我不美死

最新開源的一個文本轉語音克隆的AI項目,在不需要額外訓練的條件下可以生成非常相似的聲音。
那麼,我們是否可以生成我的賽博老婆喊我起牀的聲音當起牀鈴呢?!(亦或者惡搞親愛的室友喊我爲義父大人)
話不多說,3!2!1!上鍊接!
https://github.com/SparkAudio/Spark-TTS
這個項目主要有幾個特點:
雙語支持:支持中英文,並具備跨語言、代碼切換場景的零樣本語音克隆能力。
可控語音生成:支持通過調整性別、音調、語速等參數創建虛擬說話人。
心動了嗎!
接下來是詳細的部署方法
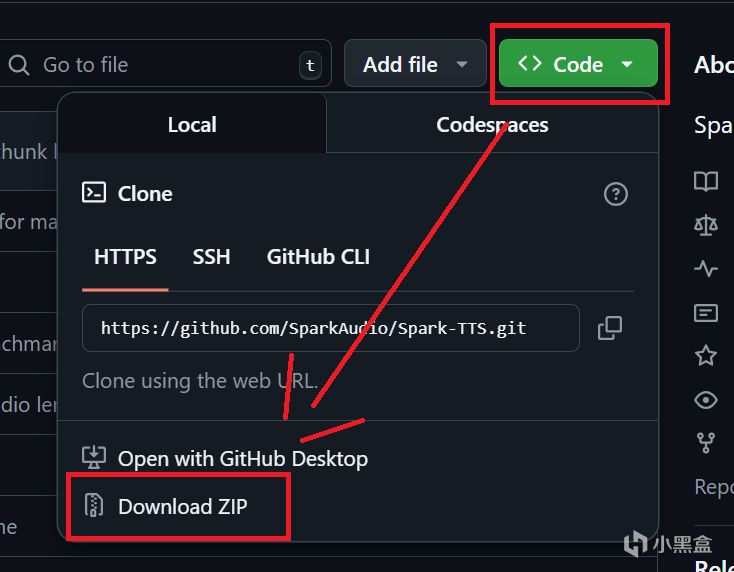
進入鏈接,“code”這裏下載項目,得到項目文件之後解壓縮
鏈接買一送一https://www.anaconda.com/download,這裏下載anaconda(submit下面有一個小小的registration,直接下載)
然後運行下載的安裝程序吧
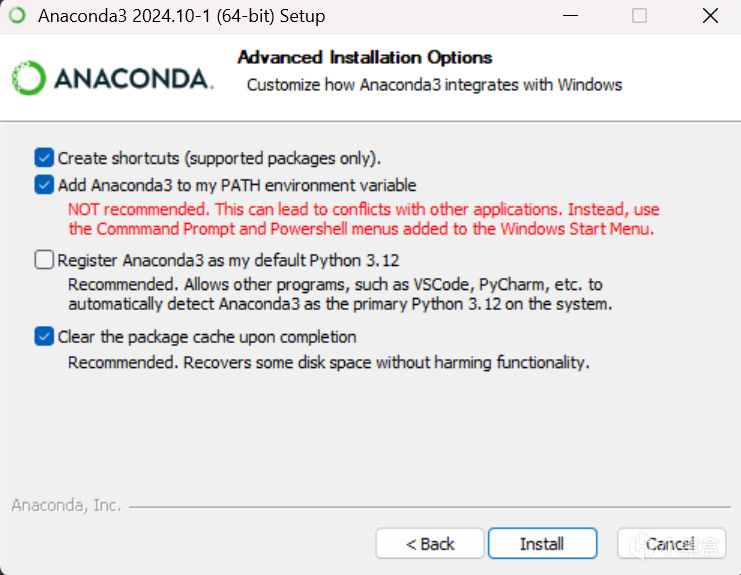
next到這裏,勾選如圖(第三個選擇性勾選),然後install,完成之後
接下來win+R進入cmd,運行
conda create -n sparktts python=3.12 -y
conda activate sparktts
進入(sparktts)就是成功啦
在Spark-TTS文件裏打開終端
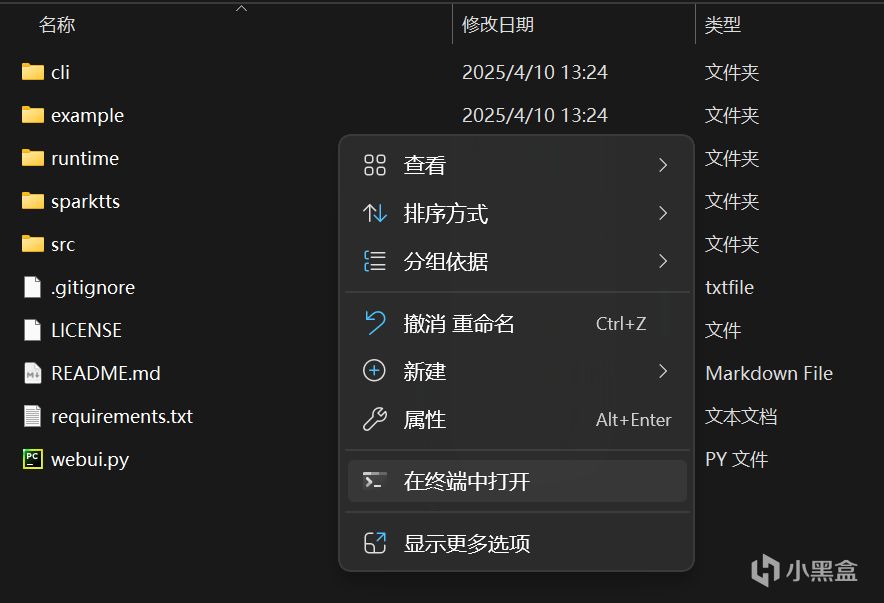
運行
pip install -r requirements.txt
依賴項安裝完成之後,還差一個PyTorch就可以下載模型啦
回到我們的cmd運行
conda install pytorch torchvision torchaudio cpuonly -c pytorch
確認下載,完成之後,進入Spark-TTS的文件夾
新建一個文本文檔,命名爲download_model.py
在裏面粘貼下面的代碼
from huggingface_hub import snapshot_download
import os
# Set download path
model_dir = "pretrained_models/Spark-TTS-0.5B"
# Check if model already exists
if os.path.exists(model_dir) and len(os.listdir(model_dir)) > 0:
print("Model files already exist. Skipping download.")
else:
print("Downloading model files...")
snapshot_download(
repo_id="SparkAudio/Spark-TTS-0.5B",
local_dir=model_dir,
resume_download=True # Resumes partial downloads
)
print("Download complete!")
然後運行這個py
python download_model.py
這樣就OK啦
然後我們就可以 python webui.py
(如果有pycharm就更好了)
這樣就可以開始我們的仿聲啦
(hym要把這個項目用作正途啊)
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com


![感覺大學根本沒有大家說的那麼好[cube_摘墨鏡]](https://imgheybox1.max-c.com/bbs/2025/10/29/b8f0746f374eed0dd6e14ecf7ac877b4.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)