1993年的一个下午,黄仁勋与两位朋友,坐在硅谷一家Denny's餐厅闲聊,打算创立英伟达时——他们仅仅只希望打造一款能够提升计算机游戏体验的图形芯片。
但谁能想到,三十年后,这家公司会成为5万亿美元市值的AI巨头。而今天凌晨即将发布的三季度财报,甚至能成为全球股市的晴雨表。

如果我们回顾英伟达的历史,会发现黄仁勋的转型绝非偶然,
从游戏到AI,游戏在技术发展中所扮演的角色也非常重要,
今天就用这篇万字长文一起来看看英伟达的故事。

黄仁勋赠予马斯克OpenAI公司——全球第一款AI超算DGX-1
游戏的蛮荒时代
回到上世纪90年代,当时的PC游戏图形处理器市场非常混乱,
硅谷大量的公司在炒作“多媒体”新概念,
市场上充斥着数十家粗制滥造的初创公司,都想争夺对游戏图形处理器的主导权,
在这样的背景下,黄仁勋创立了英伟达,并推出第一款产品NV1。
NV1当时其实不仅仅是一张用来打游戏的图形处理器,
还集成了声卡处理能力,甚至还有世嘉游戏手柄的接口,
更致命的是,NV1在3D渲染技术上押错了宝,故意对抗微软主推的Direct3D标准,
老黄英伟达首款产品NV1直接失败,导致资金链断裂、公司进入破产边缘。

创立英伟达前,老黄曾在AMD工作
而当时真正的游戏霸主为3dfx,他们推出的Voodoo系列碾压NV1,
而且可以畅玩卡马克《雷神之锤》等早期3D游戏(卡马克详见唯一封神的游戏程序员——Doom的前世今生),
Voodoo 2更是引入SLO交火技术,允许两块显卡协同工作,这在当时也是游戏发烧友的毕业配置。
然而3dfx却在最巅峰时犯下两个致命错误,直接导致破产被收购,
一是3dfx收购了板卡制造商STB Systems(类似于今天的华硕微星),
3dfx想要大包大揽,从单纯的芯片供应商,转变为集设计、制造、销售于一体的垂直整合商。
但是3dfx的路显然是走错了,
因为哪怕英伟达已经到了如今这个级别,也仍然坚持只做芯片设计,
把制造交给台积电,板卡组装给到华硕、微星等合作伙伴,从而建立了庞大的生态联盟。
3dfx第二个失误是技术路线的错判,
他们认为英特尔CPU的性能增长足以处理3D场景中的几何运算,所以显卡主要专注于光栅化和纹理填充,
而英伟达却敏锐地预见到,随着游戏场景日益复杂,CPU同样将成为最大的瓶颈。

最强游戏程序员——约翰·卡马克
英伟达发明显卡
就这样,在1999年的8月31日,英伟达发布了GeForce 256,
在广告标语上,黄仁勋并没有说它是更快的图形加速卡,
而是创造了一个全新的术语——GPU,
也就是我们如今熟知的显卡,没错,显卡正是英伟达发明的。
根据英伟达官方定义,GPU每秒能够处理至少1000万个多边形,
性能较传统图形加速器提升了10倍以上,可以为游戏玩家提供更出色的3D游戏画面。
技术层面,GeForce 256的核心突破是硬件T&L,
专门负责3D图形生成过程中两个最重要的任务,分别为几何变换与光照处理。

GeForce 256
几何变换很简单,就是游戏中3D物体在虚拟空间中的位置、角度、大小,
然后从3D空间投影到你的2D屏幕上,这个过程涉及大量的矩阵运算(请记住矩阵运算,这点很重要),
光照处理就是根据场景中设置的光源,计算3D物体表面各点的明暗、颜色和阴影,
如今的虚幻五引擎其实仍然在解决这些图形学的这些问题,比如Nanite虚拟几何体用来几何细节处理,所以有了黑神话的细节,
再者用Lumen实现动态全局光照,背后同样是结合英伟达的硬件光线追踪技术,当然,这些都是后话了。

在英伟达GeForce 256出现之前,传统3D渲染流程需要大量的浮点运算,
一般这些繁重的数学任务由CPU承担,但黄仁勋把硬件T&L固化在GPU芯片的逻辑电路中,
所以专用电路处理特定数学运算的效率远高于通用CPU,
而且这种将特定数学运算(矩阵变换)转嫁给GPU的思路,
也刚好和后来AI深度学习中的矩阵乘法转嫁给GPU的思路完全吻合。
2000年底,英伟达的GeForce 256彻底碾压3dfx的Voodoo 5 5500芯片,
资金枯竭的3dfx反被英伟达收购,大量的图形工程师加入英伟达,这些人才也成为英伟达转型期的核心力量。

老黄的奇思妙想
进入21世纪,英伟达几乎垄断了高性能游戏图形市场,老黄开始思考下一步。
英伟达接下来的GeForce 3(NV20)引入了可编程顶点着色器,这是GPU历史上第二个里程碑。
在此之前,GPU的渲染流程是固定的,游戏开发者只能调整预设的参数,比如设定死的雾化浓度和光照颜色,
过去如果是固定比例参数设计,会导致非常严重的资源浪费,
比如在游戏复杂的水面波浪中,顶点非常密集,像素着色器可能处于闲置状态,
但是在复杂的阴影处理中,像素密集,顶点着色器又无所事事,这种非对称的负载导致GPU实际性能极其低下。
而全新的可编程着色器允许开发者编写微代码,直接控制每一个顶点和像素的生成逻辑,
这个技术也在G80架构的显卡GeForce 8800 GTX上达到顶峰,
G80支持微软全新的DirectX 10 API,彻底摒弃过去分离的顶点渲染管线和像素渲染管线,转而采用统一着色器架构,
此外G80拥有128个流处理器,这些处理器不再被硬编码为处理图形任务,
而是通用的浮点运算单元,系统可以根据负载动态分配它们去处理顶点、像素,
或者,
你也可以拿他们去做其他的数学运算。

8800 GTX
2006年,就在英伟达独孤求败之时,老黄推出了CUDA,这是一个软件平台和编程模型,
允许开发者使用C语言等高级语言直接调用GPU的并行计算能力,
开发者无需像过去那样通过图形API将计算任务伪装成纹理渲染任务,
简而言之,过去科学家们做科研数学计算时,都是把这些任务伪装成游戏开发图形处理的一部分,
但是现在,老黄要把每一张游戏显卡,改造成能够兼顾游戏和科研的计算芯片,
比如很多游戏玩家他就没有科研的需求,但是如果要兼具做通用计算,
那么每一颗芯片都要增加额外的逻辑电路,这也导致芯片面积增大良率下降,制造成本飙升。

为推广CUDA,英伟达选择了高校路线——
与全球顶级研究机构和大学合作,培养下一代开发者,
但从市场来看,当时只有极少数科研人员对GPU计算感兴趣,
绝大多数游戏玩家并不需要CUDA,但他们却不得不为这部分多余的芯片买单。

CUDA之父、英伟达首席科学家-大卫·柯克
显卡危机
本来游戏市场上做得好好的英伟达,直接老黄的奇思妙想差点拖垮,
从2007年开始,由于G80后续架构成本升高,再加上全球性金融危机影响,
英伟达的毛利率受到严重挤压,2009年的Q4营收同比暴跌60%,
华尔街的分析师们那几年也是英伟达的大空头,不断质疑老黄为什么要在游戏显卡塞入昂贵的计算功能,
而英伟达的股价长期徘徊在低位,甚至一度跌破10美元。

2007年这年还发布了一款非常有名的新游戏《孤岛危机》,
外号显卡危机,因为这款游戏对光影、物理破坏和植被渲染的要求达到了当时硬件无法承受的高度,
即便是卡皇8800 GTX也难以在最高画质下维持60帧的流畅度,
所以《孤岛危机》的存在成为了后续几年显卡性能提升的标杆,
为了征服《孤岛危机》,老黄也带领英伟达进入了游戏卡架构发展的快车道,
然而神奇的是,这些游戏卡也在不经意间敲开了AI神经网络的大门。

老黄皮衣技术大会
上文说到,由于CUDA发展初期,老黄投入巨大而商业回报不明,
英伟达饱受华尔街质疑,股价承受压力,老黄觉得可以参考学术会议,
由他自己牵头,邀请全世界的学者一起参加英伟达的技术大会,共同探讨显卡的未来发展方向。
对于大多数游戏玩家,以及当时华尔街的投资者们来说,
老黄最重要的事情是赶紧迭代显卡把《孤岛危机》拿下,尽快赚钱把股价拉上来,
但老黄认为最重要的事情是让英伟达能够利用游戏显卡,去解决那些科学上的问题。

但是老黄本质上也只是工程师而已,他没有能力像马斯克那样解决从0到1的问题,
而且老黄自己也非常迷茫,英伟达显卡到底在哪个学术领域发光发热,连他自己也摸不清楚,
所以在2009年,老黄在英伟达首席科学家柯克的建议下,一起召开了第一届英伟达GTC大会,
会议上老黄常常身着皮衣与大家交流,所以皮衣也逐渐成为老黄标志性象征。

2010年的第二届GTC大会,老黄隆重推出了基于Fermi架构的GTX 400系列,
比如GTX 460,顺便提一嘴,当时你去买电脑的话一般都叫独立显卡,
Fermi是为了致敬物理学奖费米教授,Fermi的架构在设计上极度激进,
引入完整的 L1/L2 缓存层级、ECC内存支持以及大幅增强的双精度浮点,
拥有512个CUDA核心,支持C++,极大降低开发门槛,让那些习惯于x86编程的科学家也能轻松移植代码。
但是在消费级显卡市场,Fermi 的这种“重计算”设计带来了巨大的副作用,
因为大量的晶体管被用于对游戏性能贡献不大的计算逻辑和缓存控制上,
所以GTX 480运行时温度极高,也被玩家戏称是“核弹”或“煎蛋器”,能耗比相当糟糕。

GTX 580的奇迹
2011年,英伟达改善了GTX 480的功耗和发热问题后,又推出了GTX 500系列,
其中GTX 560Ti是中高端显卡,超频潜力也不错,成为众多玩家的首选,
而GTX 580则是满血版Fermi架构,稳稳坐上了单芯卡皇的宝座,
或许谁也没有想到,英伟达命运的齿轮,在GTX 580这张卡上开始转动。

2012年,当时多伦多大学有一位常年失意的教授,名叫杰弗里·辛顿(Geoffrey Hinton),
辛顿出自学术世家,外高祖父乔治·布尔创立了布尔代数,
高祖母玛丽的叔叔乔治·埃佛勒斯是地理学家,珠穆朗玛峰“Mount Everest”即以他的姓氏命名,
曾祖父查尔斯·辛顿是数学家兼科幻作家,提出“四维超正方体”概念,影响后世科幻作品,
布尔的女儿伏尼契是名著《牛虻》的作者,父亲霍华德·辛顿是剑桥大学教授、著名昆虫学家,
辛顿还有一位堂姑琼·辛顿是核物理学家、杨振宁同事,曾参与曼哈顿计划,
这位姑姑的中文名我们更熟悉,名叫寒春,也是第一位获得中国“绿卡”的外国人,
当然,啰唆了这么多,辛顿在2012年的时候并没有他祖上这些名人那么成功,
因为辛顿研究的是一项已经被判了死刑的方向——神经网络,也是整个领域攀登难度最大的珠穆朗玛峰。

在2012年以前,计算机方向几乎所有的权威专家,都认为神经网络已死,
别说是专家,就连老黄这位斯坦福EE研究生,同样也不看好神经网络。
这个故事还得追溯到上世纪60年代,当时也有一股人工智能热——感知机,
很多人都把AI的突破寄希望在感知机上,但是到了1969年,
明斯基从理论上指出了感知机的根本性局限,给神经网络泼了一盆凉水,
虽然到了80年代,辛顿等人提出了BP反向传播算法,但是如果训练更深层的网络时,
网络就会出现梯度消失/爆炸问题,导致模型难以有效学习,
而且当时的计算机硬件计算能力有限,训练一个稍复杂的神经网络可能需要数天时间,成本高昂且效率低下,难以投入实用。
与此同时,支持向量机SVM等统计学习方法在诸多任务上表现更为稳定和出色,
吸引了大量学者,也使得神经网络处于边缘地位,而辛顿则是一直坚持坐冷板凳,直到英伟达GTX 580的诞生,以及另一位天才的横空出世。

Ilya与AlexNet
如果问谁对AI的贡献最大,绝对有Ilya Sutskever的名字,
回到2012年,他当时是辛顿教授的博士生,与另一位博士生Alex一起打一场比赛,
比赛的名字为ImageNet大规模视觉识别挑战赛,比赛发起者正是斯坦福的华裔教授李飞飞,
当时是第三届ImageNet大赛,前面两届获胜团队使用的还是传统的机器学习方法,
但是到了2012年,Alex和Ilya决定使用最新的英伟达GPU来加速神经网络,
在Ilya之前,从未有人尝试过拿打游戏的GPU来训练神经网络,
于是Ilya回到自己的宿舍,用攒下的钱买了两块GTX 580,
但是Ilya发现GTX 580仅有3GB显存,无法容纳拥有6000万个参数和65万个神经元的模型,
为了突破显存限制,Alex设计了一种特殊的网络架构,将神经网络切分到两块GPU上,
两块GPU分别负责一半的神经元计算,只在特定的层级进行数据通信,
这也是人类历史上首次模型并行计算,也是十多年后万亿参数大模型多卡训练的雏形。

经过不到一周的训练,Ilya发现原本需要数月才能完成的训练,在两块GTX 580上仅用了5-6天,
而且在2012年的的ILSVRC竞赛中,辛顿团队的AlexNet以15.3%的Top-5错误率夺冠,
比第二名(使用传统计算机视觉方法)的26.2%低了整整10.8个百分点,
这是一个断崖式的领先,也瞬间宣告了传统计算机视觉时代的终结。
老黄这才猛然意识到,他一直不看好的神经网络,居然和自家显卡擦出最完美的火花,
于是老黄联系上斯坦福另一位非常有名的华裔教授Andrew Ng吴恩达,
经过交流之后,老黄认定CUDA架构原来不仅仅能做物理模拟,在神经网络深度学习领域更是天作之合,
据英伟达内部人士及多次访谈回顾,2012年一个周五的晚上,
黄仁勋在深思熟虑后,向全体员工发送了一封具有历史转折意义的内部邮件,
在这封邮件中,他做出了两个惊人的判断:
深度学习将从根本上改变软件的编写方式。 软件将不再是由人类编写逻辑,而是由数据训练生成。
英伟达不再仅仅是一家图形处理公司,而是一家AI公司。

游戏xAI
这封邮件也成为英伟达历史上最激进的转型,
英伟达硬件层未来的GPU架构将针对AI算子(矩阵乘法)进行特化设计,
软件层方面则组建团队开发cuDNN,这是一个专门针对深度学习框架优化的底层库,
老黄也开始直接向全球的AI实验室赠送显卡,并派遣系统工程师驻场协助优化代码。
与此同时,随着AI需求的指数级增长,老黄发现,
服务于游戏玩家的显卡,和服务于数据中心的加速卡,在需求上出现了不可调和的矛盾。
游戏需要强大的光栅化能力、纹理处理单元和显示输出接口;
而AI训练需要极致的矩阵吞吐量、超高带宽的显存(HBM),却几乎不需要图形输出功能。
为了能够同时统治游戏市场和AI市场,英伟达也在显卡架构上进行了关键的大分流。

2012年的GTC大会,老黄发布了Kepler架构,推出GTX 600系列,
与前代Fermi相比,新架构引入了全新流式多处理器设计,
GTX 680节省的空间里塞了1536个CUDA核心,性能提升三倍,功耗也大大降低,
与此同时,老黄还推出了Titan系列,这个系列非常短命,
初代Titan不仅是顶级游戏卡,也是科研人员和深度学习研究者的廉价超级计算机。
2014年的GTC大会,Maxwell架构与GTX 900系列发布,GTX 960、GTX 970成为市场的主流型号,
旗舰卡是980Ti,但是Maxwell架构的真·旗舰卡要等到第二年。

2014年的GTC大会
深度学习大爆炸
2015年的GTC大会,老黄发布了真正的顶级旗舰卡Titan X,
CUDA核心跃升到了3072个,显存容量来到12GB,
这款显卡也是被老黄明确定义为深度学习专用卡,
如果实验室不缺钱,还可以用四块Titan X交火的DIGITS DevBox工作站,
其实从14、15年开始,英伟达显卡的设计重心就已经倒向了AI,
但是因为16年老黄发布了GTX 10系显卡,玩家们对英伟达重心转移到AI的认知反而滞后了好几年。

2016年的GTC大会,这届既是深度学习大爆炸的盛会,同样也是玩家群体的盛宴,
笔者也是从这一年开始长期更新GTC大会的技术研报,
老黄会议上发布了全新的Pascal架构,仍然延续两年发布一个新架构的模式,
但是这代新架构的技术迭代是最大胆的,
Pascal架构首次引入了NVLink高速互联技术,可以提供160 GB/s的双向带宽,远超传统的PCIe 3.0,
这也使得多个GPU之间以及GPU与CPU之间的数据交换效率大增,特别适合多卡并行计算场景(也就是当年AlexNet双卡GTX 580的训练场景)。

基于Pascal架构的Tesla P100加速器,则是数据中心和高性能计算领域的里程碑,
Tesla P100率先使用HBM2高带宽显存,通过CoWoS封装技术,实现720 GB/s的内存带宽,
而最近一年内存紧张价格暴涨,源头也可以追溯到这里,
当时传统显存是GDDR,而HBM2是一种立体堆叠结构的显存,
可以把多个DRAM芯片在垂直方向上层叠起来,性能极高,而且功耗远低于当时的GDDR5显存,
目前全球仅有三星、SK海力士和美光等几家公司可以大规模生成HBM,
也导致高端HBM内存供应紧张,当然现在普通的显存和高端的HBM都是产能短缺的状态。
另外,老黄还首次发布了DGX-1超级计算机,集成了8块Tesla P100 GPU。

游戏玩家的盛宴
对于任何一名硬件老玩家来说,想必没有什么比GTC 2016新显卡发布更震撼的时刻了,
这年老黄还发布了基于Pascal架构的10系显卡,
入门级GTX 1060的性能甚至超越了上一代旗舰GTX 980,却保持着甜点卡的定价,
随着PUBG的兴起,1060也成为标配,逐渐也成为Steam硬件统计中最大的钉子户,
而随着挖矿的崛起,1060的5GB/6GB和1070/1080/1080Ti等型号也成为矿场的首选。

Attention Is All You Need
进入2017年,6月12日,一篇名叫《Attention Is All You Need》的论文发布在arXiv上,
随后在顶会NeurIPS上正式发表,作者来自谷歌的八位研究者,
不过真正等到这篇论文一统江湖还要几年后了。
这年的GTC大会,老黄首次引入了专为AI计算设计的Tensor Core,
在Tensor Core出现之前,GPU主要依赖CUDA Core进行各种并行计算,
但是CUDA core做矩阵乘法运算的效率仍有提升空间,
一个CUDA Core每个时钟周期通常只能完成一次乘加操作,
Tensor Core则是一种专用集成电路,经过特殊设计,每个时钟周期可以完成一个小的4x4矩阵的乘加运算,
从这时开始,我们眼中熟悉的游戏显卡,也朝着更适用于AI并行计算的方向去发展,
也恰恰是这个创新,让之后训练大型深度学习模型的时间从数周缩短到几小时成为可能。
AI反哺游戏
2018年的GTC大会,这年仍然是AI和游戏两条主轴,
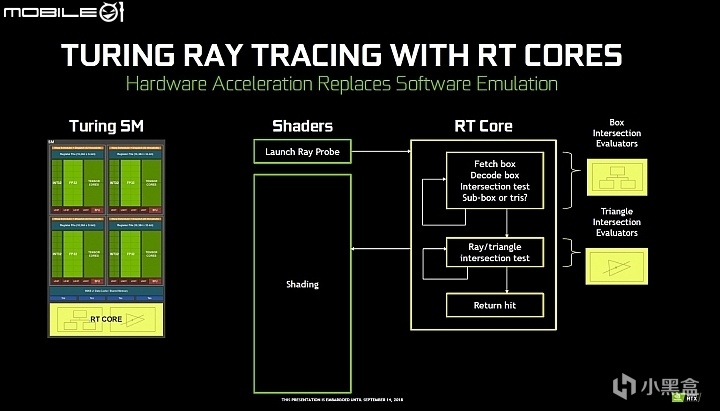
老黄致敬图灵推出了全新的Turing架构,引入了专用的RT Core硬件单元,
Turing架构也是首个同时集成RT Core和Tensor Core的消费级架构,
Tensor Core用来做AI,RT Core用来打游戏,
而Tensor Core刚好又很擅长做AI算法,可以把低分辨率图像高质量放大,
所以就有了DLSS大力水手技术,这样的话AI也可以反哺游戏。
在数据中心端,英伟达发布了NVSwitch芯片和DGX-2超级计算机,
拥有512GB的HBM2显存空间,16块V100 GPU,能够以300 GB/s的速度全互联,
这一年的热门方向有一路发展到顶峰的生成对抗网络GAN,
计算机视觉CV四小龙风光无限,深鉴科技、寒武纪轮番成为主角,
这年10月同样由谷歌团队发表的BERT论文,也掀起自然语言理解NLP的热潮。

游戏端则是由GTX变成了RTX时代,甜点卡2060依然能打,
高端卡2080TI/2080因为矿潮的影响,生命周期大大延长,
虽然16年和18年GTC大会内容都不少,
但是20系的升级远远没有10系性能提升那么震撼,
10系Pascal架构的成功,很大程度上得益于从28nm到16nm的巨大制程红利,
而20系Turing架构的复杂性远超前代,全新的DLSS技术一开始也是褒贬不一,争议也一直持续至今。

大模型时代
接下来的2020年GTC大会,则彻底沦为AI的独角戏,
这年大会是首次在线上举办,老黄推出全新的Ampere架构,
GPT已经迭代到GPT-3,彻底破圈引爆全球,
老黄介绍的产品首先就是卖爆了的A100系列,也是AI训练的主力,
同步推出的还有30系显卡,搭载第二代RT Core和第三代Tensor Core,
再加上三星8nm工艺和高速GDDR6X显存,
但30系给人印象最深的,也仅有感谢2077帮我买到原价的30系显卡......

GTC 2020
由于玩家长时间买不到正常价格的显卡,30系仿佛是被跳过的一代,
那几年也让人遗忘,但是老黄在AI上面发力可是一点也不少。
2021年的GTC大会,英伟达正式确立了 GPU + CPU + DPU 的三支柱战略,
这里面游戏只占很小一部分,其中CPU也是专用于大模型的Grace CPU,并不在消费级产品范畴。
2022年的GTC大会,GPT的火彻底点燃工业界,老黄带来了销量王Hopper架构,
也是把英伟达推上五万亿宝座的主力,基于Hopper架构的H100也是专为LLM大模型量身定做,
H100搭载Transformer引擎,将Transformer模型的训练速度相比A100提升6倍,
游戏玩家这边由30系的Ampere架构升级为40系的Ada Lovelace架构,
搭载第三代RT Core和第四代Tensor Core,支持DLSS3和光学多帧生成(智能插帧)。

GTC 2022
2023年的GTC大会则是改变了英伟达只卖硬件的模式,
转而和Oracle、Microsoft Azure、Google Cloud合作推出了DGX Cloud服务。
今年的GTC大会刚开完不久,去年底到今年可以说是推理元年,
24年GTC大会,老黄专为万亿参数推理大模型设计了Blackwell架构,
GB200 NVL72搭载36个Grace CPU和72个Blackwell GPU,可以单机架运行万亿参数模型,
同时到来的还有搭载Blackwell同架构的50系显卡,完全是挤牙膏式升级,用心程度远远比不上AI......
今年GTC大会英伟达加快了迭代节奏,针对对长上下文推理推出Blackwell Ultra,
显存升级到最新的HBM3e,可以容纳巨大的KV Cache,
下一代Rubin架构仍在大饼状态,计划引入HBM4e,支持NVLink 6互联。

卖铲子的老黄
英伟达的GTC大会讲到这里也就结束了,但是英伟达的故事还远未结束。
当我们把目光从令人眼花缭乱的架构和技术里收回,重新审视英伟达当下的处境,
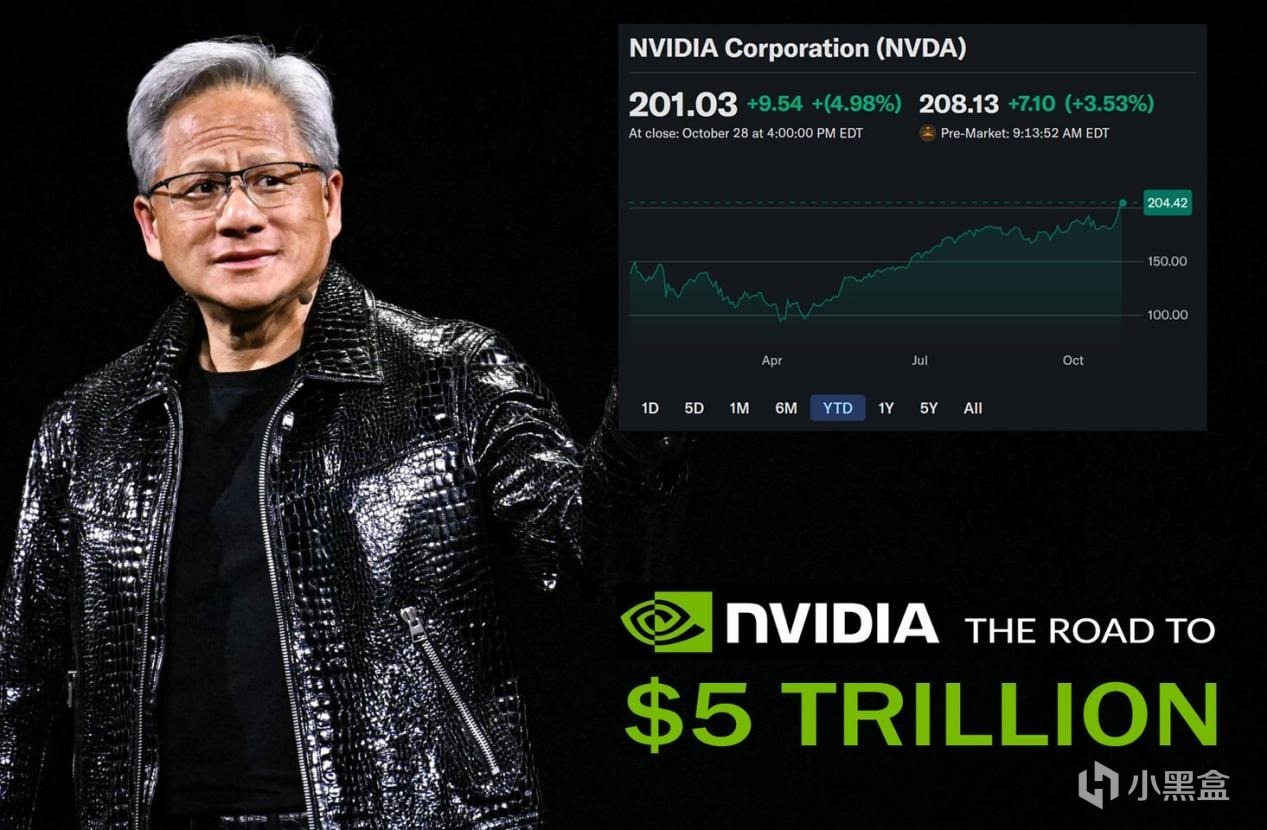
会发现从2023年开始,几乎硅谷所有的巨头都在给老黄打工,
微软、Meta、谷歌、亚马逊,他们为了拿到AGI算力的船票,几乎排着队采购H100,
这就像当年的淘金热,无论是挖到金子的(OpenAI),还是没挖到的,
都得先向卖铲子的人——英伟达,缴纳昂贵的过路费,
这种极度的供需失衡,造就了英伟达恐怖的利润率,也将市值推向了难以置信的高度。
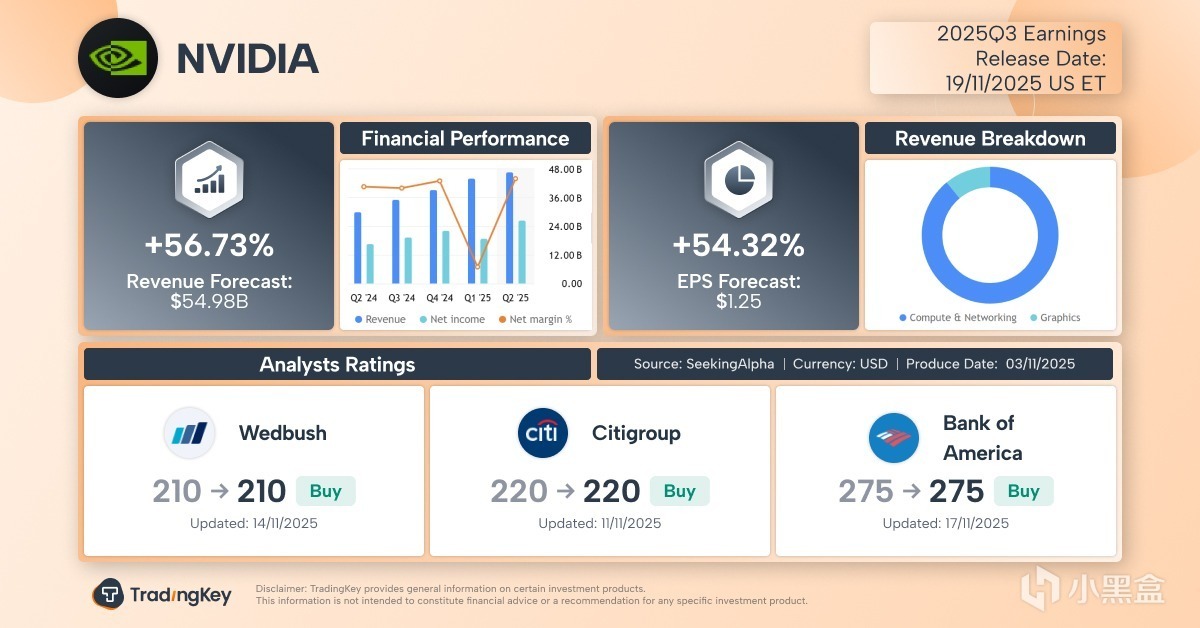
而今天凌晨的这份Q3财报,之所以被视作“全球股市晴雨表”,
是因为华尔街想要确认两件事,第一,AI的泡沫到底有没有破裂的迹象?
如果连“卖铲子”的人业绩都开始下滑,说明淘金客们已经没钱了;
第二,Blackwell的出货是否顺利?此前传出的散热问题是否会影响量产进度?
在某种意义上,英伟达的财报已经不再属于一家公司,而是成为了整个AI产业链的信心指数。
作为一名玩家的后话
而回到我们最初的话题,在英伟达如今庞大的AI帝国版图中,
那个曾经陪伴无数少年在网吧通宵、在宿舍开黑的N卡,似乎变得不再重要了,
我们能负担得起显卡的价格,却很难找到儿时的那种快乐,
英伟达和老黄也变得不那么有人情味,数据中心业务的营收占比早已碾压游戏业务,
显卡价格越来越贵,显存给得越来越抠搜,我们玩家也已经被老黄抛弃,成为了AI发展的垫脚石。
这听起来非常残酷,但也是事实。
从技术发展角度看,如果没有游戏市场,英伟达显卡或许就不会诞生,
如果没有玩家这三十年来的支持,为英伟达提供了源源不断的研发资金,AI的爆发可能还要推迟十年;
反过来,如果没有AI带来的技术反哺,在摩尔定律已死的今天,
单纯靠堆晶体管,我们也可能迟迟无法在消费级显卡上实现突破,
未来的游戏,或许不再是单纯的图形渲染, 而是像《黑客帝国》那样,
由AI实时生成的、无限细节的虚拟世界——
或许也就是老黄口中那个融合了图形学与AI的终极目标:Omniverse(全是大饼)。

故事的最后,让我们把时钟拨回到1993年的那个下午,
硅谷那家Denny's餐厅里,那三个年轻人看着窗外加州的阳光,
即使是当时最狂妄的梦想家,恐怕也不敢想象,
他们为了打游戏而设计的芯片,有一天会学会写诗、学会作画、甚至学会思考, 并成为人类历史上最强大的算力引擎。
黄仁勋曾说,英伟达成功的秘诀在于——总是去解决那些极其困难、且尚未有人涉足的问题(Zero Billion Dollar Markets)。
从故意对抗微软标准导致的濒临破产,
到力排众议在显卡中塞入CUDA核心的至暗时刻,
再到那个决定将公司命运押注在深度学习上的周五夜晚,
这家公司无数次站在悬崖边上,却又无数次因为对技术的偏执而绝处逢生。
今天的英伟达,已经不再是一家显卡公司,甚至不再是一家AI公司,
它正在变成未来数字世界的基石,无论财报数字如何跳动,无论股价涨跌几何,
从游戏到AI,这段跨越三十年的技术长征,
这个故事本身,
就已经足够传奇。
全文完,
感谢一直追老黄发家史的盒友们!

老黄发家史系列
游戏&AI系列:
AI——AI,是游戏NPC的未来吗?
巫师三——文生图教程!SD3开源+ComfyUI,画出你喜欢的小姐姐!
你的游戏存档——你的游戏存档,正在改写人类药物研发史——Nature诺奖游戏项目
无主之地3——臭打游戏,竟能解决人类大肠便秘烦恼——《无主之地3》科学游戏
一句话造GTA——一句话生成GTA?全球首款A游戏引擎Mirage上线!
AI女装换脸——AI女装换脸——FaceAPP应用和原理
AI捏脸技术——你想在游戏中捏谁的脸?——最新的AI捏脸技术
Epic虚幻引擎——Epic虚幻引擎公开“元人类生成器”,小白也可参与游戏开发(附教程)
脑机接口——魔幻的脑机接口技术——特斯拉、米哈游等公司纷纷开始布局
白话科普——白话科普——比特币到底是如何诞生的?
永劫无间——永劫无间——肌肉金轮,AI如何帮助玩家捏脸?
Adobe之父——Adobe之父去世:曾发明PDF格式,助乔布斯封神
FPS游戏之父——谁是最伟大的游戏程序员?——FPS游戏之父
《巫师3》MOD——《巫师3》MOD制作教程,从零开始!
#gd的ai&游戏杂谈#
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















