開了眼了,上週編輯部還在說下半年感覺 AI 領域沒啥大活兒了,結果沒過幾天就發現話放早了。
寧猜怎麼着,本來以爲 AI 還停留在輸入文字,然後出圖出視頻的這些程度上,結果這兩天突然有幾個 AI 公司,都開始宣佈人家可以生成世界了。

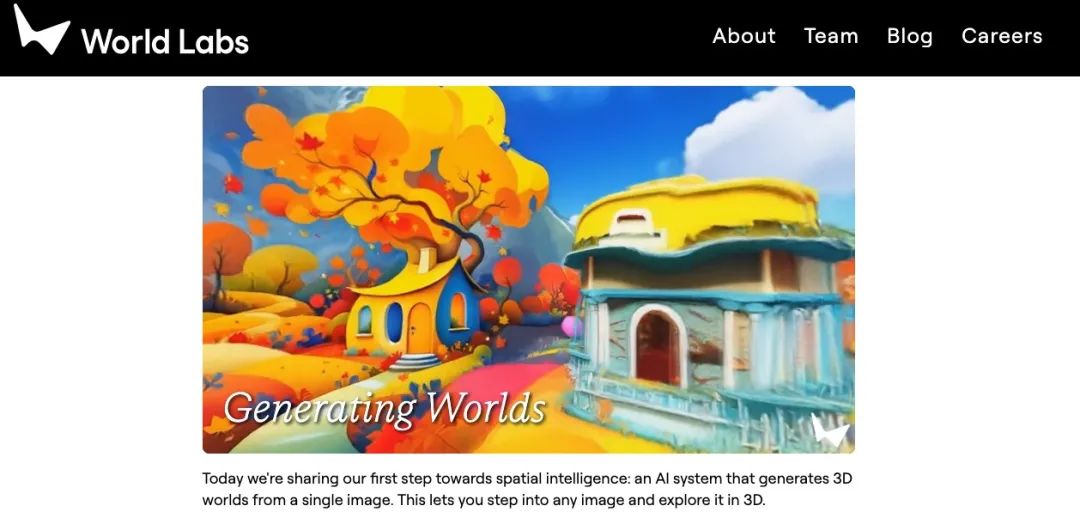
先是前幾天的 World Labs ,雖然大家可能沒聽說過,但人家創始人可是著名 AI 科學家、斯坦福大學教授、美國科學院院士、機器學習奠基人之一、有 AI 教母之稱的著名美籍華人科學家李飛飛。

說人話就是,這玩意跟以前的生圖生視頻模型不一樣了,只需要塞給它一張圖,人家就能給出一套空間建模,而且還能在裏面動。

雖然現在咱們還沒法用,但人家官網還是放出來一些案例給大家看。

大家一眼就會發現,這演示畫面裏咋有個鍵盤和鼠標。
其實就是人家爲了展示這生成出來的場景是有自由度滴,你可以自己用鍵鼠操作,在網頁上操作去試。

不過作爲行業內首發,咱也是可以理解萬歲一波的。

但好巧不巧,李飛飛這東西發佈才過了一天,還有高手。

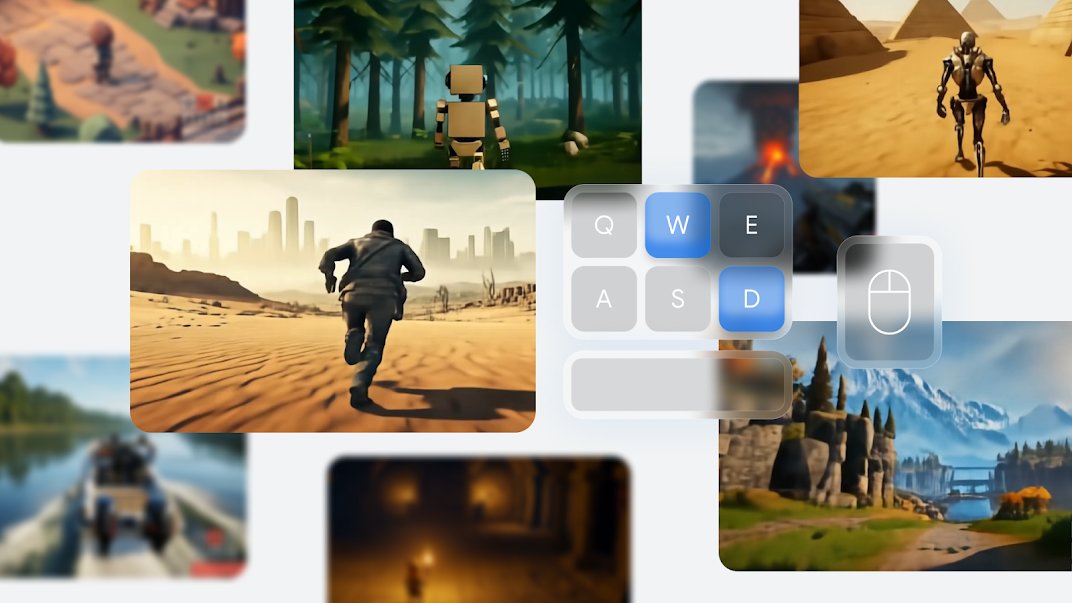
先看人家的演示,輸入一句提示詞以後生成的效果。

該說不說,這瞅着確實也挺逼真的,有兩下子。

實際上人家官網也說了,這是一個類似遊戲的基礎世界模型,在這裏面,你也一樣可以用 WASD ,空格和鼠標來操控畫面裏的角色

甚至還可以生成第一人稱視角的版本!

而根據操作產生的畫面,則全部是由 AI 即時算出來的,甚至可以持續長達一分鐘時間。

而已經生成出來的畫面和建模,你要是操控鍵盤往回走,會發現之前是什麼樣現在還是什麼樣。

這就很離譜了,相當於生成出來的這個新世界,每一秒長啥樣這 AI 都是能記得住的。

除此之外,這裏面的角色和交互也很有看點。
光在運動上,就不止常規的步行,你可以跑可以跳,還可以爬梯子


甚至可以開車,還可以開槍射擊。


而裏面 AI 生的 npc 們,也是可以發生交互的

雖然這交互效果有點不盡人意,但還是能看出來動了的。
而在整個場景中,跟自然相關的運動場景也能搞出來.
就比如水面:

還有煙霧:

還包括了重力和光線反射效果:


哪怕你給出現實中的照片,它也能跟着模擬一下週圍的環境,瞅着跟谷歌地圖的街景似的。

雖然視覺效果着實挺牛逼的,不過,跟李飛飛那個一樣,DeepMind的新模型也沒有給出來讓大家上手試,只在官網發佈的他們測試的版本。

不過這次比較好玩的是,DeepMind也很實誠的說,他們這個還是一個早期的版本,自己測試的時候也會出現一些翻車案例。

就比如下面這個,本來說讓畫面裏的小哥滑雪,結果 AI 給他搞成了跑酷。

還有一個花園的場景,玩家還沒操作呢,啥都沒動,結果花園裏突然飄過了一個幽靈。。。

雖然還有瑕疵,但是就從他們給的這些演示上,世超覺得這確實是在 AI 理解世界這方面,取得了比較成功的進步。

其實還是跟訓練 AI 的方向有關係。
Sora 雖然剛出來的時候號稱世界模型,但是實際這些視頻模型穿模的情況還是很多的,幻覺也不太好解決。

就比如說,讓 AI 從看視頻裏學到物體有重量,是相當困難的。

而要讓 AI 意識到這些真實世界裏的參數,它首先就得知道環境是一回事,環境裏的人和物是另一回事,所以大家才從文生圖模型,一步步走向了生成地理環境,而後在環境內去呈現人的動作。

但相比上面 World Labs ,DeepMind顯得更厲害一點,這其實跟他們的技術路線不一樣有點關係。如果說前一個是打算用圖片來還原更真實的場景,後一個則是用 AI 給你生成了一個遊戲世界。
當然他們之所以能搞出來,主要人家在訓練的時候就是按遊戲素材來學習的.
相比視頻素材,遊戲的好處就在於 ai 不僅能學到角色和畫面的動態變化,也能觀察到角色動作的鍵盤操作,是如何影響畫面和動作變化的,這樣它就對物體與環境的交互理解的更全面。

結果到了 2.0 版本,人家給 3d 的整出來了,實際效果看起來也非常接近大家平時玩的這些 3d 遊戲,甚至比一些遊戲的畫面質量還要好一點。

不過呢,咱也不是說DeepMind就發現了 AGI 的通用解,演示中表現的還行也不等同於 AI 就真的理解現實。
最明顯的原因就是,這 AI 是靠遊戲學的,而遊戲是人類根據現實來做的。靠人類的二手資料學的再好,也絕不等同於對真實世界的理解無誤。
至於 AGI 啥時候真來,咱還是得說句,再等等。
撰文:納西
編輯:江江 & 面線
美編:萱萱
圖片、資料來源:DeepMind,World Labs,MITTech等,部分圖源網絡

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















