今年開年,DeepSeek在全球爆火,掀起了一波AI熱潮,最近給大家連續更新了兩週英偉達老黃系列,文章中頻率出現最高的就是深度學習和神經網絡這些熱門術語,兩個月前,我又給大家更新了2025年版本的AI入坑深度學習的指南。今天這篇文章就繼續聊聊我這段時間重新蒐集整理的神經網絡綜述,老黃髮家史系列硬核部分爲了照顧多數讀者,所以省略了很多,今天這篇文章專業性會略強一些。

01 什麼是綜述
最近十多年時間,人工智能是全球最熱門的話題,
很多其他領域的學生或者從業人員,可能會感到非常焦慮,
但如果你想要真正去了解AI,
看自媒體那短短几十分鐘的視頻,
還是遠遠不夠的,
而對於大多數人來說,
也不太可能系統把神經網絡的論文全都讀一遍,
這篇綜述文章可以快速幫你梳理神經網絡的發展歷程,
即便沒有專業背景,
也能對神經網絡這個領域有一個清晰、全面的認識。

02 神經網絡
在老黃髮家史中,我們看到英偉達的轉折點是2012年,
當時辛頓教授團隊,在ImageNet圖像大賽上以壓倒性優勢奪冠,
此後卷積神經網絡成爲顯學,
英偉達的AI加速卡成爲各國核戰略級別的算力資源,
而最近十多年的各種科技突破中,
多數都用到了卷積神經網絡,
比如擊敗柯潔、李世石的AlphaGo,
用於手機解鎖、安防領域的人臉識別系統,
車企廠商自動駕駛中的物體檢測,
醫學腫瘤檢測CT/MRI影像自動診斷,
AI繪畫生成工具Stable Diffusion,
和大型語言模型LLM等應用,
如果你想探索這些技術背後的原理,
那麼卷積神經網絡(CNN)就是入門AI的第一步!

CNN的誕生與人工神經網絡(ANN)發展密不可分,
最早可以追溯到1943年,
當時McCulloch與Pitts提出首個神經元數學模型,
50年代末,羅森布拉特在MP模型基礎上增加學習能力,
提出單層感知機模型,你可以把它想象成一個自動分類的簡易開關,
核心任務非常簡單,就是根據輸入的特徵(比如蘋果的顏色、大小),
快速判斷它屬於哪一類(比如“好蘋果”或“壞蘋果”),
但是單層感知機無法解決計算機中的線性不可分問題(比如異或XOR問題),
通俗來說,單層感知機模型就是一臺只會畫直線的分類器,
靠試錯調整自己的判斷標準,是AI世界裏的入門學步車,
想要讓感知機變強,就得給它加層加神經元,
於是,一門研究如何讓感知機網絡層數加深的學科出現了,
也就是深度學習的雛形。

神經網絡之父辛頓 出席上海WAIC 2025
03 深度學習
很多人誤以爲AI的入門非常難,需要很強的數學基礎,
但實際上,學好大學基礎的線性代數課程,
再加上一點微積分入門課程,就足以看懂卷積神經網絡。
1984年,辛頓教授提出了用於多層網絡的誤差反向傳播——BP算法,
併成功訓練了多層感知機MLP,
BP算法是整個神經網絡訓練的基石,
無論是FSD自動駕駛模型,還是LLM大語言模型,
挖掘到模型的核心都是依賴BP算法來不斷進行學習,
區別就是多層感知機的參數很少,
而如今70B通用模型參數規模達到數百億之巨。
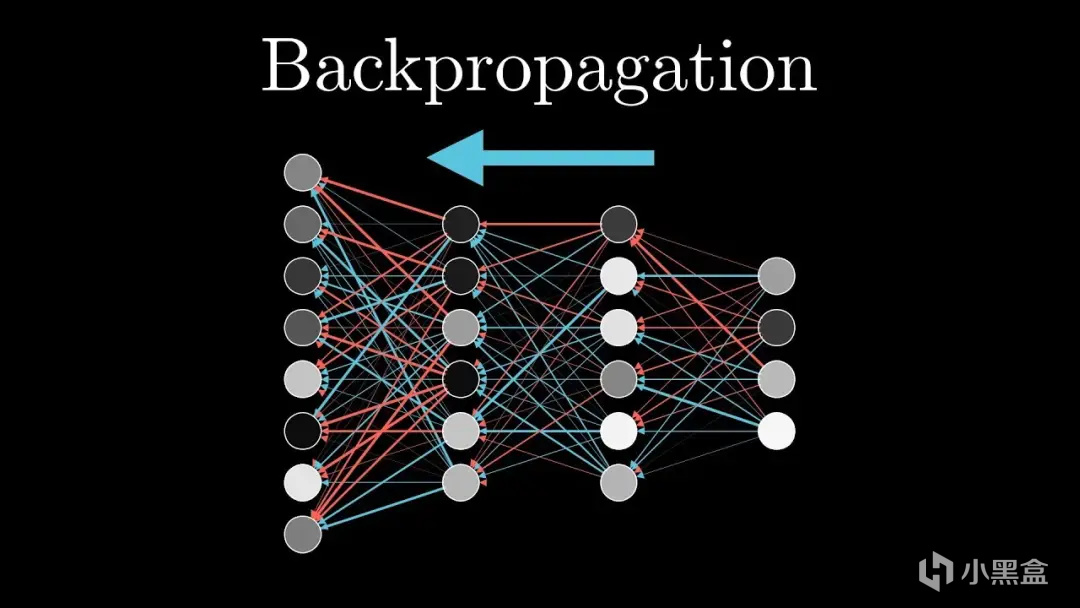
辛頓多層感知機的突破,是在輸入和輸出之間加入隱藏層,
形成多層結構,第一層識別簡單特徵(如線條),
第二層組合成複雜特徵(如形狀),層層遞進,
每層後加入Sigmoid、ReLU這種非線性函數,
將直線“彎曲”成曲線或折線,從而擬合複雜邊界,
從輸出層開始,按“誰導致我出錯,我就糾正誰”的邏輯,
用微積分的鏈式法則計算每層權重的梯度,
一句話公式簡化:
梯度 = 輸出誤差 × 激活函數的導數 × 前一層輸出值,
BP算法負責沿梯度反方向調整權重(梯度下降),減少誤差。

04 手寫體識別
90年代,Yann LeCun等人構建了用於手寫郵編識別的卷積網絡,
這也是歷史上首次使用"卷積"術語,
歷史上第一個卷積神經網絡LeNet-5誕生。
手寫體識別是計算機視覺最經典的任務
(如果你把這一小節內容消化好了,
本科畢業論文做個類似於手寫體識別的小實驗就算非常不錯了),
簡而言之,手寫體識別就像教電腦“看懂”人隨手寫的字,
首先需要把你寫的字拍成照片,組成一個圖像數據集MNIST,
這些圖像可能模糊、歪斜或有背景干擾,
傳統方法是電腦拿着字的特徵圖,去對比字庫進行識別,
這類方法在計算機領域統稱爲專家系統,
類似於制定規則讓電腦去死記硬背,
雖然規則你可以做到很完美,但遇到字跡潦草或變形時就容易掛科。

MNIST
這也是過去幾十年AI無法突破的原因,
所有學者都想盡可能去完善規則,
而卷積神經網絡更像是一個黑箱模型,
Yann LeCun教授首先將圖像轉化爲灰度圖作爲原始圖像輸入,
然後通過神經網絡的卷積層提取低級特徵,
再用池化層降維,LeNet-5通過卷積→池化交替兩次,
最後通過全連接層+Softmax函數輸出0-9的分類概率,
LeNet-5只需要10個訓練週期(Epoch),測試集準確率可達98%以上,
LeNet在歷史上首次驗證了CNN在視覺任務中的可行性,
直接啓發了AlexNet、ResNet等後續模型。
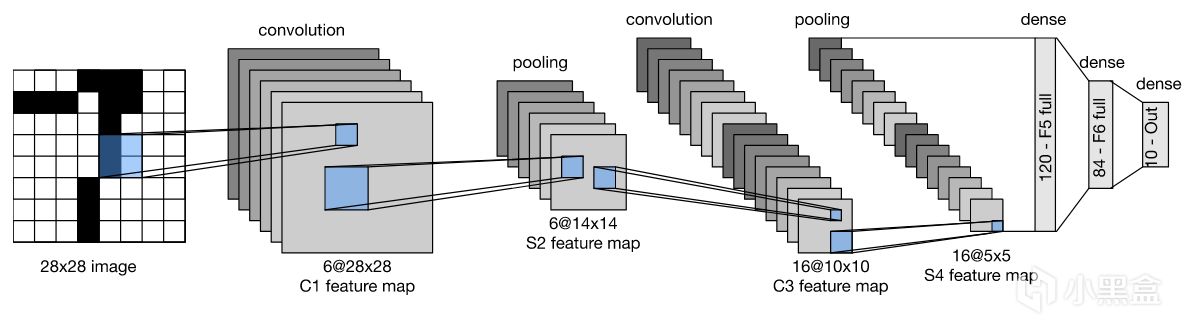
LeNet
05 深度學習的困境
如果你沒看過老黃髮家史,可能會非常疑惑,
爲什麼1998年最早的卷積神經網絡LeNet-5就已經成功,
但是真正的AI元年卻要等到2012年的AlexNet,
答案很簡單,深度學習有不少難題,
比如反向傳播算法非常強大,
但是當研究人員嘗試構建更深的網絡時,
會出現梯度消失和梯度爆炸,
BP中的梯度信號經過多層傳遞後變得過小或過大,導致網絡無法有效學習,
而且深度網絡還更更容易陷入局部最優解,出現過擬合問題。
率先取得突破的又是辛頓教授,他在2006年發佈了DBN深度信念網絡,
首次提出逐層預訓練的方法(如今大模型領域,預訓練也是最核心的方法),
即先用無監督的方式逐層訓練網絡,
然後再使用反向傳播算法對整個網絡進行微調。
不過方法再好也需要能打硬仗的“武器”,
LeNet-5僅2個卷積層,難以學習複雜特徵,
一旦把網絡加深,參數量又太大,
訓練10層網絡需TB級數據與TFLOPS算力,
而2000年代初CPU僅GFLOPS水平,
所以深度學習的發展又阻滯了十多年,
再次淪爲學者眼中沒有任何前途、已經被判死刑的領域。

黃仁勳 辛頓
06 AlexNet革命
現在人工智能有一大堆熱詞,數據科學、大模型、深度學習等等,
但AI真正最需要的是三要素,分別是數據、算法和算力,
只有三者都取得突破,人類纔會迎來嶄新的技術革命,
有意思的是,其中兩個要素都是華人解決的,
時間點仍然是2006年,李飛飛從錢老的母校加州理工學院博士畢業,
開始着手創建人類歷史上最大的圖像數據集,
包括2萬個類別、上千萬張圖像,李飛飛將這個數據集命名爲AlexNet,
黃仁勳則在06年推出了CUDA,
把顯卡賣給玩家籌錢,用來研發科學計算領域,
而辛頓則在06年陸續收下了兩名學生,分別是Alex和Ilya。

三條主線在2012年正式相遇,
Alex和Ilya省錢自掏腰包購入了兩塊英偉達GTX 580顯卡,
使用老師一生堅持的卷積神經網絡,去打ImageNet挑戰賽,
Alex的AlexNet以壓倒性優勢奪冠,直接震驚了整個計算機視覺領域!
對比初代卷積神經網絡LeNet-5,
AlexNet有幾項關鍵性的突破,
一是ReLU激活函數,解決梯度消失問題,加速訓練;
二是Dropout正則化,可以抑制過擬合,提升泛化能力;
三是GPU並行訓練,首次利用雙GPU分載計算,突破算力瓶頸;
這些直接解決了90年代和00年代導致深度學習陷入困境的三大問題,
AlexNet成功證明CNN在複雜的視覺任務上性能遠超其他模型,也直接開啓了AI元年!
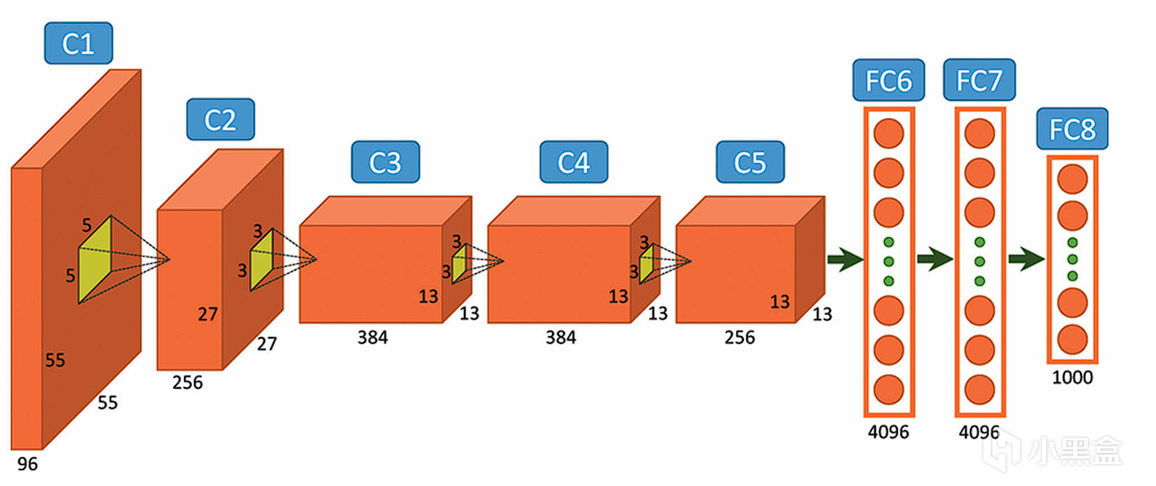
AlexNet
07 越深越好
Alex和Ilya公開了AlexNet的細節,
像谷歌、微軟這樣的大公司也紛紛復現AlexNet,
同時琢磨如何提升AlexNet的性能,
其中最顯而易見的方法就是讓神經網絡變得越深越好
(不然爲什麼叫深度學習),
於是到了13、14年的ImageNet大賽,
VGGNet堆疊了16-19層卷積層,
整個網絡幾乎完全由小尺寸3x3的卷積核和2x2的最大池化層堆疊而成,
網絡性能得到大幅度提升。
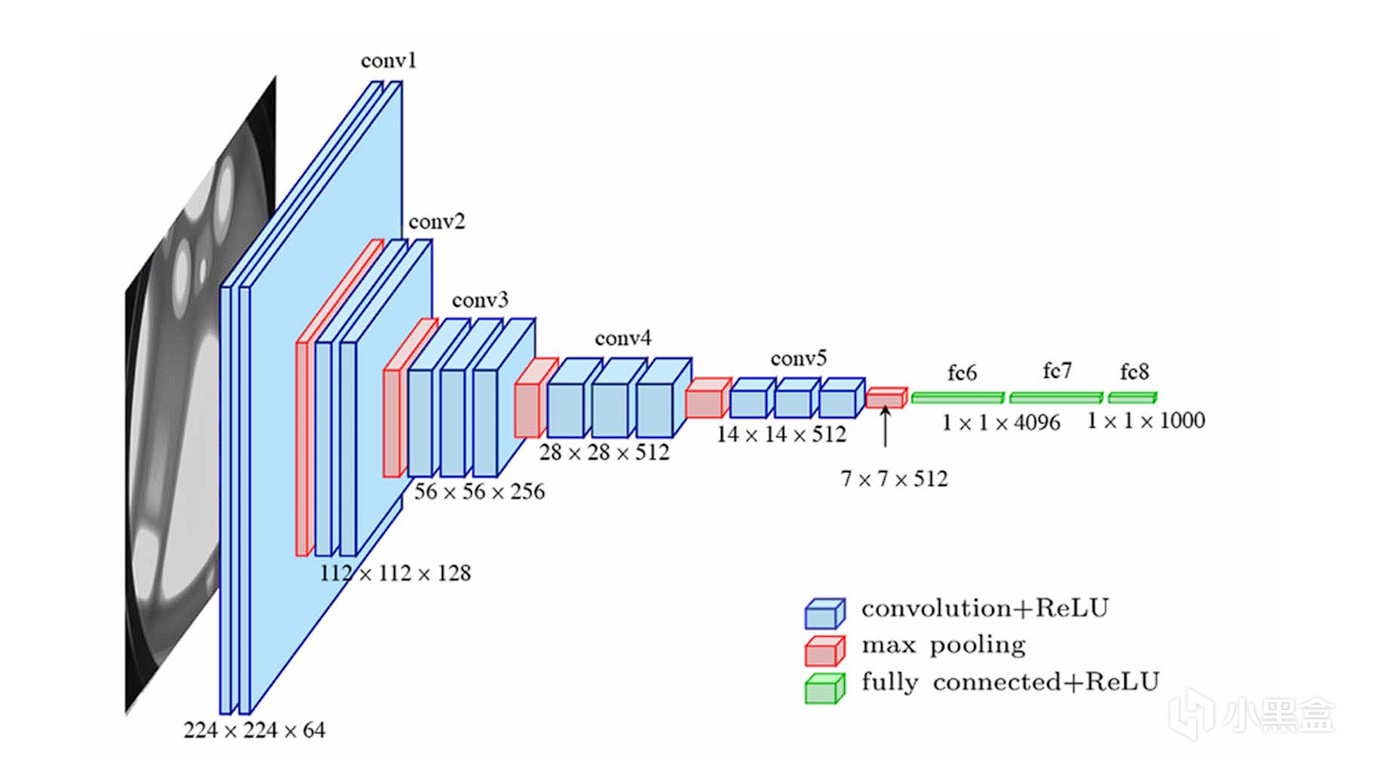
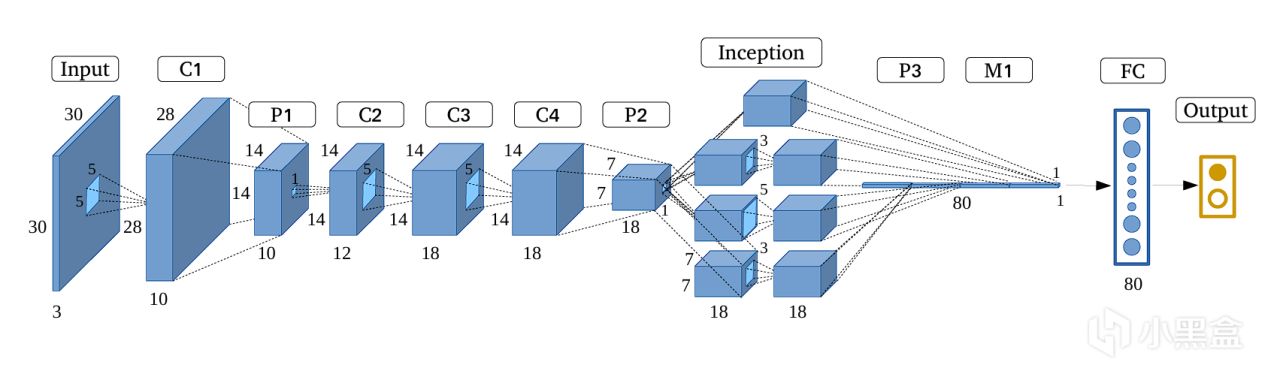
而真正讓人大喫一驚的還是谷歌,他們直接堆疊了一個22層的超深網絡,
拿下2014年ImageNet大賽的冠軍,
而谷歌還不止是單純追求深度,他們還創建了Inception模塊,
在同一層級上並行地使用多種不同尺寸的卷積核(1x1, 3x3, 5x5)和一個最大池化操作,
將所有輸出的特徵圖在通道維度上拼接起來,
讓網絡能夠同時捕捉不同尺度的特徵,
谷歌將這個網絡命名爲GoogLeNet,
既是套用Google的名字,也是致敬初代神經網絡LeNet,
後續谷歌財大氣粗還對GoogLeNet的架構進行優化,
推出了v2、v3和v4版本,網絡越來越深,參數量越來越大,
其中最贏麻的還得是老黃,畢竟參數越多,
就越需要他的AI加速卡。
GoogLeNet
08 何愷明ResNet
接下來的2015年,又是一位華人科學家改變了AI的歷史進程,
何愷明等學者發現神經網絡層數在超過20層後會出現退化現象,
即層數增加,準確率不升反降,但這又不是過擬合,
因爲深層網絡梯度反向傳播時易消失/爆炸,而且難以學習恆等映射,
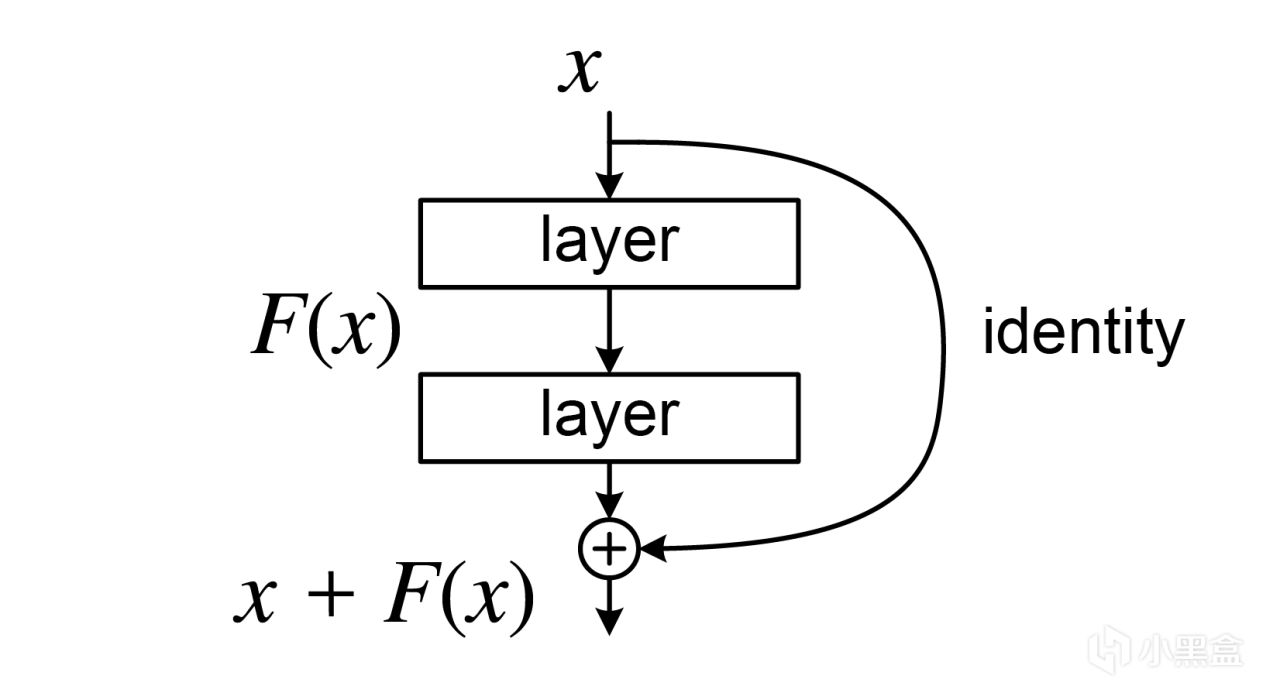
所以何愷明提出了全新的殘差連接(Residual Connection),
殘差連接的結構真的特別特別簡單,
核心設計僅用一個學習殘差的運算,就顛覆了深度學習的發展軌跡,
一句話計算殘差 F(x) = H(x) - x,取真實目標與輸入的差值,
Residual Connection
ResNet僅用兩種殘差塊就支撐起18~152層的所有模型,
傳統網絡20層後梯度衰減至近乎0,
而ResNet-34在ImageNet上錯誤率26.7%,遠低於 34層傳統CNN的37%,
並且ResNet-1202(1202層!)在CIFAR-10上仍保持87%準確率!
在這篇綜述文章中,能夠單開一個小節的人物並不多,
何愷明絕對實至名歸,
而ResNet論文目前成爲21世紀引量最高的學術論文,遠超Transformer和AlexNet。

導師湯曉鷗(商湯科技創始人)、何愷明
09 序列模型
除了圖像數據外,還有大量的序列數據,
比如文本內容、時間序列,
像統計學和計量經濟學裏面都有時間序列分析,
比較傳統的方法有自迴歸模型、移動平均模型和ARIMA模型這些統計方法,
後來隨着機器學習的大熱,
很多學者把時間序列分析與機器學習結合起來,提出了循環網絡的概念,
比如最早的循環網絡是1982年的Hopfield網絡
(Hopfield和Hinton後來一起獲得2024年的諾貝爾物理學獎),

Hopfield Hinton
到了1997年,除了同時代最受關注的初代卷積神經網絡CNN,
還有專門處理序列數據的循環神經網絡RNN,
RNN的核心思想是循環,在處理序列的每一步時,
不僅考慮當前的輸入,還利用一個“隱藏狀態”來維持對過去所有信息的記憶,
不過隨着循環連接保留歷史信息的增加,也會出現梯度消失/爆炸問題,
另一位大佬Jürgen Schmidhuber在RNN的基礎上,
提出了LSTM長短期記憶網絡,引入了門控機制(遺忘門、輸入門、輸出門),
再引入細胞狀態(Cell State) 作爲“記憶通道”不斷更新信息,
有效避免了梯度連乘問題,長期依賴能力大大加強,
但問題也來了,LSTM的參數量達到RNN的四倍,
訓練過程也需要大量的計算資源,
所以後來老黃還推出了優化庫CuDNN進行加速,
不過在2012年前後,大家注意力都被計算機視覺CV吸走了,
像RNN/LSTM這類自然語言處理NLP領域的模型熱度並沒有CV那麼高。

Schmidhuber
10 Transformer
到了2017年,就在AlexNet誕生後的第五年,
另一個足以比肩AlexNet的模型出現了,它就是Transformer,
谷歌在17年發表了新論文《Attention Is All You Need》,
在原本RNN/LSTM的基礎上,引入了自注意力(self-attention)機制,
Transformer論文也被視作是GPT時代的起點。
這裏補充一點,當時我就看過這篇論文還詳細寫了技術博客,
不過Transformer論文在NeurIPS 2017上未獲Oral演講資格,
而且我印象裏GPT一開始也並不是很火,
因爲前有生成對抗網絡GAN的餘威,直接橫掃整個CV領域,
後有BERT的誕生(被視爲NLP最有希望取得突破的模型),
所以GPT在2019年以前並沒有得到像今天這樣鋪天蓋地的關注度。
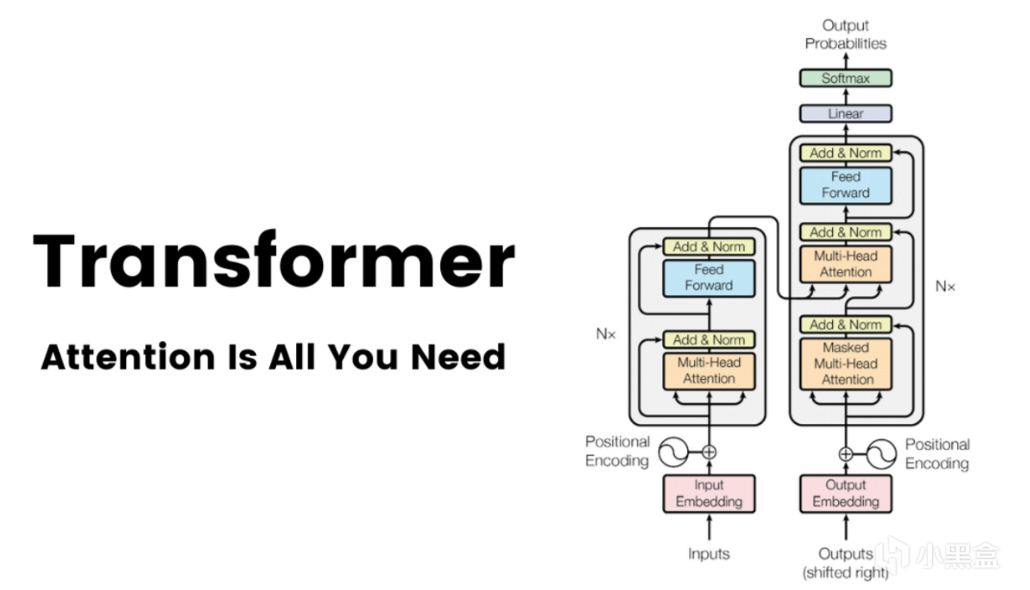
再回到Transformer,它對比CNN的優勢是可以建立對全局上下文的理解,
天然就適合處理序列文本,
谷歌又想了一個新招,原本CV領域長期由ResNet主導,
依賴卷積提取局部特徵,但難以建模長距離依賴,
谷歌將Transformer用在視覺領域,先把圖像分割爲固定大小的Patch(圖像塊),
每個Patch視爲一個視覺詞(類似 NLP 中的 token),
然後通過線性投影轉換爲向量序列輸入Transformer,
於是也就有了ViT架構,這玩意兒在大規模數據集下特別強,
缺點就是需要大規模的預訓練,否則很容易過擬合,
然後因爲分了一大堆Patch,所以計算複雜度比較高,
需要耗費大量的計算資源(老黃又贏麻了)。
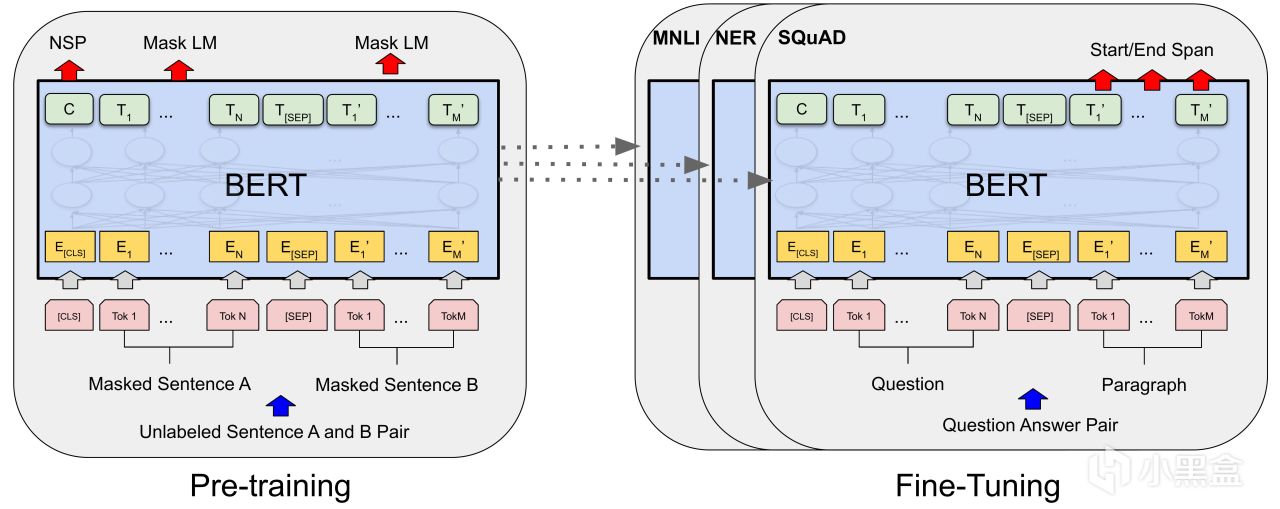
而Transformer另一條主線是BERT,
在18-19年左右,BERT幾乎把所有NLP可以刷的榜全部刷了一遍,
BERT一句話解釋就是雙向Transformer編碼器,利用預訓練+微調解決NLP問題,
這玩意兒優點是省錢,花錢的地方集中在預訓練階段,
但是預訓練的參數模型是可以共用的,
企業只需要專注微調這部分即可解決特定的NLP任務,
當年最有前景的就是問答系統,因爲這很符合公衆對AI人工智能的想象。
11 GPT
OpenAI這邊的GPT-1與BERT是同一時期,
但是熱度遠遠不如BERT,也並未成爲學界主流。
GPT在學術界破圈是在2019年,
當時OpenAI以安全擔憂爲由拒絕開源15億參數版GPT-2,
因爲GPT-2可以生成假新聞、做故事續寫,
展現出很強的語言泛化能力,
雖然OpenAI不公開,但是社區可以通過逆向工程復現模型(比如DistilGPT-2),
在此期間反而是催生出了Hugging Face這種大模型開源生態,

Hugging Face
到了2020年,GPT-3的參數量飆升至1750億,訓練數據涵蓋45TB文本。
不過GPT-3強是強,但生成內容不可控、邏輯混亂,
所以OpenAI將工作重心轉向了RLHF,即從人類反饋中強化學習,
這裏強化學習的思路和我之前介紹柯潔阿爾法狗技術專題的內容有點像,
就是讓人類標註員對回答排序,訓練獎勵模型,
然後再用強化學習微調模型生成策略。
看到這裏,你會發現RLHF其實是做產品的思維,
OpenAI更新後的GPT-3.5,就是一個完美的問答系統產品,
於是搭載GPT-3.5的ChatGPT也就應運而生,
後面GPT的發展,以及國產大模型的崛起,
也都是我們比較熟悉的內容了。

12 練習兩年半
再回顧上面10個小節神經網絡的發展史,
一開始是40年代大家都不看好的感知機,
然後是辛頓和LeCun弄出來初代卷積神經網絡LeNet,
再到2012年AlexNet的橫空出世,
這裏面前後一共花了70年時間才抵達AI元年,
之後就是大量學者開始研究神經網絡,
再到2017年,谷歌的Transformer架構誕生只花了五年時間,
接下來,2018年BERT爆火,
結果沒過幾年就被GPT徹底打趴下,
2022年底,OpenAI正式發佈ChatGPT,
到今天也不過練習了兩年半時間,
這裏面發生的事情足夠再讓我寫十幾篇這樣篇幅的文章,

當然,其中的主導力量已經由學術界,
轉向資金人才實力雄厚的科技巨頭。
如果讓我給最近這兩年半挑一個最重量級的革新,
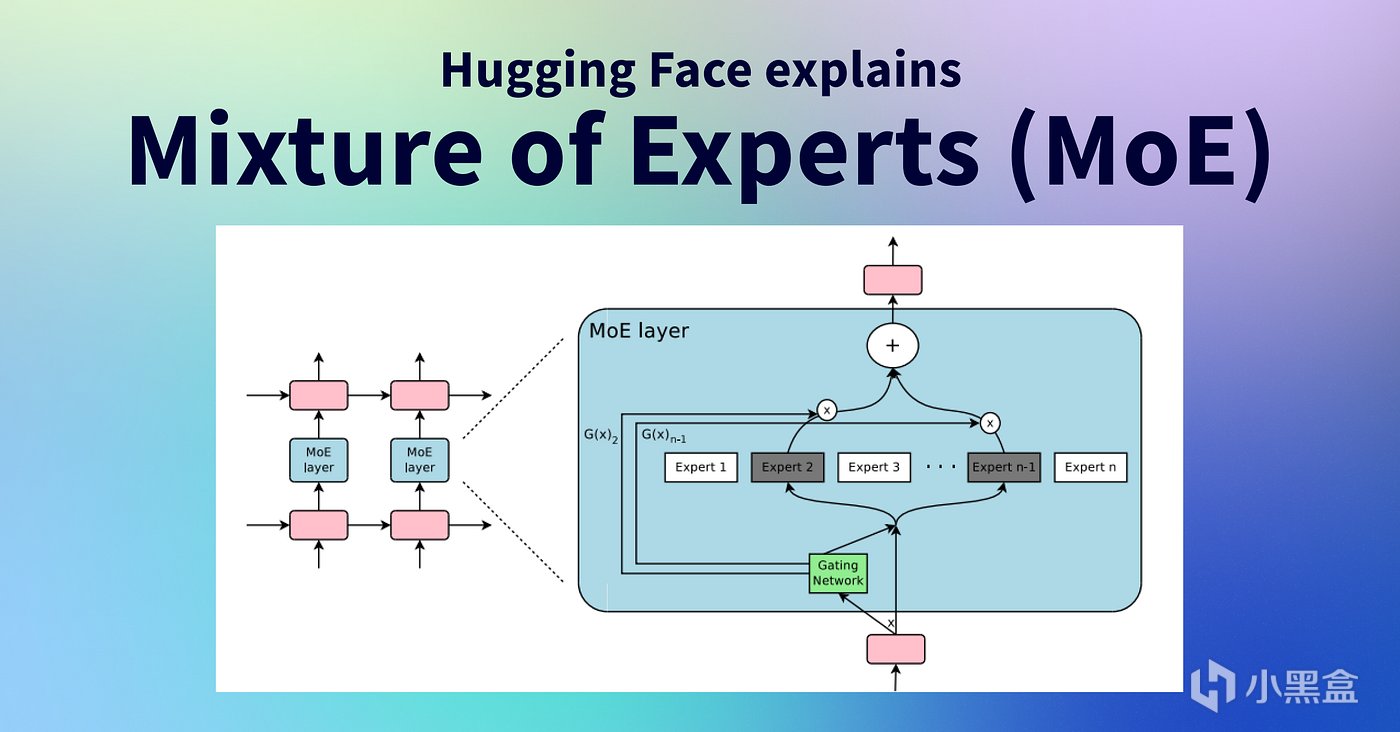
那麼應該可以給到MoE混合專家模型,
這玩意兒最早其實是辛頓和邁克爾喬丹提出的
(這個MJ是機器學習大佬、吳恩達的老師),
近兩年迎來大爆發,成爲大模型的核心架構,
Mixtral AI、GPT-4、Gemini 2.5、DeepSeek-R1,
以及Grok-4、Kimi K2和Qwen3等等均是採用MoE架構的推理大模型,
MoE簡而言之就是用一種動態路由機制,將任務分配給多個專業化子模型(專家),
最大的優點是節省資源提升計算效率,
MoE並沒有讓模型變得更大,而是讓大模型變得可用,
後面DeepSeek開源的各種優化工具也是基於MoE架構。
13 未來
當下最熱炒的話題方向是AI Agent智能體,
越來越多的大模型公司開始畫餅“模型即Agent”概念,
很多人認爲AI Agent最終會成爲AGI落地核心載體。
除此之外,具身智能也是炒作的大方向,
包括特斯拉Optimus人形機器人、宇樹科技Unitree G1等等,
另外還有世界模型World Models,
希望構建物理世界的動態模擬器,讓AI具備預測因果和長期推理能力,
應用層面還有多模態大模型、移動端側大模型等等,
但是這些技術仍然是畫餅居多,
暫無卷積神經網絡這樣已經成功而且非常清晰的技術路線。
最後的最後,我反而對一個老掉牙的話題更感興趣,
即卷積神經網絡的可解釋性問題,
從一開始大家就認爲神經網絡是個“黑箱”,
雖然我們都知道它能做出準確的預測,但很難理解它做出某個決策的具體原因,
換句話說,可解釋性問題也可以理解爲,
我們的終極目標可能不是如何構建一個更大、更快的網絡,
而是對模型進行根本性的改造,讓它們變得更符合人類常識,
走向對世界更深層次、更因果化的理解。
綜上所述,卷積神經網絡絕對是過去數十年人工智能領域最成功的技術之一,
作用深遠而且持久,幾乎我們每個人都會受到它的影響,
而翻遍整個互聯網,似乎也沒有太多的人願意從專業角度把這些技術全部梳理一遍,
這也是我寫這篇大白話類型綜述的原因所在,
時間有限,這篇文章只選取了一些比較重要的技術講。
(老黃髮家史確定是打算鴿了,要寫的東西太多太多,喜歡技術的可以參考這篇文章)。

遊戲&AI系列:
老黃髮家史——英偉達市值突破4萬億,老黃的傳奇人生!
老黃髮家史——傳奇AMD工程師,老黃人生的第一份工作!
老黃髮家史——世嘉主機拯救英偉達,老黃曾差點破產!
老黃髮家史——FPS天才成就英偉達,N卡的誕生!
老黃髮家史——N卡大戰A卡,上古芯片巨頭ATI!
老黃髮家史——英偉達創造顯卡,PC遊戲的崛起!
老黃髮家史——極客玩家的一次靈感,啓發英偉達進軍AI!
老黃髮家史——讓玩家爲 AI 買單,老黃成功的祕訣!
老黃髮家史——CUDA崛起,英偉達AI的護城河!
老黃髮家史——華人AI教母李飛飛,老黃髮家的貴人!
老黃髮家史——神經網絡,AI革命的起點!
老黃髮家史——500美元的遊戲顯卡,居然開啓 AI 元年!
老黃髮家史——百度大戰微軟谷歌,一場改變世界的祕密拍賣會!
老黃髮家史——柯潔夢碎,阿爾法狗靈感源於遊戲!
老黃髮家史——馬斯克大戰老黃,OpenAI的誕生!
AI——是遊戲NPC的未來嗎?
巫師三——AI如何幫助老遊戲畫質重獲新生
你的遊戲存檔——正在改寫人類藥物研發史
無主之地3——臭打遊戲,竟能解決人類大腸便祕煩惱
一句話造GTA——全球首款A遊戲引擎Mirage上線
AI女裝換臉——FaceAPP應用和原理
AI捏臉技術——你想在遊戲中捏誰的臉?
Epic虛幻引擎——“元人類生成器”遊戲開發(附教程)
腦機接口——特斯拉、米哈遊的“魔幻未來技術”
白話科普——Bit到底是如何誕生的?
永劫無間——肌肉金輪,AI如何幫助玩家捏臉?
Adobe之父——發明PDF格式,助喬布斯封神
FPS遊戲之父——誰是最偉大的遊戲程序員?
《巫師3》MOD——製作教程,從零開始!
#gd的ai&遊戲雜談#
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















