DeepSeek 今天又發新東西了,但這次不是模型。
噢?那不用看了沒意思是不是,先別急着划走。
DSpark 不是大模型,不是新的版本,它是DeepSeek團隊和北大聯名搞的一個推理加速框架,目前已經塞進 V4-Flash 和 V4-Pro 的預覽引擎裏跑了,高併發下,單用戶生成速度提升 60% 到 85%,V4-Flash 120 tok/s 那檔 SLA 下,吞吐直接翻了 6 倍多。
簡單來說就是優化 DeepSeek 一個工具。
誒,不是念廠商稿裏的數字吧?這件事其實比很多新模型發佈更值得看,爲啥呢,因爲這是內部功力提升的一個優化,它解決的是一件很具體的事,AI 吐字太慢。
推理加速框架是什麼?
要理解這個,先得明白大模型是怎麼幹活的。你可以把 LLM 想象成一個只能一次寫一個字的學生,而且它每寫一個字,都要把整本書翻一遍,來猜下一個字最可能是什麼。
所以你問它一個複雜問題,它不單要深度思考思考想很久,還得想完了愣一下才開始回,或者寫長文的時候,一卡一卡,吐了幾句話,又卡一下下。這個學生不是腦子慢,是它寫字的機制太慢。
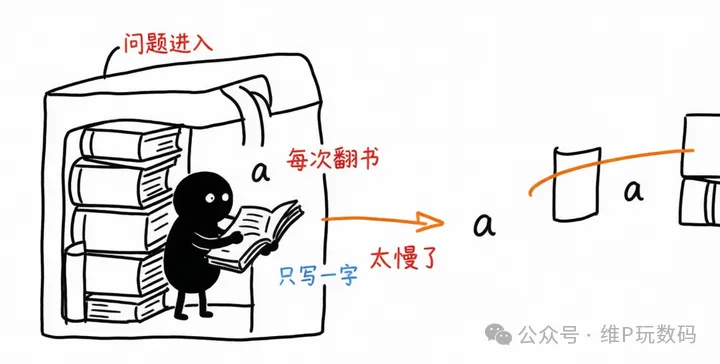
推理加速框架,就是給這個學生配了一個專門的草稿小弟。小弟寫得快,但不一定準,先嘩嘩譁寫一串候選字,然後學生再一次性檢查這一段對不對。對的留下,錯的重寫。這樣學生就不用每寫一個字都翻一遍書,整體速度就上去了。
先把一個事情做成60分,然後再把它從60分優化到80分,大概背後是有這種指導思路的影子。
DSpark 就是這個草稿小弟的升級版。它不只是發論文,是真塞進了 DeepSeek 自己的生產引擎裏跑。
好,原理就這樣。但你是不是決定,誒,我如果不用 DeepSeek ,我就是天天喜歡豆包姐姐哄我開心,可能覺得這事兒跟你沒關係。
有關係的。
你下次用 DeepSeek-V4 的時候,尤其是 Flash 或者 Pro 那兩檔,會明顯感覺它回得快了。高峯期你堵在加載動畫轉圈的概率小了,它回你回得快了,而且這種技術思路也會同樣影響其他大模型的發展,以前爲了追求速度用的那些 Flash 模型也可以變得更強了。
Pro 通常是全參數稠密模型,或者 MoE 裏專家數/總參更大,每步激活參數量高;
Flash 傾向更小的稠密模型,或MoE 但專家更少/總參壓得很低,推理快、省顯存。
那如果這個技術能改善吐字,以前爲了吐字快的那些犧牲就可以加回來了。
普通用戶能直接感知的部分主要是這塊。
降本增效大法好
DSpark 真正有意思的地方不在這。
我有時候覺得,2025 年到 2026 年這一年,外界看中國 AI 特別容易只盯着兩件事,模型參數又多大,榜單又刷了多少。
搞得好像 AI 就只剩刷榜這一個玩法似的。
其實不完全是這樣。
你看看OpenRouter 最近這個月的數據,前三名爲什麼用的多呢?
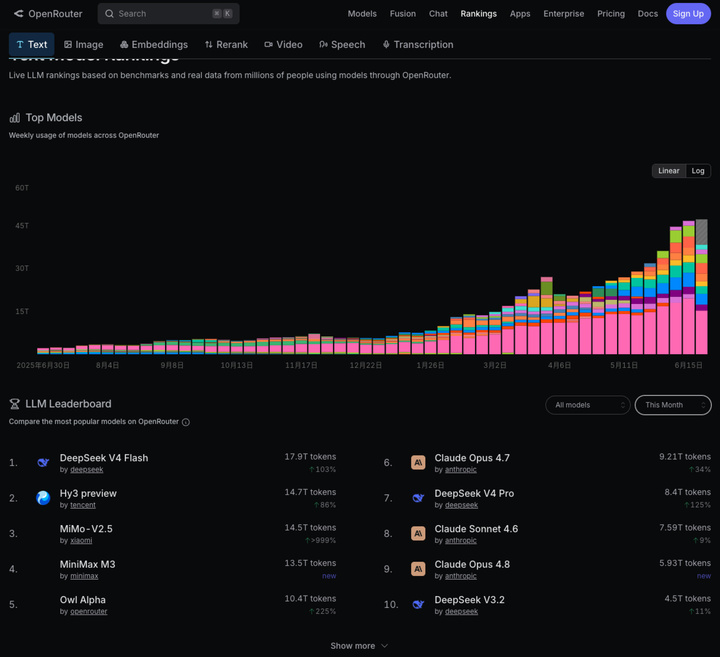
DeepSeek V4 Flash
Hy3 preview (騰訊元寶默認的那個混元模型)
MiMo-V2.5(小米做的類似 DeepSeek 路線的 LLM)
好難猜啊。
你去查一下這三個模型的 API 定價?然後再看看Claude 的定價?
除了少數富哥,多數人玩 AI 燒token那肯定還是要看看性價比的。

模型本身強不強是一回事,模型能不能低成本、高併發、穩定地跑出來服務用戶,是另一回事。前者是面子,後者是裏子,DSpark 乾的就是裏子活,等於是能讓原來的模型進一步提高效率,原先就很快的大模型能進一步加參數增智慧,原先的超大模型能講話更利索和普通大模型一樣快了。
DeepSeek 大模型官方 API 的價格更是物美價廉,如果不是特別重度的任務或者是有多模態需求,我真的安利去買它們家的 API,自己配一個 claw 或者是現在其他阿里/騰訊/百度/字節能有配置項能自己加 api key的話,也可以用別人的前端對接 DeepSeek API,真的很不錯。
你如果是自己搭推理服務的,不管是創業團隊還是公司私有化部署,絕大多數人第一時間想到DeepSeek ,主要開源倉庫(挑幾個有代表性的)你都可以拿下來玩。
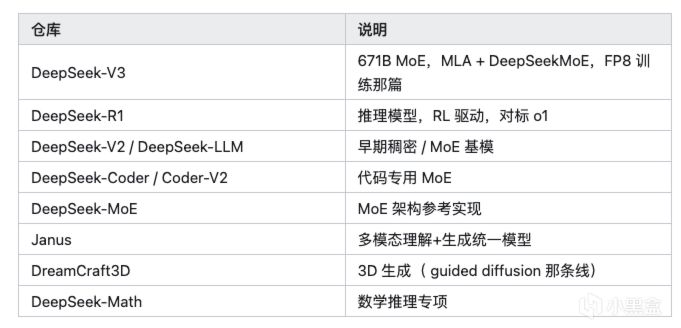
模型權重另託管在 Hugging Face:huggingface.co/deepseek-ai(V3 / R1 / Coder / Janus 權重都在那)
你如果在跑 Qwen3-4B、8B、14B 或者 Gemma-4-12B 當目標模型,DSpark 草稿模型可以直接拉 checkpoint 試,不用從零訓。
論文裏 Qwen3-4B 上 DSpark 相對 Eagle3 接受長度提升 30.9%,相對 DFlash 提升 16.3%。
接受長度直接決定你每秒能出多少 token。
成本賬也好算,假設你跑 V4-Pro 類服務,SLA 定在 50 tok/s 那檔。原來 MTP-1 基線單卡扛不動,得堆卡,DSpark 標稱吞吐提升 406%,同樣 QPS 下,卡數可以往下調一檔,或者同樣卡數扛 4 倍流量。
8 卡 H100 原來扛 100 QPS,換 DSpark 後理論能扛 400 QPS。或者 2 到 4 卡就能扛原來的量。電費、折舊、卡租金,按月算省的是實錢。
但有個坑得提醒。
DSpark 的並行主幹不管你最後驗多長,都得先把完整候選塊算出來。
複雜查詢接受率低的時候這部分草稿算力回收不回來。如果你的場景是長推理鏈加高拒絕率,比如 deep research 類 agent 跑複雜規劃,DSpark 的收益會被打折,別盲目上。
站在純學術研究的角度,DSpark 確實不是在提出新架構,而是在工程化上往前推了一步,降本增效了的風也吹進AI了屬於是。
DSpark 真正值得看的點,是中國團隊開始有能力在推理系統這種髒活累活上自己找解法。不是跟着別人論文後面跑,而是把東西塞進生產引擎,再開源出來讓人復現,已經是自己在探索一片漆黑未知的技術方向了。
AI 已經是科技戰的重要部分
中國AI大模型技術,正在昂首矯健步入第一梯隊。
旗艦也追得很近,中段和性價比端已經再內卷模式下對普通消費者及其友好。
那第一梯隊是不是有人不爽了呢?
當然了,6 月 2 號,特朗普簽了行政令 14409,建了前沿模型自願預發佈審查框架,10 天后商務部對 Anthropic 發出口管制令,本來是想說限制只給美國用不給其他國家用,但是人家 Fable 5 / Mythos 5 安排是全球下線,又過 13 天,GPT-5.6 發佈節奏被華盛頓接管,從自願框架到實際管控,難道是過於先進不便展示的新戰略?搞不好之後美國軍方相關利益方是不是又要搞出什麼新花樣。
放在這個背景下看 DeepSeek 的開源,就很有意思了,你是跟老美還是要跟老中?

中國這邊又準備給AI廠商發A股牌,就在這個月,證監會和上交所剛把科創板第五套上市標準擴到了 AI 大模型行業。以前這套標準主要給醫藥企業用,現在 AI 公司也能用。意味着像 DeepSeek 這種還在燒錢做技術、暫時沒盈利的公司,多了一條在國內上市的通道。
DeepSeek剛完成首輪500億融資(騰訊100億入局),估值3380億。梁文鋒已公開表態立志成爲中國首家創新型AI大模型企業,團隊全華班非海歸,IPO已在計劃中。智譜和MiniMax也跟着在排隊了,AI 公司很快就有機會拿着 A 股市場的錢繼續燒錢推進技術了。
可以說這一波的 AI 大模型技術已經成爲了科技戰的重要組成部分。
希望中國能夠真的在高端生產力上面取得新的突破,讓新質生產力的未來牢牢掌握在中國人自己手中,落後會發生什麼事情,中國近代史太明白了。

-----------
論文原文:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》,建議各位可以使用付費的AI進行PDF解讀(別用免費的便宜的)
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















