某國政客扇扇嘴皮子,CN玩硬件和深度學習的圈子裏就掀起了一場風暴,這就是著名的嘴皮子效應(誤)。沒了高性能計算的A100H100倒也能理解,但是美利堅這波把RTX4090禁售了就讓人無語了,所以不少做深度學習的老哥都在找替代方案。沒了RTX4090之後,完全CUDA應用就只有上一代的RTX3090堪用,但是很多朋友不知道,其實AMD的Radeon系列民用顯卡也是能做深度學習的,而且性能也並不差。而且就在不久之前,AMD的11月和12月驅動兩次加強了7000系顯卡的深度學習能力,DirectML也有提升
DirectML API在Windows和Linux都有對應的AI繪圖整合包,也可以使用Olive或者HIP,同時ROCm在Linux上能夠替代CUDA做Pytorch或者TensorFlow的GPU加速,算是目前非常有潛力的CUDA替代方案。今天我就來給大家詳細說說如何使用大家手中的A卡,來部署深度學習用的ROCm和ONNX,以及如何實現在Windows和Linux上跑AI繪圖!
1、選擇你的系統和環境
平臺的選擇會決定顯卡用什麼樣的方式來運行,因爲深度學習開發一般都是使用Python的,所以Win和Linux上有比較大的區別。一般玩家肯定是需要Windows來玩遊戲的,但是開發老鳥或許更熟悉Linux一些,因此給大家列出下面這些選項
如果是一般玩家,家裏有一張A卡,看着AI繪畫眼饞,可以直接看第二段的Windows入門級教程。
如果是對於開發比較熟悉的,想要體驗性能比較高的AMD顯卡深度學習推理,可以看第三段的windows ONNX+Olive,這個也可以用於其他模型的深度學習推理。
如果家裏有多的硬盤,可以裝雙系統或者直接有多餘的主機可以裝Linux的,可以看第四段的Linux ROCm滿血部署方案,這個可以直接作爲開發平臺使用(優先推薦用這個)
這次我用的配置是我一直以來用作輔機的配置,R9 7900X+RX7900XT,但是換了新的內存和硬盤,如圖,這個配置我跑AI繪畫和簡單的開發是沒有問題的,大規模訓練肯定還是優先上服務器



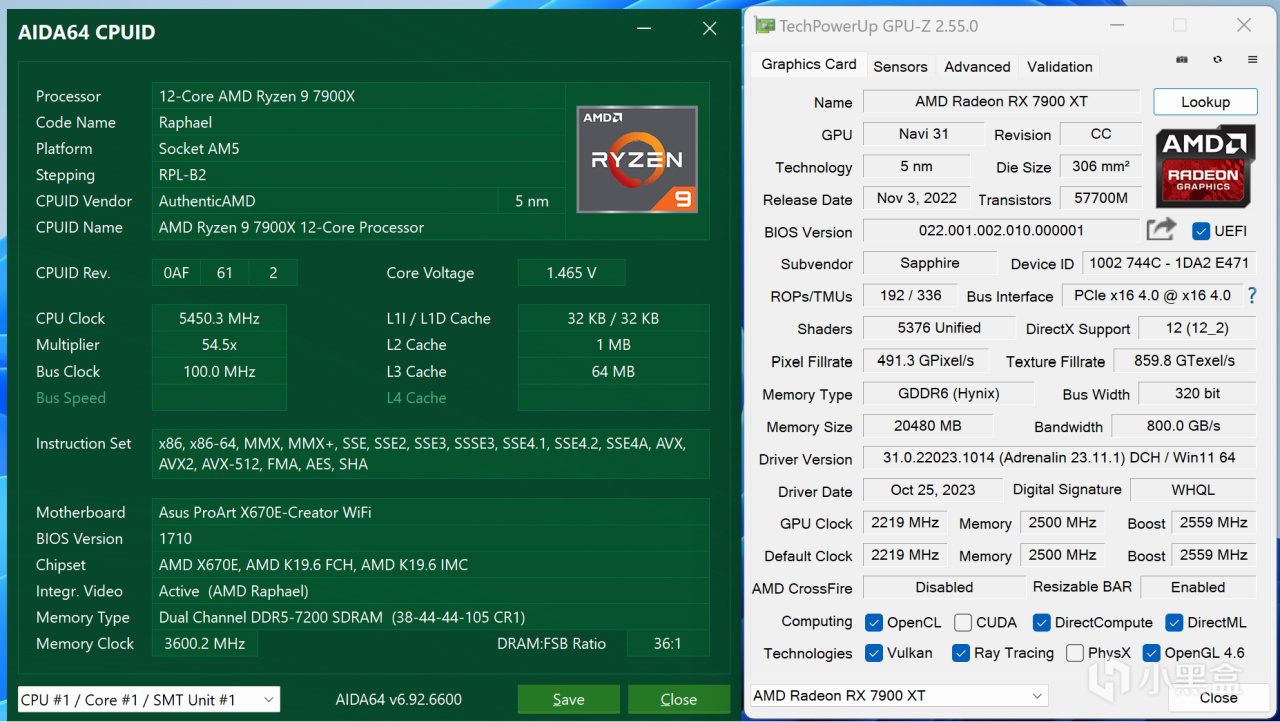
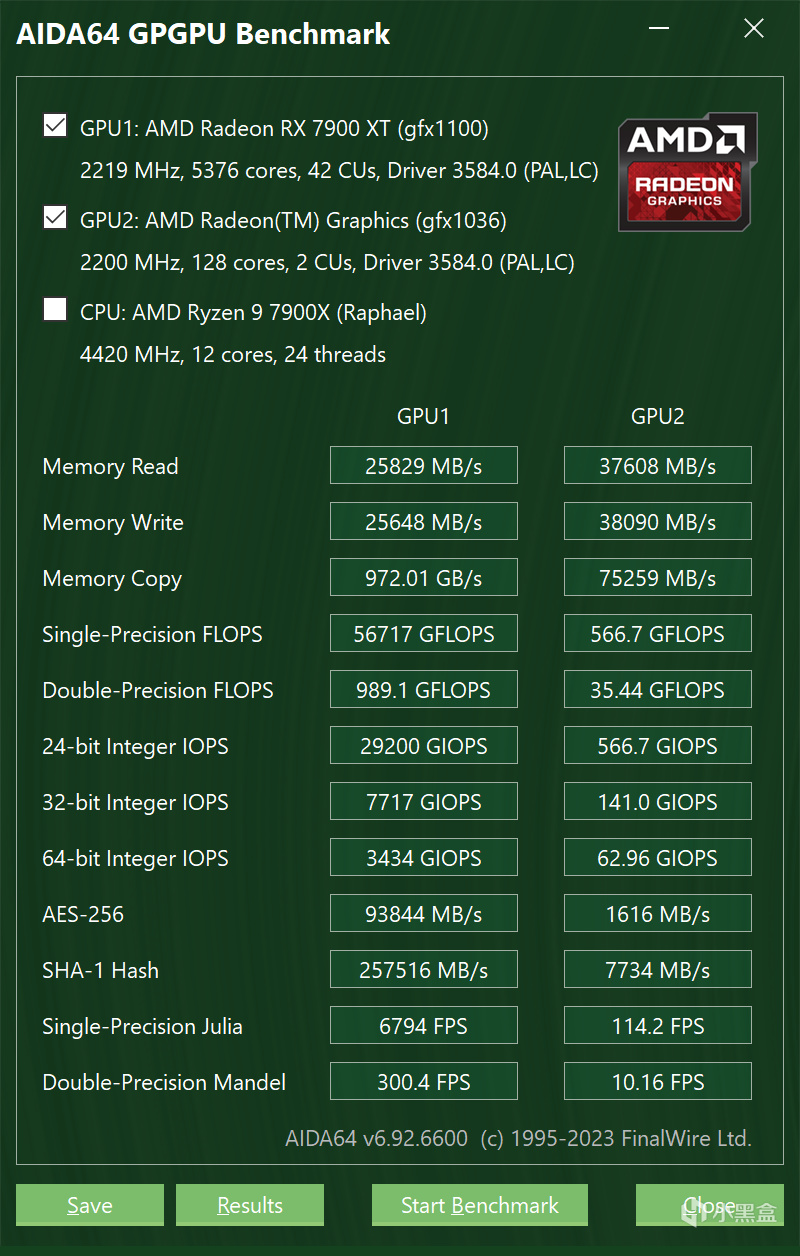
從測試上來看,7900XT這張顯卡實際上有56T單精度浮點的實力,理論上深度學習能力應該不差,現在ROCm更新之後終於好好優化了這幾張頂級的顯卡
2、Windows AMD GPU AI繪畫教程
這一部分內容很簡單,因爲ai繪畫目前已經有非常多的整合包了,所以直接使用是沒有任何問題的。這裏使用的整合包是某站大up秋葉地址的包,具體的使用過程和包的選擇可以查看他的文章,需要根據自己的平臺和想要的版本來進行選擇。
因爲本次使用的平臺是AMD,所以選中的是使用DirectML API的整合包,直接下載之後打開即可。程序會自動檢查更新並且安裝依賴的.Net6.0,整個UI非常整潔易懂
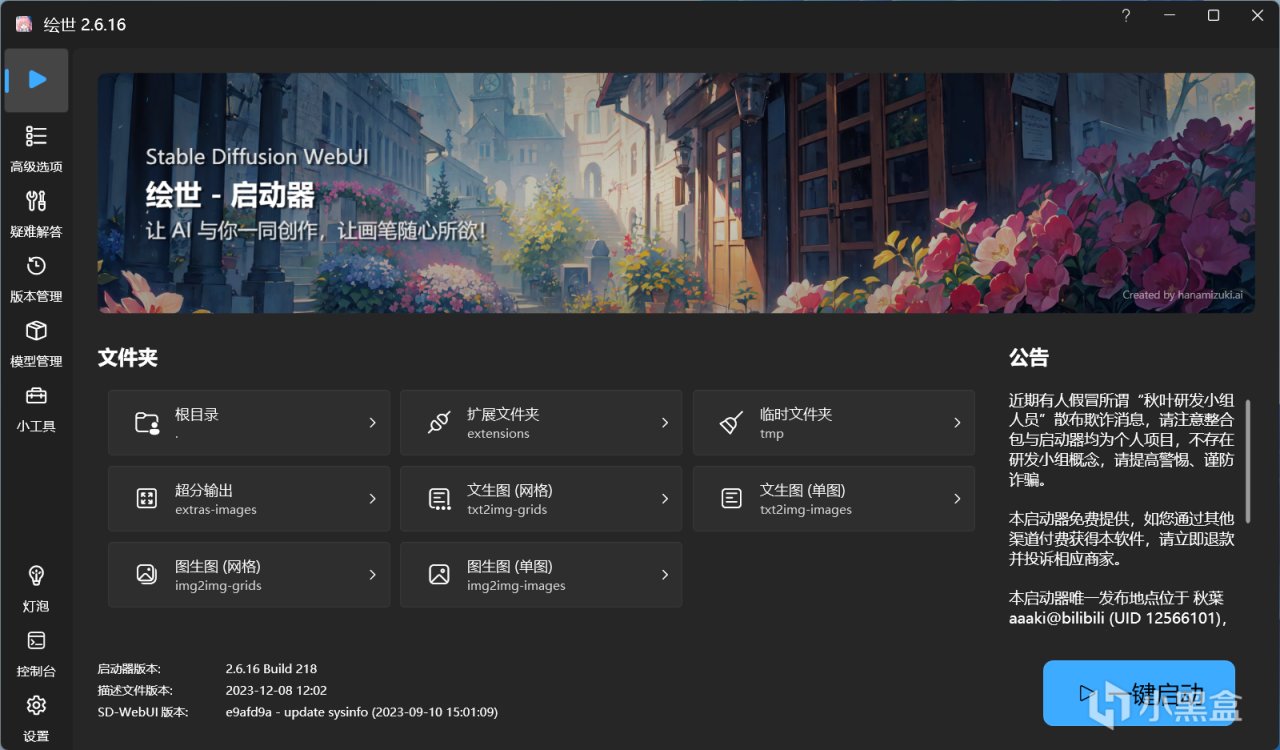
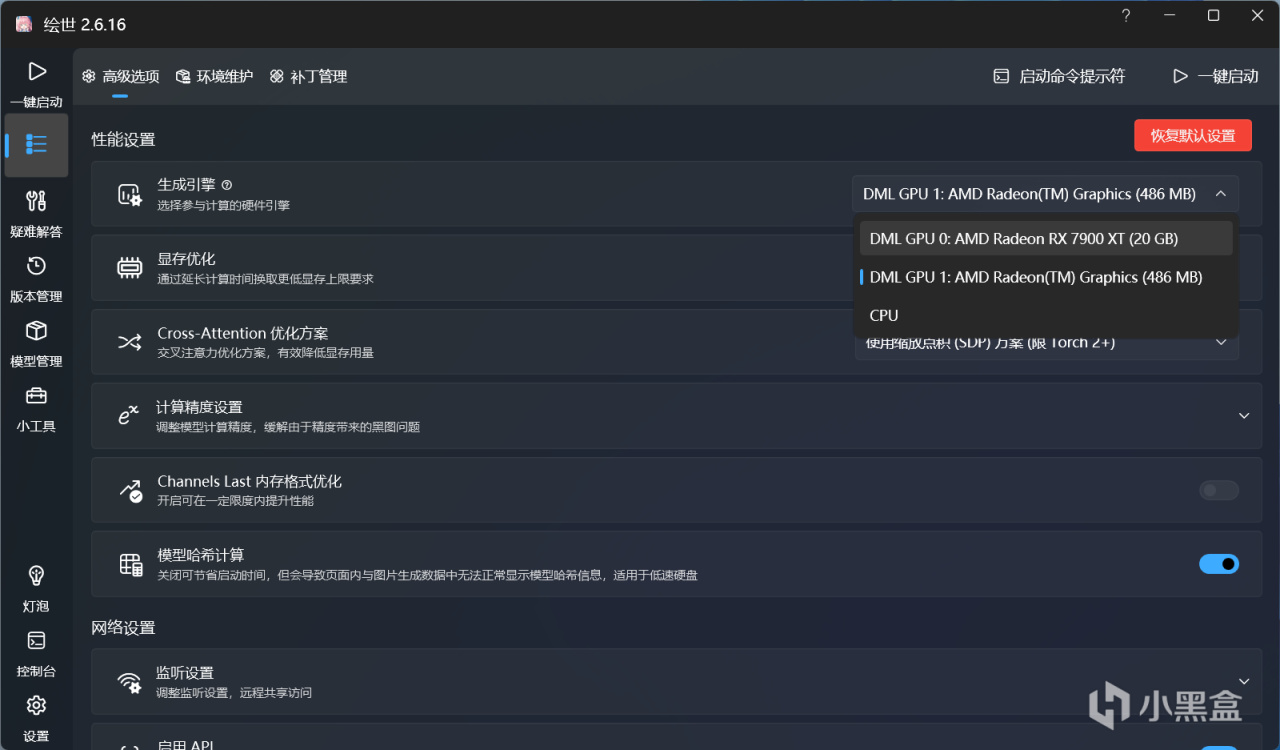
在使用過程之前,還需要一些小設置,首先是引擎選到GPU上,現在AMD可以直接使用DirectML進行AI圖像生成,選自己的顯卡即可。顯存優化根據自己顯卡的顯存來判斷,一般選擇8G優化會比較快,其他的就不用更改,一鍵啓動即可開始AI繪畫
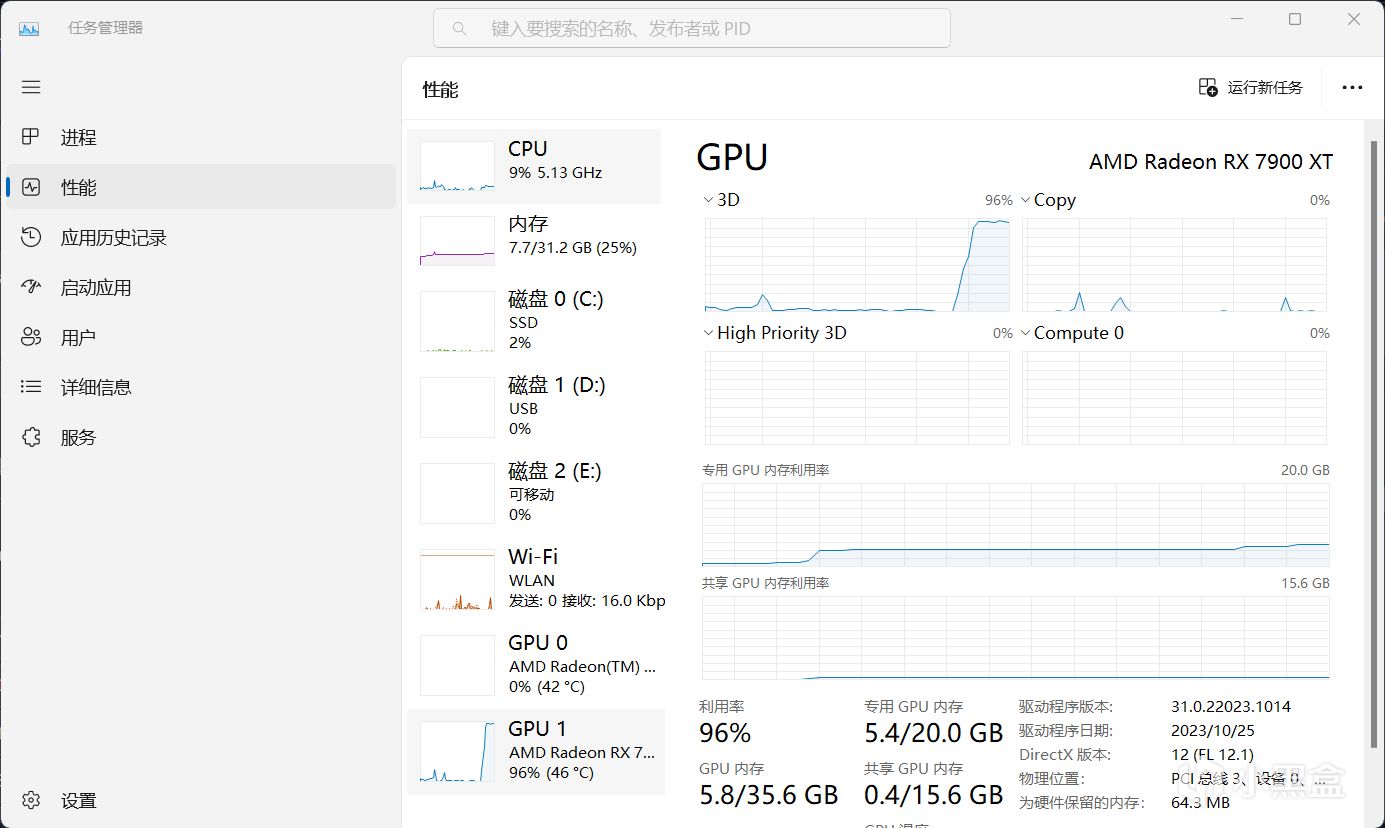
可以看到生成過程中,顯卡實際上使用最多就是自己的張量核心,不過可惜的是目前DirectML並不能獲取滿血的性能,需要更高性能的話需要Olive或者使用linux
3、Windows AMD GPU ONNX+Olive使用教程
ONNX即是Open Neural Network Exchange,是爲了適應多種不同的深度學習框架而產生的一種通用性深度學習框架,可以處理Keras、Pytorch以及Chainer等一系列不同的模型文件並獲得ONNX模型。獲得ONNX模型之後就可以使用Windows的ML進行加速了,而AMD與微軟一起維護了一個Olive的優化方法,這個方法可以將GPU原本DirectML的調用方法改爲使用ONNX+Olive,從而大幅度提高性能
部署方法也不難,首先第一步是安裝Conda環境,我推薦使用anaconda,miniconda也可以,用anaconda的GUI會更方便一些。打開conda的prompt.exe,分步執行下面這些命令,即可完成Olive安裝
conda create -n onnx python=3.11
conda activate onnx
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install olive-ai[gpu]
然後需要安裝一個git,這個熟悉代碼的朋友應該都知道,我這裏就不具體講述怎麼安裝了,安裝之後重啓,然後繼續進入conda中onnx環境的prompt.exe,考慮到大部分網友都在本地,所以比官方教程多了換源的步驟
git config --global url."https://hub.nuaa.cf/".insteadOf "https://github.com/"
git clone https://github.com/lshqqytiger/stable-diffusion-webui-directml
cd stable-diffusion-webui-directml
git submodule update --init --recursive
venvScriptsactivate
pip install httpx==0.24.1
webui.bat --onnx --backend directml --precision full --no-half
接下來就進入的是帶有onnx的Stable Diffusion,在Olive選項卡中選擇Optimizing model with Olive即可獲取一個經過優化的模型,在最上方的選項卡中選擇這個模型,即可加速AI繪畫過程了
性能對比
經過測試,這樣的方法能把AI繪畫的速度提升到原來的三倍左右,但是仍然不是完全體。使用512x512的大小進行測試,使用DPM++ SDE Karras採樣方法,可以看到,在9月的驅動中,直接使用DirectML的話只有1.11次迭代這樣的速度,也就是畫圖一張圖20次迭代需要18s左右,如果使用新的12.1驅動,DirectML的性能暴漲到了3.58,畫圖僅需要不到6s,有超過3倍的提升。如果進一步使用Olive提升速度,則能達到10.71,2s一張出圖速度已經非常快了
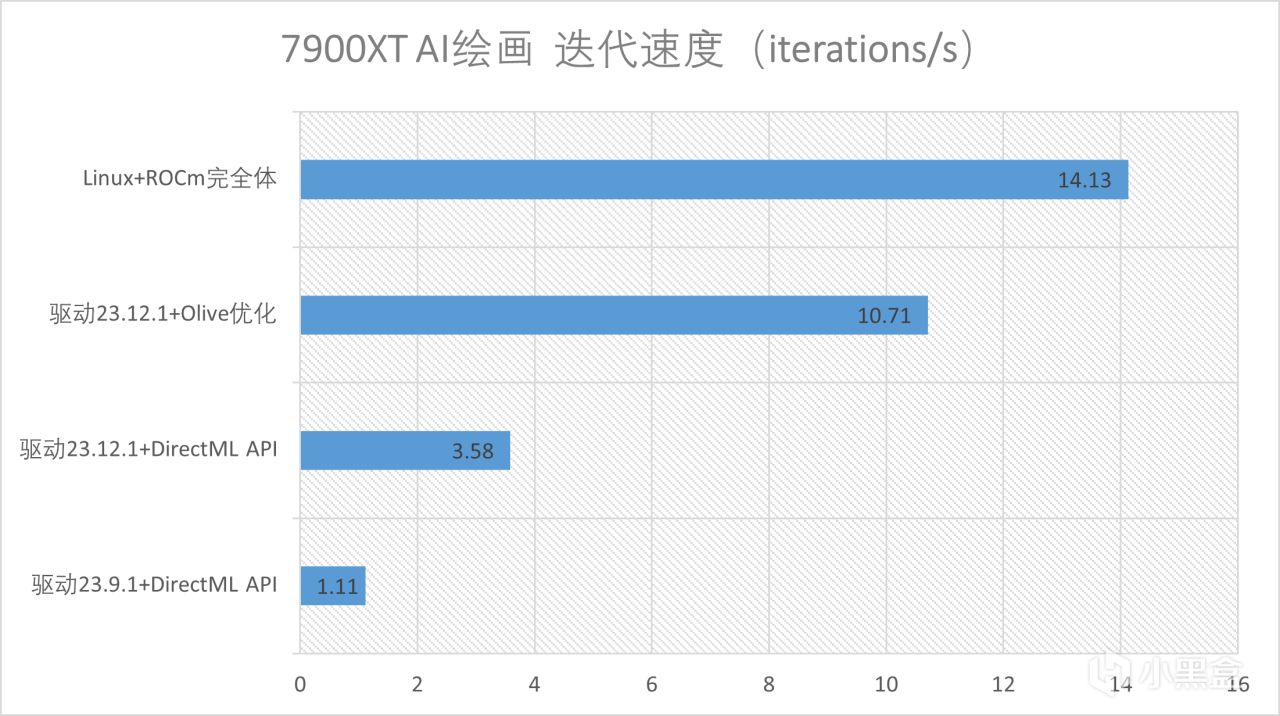
但這仍然不是AMD深度學習的極限,ROCm目前可以做到完全釋放顯卡的性能,在簡單的深度學習開發上基本能和CUDA平起平坐,也是我最爲推薦的一種方式,下面一個章節我來詳細介紹一下如何安裝部署一個基於ROCm的深度學習環境,並且實現stable diffusion
4、Linux AMD ROCm部署
隨着AMD不懈努力,AMD的ROCm on Linux終於形成了一個還不錯的環境,是目前僅次於CUDA的一種深度學習API了。而且ROCm在Pytorch以及Keras中的使用方法仍然呼做cuda,所以很多代碼是不用更改就能換成ROCm來使用的。而且ROCm有自己的amdgpu-dkms管理,安裝上比起一言不合就not found 的cuda要穩定不少,所以我個人是非常推薦目前有A卡的朋友在做開發的過程中使用ROCm作爲CUDA的平替
ROCm的部署過程也不復雜,我這裏就手把手的來教大家用一下。因爲7000系顯卡是最新支持的,AMD把這些顯卡的應用內核版本限制到了22.04的Linux上以便uptodate,所以首先我們需要準備的是Ubuntu22.04.3版本的系統,可以直接官網下載,具體安裝過程我就不贅述了,網上的教程已經非常豐富
開機第一步,使用apt命令對源以及包進行一次更新,然後確認內核版本是否爲ROCm所支持的(目前LTS版本是一定支持的,這一步可以省略),然後安裝一些一定會用到的應用,比如curl git 和vim這些
sudo apt update
sudo apt install curl vim ffmpeg gfortran libsrdc++-12-dev cockpit openssh-server
uname -a (檢查版本用)
按照AMD官方的指引一步一步地安裝ROCm,一般來說使用AMDgpudkms是最方便的安裝方法,我這裏推薦使用5.7版本的ROCm,使用官方的dkms來安裝管理這個系統。分步執行下面這些命令,即可安裝ROCm。這些包非常大,所以建議耐心等待或者使用更流暢的網絡
curl -0 https://repo.radeon.com/amdgpu-i ... 5.7.50701-1_all.deb
sudo apt install ./amdgpu-install_5.7.50701-1_all.deb
sudo amdgpu-install --usecase=hiplibsdk,rocm
sudo usermod -aG video $USER
sudo usermod -aG render $USER
sudo reboot (重啓之後才能看到rocm安裝好沒有)
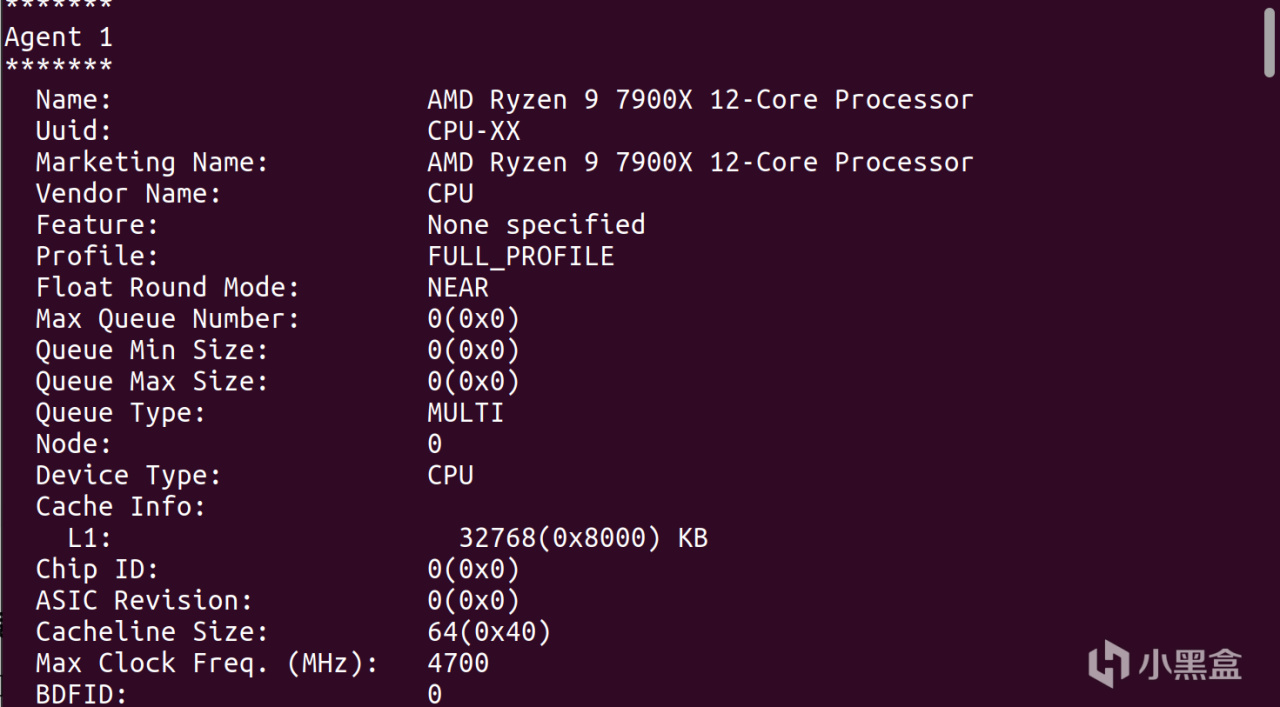
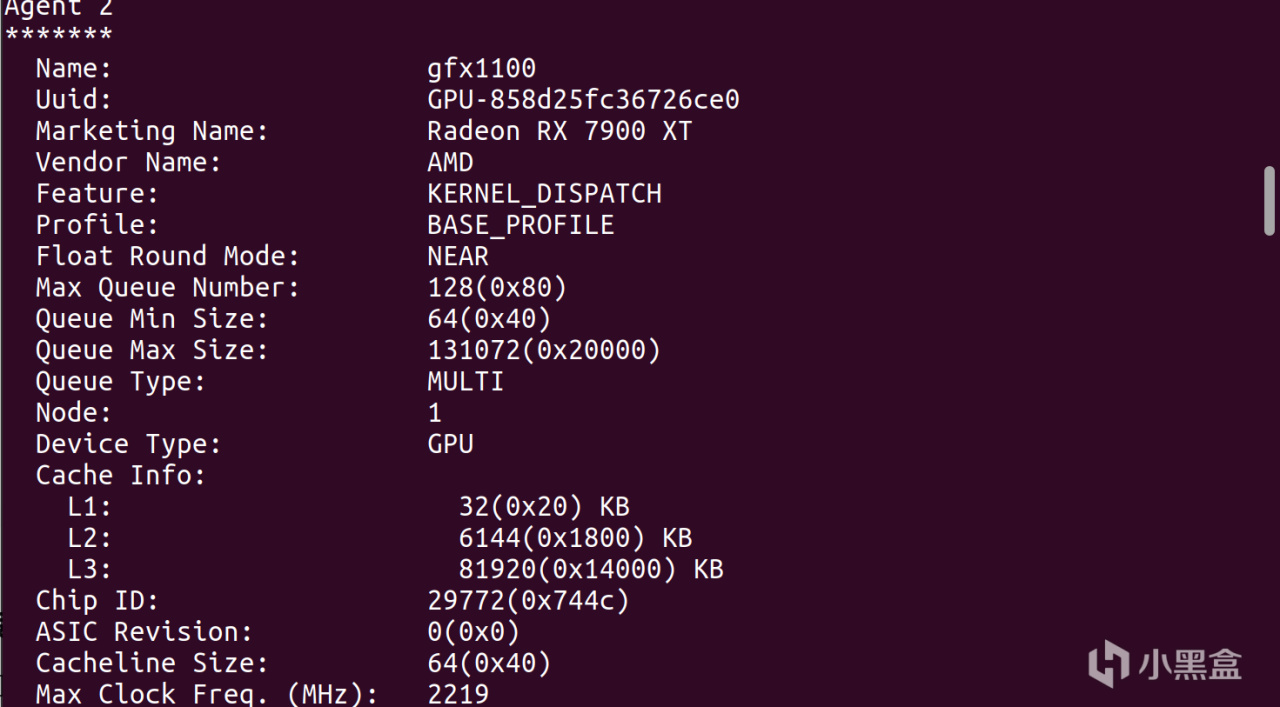
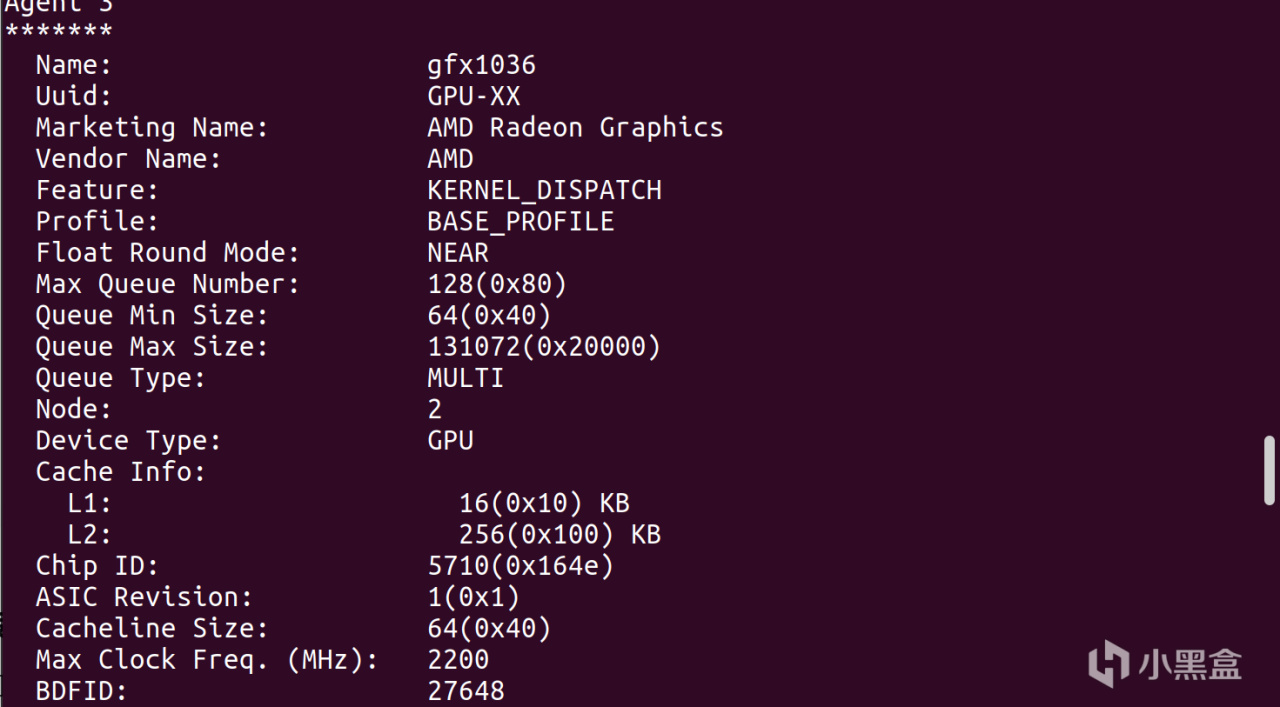
重啓之後,再次打開terminal,就能使用rocminfo命令以及rocm-smi對硬件進行監測了。可以看到ROCM支持的設備一共有三個,分別是CPU、79TXT和核顯
rocminfo
watch -n .5 rocm-smi
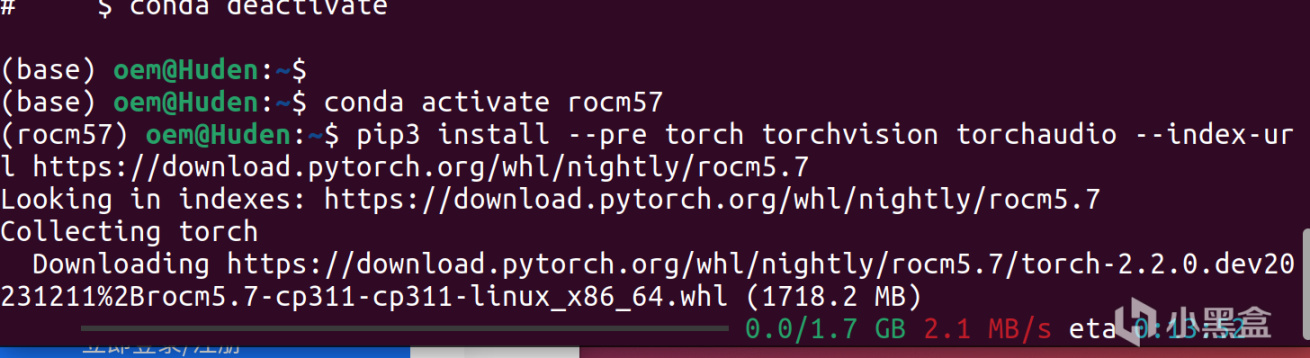
下一步需要安裝miniconda或者anaconda,這個我就不細說了,網上教程非常多。安裝之後重啓terminal,然後對conda進行換源,並且創建一個針對ROCm的新環境,我這裏命名爲ROCm57,大家可以自行更改。隨後,進入這個環境,更換pip的源,安裝深度學習所需要的torch包,這個包也是Stable Diffusion所需要的。有兩種方案,一種是安裝穩定版的,一種是安裝preview版的,我使用的是preview版,也是可以自行選擇其中之一
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda create -n rocm57 python=3.11
conda activate rocm57
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(安裝穩定版)pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
(或者安裝預覽版)pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.7
到此爲止,這個環境就已經可以使用torch對代碼進行調試開發了,rocm的呼喚方法和cuda是一樣的,不用特意修改代碼
需要Stable diffusion的話,下面就可以使用git clone對Stable Diffusion進行下載,用pip安裝依賴。安裝好之後就能進行試運行了,試運行的目的是爲了檢查代碼是否能跑通,否則用bash是跑不起來的
git config --global url."https://hub.nuaa.cf/".insteadOf "https://github.com/"
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
pip install -r requirements.txt
HF_ENDPOINT=https://hf-mirror.com python launch.py --listen --autolaunch
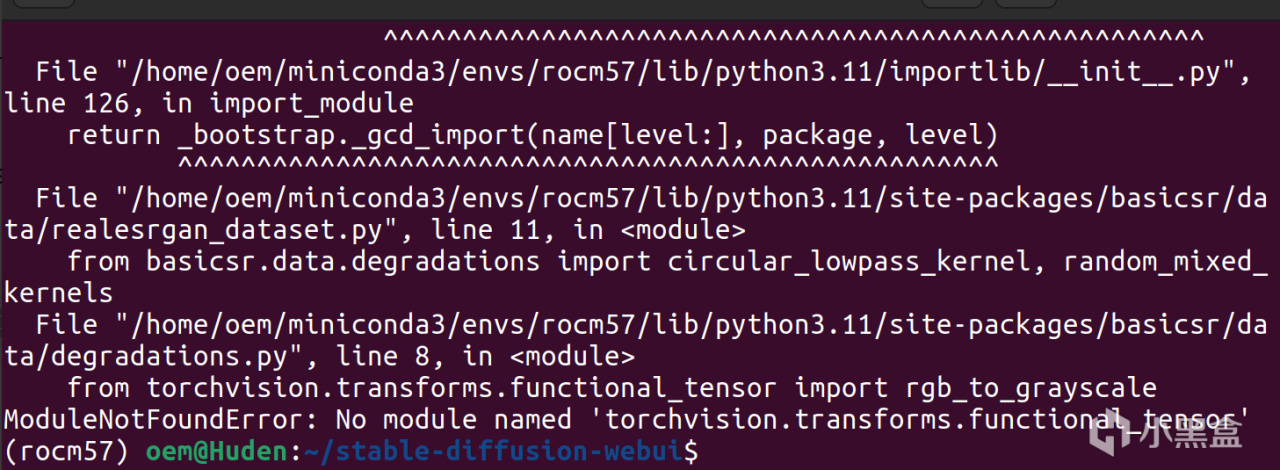
可以看到這裏有一個module錯誤,這個錯誤是因爲basicSR年久失修沒有跟上torch版本導致的,所以我們需要根據自己環境地址,對這個文件進行修改
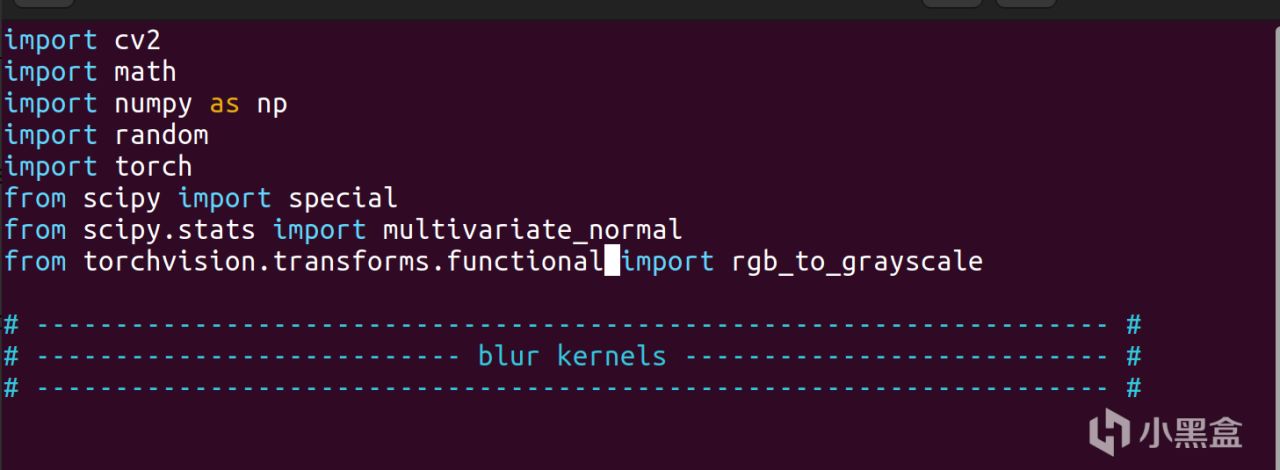
使用vim命令修改文件,改成如下的格式
sudo vim ~/miniconda3/envs/rocm57/lib/python3.11/site-packages/basicsr/data/degradations.py
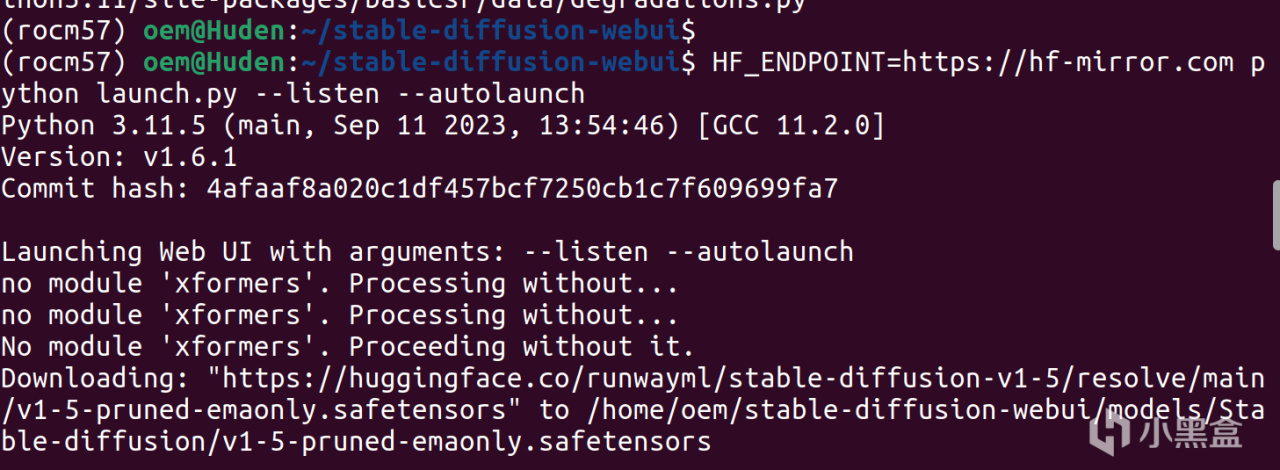
下面繼續進行測試,一般不會出現報錯了,如有報錯可以在評論區交流。但是如果網絡不佳會出現如下這種下載不了與訓練模型的情況,這個情況是非常好解決的,目前網絡中SD的預訓練模型很多,下載一個喜歡的放一個進去就行,~/stable-diffusion-webui/models/Stable-diffusion/,如果之前操作了win上的整合包,那麼要做的就是直接把整個models文件複製過去!非常方便快捷
下面就能啓動模型畫圖了,我這裏提供一個便捷的啓動腳本和命令。其中有一些需要自己修改,比如HSAversion,你的顯卡是7000系的,就用11.0.0,如果是上一代或者上上代就用10.3.0
cat < ~/stable-diffusion-webui/ezlaunch.sh
#!/bin/sh
# select version according to your GPU: RX7000s use 11.0.0; RX6000s5000s use 10.3.0
export HSA_OVERRIDE_GFX_VERSION=11.0.0
# select HIP according to your GPU node: GPU:0, iGPU:1
export HIP_VISIBLE_DEVICES=0
export PYTORCH_HIP_ALLOC_CONF=garbage_collection_threshold:0.8,max_split_size_mb:512
python3 launch.py --listen --opt-split-attention-invokeai --enable-insecure-extension-access --no-half-vae
EOF
然後使用下面這個命令在任意時候都能打開SD服務,如果家在模型完成(出現model loaded),打開本地的0.0.0.0:7860就能使用了
conda activate sd && cd ~/stable-diffusion-webui && bash ezlaunch.sh
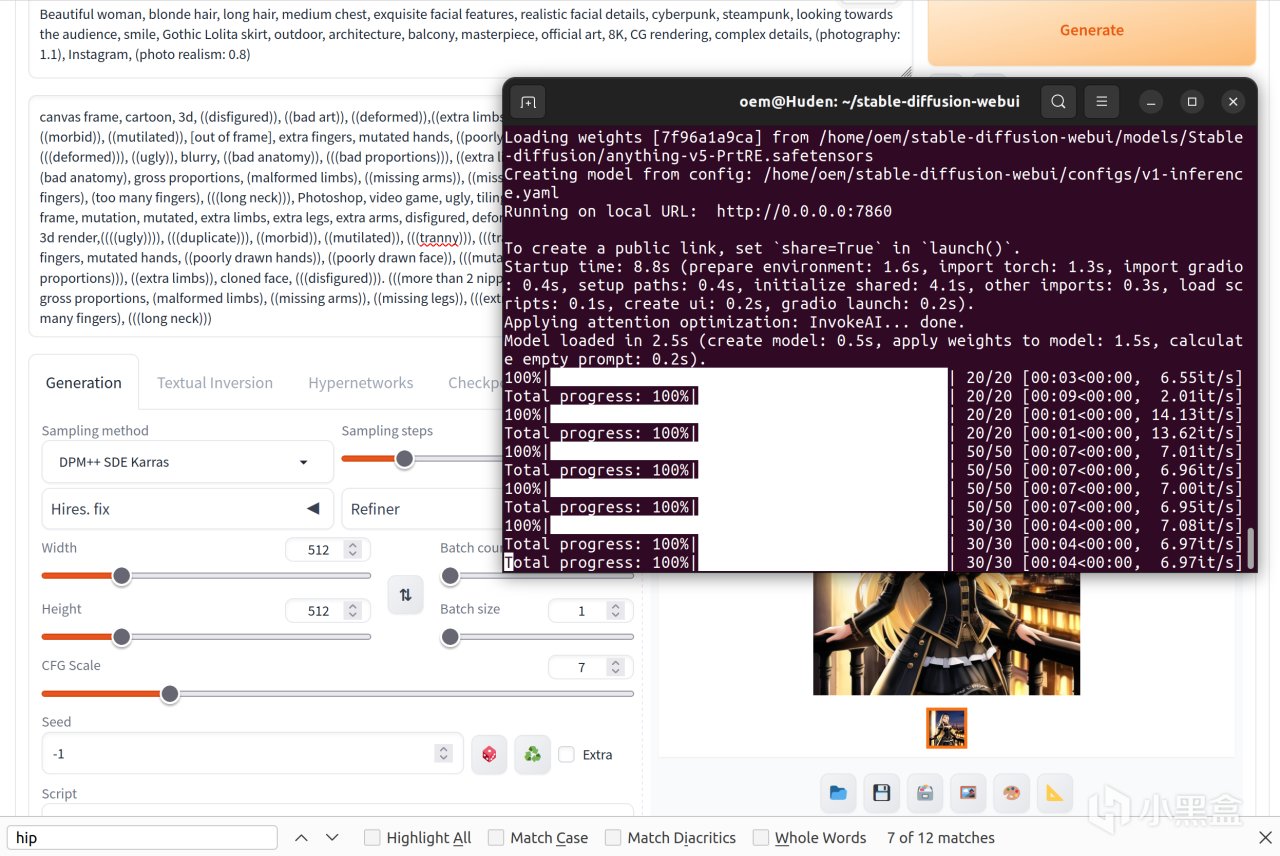
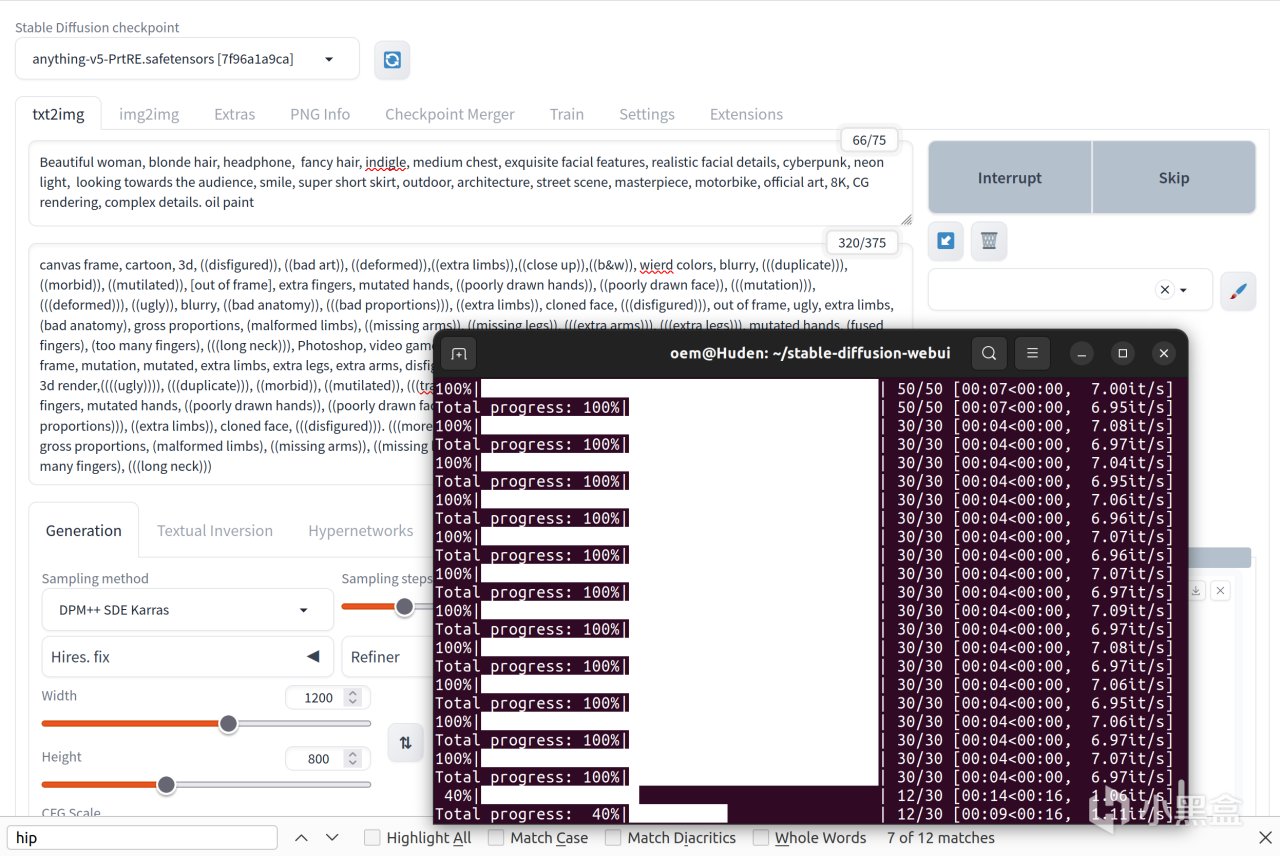
大模型+高顯存+大圖片會讓迭代速度下降很多,不過在相同的512x512環境下使用SD的話,14iterations/s的速度可以說是吊着windows上任意方式打的
512x512的圖片分辨率不夠的話可以提升到1200x1200,迭代速度大概4it/s,只要顯存夠,那麼迭代速度只根據圖像大小線性下降,倒也是能接受的



這樣的環境是可以進行深度學習開發的,除了系統中指定顯卡和版本的語句不一樣之外,在pytorch中的使用和CUDA是完全一致的,所以我認爲目前ROCm在簡單的深度學習開發上,基本可以做到替代CUDA了
5、硬件介紹
本文使用的CPU和主板是AMD R9 7900X+ ProArt X670E-Creator,性能充沛,且內存適配也不錯,比如這詞用的內存就是7200MHz的,可以直接EXPO ii開機,如果要部署工作站或者開發機的話,也可以選擇R9 7900













顯卡用的是藍寶石的超白金RX7900XT,這張顯卡是目前藍寶石最好的7900XT型號,玩遊戲基本可以暢玩4K,做深度學習也有20GB的顯存,而且價格比79XTX低不少,而且散熱不錯,個人很喜歡






內存和硬盤是金士頓的RENEGADE 7200MHz 16x2和KC30002T,最近硬盤即將漲價,需要買硬盤的朋友得趕緊了。金士頓的高頻燈條RENEGADE造型做得確實非常不錯,燈光也可以同步,頻率高而且穩定,在X670E上也能直接EXPO開機,我覺得是目前比較值得買的高頻DDR5內存











電源是海韻的新Focus GX1000,在經過多次改良之後,海運的新版Focus不僅標準符合了ATX3.0標準,而且也支持12VHPWR接口,面對新的顯卡也毫無壓力







純白色的造型並且還送一套壓紋線,直接免去了定製線的需求,而且這個線還挺軟,走線也沒什麼壓力,用起來很舒服
總結
很多朋友都覺得買了AMD就和深度學習絕緣了,其實並不然,AMD現在不僅在Linux上有ROCm,在Win上使用Olive加速之後,進行模型推理也並不慢。而AI繪畫這個原本只有頂級顯卡才能跑的項目,現在經過層層優化,也能輕鬆部署在家用顯卡上了。對AI繪畫感興趣的朋友可以趕緊用手上的顯卡嘗試一下,畢竟現在AMD顯卡是真不貴,對比一下某禁售的4090,就只要三分之一的價格就能買到次旗艦我是真覺得不虧
RX7900XT這張顯卡我是比較推薦的,一來沒有旗艦卡那種維持門面的價格,也不用把頻率調校得離譜高,二來這卡用的又是旗艦散熱,讓顯卡的散熱爽到飛起,完全不用擔心熱量壓力。而且性能和顯存完全夠用,進可暢爽玩AI,退可暢爽打遊戲,非常理想
感謝大家圍觀
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















