我不美死

最新开源的一个文本转语音克隆的AI项目,在不需要额外训练的条件下可以生成非常相似的声音。
那么,我们是否可以生成我的赛博老婆喊我起床的声音当起床铃呢?!(亦或者恶搞亲爱的室友喊我为义父大人)
话不多说,3!2!1!上链接!
https://github.com/SparkAudio/Spark-TTS
这个项目主要有几个特点:
双语支持:支持中英文,并具备跨语言、代码切换场景的零样本语音克隆能力。
可控语音生成:支持通过调整性别、音调、语速等参数创建虚拟说话人。
心动了吗!
接下来是详细的部署方法
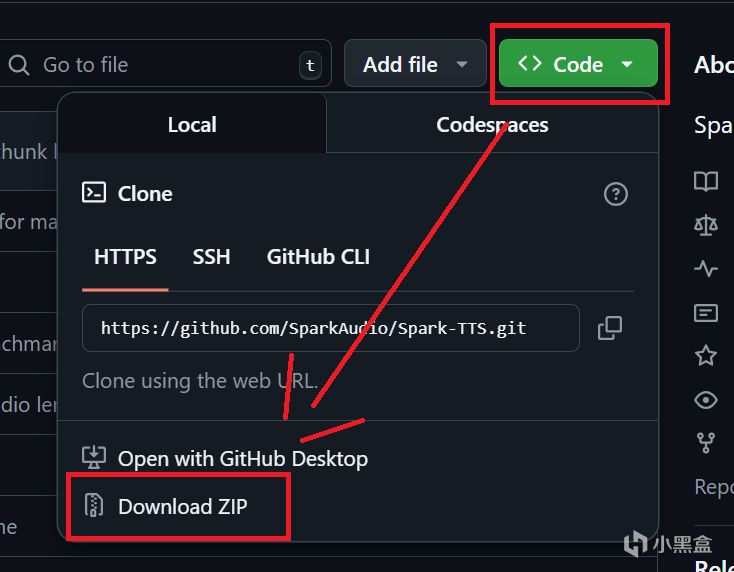
进入链接,“code”这里下载项目,得到项目文件之后解压缩
链接买一送一https://www.anaconda.com/download,这里下载anaconda(submit下面有一个小小的registration,直接下载)
然后运行下载的安装程序吧
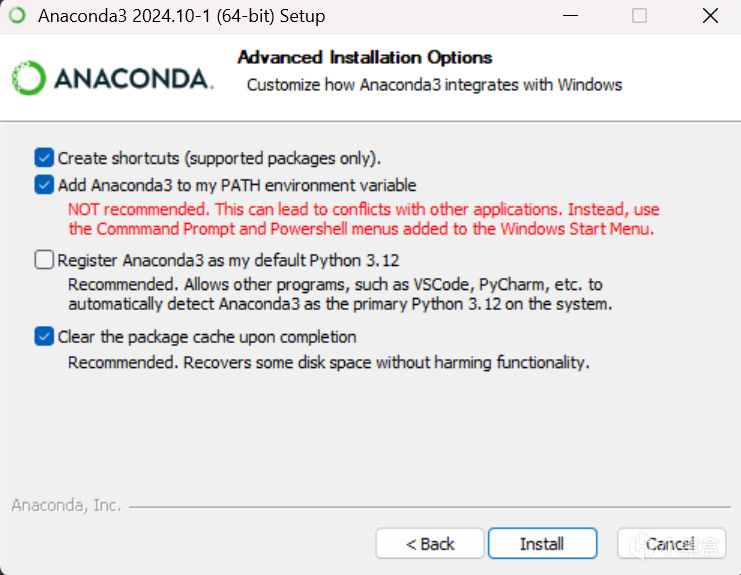
next到这里,勾选如图(第三个选择性勾选),然后install,完成之后
接下来win+R进入cmd,运行
conda create -n sparktts python=3.12 -y
conda activate sparktts
进入(sparktts)就是成功啦
在Spark-TTS文件里打开终端
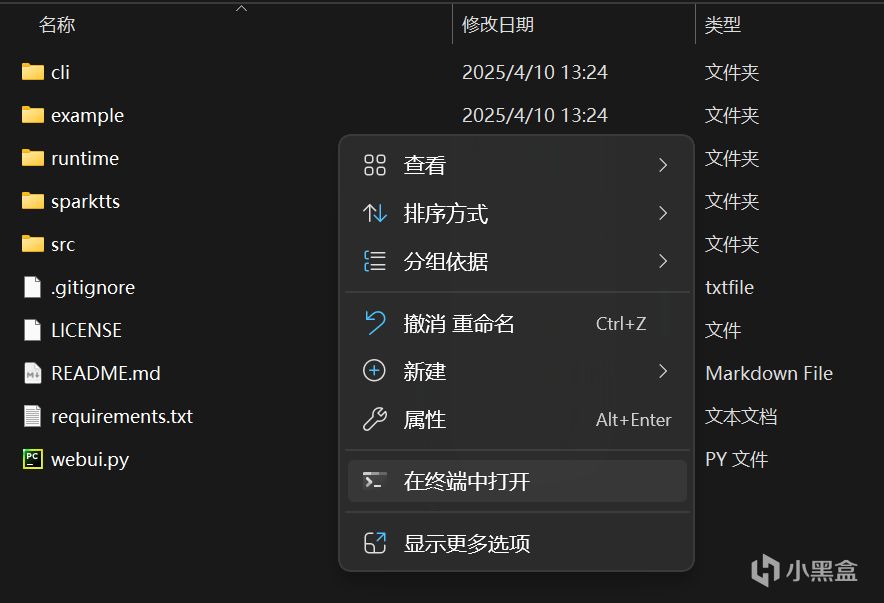
运行
pip install -r requirements.txt
依赖项安装完成之后,还差一个PyTorch就可以下载模型啦
回到我们的cmd运行
conda install pytorch torchvision torchaudio cpuonly -c pytorch
确认下载,完成之后,进入Spark-TTS的文件夹
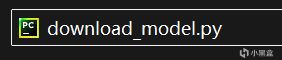
新建一个文本文档,命名为download_model.py
在里面粘贴下面的代码
from huggingface_hub import snapshot_download
import os
# Set download path
model_dir = "pretrained_models/Spark-TTS-0.5B"
# Check if model already exists
if os.path.exists(model_dir) and len(os.listdir(model_dir)) > 0:
print("Model files already exist. Skipping download.")
else:
print("Downloading model files...")
snapshot_download(
repo_id="SparkAudio/Spark-TTS-0.5B",
local_dir=model_dir,
resume_download=True # Resumes partial downloads
)
print("Download complete!")
然后运行这个py
python download_model.py
这样就OK啦
然后我们就可以 python webui.py
(如果有pycharm就更好了)
这样就可以开始我们的仿声啦
(hym要把这个项目用作正途啊)
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















