勳贈予馬斯克OpenAI公司——全球第一款AI超算DGX-1
遊戲的蠻荒時代
回到上世紀90年代,當時的PC遊戲圖形處理器市場非常混亂,
硅谷大量的公司在炒作“多媒體”新概念,
市場上充斥着數十家粗製濫造的初創公司,都想爭奪對遊戲圖形處理器的主導權,
在這樣的背景下,黃仁勳創立了英偉達,並推出第一款產品NV1。
NV1當時其實不僅僅是一張用來打遊戲的圖形處理器,
還集成了聲卡處理能力,甚至還有世嘉遊戲手柄的接口,
更致命的是,NV1在3D渲染技術上押錯了寶,故意對抗微軟主推的Direct3D標準,
老黃英偉達首款產品NV1直接失敗,導致資金鍊斷裂、公司進入破產邊緣。

創立英偉達前,老黃曾在AMD工作
而當時真正的遊戲霸主爲3dfx,他們推出的Voodoo系列碾壓NV1,
而且可以暢玩卡馬克《雷神之錘》等早期3D遊戲(卡馬克詳見唯一封神的遊戲程序員——Doom的前世今生),
Voodoo 2更是引入SLO交火技術,允許兩塊顯卡協同工作,這在當時也是遊戲發燒友的畢業配置。
然而3dfx卻在最巔峯時犯下兩個致命錯誤,直接導致破產被收購,
一是3dfx收購了板卡製造商STB Systems(類似於今天的華碩微星),
3dfx想要大包大攬,從單純的芯片供應商,轉變爲集設計、製造、銷售於一體的垂直整合商。
但是3dfx的路顯然是走錯了,
因爲哪怕英偉達已經到了如今這個級別,也仍然堅持只做芯片設計,
把製造交給臺積電,板卡組裝給到華碩、微星等合作伙伴,從而建立了龐大的生態聯盟。
3dfx第二個失誤是技術路線的錯判,
他們認爲英特爾CPU的性能增長足以處理3D場景中的幾何運算,所以顯卡主要專注於光柵化和紋理填充,
而英偉達卻敏銳地預見到,隨着遊戲場景日益複雜,CPU同樣將成爲最大的瓶頸。

最強遊戲程序員——約翰·卡馬克
英偉達發明顯卡
就這樣,在1999年的8月31日,英偉達發佈了GeForce 256,
在廣告標語上,黃仁勳並沒有說它是更快的圖形加速卡,
而是創造了一個全新的術語——GPU,
也就是我們如今熟知的顯卡,沒錯,顯卡正是英偉達發明的。
根據英偉達官方定義,GPU每秒能夠處理至少1000萬個多邊形,
性能較傳統圖形加速器提升了10倍以上,可以爲遊戲玩家提供更出色的3D遊戲畫面。
技術層面,GeForce 256的核心突破是硬件T&L,
專門負責3D圖形生成過程中兩個最重要的任務,分別爲幾何變換與光照處理。

GeForce 256
幾何變換很簡單,就是遊戲中3D物體在虛擬空間中的位置、角度、大小,
然後從3D空間投影到你的2D屏幕上,這個過程涉及大量的矩陣運算(請記住矩陣運算,這點很重要),
光照處理就是根據場景中設置的光源,計算3D物體表面各點的明暗、顏色和陰影,
如今的虛幻五引擎其實仍然在解決這些圖形學的這些問題,比如Nanite虛擬幾何體用來幾何細節處理,所以有了黑神話的細節,
再者用Lumen實現動態全局光照,背後同樣是結合英偉達的硬件光線追蹤技術,當然,這些都是後話了。

在英偉達GeForce 256出現之前,傳統3D渲染流程需要大量的浮點運算,
一般這些繁重的數學任務由CPU承擔,但黃仁勳把硬件T&L固化在GPU芯片的邏輯電路中,
所以專用電路處理特定數學運算的效率遠高於通用CPU,
而且這種將特定數學運算(矩陣變換)轉嫁給GPU的思路,
也剛好和後來AI深度學習中的矩陣乘法轉嫁給GPU的思路完全吻合。
2000年底,英偉達的GeForce 256徹底碾壓3dfx的Voodoo 5 5500芯片,
資金枯竭的3dfx反被英偉達收購,大量的圖形工程師加入英偉達,這些人才也成爲英偉達轉型期的核心力量。

老黃的奇思妙想
進入21世紀,英偉達幾乎壟斷了高性能遊戲圖形市場,老黃開始思考下一步。
英偉達接下來的GeForce 3(NV20)引入了可編程頂點着色器,這是GPU歷史上第二個里程碑。
在此之前,GPU的渲染流程是固定的,遊戲開發者只能調整預設的參數,比如設定死的霧化濃度和光照顏色,
過去如果是固定比例參數設計,會導致非常嚴重的資源浪費,
比如在遊戲複雜的水面波浪中,頂點非常密集,像素着色器可能處於閒置狀態,
但是在複雜的陰影處理中,像素密集,頂點着色器又無所事事,這種非對稱的負載導致GPU實際性能極其低下。
而全新的可編程着色器允許開發者編寫微代碼,直接控制每一個頂點和像素的生成邏輯,
這個技術也在G80架構的顯卡GeForce 8800 GTX上達到頂峯,
G80支持微軟全新的DirectX 10 API,徹底摒棄過去分離的頂點渲染管線和像素渲染管線,轉而採用統一着色器架構,
此外G80擁有128個流處理器,這些處理器不再被硬編碼爲處理圖形任務,
而是通用的浮點運算單元,系統可以根據負載動態分配它們去處理頂點、像素,
或者,
你也可以拿他們去做其他的數學運算。

8800 GTX
2006年,就在英偉達獨孤求敗之時,老黃推出了CUDA,這是一個軟件平臺和編程模型,
允許開發者使用C語言等高級語言直接調用GPU的並行計算能力,
開發者無需像過去那樣通過圖形API將計算任務僞裝成紋理渲染任務,
簡而言之,過去科學家們做科研數學計算時,都是把這些任務僞裝成遊戲開發圖形處理的一部分,
但是現在,老黃要把每一張遊戲顯卡,改造成能夠兼顧遊戲和科研的計算芯片,
比如很多遊戲玩家他就沒有科研的需求,但是如果要兼具做通用計算,
那麼每一顆芯片都要增加額外的邏輯電路,這也導致芯片面積增大良率下降,製造成本飆升。

爲推廣CUDA,英偉達選擇了高校路線——
與全球頂級研究機構和大學合作,培養下一代開發者,
但從市場來看,當時只有極少數科研人員對GPU計算感興趣,
絕大多數遊戲玩家並不需要CUDA,但他們卻不得不爲這部分多餘的芯片買單。

CUDA之父、英偉達首席科學家-大衛·柯克
顯卡危機
本來遊戲市場上做得好好的英偉達,直接老黃的奇思妙想差點拖垮,
從2007年開始,由於G80後續架構成本升高,再加上全球性金融危機影響,
英偉達的毛利率受到嚴重擠壓,2009年的Q4營收同比暴跌60%,
華爾街的分析師們那幾年也是英偉達的大空頭,不斷質疑老黃爲什麼要在遊戲顯卡塞入昂貴的計算功能,
而英偉達的股價長期徘徊在低位,甚至一度跌破10美元。

2007年這年還發布了一款非常有名的新遊戲《孤島危機》,
外號顯卡危機,因爲這款遊戲對光影、物理破壞和植被渲染的要求達到了當時硬件無法承受的高度,
即便是卡皇8800 GTX也難以在最高畫質下維持60幀的流暢度,
所以《孤島危機》的存在成爲了後續幾年顯卡性能提升的標杆,
爲了征服《孤島危機》,老黃也帶領英偉達進入了遊戲卡架構發展的快車道,
然而神奇的是,這些遊戲卡也在不經意間敲開了AI神經網絡的大門。

老黃皮衣技術大會
上文說到,由於CUDA發展初期,老黃投入巨大而商業回報不明,
英偉達飽受華爾街質疑,股價承受壓力,老黃覺得可以參考學術會議,
由他自己牽頭,邀請全世界的學者一起參加英偉達的技術大會,共同探討顯卡的未來發展方向。
對於大多數遊戲玩家,以及當時華爾街的投資者們來說,
老黃最重要的事情是趕緊迭代顯卡把《孤島危機》拿下,儘快賺錢把股價拉上來,
但老黃認爲最重要的事情是讓英偉達能夠利用遊戲顯卡,去解決那些科學上的問題。

但是老黃本質上也只是工程師而已,他沒有能力像馬斯克那樣解決從0到1的問題,
而且老黃自己也非常迷茫,英偉達顯卡到底在哪個學術領域發光發熱,連他自己也摸不清楚,
所以在2009年,老黃在英偉達首席科學家柯克的建議下,一起召開了第一屆英偉達GTC大會,
會議上老黃常常身着皮衣與大家交流,所以皮衣也逐漸成爲老黃標誌性象徵。

2010年的第二屆GTC大會,老黃隆重推出了基於Fermi架構的GTX 400系列,
比如GTX 460,順便提一嘴,當時你去買電腦的話一般都叫獨立顯卡,
Fermi是爲了致敬物理學獎費米教授,Fermi的架構在設計上極度激進,
引入完整的 L1/L2 緩存層級、ECC內存支持以及大幅增強的雙精度浮點,
擁有512個CUDA核心,支持C++,極大降低開發門檻,讓那些習慣於x86編程的科學家也能輕鬆移植代碼。
但是在消費級顯卡市場,Fermi 的這種“重計算”設計帶來了巨大的副作用,
因爲大量的晶體管被用於對遊戲性能貢獻不大的計算邏輯和緩存控制上,
所以GTX 480運行時溫度極高,也被玩家戲稱是“核彈”或“煎蛋器”,能耗比相當糟糕。

GTX 580的奇蹟
2011年,英偉達改善了GTX 480的功耗和發熱問題後,又推出了GTX 500系列,
其中GTX 560Ti是中高端顯卡,超頻潛力也不錯,成爲衆多玩家的首選,
而GTX 580則是滿血版Fermi架構,穩穩坐上了單芯卡皇的寶座,
或許誰也沒有想到,英偉達命運的齒輪,在GTX 580這張卡上開始轉動。

2012年,當時多倫多大學有一位常年失意的教授,名叫傑弗裏·辛頓(Geoffrey Hinton),
辛頓出自學術世家,外高祖父喬治·布爾創立了布爾代數,
高祖母瑪麗的叔叔喬治·埃佛勒斯是地理學家,珠穆朗瑪峯“Mount Everest”即以他的姓氏命名,
曾祖父查爾斯·辛頓是數學家兼科幻作家,提出“四維超正方體”概念,影響後世科幻作品,
布爾的女兒伏尼契是名著《牛虻》的作者,父親霍華德·辛頓是劍橋大學教授、著名昆蟲學家,
辛頓還有一位堂姑瓊·辛頓是核物理學家、楊振寧同事,曾參與曼哈頓計劃,
這位姑姑的中文名我們更熟悉,名叫寒春,也是第一位獲得中國“綠卡”的外國人,
當然,囉唆了這麼多,辛頓在2012年的時候並沒有他祖上這些名人那麼成功,
因爲辛頓研究的是一項已經被判了死刑的方向——神經網絡,也是整個領域攀登難度最大的珠穆朗瑪峯。

在2012年以前,計算機方向幾乎所有的權威專家,都認爲神經網絡已死,
別說是專家,就連老黃這位斯坦福EE研究生,同樣也不看好神經網絡。
這個故事還得追溯到上世紀60年代,當時也有一股人工智能熱——感知機,
很多人都把AI的突破寄希望在感知機上,但是到了1969年,
明斯基從理論上指出了感知機的根本性侷限,給神經網絡潑了一盆涼水,
雖然到了80年代,辛頓等人提出了BP反向傳播算法,但是如果訓練更深層的網絡時,
網絡就會出現梯度消失/爆炸問題,導致模型難以有效學習,
而且當時的計算機硬件計算能力有限,訓練一個稍複雜的神經網絡可能需要數天時間,成本高昂且效率低下,難以投入實用。
與此同時,支持向量機SVM等統計學習方法在諸多任務上表現更爲穩定和出色,
吸引了大量學者,也使得神經網絡處於邊緣地位,而辛頓則是一直堅持坐冷板凳,直到英偉達GTX 580的誕生,以及另一位天才的橫空出世。

Ilya與AlexNet
如果問誰對AI的貢獻最大,絕對有Ilya Sutskever的名字,
回到2012年,他當時是辛頓教授的博士生,與另一位博士生Alex一起打一場比賽,
比賽的名字爲ImageNet大規模視覺識別挑戰賽,比賽發起者正是斯坦福的華裔教授李飛飛,
當時是第三屆ImageNet大賽,前面兩屆獲勝團隊使用的還是傳統的機器學習方法,
但是到了2012年,Alex和Ilya決定使用最新的英偉達GPU來加速神經網絡,
在Ilya之前,從未有人嘗試過拿打遊戲的GPU來訓練神經網絡,
於是Ilya回到自己的宿舍,用攢下的錢買了兩塊GTX 580,
但是Ilya發現GTX 580僅有3GB顯存,無法容納擁有6000萬個參數和65萬個神經元的模型,
爲了突破顯存限制,Alex設計了一種特殊的網絡架構,將神經網絡切分到兩塊GPU上,
兩塊GPU分別負責一半的神經元計算,只在特定的層級進行數據通信,
這也是人類歷史上首次模型並行計算,也是十多年後萬億參數大模型多卡訓練的雛形。

經過不到一週的訓練,Ilya發現原本需要數月才能完成的訓練,在兩塊GTX 580上僅用了5-6天,
而且在2012年的的ILSVRC競賽中,辛頓團隊的AlexNet以15.3%的Top-5錯誤率奪冠,
比第二名(使用傳統計算機視覺方法)的26.2%低了整整10.8個百分點,
這是一個斷崖式的領先,也瞬間宣告了傳統計算機視覺時代的終結。
老黃這才猛然意識到,他一直不看好的神經網絡,居然和自家顯卡擦出最完美的火花,
於是老黃聯繫上斯坦福另一位非常有名的華裔教授Andrew Ng吳恩達,
經過交流之後,老黃認定CUDA架構原來不僅僅能做物理模擬,在神經網絡深度學習領域更是天作之合,
據英偉達內部人士及多次訪談回顧,2012年一個週五的晚上,
黃仁勳在深思熟慮後,向全體員工發送了一封具有歷史轉折意義的內部郵件,
在這封郵件中,他做出了兩個驚人的判斷:
深度學習將從根本上改變軟件的編寫方式。 軟件將不再是由人類編寫邏輯,而是由數據訓練生成。
英偉達不再僅僅是一家圖形處理公司,而是一家AI公司。

遊戲xAI
這封郵件也成爲英偉達歷史上最激進的轉型,
英偉達硬件層未來的GPU架構將針對AI算子(矩陣乘法)進行特化設計,
軟件層方面則組建團隊開發cuDNN,這是一個專門針對深度學習框架優化的底層庫,
老黃也開始直接向全球的AI實驗室贈送顯卡,並派遣系統工程師駐場協助優化代碼。
與此同時,隨着AI需求的指數級增長,老黃髮現,
服務於遊戲玩家的顯卡,和服務於數據中心的加速卡,在需求上出現了不可調和的矛盾。
遊戲需要強大的光柵化能力、紋理處理單元和顯示輸出接口;
而AI訓練需要極致的矩陣吞吐量、超高帶寬的顯存(HBM),卻幾乎不需要圖形輸出功能。
爲了能夠同時統治遊戲市場和AI市場,英偉達也在顯卡架構上進行了關鍵的大分流。

2012年的GTC大會,老黃髮布了Kepler架構,推出GTX 600系列,
與前代Fermi相比,新架構引入了全新流式多處理器設計,
GTX 680節省的空間裏塞了1536個CUDA核心,性能提升三倍,功耗也大大降低,
與此同時,老黃還推出了Titan系列,這個系列非常短命,
初代Titan不僅是頂級遊戲卡,也是科研人員和深度學習研究者的廉價超級計算機。
2014年的GTC大會,Maxwell架構與GTX 900系列發佈,GTX 960、GTX 970成爲市場的主流型號,
旗艦卡是980Ti,但是Maxwell架構的真·旗艦卡要等到第二年。

2014年的GTC大會
深度學習大爆炸
2015年的GTC大會,老黃髮布了真正的頂級旗艦卡Titan X,
CUDA核心躍升到了3072個,顯存容量來到12GB,
這款顯卡也是被老黃明確定義爲深度學習專用卡,
如果實驗室不缺錢,還可以用四塊Titan X交火的DIGITS DevBox工作站,
其實從14、15年開始,英偉達顯卡的設計重心就已經倒向了AI,
但是因爲16年老黃髮布了GTX 10系顯卡,玩家們對英偉達重心轉移到AI的認知反而滯後了好幾年。

2016年的GTC大會,這屆既是深度學習大爆炸的盛會,同樣也是玩家羣體的盛宴,
筆者也是從這一年開始長期更新GTC大會的技術研報,
老黃會議上發佈了全新的Pascal架構,仍然延續兩年發佈一個新架構的模式,
但是這代新架構的技術迭代是最大膽的,
Pascal架構首次引入了NVLink高速互聯技術,可以提供160 GB/s的雙向帶寬,遠超傳統的PCIe 3.0,
這也使得多個GPU之間以及GPU與CPU之間的數據交換效率大增,特別適合多卡並行計算場景(也就是當年AlexNet雙卡GTX 580的訓練場景)。

基於Pascal架構的Tesla P100加速器,則是數據中心和高性能計算領域的里程碑,
Tesla P100率先使用HBM2高帶寬顯存,通過CoWoS封裝技術,實現720 GB/s的內存帶寬,
而最近一年內存緊張價格暴漲,源頭也可以追溯到這裏,
當時傳統顯存是GDDR,而HBM2是一種立體堆疊結構的顯存,
可以把多個DRAM芯片在垂直方向上層疊起來,性能極高,而且功耗遠低於當時的GDDR5顯存,
目前全球僅有三星、SK海力士和美光等幾家公司可以大規模生成HBM,
也導致高端HBM內存供應緊張,當然現在普通的顯存和高端的HBM都是產能短缺的狀態。
另外,老黃還首次發佈了DGX-1超級計算機,集成了8塊Tesla P100 GPU。

遊戲玩家的盛宴
對於任何一名硬件老玩家來說,想必沒有什麼比GTC 2016新顯卡發佈更震撼的時刻了,
這年老黃還發布了基於Pascal架構的10系顯卡,
入門級GTX 1060的性能甚至超越了上一代旗艦GTX 980,卻保持着甜點卡的定價,
隨着PUBG的興起,1060也成爲標配,逐漸也成爲Steam硬件統計中最大的釘子戶,
而隨着挖礦的崛起,1060的5GB/6GB和1070/1080/1080Ti等型號也成爲礦場的首選。

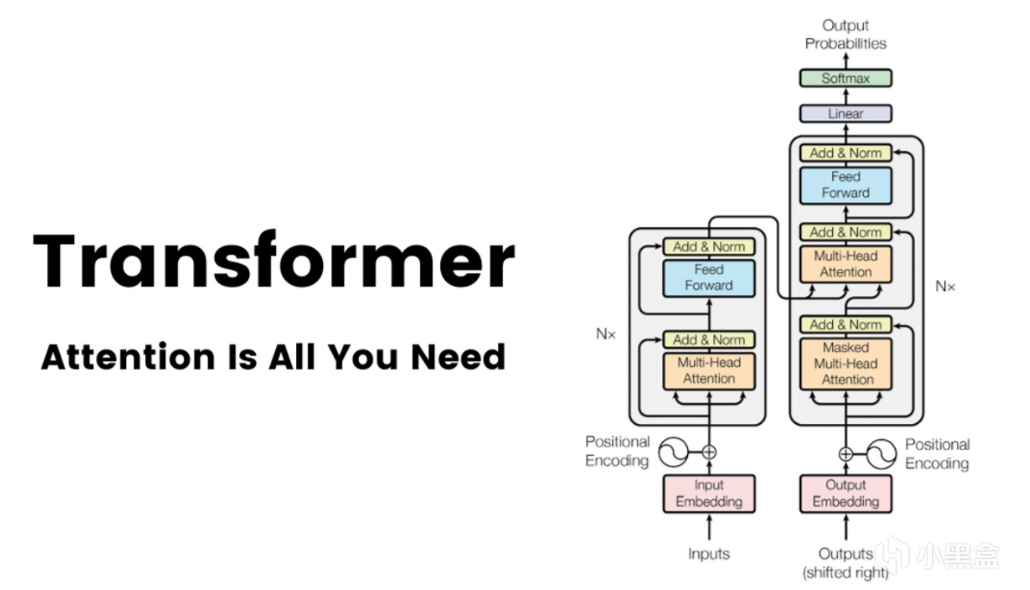
Attention Is All You Need
進入2017年,6月12日,一篇名叫《Attention Is All You Need》的論文發佈在arXiv上,
隨後在頂會NeurIPS上正式發表,作者來自谷歌的八位研究者,
不過真正等到這篇論文一統江湖還要幾年後了。
這年的GTC大會,老黃首次引入了專爲AI計算設計的Tensor Core,
在Tensor Core出現之前,GPU主要依賴CUDA Core進行各種並行計算,
但是CUDA core做矩陣乘法運算的效率仍有提升空間,
一個CUDA Core每個時鐘週期通常只能完成一次乘加操作,
Tensor Core則是一種專用集成電路,經過特殊設計,每個時鐘週期可以完成一個小的4x4矩陣的乘加運算,
從這時開始,我們眼中熟悉的遊戲顯卡,也朝着更適用於AI並行計算的方向去發展,
也恰恰是這個創新,讓之後訓練大型深度學習模型的時間從數週縮短到幾小時成爲可能。
AI反哺遊戲
2018年的GTC大會,這年仍然是AI和遊戲兩條主軸,
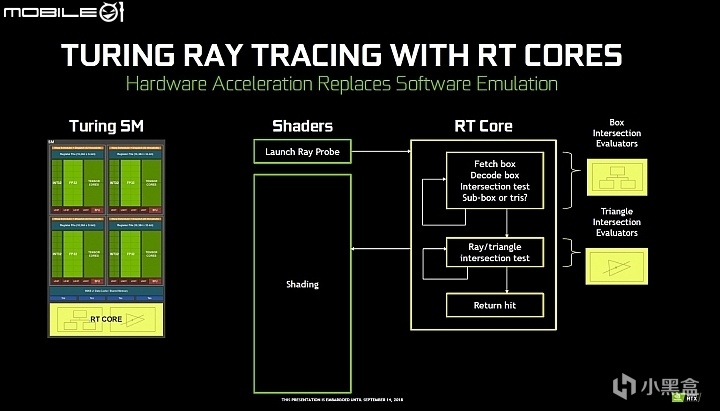
老黃致敬圖靈推出了全新的Turing架構,引入了專用的RT Core硬件單元,
Turing架構也是首個同時集成RT Core和Tensor Core的消費級架構,
Tensor Core用來做AI,RT Core用來打遊戲,
而Tensor Core剛好又很擅長做AI算法,可以把低分辨率圖像高質量放大,
所以就有了DLSS大力水手技術,這樣的話AI也可以反哺遊戲。
在數據中心端,英偉達發佈了NVSwitch芯片和DGX-2超級計算機,
擁有512GB的HBM2顯存空間,16塊V100 GPU,能夠以300 GB/s的速度全互聯,
這一年的熱門方向有一路發展到頂峯的生成對抗網絡GAN,
計算機視覺CV四小龍風光無限,深鑑科技、寒武紀輪番成爲主角,
這年10月同樣由谷歌團隊發表的BERT論文,也掀起自然語言理解NLP的熱潮。

遊戲端則是由GTX變成了RTX時代,甜點卡2060依然能打,
高端卡2080TI/2080因爲礦潮的影響,生命週期大大延長,
雖然16年和18年GTC大會內容都不少,
但是20系的升級遠遠沒有10系性能提升那麼震撼,
10系Pascal架構的成功,很大程度上得益於從28nm到16nm的巨大製程紅利,
而20系Turing架構的複雜性遠超前代,全新的DLSS技術一開始也是褒貶不一,爭議也一直持續至今。

大模型時代
接下來的2020年GTC大會,則徹底淪爲AI的獨角戲,
這年大會是首次在線上舉辦,老黃推出全新的Ampere架構,
GPT已經迭代到GPT-3,徹底破圈引爆全球,
老黃介紹的產品首先就是賣爆了的A100系列,也是AI訓練的主力,
同步推出的還有30系顯卡,搭載第二代RT Core和第三代Tensor Core,
再加上三星8nm工藝和高速GDDR6X顯存,
但30系給人印象最深的,也僅有感謝2077幫我買到原價的30系顯卡......

GTC 2020
由於玩家長時間買不到正常價格的顯卡,30系彷彿是被跳過的一代,
那幾年也讓人遺忘,但是老黃在AI上面發力可是一點也不少。
2021年的GTC大會,英偉達正式確立了 GPU + CPU + DPU 的三支柱戰略,
這裏面遊戲只佔很小一部分,其中CPU也是專用於大模型的Grace CPU,並不在消費級產品範疇。
2022年的GTC大會,GPT的火徹底點燃工業界,老黃帶來了銷量王Hopper架構,
也是把英偉達推上五萬億寶座的主力,基於Hopper架構的H100也是專爲LLM大模型量身定做,
H100搭載Transformer引擎,將Transformer模型的訓練速度相比A100提升6倍,
遊戲玩家這邊由30系的Ampere架構升級爲40系的Ada Lovelace架構,
搭載第三代RT Core和第四代Tensor Core,支持DLSS3和光學多幀生成(智能插幀)。

GTC 2022
2023年的GTC大會則是改變了英偉達只賣硬件的模式,
轉而和Oracle、Microsoft Azure、Google Cloud合作推出了DGX Cloud服務。
今年的GTC大會剛開完不久,去年底到今年可以說是推理元年,
24年GTC大會,老黃專爲萬億參數推理大模型設計了Blackwell架構,
GB200 NVL72搭載36個Grace CPU和72個Blackwell GPU,可以單機架運行萬億參數模型,
同時到來的還有搭載Blackwell同架構的50系顯卡,完全是擠牙膏式升級,用心程度遠遠比不上AI......
今年GTC大會英偉達加快了迭代節奏,針對對長上下文推理推出Blackwell Ultra,
顯存升級到最新的HBM3e,可以容納巨大的KV Cache,
下一代Rubin架構仍在大餅狀態,計劃引入HBM4e,支持NVLink 6互聯。

賣鏟子的老黃
英偉達的GTC大會講到這裏也就結束了,但是英偉達的故事還遠未結束。
當我們把目光從令人眼花繚亂的架構和技術裏收回,重新審視英偉達當下的處境,
會發現從2023年開始,幾乎硅谷所有的巨頭都在給老黃打工,
微軟、Meta、谷歌、亞馬遜,他們爲了拿到AGI算力的船票,幾乎排着隊採購H100,
這就像當年的淘金熱,無論是挖到金子的(OpenAI),還是沒挖到的,
都得先向賣鏟子的人——英偉達,繳納昂貴的過路費,
這種極度的供需失衡,造就了英偉達恐怖的利潤率,也將市值推向了難以置信的高度。
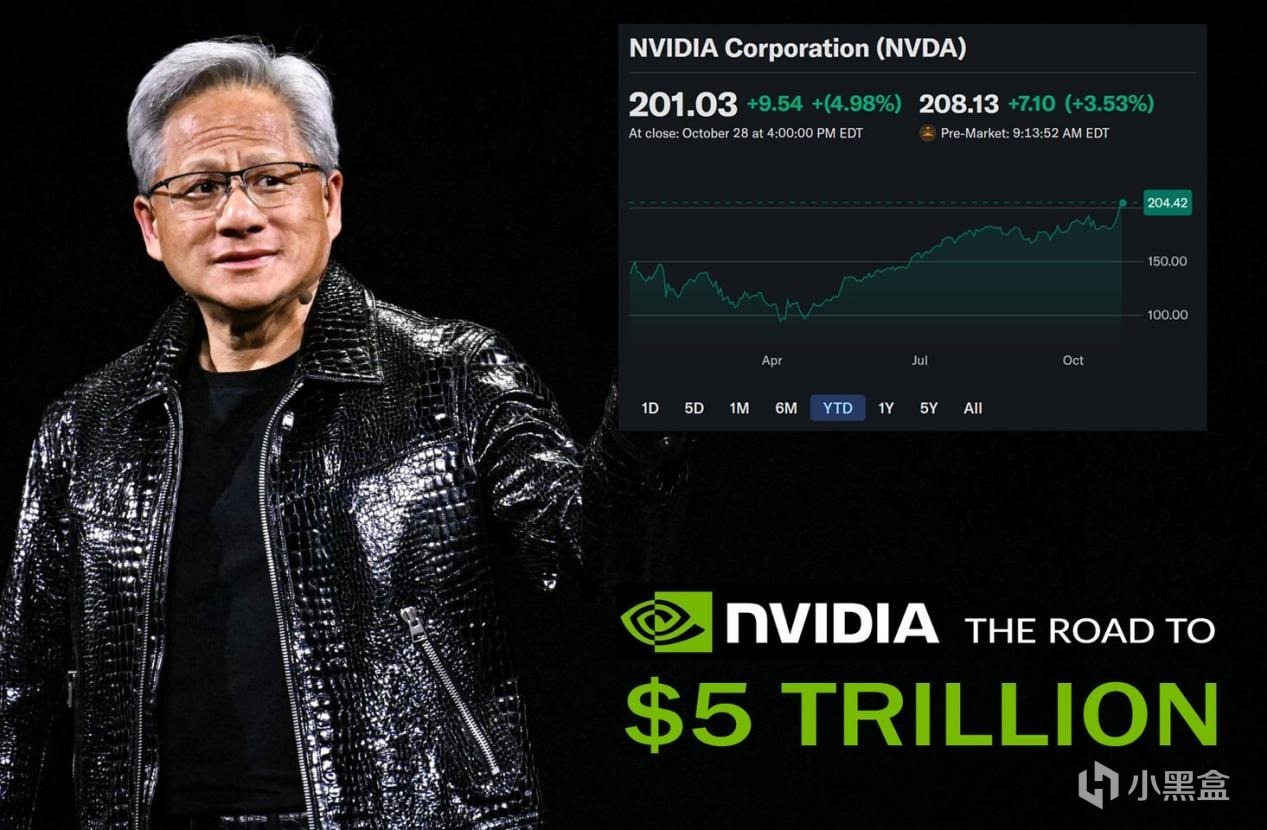
而今天凌晨的這份Q3財報,之所以被視作“全球股市晴雨表”,
是因爲華爾街想要確認兩件事,第一,AI的泡沫到底有沒有破裂的跡象?
如果連“賣鏟子”的人業績都開始下滑,說明淘金客們已經沒錢了;
第二,Blackwell的出貨是否順利?此前傳出的散熱問題是否會影響量產進度?
在某種意義上,英偉達的財報已經不再屬於一家公司,而是成爲了整個AI產業鏈的信心指數。
作爲一名玩家的後話
而回到我們最初的話題,在英偉達如今龐大的AI帝國版圖中,
那個曾經陪伴無數少年在網吧通宵、在宿舍開黑的N卡,似乎變得不再重要了,
我們能負擔得起顯卡的價格,卻很難找到兒時的那種快樂,
英偉達和老黃也變得不那麼有人情味,數據中心業務的營收佔比早已碾壓遊戲業務,
顯卡價格越來越貴,顯存給得越來越摳搜,我們玩家也已經被老黃拋棄,成爲了AI發展的墊腳石。
這聽起來非常殘酷,但也是事實。
從技術發展角度看,如果沒有遊戲市場,英偉達顯卡或許就不會誕生,
如果沒有玩家這三十年來的支持,爲英偉達提供了源源不斷的研發資金,AI的爆發可能還要推遲十年;
反過來,如果沒有AI帶來的技術反哺,在摩爾定律已死的今天,
單純靠堆晶體管,我們也可能遲遲無法在消費級顯卡上實現突破,
未來的遊戲,或許不再是單純的圖形渲染, 而是像《黑客帝國》那樣,
由AI實時生成的、無限細節的虛擬世界——
或許也就是老黃口中那個融合了圖形學與AI的終極目標:Omniverse(全是大餅)。

故事的最後,讓我們把時鐘撥回到1993年的那個下午,
硅谷那家Denny's餐廳裏,那三個年輕人看着窗外加州的陽光,
即使是當時最狂妄的夢想家,恐怕也不敢想象,
他們爲了打遊戲而設計的芯片,有一天會學會寫詩、學會作畫、甚至學會思考, 併成爲人類歷史上最強大的算力引擎。
黃仁勳曾說,英偉達成功的祕訣在於——總是去解決那些極其困難、且尚未有人涉足的問題(Zero Billion Dollar Markets)。
從故意對抗微軟標準導致的瀕臨破產,
到力排衆議在顯卡中塞入CUDA核心的至暗時刻,
再到那個決定將公司命運押注在深度學習上的週五夜晚,
這家公司無數次站在懸崖邊上,卻又無數次因爲對技術的偏執而絕處逢生。
今天的英偉達,已經不再是一家顯卡公司,甚至不再是一家AI公司,
它正在變成未來數字世界的基石,無論財報數字如何跳動,無論股價漲跌幾何,
從遊戲到AI,這段跨越三十年的技術長征,
這個故事本身,
就已經足夠傳奇。
全文完,
感謝一直追老黃髮家史的盒友們!

老黃髮家史系列
遊戲&AI系列:
AI——AI,是遊戲NPC的未來嗎?
巫師三——文生圖教程!SD3開源+ComfyUI,畫出你喜歡的小姐姐!
你的遊戲存檔——你的遊戲存檔,正在改寫人類藥物研發史——Nature諾獎遊戲項目
無主之地3——臭打遊戲,竟能解決人類大腸便祕煩惱——《無主之地3》科學遊戲
一句話造GTA——一句話生成GTA?全球首款A遊戲引擎Mirage上線!
AI女裝換臉——AI女裝換臉——FaceAPP應用和原理
AI捏臉技術——你想在遊戲中捏誰的臉?——最新的AI捏臉技術
Epic虛幻引擎——Epic虛幻引擎公開“元人類生成器”,小白也可參與遊戲開發(附教程)
腦機接口——魔幻的腦機接口技術——特斯拉、米哈遊等公司紛紛開始佈局
白話科普——白話科普——比特幣到底是如何誕生的?
永劫無間——永劫無間——肌肉金輪,AI如何幫助玩家捏臉?
Adobe之父——Adobe之父去世:曾發明PDF格式,助喬布斯封神
FPS遊戲之父——誰是最偉大的遊戲程序員?——FPS遊戲之父
《巫師3》MOD——《巫師3》MOD製作教程,從零開始!
#gd的ai&遊戲雜談#
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















