今年开年,DeepSeek在全球爆火,掀起了一波AI热潮,最近给大家连续更新了两周英伟达老黄系列,文章中频率出现最高的就是深度学习和神经网络这些热门术语,两个月前,我又给大家更新了2025年版本的AI入坑深度学习的指南。今天这篇文章就继续聊聊我这段时间重新搜集整理的神经网络综述,老黄发家史系列硬核部分为了照顾多数读者,所以省略了很多,今天这篇文章专业性会略强一些。

01 什么是综述
最近十多年时间,人工智能是全球最热门的话题,
很多其他领域的学生或者从业人员,可能会感到非常焦虑,
但如果你想要真正去了解AI,
看自媒体那短短几十分钟的视频,
还是远远不够的,
而对于大多数人来说,
也不太可能系统把神经网络的论文全都读一遍,
这篇综述文章可以快速帮你梳理神经网络的发展历程,
即便没有专业背景,
也能对神经网络这个领域有一个清晰、全面的认识。

02 神经网络
在老黄发家史中,我们看到英伟达的转折点是2012年,
当时辛顿教授团队,在ImageNet图像大赛上以压倒性优势夺冠,
此后卷积神经网络成为显学,
英伟达的AI加速卡成为各国核战略级别的算力资源,
而最近十多年的各种科技突破中,
多数都用到了卷积神经网络,
比如击败柯洁、李世石的AlphaGo,
用于手机解锁、安防领域的人脸识别系统,
车企厂商自动驾驶中的物体检测,
医学肿瘤检测CT/MRI影像自动诊断,
AI绘画生成工具Stable Diffusion,
和大型语言模型LLM等应用,
如果你想探索这些技术背后的原理,
那么卷积神经网络(CNN)就是入门AI的第一步!

CNN的诞生与人工神经网络(ANN)发展密不可分,
最早可以追溯到1943年,
当时McCulloch与Pitts提出首个神经元数学模型,
50年代末,罗森布拉特在MP模型基础上增加学习能力,
提出单层感知机模型,你可以把它想象成一个自动分类的简易开关,
核心任务非常简单,就是根据输入的特征(比如苹果的颜色、大小),
快速判断它属于哪一类(比如“好苹果”或“坏苹果”),
但是单层感知机无法解决计算机中的线性不可分问题(比如异或XOR问题),
通俗来说,单层感知机模型就是一台只会画直线的分类器,
靠试错调整自己的判断标准,是AI世界里的入门学步车,
想要让感知机变强,就得给它加层加神经元,
于是,一门研究如何让感知机网络层数加深的学科出现了,
也就是深度学习的雏形。

神经网络之父辛顿 出席上海WAIC 2025
03 深度学习
很多人误以为AI的入门非常难,需要很强的数学基础,
但实际上,学好大学基础的线性代数课程,
再加上一点微积分入门课程,就足以看懂卷积神经网络。
1984年,辛顿教授提出了用于多层网络的误差反向传播——BP算法,
并成功训练了多层感知机MLP,
BP算法是整个神经网络训练的基石,
无论是FSD自动驾驶模型,还是LLM大语言模型,
挖掘到模型的核心都是依赖BP算法来不断进行学习,
区别就是多层感知机的参数很少,
而如今70B通用模型参数规模达到数百亿之巨。
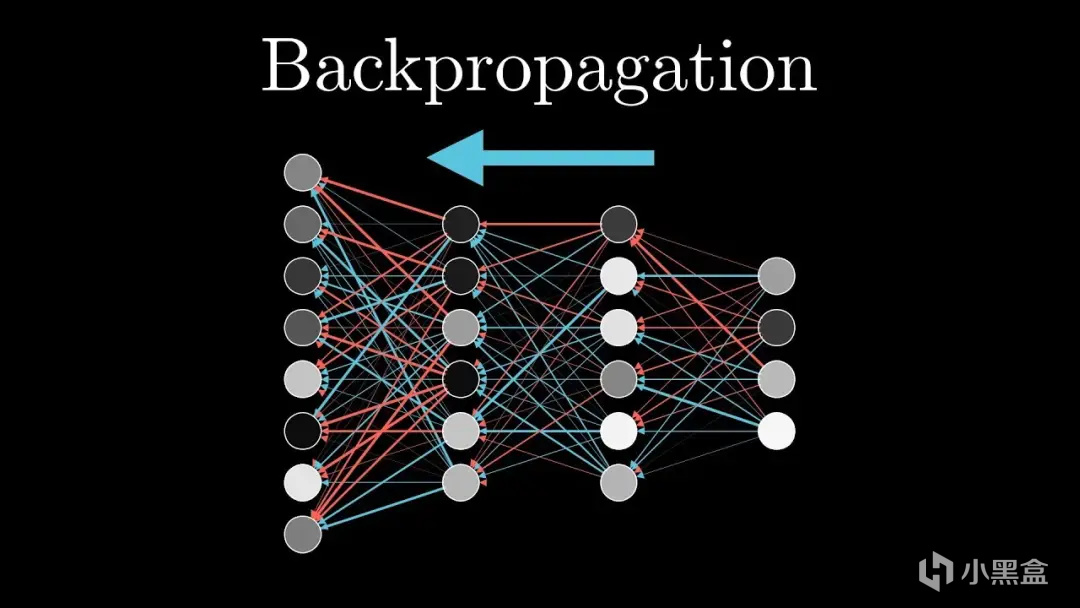
辛顿多层感知机的突破,是在输入和输出之间加入隐藏层,
形成多层结构,第一层识别简单特征(如线条),
第二层组合成复杂特征(如形状),层层递进,
每层后加入Sigmoid、ReLU这种非线性函数,
将直线“弯曲”成曲线或折线,从而拟合复杂边界,
从输出层开始,按“谁导致我出错,我就纠正谁”的逻辑,
用微积分的链式法则计算每层权重的梯度,
一句话公式简化:
梯度 = 输出误差 × 激活函数的导数 × 前一层输出值,
BP算法负责沿梯度反方向调整权重(梯度下降),减少误差。

04 手写体识别
90年代,Yann LeCun等人构建了用于手写邮编识别的卷积网络,
这也是历史上首次使用"卷积"术语,
历史上第一个卷积神经网络LeNet-5诞生。
手写体识别是计算机视觉最经典的任务
(如果你把这一小节内容消化好了,
本科毕业论文做个类似于手写体识别的小实验就算非常不错了),
简而言之,手写体识别就像教电脑“看懂”人随手写的字,
首先需要把你写的字拍成照片,组成一个图像数据集MNIST,
这些图像可能模糊、歪斜或有背景干扰,
传统方法是电脑拿着字的特征图,去对比字库进行识别,
这类方法在计算机领域统称为专家系统,
类似于制定规则让电脑去死记硬背,
虽然规则你可以做到很完美,但遇到字迹潦草或变形时就容易挂科。

MNIST
这也是过去几十年AI无法突破的原因,
所有学者都想尽可能去完善规则,
而卷积神经网络更像是一个黑箱模型,
Yann LeCun教授首先将图像转化为灰度图作为原始图像输入,
然后通过神经网络的卷积层提取低级特征,
再用池化层降维,LeNet-5通过卷积→池化交替两次,
最后通过全连接层+Softmax函数输出0-9的分类概率,
LeNet-5只需要10个训练周期(Epoch),测试集准确率可达98%以上,
LeNet在历史上首次验证了CNN在视觉任务中的可行性,
直接启发了AlexNet、ResNet等后续模型。
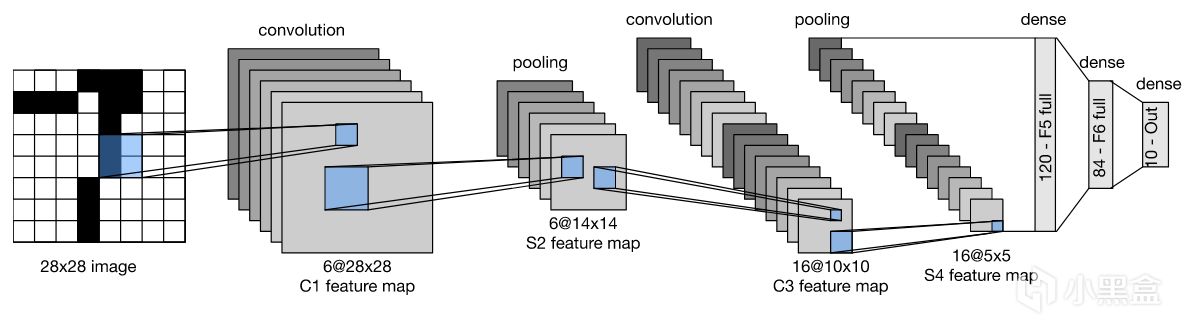
LeNet
05 深度学习的困境
如果你没看过老黄发家史,可能会非常疑惑,
为什么1998年最早的卷积神经网络LeNet-5就已经成功,
但是真正的AI元年却要等到2012年的AlexNet,
答案很简单,深度学习有不少难题,
比如反向传播算法非常强大,
但是当研究人员尝试构建更深的网络时,
会出现梯度消失和梯度爆炸,
BP中的梯度信号经过多层传递后变得过小或过大,导致网络无法有效学习,
而且深度网络还更更容易陷入局部最优解,出现过拟合问题。
率先取得突破的又是辛顿教授,他在2006年发布了DBN深度信念网络,
首次提出逐层预训练的方法(如今大模型领域,预训练也是最核心的方法),
即先用无监督的方式逐层训练网络,
然后再使用反向传播算法对整个网络进行微调。
不过方法再好也需要能打硬仗的“武器”,
LeNet-5仅2个卷积层,难以学习复杂特征,
一旦把网络加深,参数量又太大,
训练10层网络需TB级数据与TFLOPS算力,
而2000年代初CPU仅GFLOPS水平,
所以深度学习的发展又阻滞了十多年,
再次沦为学者眼中没有任何前途、已经被判死刑的领域。

黄仁勋 辛顿
06 AlexNet革命
现在人工智能有一大堆热词,数据科学、大模型、深度学习等等,
但AI真正最需要的是三要素,分别是数据、算法和算力,
只有三者都取得突破,人类才会迎来崭新的技术革命,
有意思的是,其中两个要素都是华人解决的,
时间点仍然是2006年,李飞飞从钱老的母校加州理工学院博士毕业,
开始着手创建人类历史上最大的图像数据集,
包括2万个类别、上千万张图像,李飞飞将这个数据集命名为AlexNet,
黄仁勋则在06年推出了CUDA,
把显卡卖给玩家筹钱,用来研发科学计算领域,
而辛顿则在06年陆续收下了两名学生,分别是Alex和Ilya。

三条主线在2012年正式相遇,
Alex和Ilya省钱自掏腰包购入了两块英伟达GTX 580显卡,
使用老师一生坚持的卷积神经网络,去打ImageNet挑战赛,
Alex的AlexNet以压倒性优势夺冠,直接震惊了整个计算机视觉领域!
对比初代卷积神经网络LeNet-5,
AlexNet有几项关键性的突破,
一是ReLU激活函数,解决梯度消失问题,加速训练;
二是Dropout正则化,可以抑制过拟合,提升泛化能力;
三是GPU并行训练,首次利用双GPU分载计算,突破算力瓶颈;
这些直接解决了90年代和00年代导致深度学习陷入困境的三大问题,
AlexNet成功证明CNN在复杂的视觉任务上性能远超其他模型,也直接开启了AI元年!
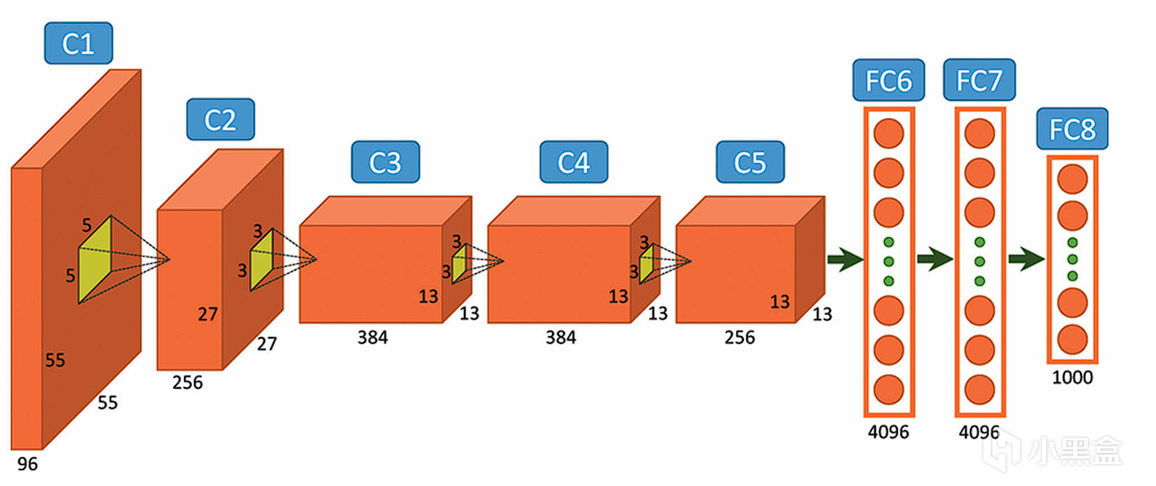
AlexNet
07 越深越好
Alex和Ilya公开了AlexNet的细节,
像谷歌、微软这样的大公司也纷纷复现AlexNet,
同时琢磨如何提升AlexNet的性能,
其中最显而易见的方法就是让神经网络变得越深越好
(不然为什么叫深度学习),
于是到了13、14年的ImageNet大赛,
VGGNet堆叠了16-19层卷积层,
整个网络几乎完全由小尺寸3x3的卷积核和2x2的最大池化层堆叠而成,
网络性能得到大幅度提升。
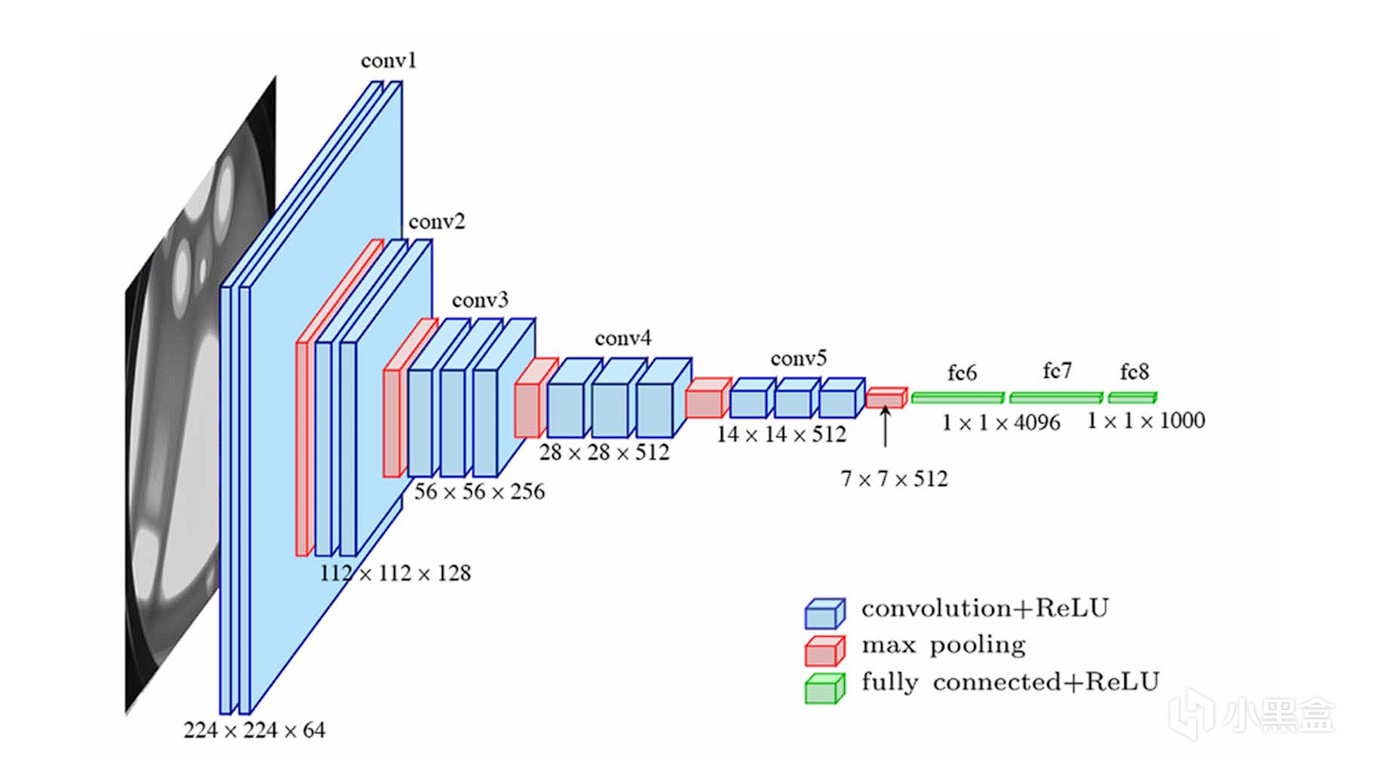
而真正让人大吃一惊的还是谷歌,他们直接堆叠了一个22层的超深网络,
拿下2014年ImageNet大赛的冠军,
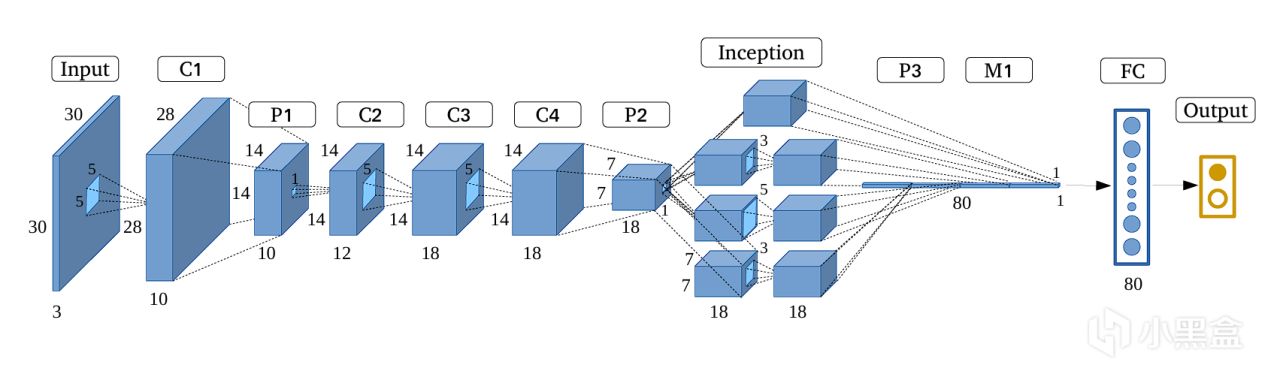
而谷歌还不止是单纯追求深度,他们还创建了Inception模块,
在同一层级上并行地使用多种不同尺寸的卷积核(1x1, 3x3, 5x5)和一个最大池化操作,
将所有输出的特征图在通道维度上拼接起来,
让网络能够同时捕捉不同尺度的特征,
谷歌将这个网络命名为GoogLeNet,
既是套用Google的名字,也是致敬初代神经网络LeNet,
后续谷歌财大气粗还对GoogLeNet的架构进行优化,
推出了v2、v3和v4版本,网络越来越深,参数量越来越大,
其中最赢麻的还得是老黄,毕竟参数越多,
就越需要他的AI加速卡。
GoogLeNet
08 何恺明ResNet
接下来的2015年,又是一位华人科学家改变了AI的历史进程,
何恺明等学者发现神经网络层数在超过20层后会出现退化现象,
即层数增加,准确率不升反降,但这又不是过拟合,
因为深层网络梯度反向传播时易消失/爆炸,而且难以学习恒等映射,
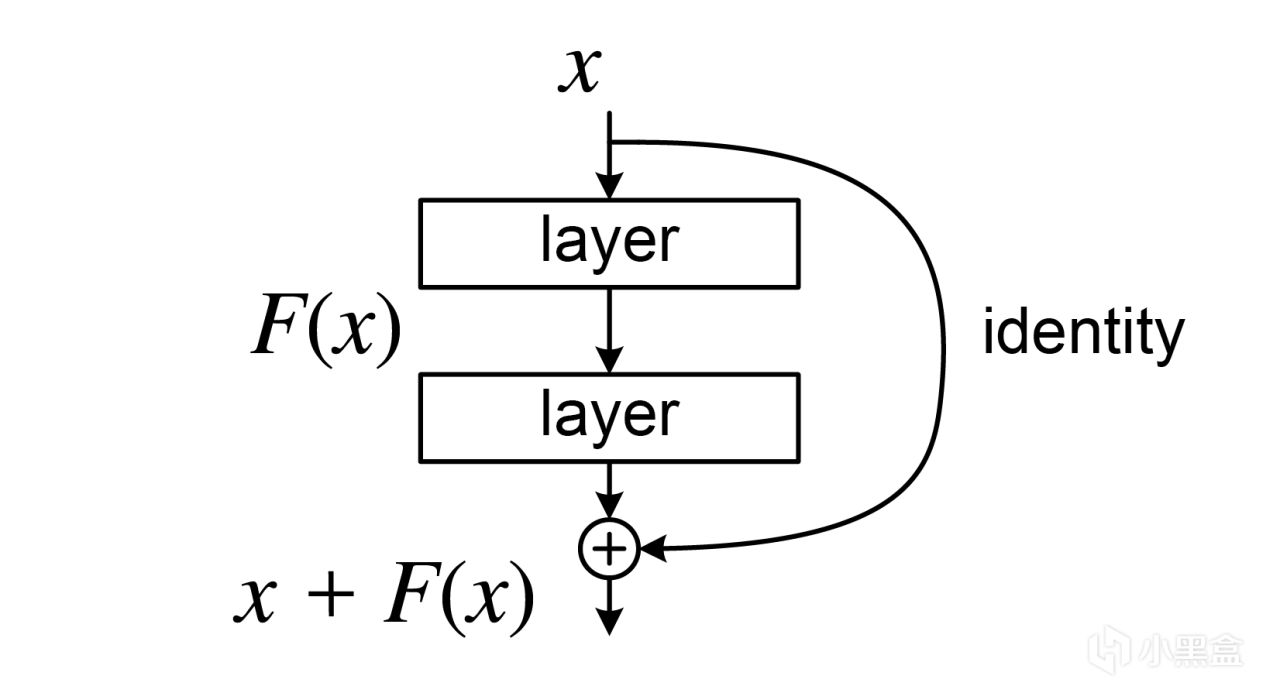
所以何恺明提出了全新的残差连接(Residual Connection),
残差连接的结构真的特别特别简单,
核心设计仅用一个学习残差的运算,就颠覆了深度学习的发展轨迹,
一句话计算残差 F(x) = H(x) - x,取真实目标与输入的差值,
Residual Connection
ResNet仅用两种残差块就支撑起18~152层的所有模型,
传统网络20层后梯度衰减至近乎0,
而ResNet-34在ImageNet上错误率26.7%,远低于 34层传统CNN的37%,
并且ResNet-1202(1202层!)在CIFAR-10上仍保持87%准确率!
在这篇综述文章中,能够单开一个小节的人物并不多,
何恺明绝对实至名归,
而ResNet论文目前成为21世纪引量最高的学术论文,远超Transformer和AlexNet。

导师汤晓鸥(商汤科技创始人)、何恺明
09 序列模型
除了图像数据外,还有大量的序列数据,
比如文本内容、时间序列,
像统计学和计量经济学里面都有时间序列分析,
比较传统的方法有自回归模型、移动平均模型和ARIMA模型这些统计方法,
后来随着机器学习的大热,
很多学者把时间序列分析与机器学习结合起来,提出了循环网络的概念,
比如最早的循环网络是1982年的Hopfield网络
(Hopfield和Hinton后来一起获得2024年的诺贝尔物理学奖),

Hopfield Hinton
到了1997年,除了同时代最受关注的初代卷积神经网络CNN,
还有专门处理序列数据的循环神经网络RNN,
RNN的核心思想是循环,在处理序列的每一步时,
不仅考虑当前的输入,还利用一个“隐藏状态”来维持对过去所有信息的记忆,
不过随着循环连接保留历史信息的增加,也会出现梯度消失/爆炸问题,
另一位大佬Jürgen Schmidhuber在RNN的基础上,
提出了LSTM长短期记忆网络,引入了门控机制(遗忘门、输入门、输出门),
再引入细胞状态(Cell State) 作为“记忆通道”不断更新信息,
有效避免了梯度连乘问题,长期依赖能力大大加强,
但问题也来了,LSTM的参数量达到RNN的四倍,
训练过程也需要大量的计算资源,
所以后来老黄还推出了优化库CuDNN进行加速,
不过在2012年前后,大家注意力都被计算机视觉CV吸走了,
像RNN/LSTM这类自然语言处理NLP领域的模型热度并没有CV那么高。

Schmidhuber
10 Transformer
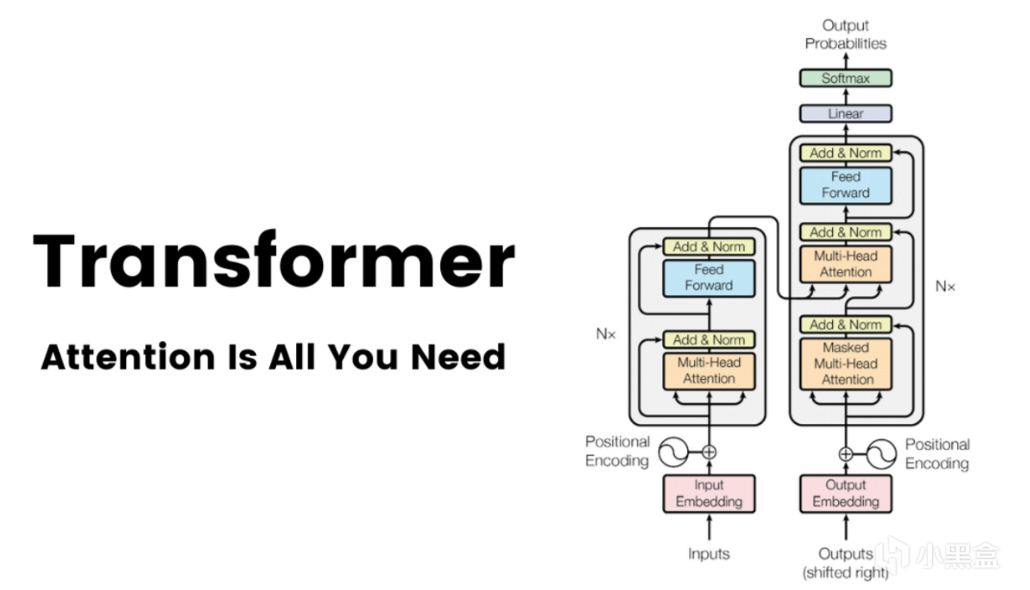
到了2017年,就在AlexNet诞生后的第五年,
另一个足以比肩AlexNet的模型出现了,它就是Transformer,
谷歌在17年发表了新论文《Attention Is All You Need》,
在原本RNN/LSTM的基础上,引入了自注意力(self-attention)机制,
Transformer论文也被视作是GPT时代的起点。
这里补充一点,当时我就看过这篇论文还详细写了技术博客,
不过Transformer论文在NeurIPS 2017上未获Oral演讲资格,
而且我印象里GPT一开始也并不是很火,
因为前有生成对抗网络GAN的余威,直接横扫整个CV领域,
后有BERT的诞生(被视为NLP最有希望取得突破的模型),
所以GPT在2019年以前并没有得到像今天这样铺天盖地的关注度。
再回到Transformer,它对比CNN的优势是可以建立对全局上下文的理解,
天然就适合处理序列文本,
谷歌又想了一个新招,原本CV领域长期由ResNet主导,
依赖卷积提取局部特征,但难以建模长距离依赖,
谷歌将Transformer用在视觉领域,先把图像分割为固定大小的Patch(图像块),
每个Patch视为一个视觉词(类似 NLP 中的 token),
然后通过线性投影转换为向量序列输入Transformer,
于是也就有了ViT架构,这玩意儿在大规模数据集下特别强,
缺点就是需要大规模的预训练,否则很容易过拟合,
然后因为分了一大堆Patch,所以计算复杂度比较高,
需要耗费大量的计算资源(老黄又赢麻了)。
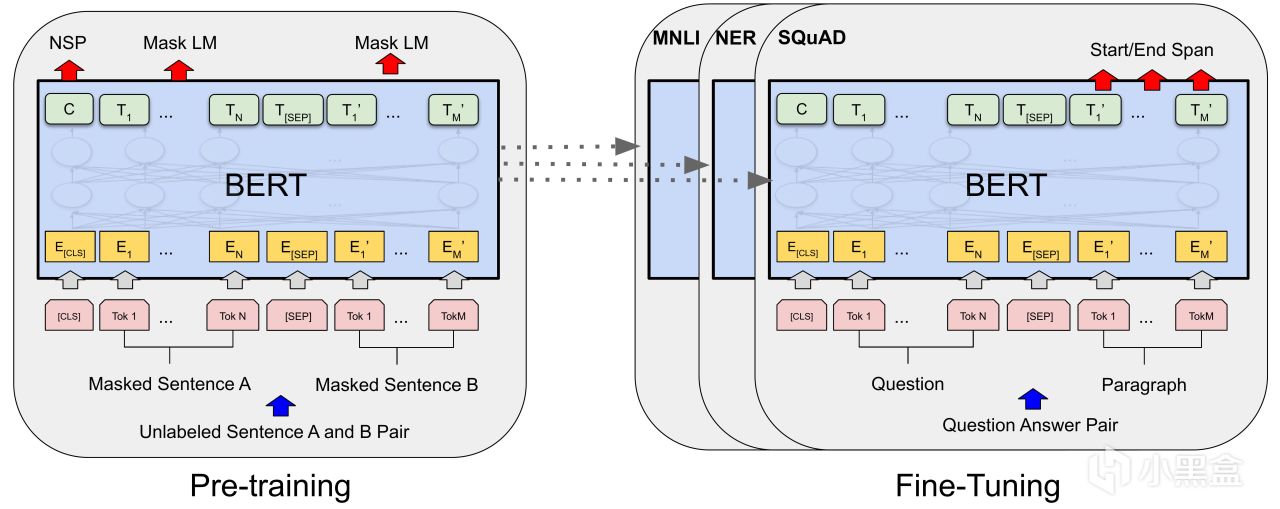
而Transformer另一条主线是BERT,
在18-19年左右,BERT几乎把所有NLP可以刷的榜全部刷了一遍,
BERT一句话解释就是双向Transformer编码器,利用预训练+微调解决NLP问题,
这玩意儿优点是省钱,花钱的地方集中在预训练阶段,
但是预训练的参数模型是可以共用的,
企业只需要专注微调这部分即可解决特定的NLP任务,
当年最有前景的就是问答系统,因为这很符合公众对AI人工智能的想象。
11 GPT
OpenAI这边的GPT-1与BERT是同一时期,
但是热度远远不如BERT,也并未成为学界主流。
GPT在学术界破圈是在2019年,
当时OpenAI以安全担忧为由拒绝开源15亿参数版GPT-2,
因为GPT-2可以生成假新闻、做故事续写,
展现出很强的语言泛化能力,
虽然OpenAI不公开,但是社区可以通过逆向工程复现模型(比如DistilGPT-2),
在此期间反而是催生出了Hugging Face这种大模型开源生态,

Hugging Face
到了2020年,GPT-3的参数量飙升至1750亿,训练数据涵盖45TB文本。
不过GPT-3强是强,但生成内容不可控、逻辑混乱,
所以OpenAI将工作重心转向了RLHF,即从人类反馈中强化学习,
这里强化学习的思路和我之前介绍柯洁阿尔法狗技术专题的内容有点像,
就是让人类标注员对回答排序,训练奖励模型,
然后再用强化学习微调模型生成策略。
看到这里,你会发现RLHF其实是做产品的思维,
OpenAI更新后的GPT-3.5,就是一个完美的问答系统产品,
于是搭载GPT-3.5的ChatGPT也就应运而生,
后面GPT的发展,以及国产大模型的崛起,
也都是我们比较熟悉的内容了。

12 练习两年半
再回顾上面10个小节神经网络的发展史,
一开始是40年代大家都不看好的感知机,
然后是辛顿和LeCun弄出来初代卷积神经网络LeNet,
再到2012年AlexNet的横空出世,
这里面前后一共花了70年时间才抵达AI元年,
之后就是大量学者开始研究神经网络,
再到2017年,谷歌的Transformer架构诞生只花了五年时间,
接下来,2018年BERT爆火,
结果没过几年就被GPT彻底打趴下,
2022年底,OpenAI正式发布ChatGPT,
到今天也不过练习了两年半时间,
这里面发生的事情足够再让我写十几篇这样篇幅的文章,

当然,其中的主导力量已经由学术界,
转向资金人才实力雄厚的科技巨头。
如果让我给最近这两年半挑一个最重量级的革新,
那么应该可以给到MoE混合专家模型,
这玩意儿最早其实是辛顿和迈克尔乔丹提出的
(这个MJ是机器学习大佬、吴恩达的老师),
近两年迎来大爆发,成为大模型的核心架构,
Mixtral AI、GPT-4、Gemini 2.5、DeepSeek-R1,
以及Grok-4、Kimi K2和Qwen3等等均是采用MoE架构的推理大模型,
MoE简而言之就是用一种动态路由机制,将任务分配给多个专业化子模型(专家),
最大的优点是节省资源提升计算效率,
MoE并没有让模型变得更大,而是让大模型变得可用,
后面DeepSeek开源的各种优化工具也是基于MoE架构。
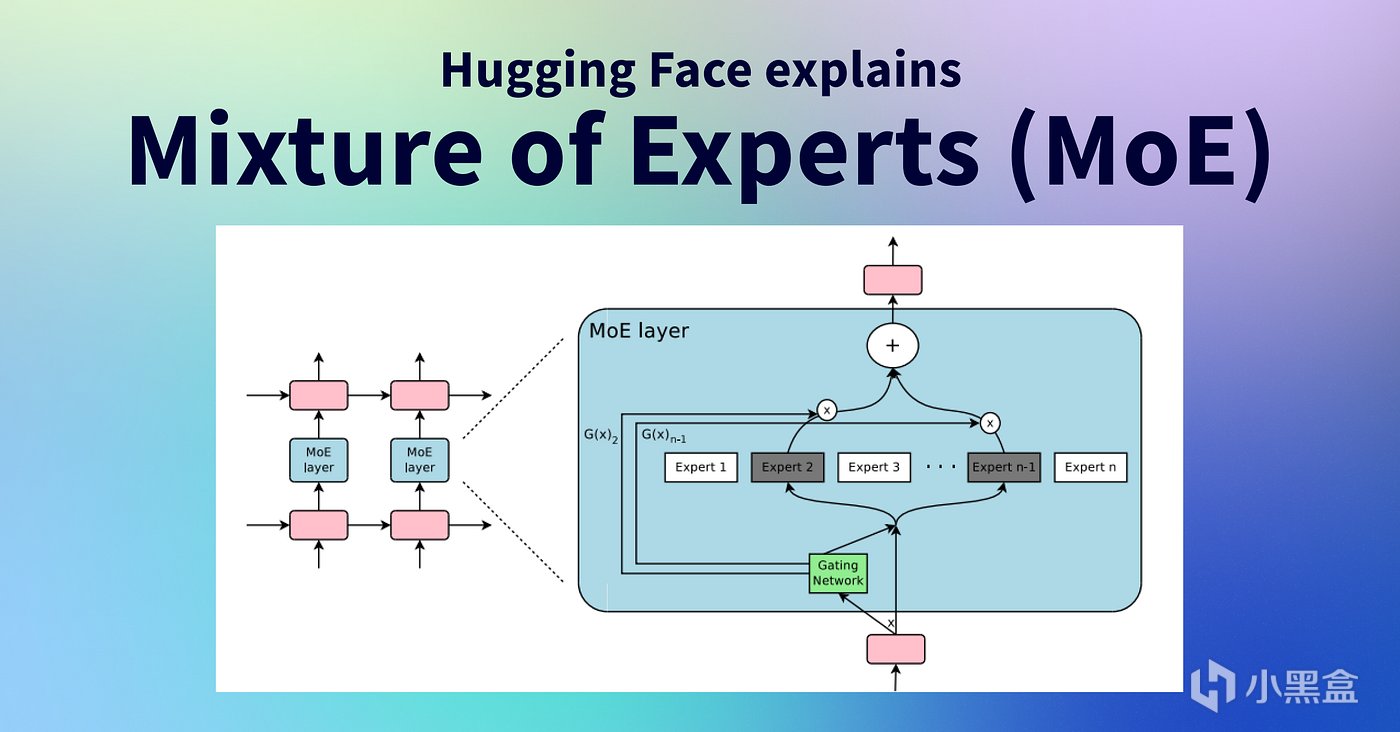
13 未来
当下最热炒的话题方向是AI Agent智能体,
越来越多的大模型公司开始画饼“模型即Agent”概念,
很多人认为AI Agent最终会成为AGI落地核心载体。
除此之外,具身智能也是炒作的大方向,
包括特斯拉Optimus人形机器人、宇树科技Unitree G1等等,
另外还有世界模型World Models,
希望构建物理世界的动态模拟器,让AI具备预测因果和长期推理能力,
应用层面还有多模态大模型、移动端侧大模型等等,
但是这些技术仍然是画饼居多,
暂无卷积神经网络这样已经成功而且非常清晰的技术路线。
最后的最后,我反而对一个老掉牙的话题更感兴趣,
即卷积神经网络的可解释性问题,
从一开始大家就认为神经网络是个“黑箱”,
虽然我们都知道它能做出准确的预测,但很难理解它做出某个决策的具体原因,
换句话说,可解释性问题也可以理解为,
我们的终极目标可能不是如何构建一个更大、更快的网络,
而是对模型进行根本性的改造,让它们变得更符合人类常识,
走向对世界更深层次、更因果化的理解。
综上所述,卷积神经网络绝对是过去数十年人工智能领域最成功的技术之一,
作用深远而且持久,几乎我们每个人都会受到它的影响,
而翻遍整个互联网,似乎也没有太多的人愿意从专业角度把这些技术全部梳理一遍,
这也是我写这篇大白话类型综述的原因所在,
时间有限,这篇文章只选取了一些比较重要的技术讲。
(老黄发家史确定是打算鸽了,要写的东西太多太多,喜欢技术的可以参考这篇文章)。

游戏&AI系列:
老黄发家史——英伟达市值突破4万亿,老黄的传奇人生!
老黄发家史——传奇AMD工程师,老黄人生的第一份工作!
老黄发家史——世嘉主机拯救英伟达,老黄曾差点破产!
老黄发家史——FPS天才成就英伟达,N卡的诞生!
老黄发家史——N卡大战A卡,上古芯片巨头ATI!
老黄发家史——英伟达创造显卡,PC游戏的崛起!
老黄发家史——极客玩家的一次灵感,启发英伟达进军AI!
老黄发家史——让玩家为 AI 买单,老黄成功的秘诀!
老黄发家史——CUDA崛起,英伟达AI的护城河!
老黄发家史——华人AI教母李飞飞,老黄发家的贵人!
老黄发家史——神经网络,AI革命的起点!
老黄发家史——500美元的游戏显卡,居然开启 AI 元年!
老黄发家史——百度大战微软谷歌,一场改变世界的秘密拍卖会!
老黄发家史——柯洁梦碎,阿尔法狗灵感源于游戏!
老黄发家史——马斯克大战老黄,OpenAI的诞生!
AI——是游戏NPC的未来吗?
巫师三——AI如何帮助老游戏画质重获新生
你的游戏存档——正在改写人类药物研发史
无主之地3——臭打游戏,竟能解决人类大肠便秘烦恼
一句话造GTA——全球首款A游戏引擎Mirage上线
AI女装换脸——FaceAPP应用和原理
AI捏脸技术——你想在游戏中捏谁的脸?
Epic虚幻引擎——“元人类生成器”游戏开发(附教程)
脑机接口——特斯拉、米哈游的“魔幻未来技术”
白话科普——Bit到底是如何诞生的?
永劫无间——肌肉金轮,AI如何帮助玩家捏脸?
Adobe之父——发明PDF格式,助乔布斯封神
FPS游戏之父——谁是最伟大的游戏程序员?
《巫师3》MOD——制作教程,从零开始!
#gd的ai&游戏杂谈#
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com
















