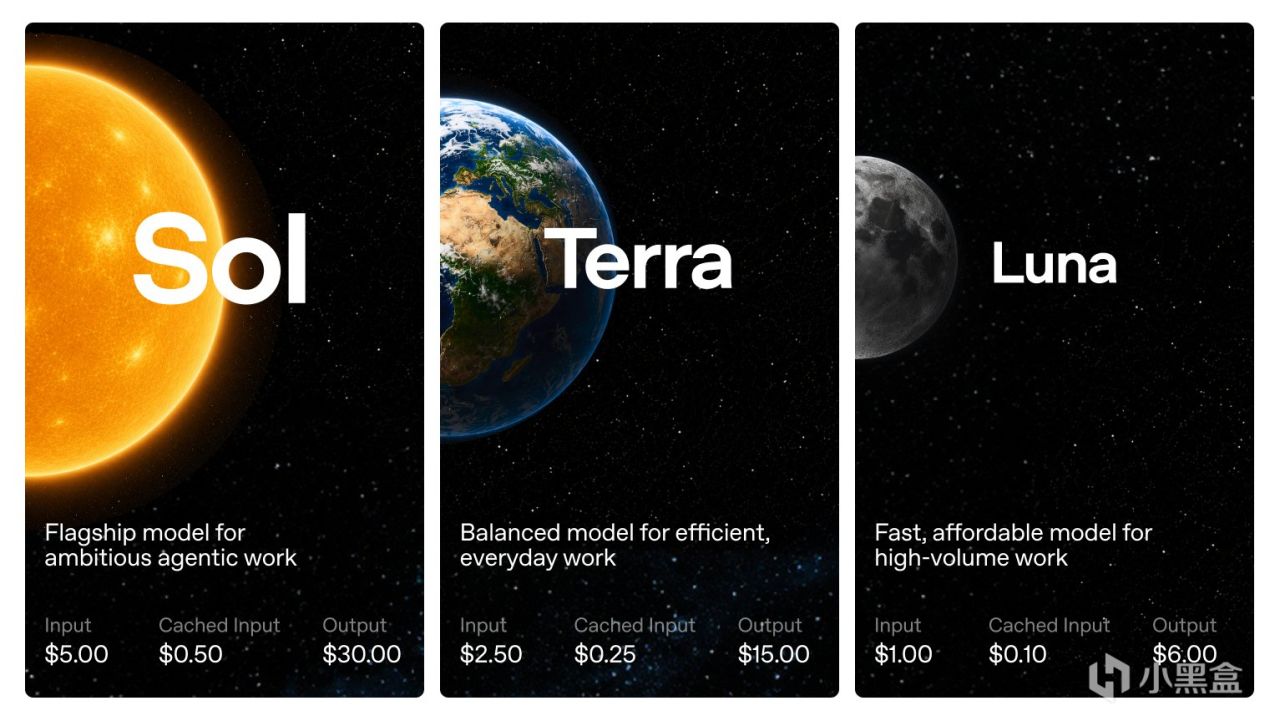
OpenAI 在 X 上發了一個gpt5.6的帖子。
第一條是常規發佈:GPT-5.6 系列開始 limited preview,分三檔——Sol 是旗艦,Terra 做日常平衡,Luna 主打便宜和高吞吐。第二條說 Sol 在 Terminal-Bench 2.1 上刷新成績,這個基準測的是複雜命令行工作流,需要規劃、迭代和工具協調。第三條最敏感:OpenAI 說,GPT-5.6 Sol 是它們目前最強的網絡安全模型,能把長程安全任務裏的漏洞研究和漏洞利用,推到新的性能效率邊界。
“漏洞利用”這幾個字,足夠讓安全圈警覺。
Sol 的兩個成績,要分開看
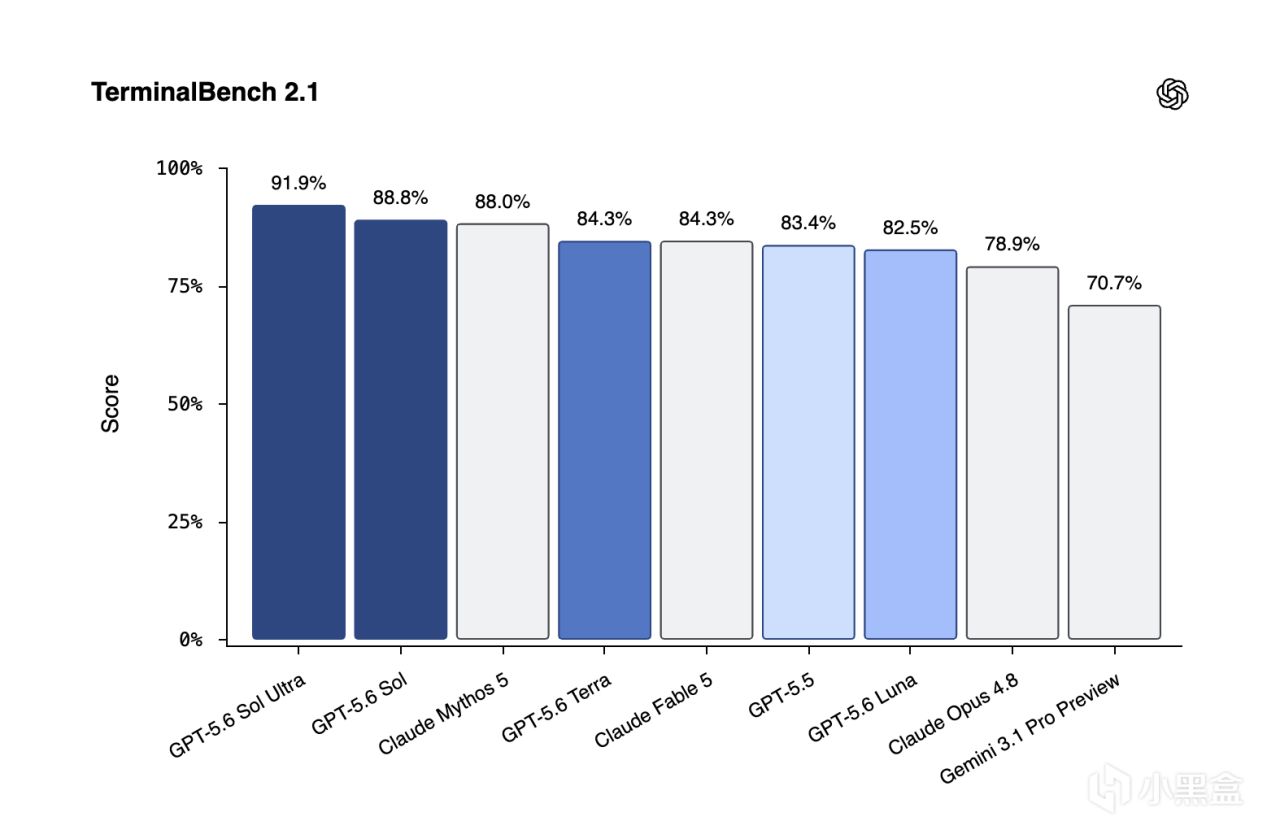
先看 Terminal-Bench 2.1。OpenAI 圖裏,GPT-5.6 Sol Ultra 拿到 91.9%,GPT-5.6 Sol 是 88.8%。Claude Mythos 5 是 88.0%,GPT-5.6 Terra 和 Claude Fable 5 都是 84.3%,GPT-5.5 是 83.4%,Luna 是 82.5%,Claude Opus 4.8 是 78.9%,Gemini 3.1 Pro Preview 是 70.7%。
這張圖只說明 Terminal-Bench 2.1 這一項:Sol Ultra 排第一,Sol 與 Mythos 5 接近,差距爲 0.8 個百分點。單項基準不能代表綜合排名,但足以說明 OpenAI 這代模型在命令行代理任務上進入第一梯隊。
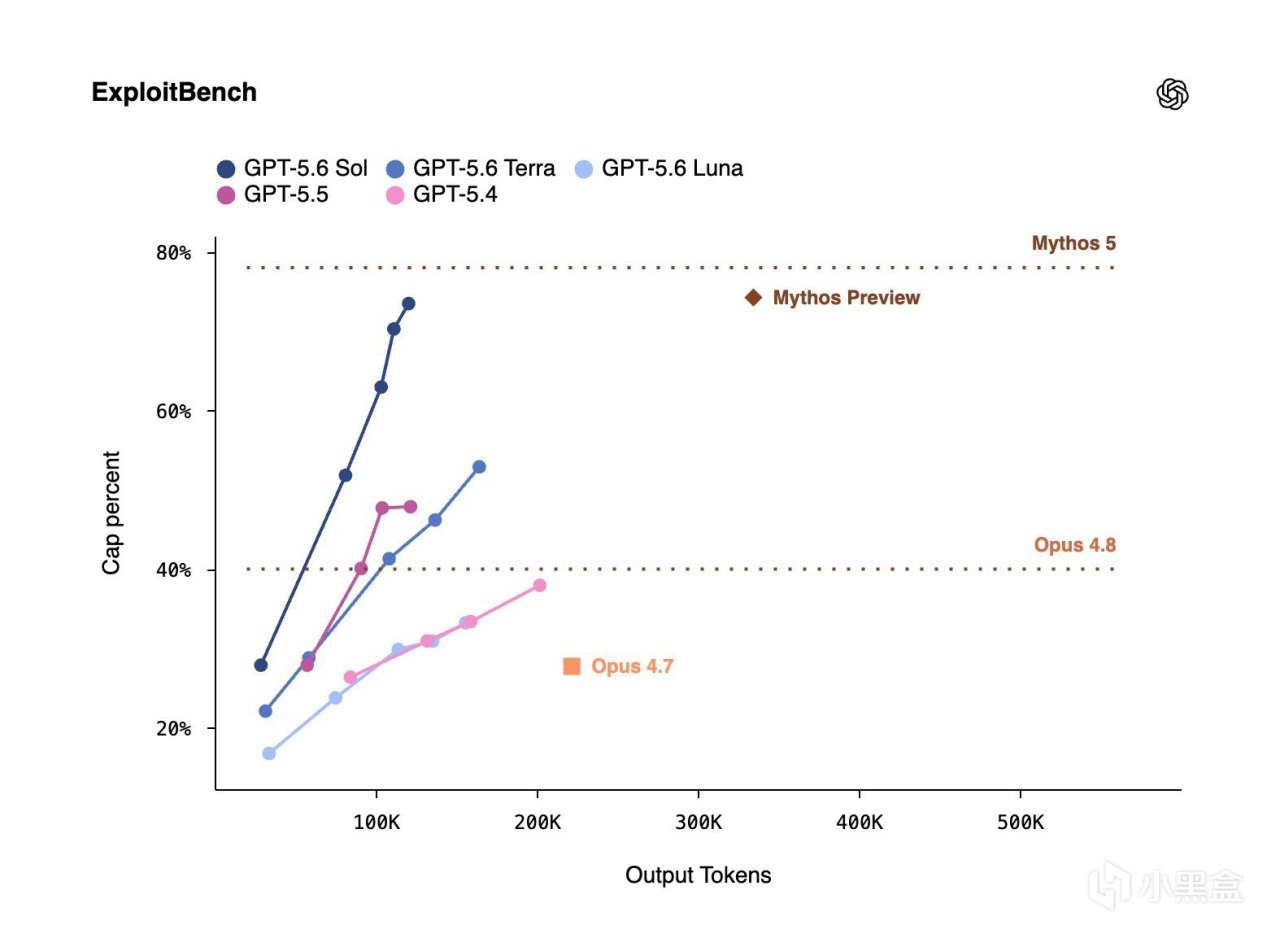
再看 ExploitBench。用戶提供的圖裏,GPT-5.6 Sol 爬到 73% 到 74% 一帶,明顯高過 Terra、Luna、GPT-5.5 和 GPT-5.4。但 Mythos 5 的參考線大約在 78%。
所以這兩個結論不能混在一起:Terminal-Bench 上 Sol Ultra 是第一;ExploitBench 上 Mythos 仍像天花板,Sol 還差一截,但已經摸到了那層上沿。
這比單純“模型變聰明瞭”更值得關注。Sol 的強項落在漏洞研究、命令行代理、長程工具協作這些真實工作流裏。
OpenAI 的說法很剋制
OpenAI 的口徑是:Sol 和 Terra 能發現漏洞,也能拼出漏洞利用的片段;但在針對加固目標的測試中,還不能可靠地完成端到端自主攻擊。簡單說,它能幫安全人員找洞、修洞、寫出局部利用思路;獨立打穿一個加固目標,還不是它現在的官方邊界。
這個區別很重要。
如果只看 “exploitation”,很容易寫成“AI 已經能自動入侵”。這不準確。OpenAI 目前給出的邊界是:能力顯著上升,但沒有跨過它們自己框架裏的 cyber critical threshold。
現實世界也不會只按論文表格運轉。防禦方能用它提速,攻擊方也會嘗試把同樣的能力拼進工作流。安全模型越強,訪問控制和使用審計就越關鍵。
真正引爆的是訪問權
這次 GPT-5.6 沒有直接放開。
OpenAI 說,作爲和美國政府持續溝通的一部分,它們在發佈前向政府預覽了計劃和模型能力;應政府要求,先從一小羣可信合作方開始有限預覽,並把這些合作方參與情況同步給政府。媒體報道里還提到,首批大約是 20 家政府批准的合作方。這個數字不是 X 帖原文,只能按媒體口徑看。
OpenAI 自己也表達過一個態度:這種政府介入的訪問流程,不應該成爲長期默認。因爲這會把最好的工具擋在用戶、開發者、企業、網絡防禦者和全球夥伴之外。
這句話比“模型很強”更值得寫。
AI 公司這幾年持續搶算力。GPU、服務器、數據中心和電力成本,最終都會傳導到硬件、雲服務和開發成本里。
可當更好的模型終於出現,訪問權卻先被政府批准名單鎖住。成本與收益開始錯位。
如果成本擴散到整個市場,能力卻被少數機構優先拿走,這就是最容易點燃的矛盾。普通人未必需要 Sol 做安全研究,卻已經承受了 AI 基建時代的硬件和服務成本。
對開發者來說,這不是遠方新聞
很多人看見“網絡安全模型”會覺得和自己沒關係。其實關係很近。
Terminal-Bench 2.1 的重點是命令行工作流。也就是模型能不能規劃步驟、調用工具、看報錯、改命令、繼續迭代。這正是 Codex、自動化運維、代碼審計、CI 修復這類工具的核心能力。
Sol 如果在這些任務上明顯更強,普通開發者未來最先感受到的,可能是工程問題被模型自動跑通的概率變高了。它會不會挖漏洞只是其中一面;它能不能獨立處理複雜終端任務,纔會更頻繁地落到日常工作裏。
價格圖也說明了 OpenAI 的分層思路:Sol 是旗艦,輸入 5 美元、緩存輸入 0.5 美元、輸出 30 美元;Terra 砍半,輸入 2.5 美元、緩存輸入 0.25 美元、輸出 15 美元;Luna 再降,輸入 1 美元、緩存輸入 0.1 美元、輸出 6 美元。圖裏沒標明計價單位,不能擅自補成每百萬 tokens,但價格梯度很清楚:越強,越貴;越便宜,越偏高吞吐。
但這裏也有風險。越能自主操作終端的模型,越需要嚴格邊界。執行權限、文件寫入、網絡訪問、密鑰隔離、審批流程,都不能再靠一句“相信模型”。模型越像同事,越要給它工位、權限和審計,不該把整臺機器隨手交出去。
這點在安全模型上更明顯。一個能讀代碼、跑工具、推漏洞鏈的系統,如果沒有邊界,同一套能力既能幫防禦,也能放大風險。
這次發佈暴露的是分配問題
GPT-5.6 Sol 的技術點很清楚:更強的長程任務,更強的命令行代理,更強的網絡安全能力。Terminal-Bench 圖給了 OpenAI 一個第一名,ExploitBench 圖也給了另一個提醒:Mythos 仍在更高處,Sol 已經逼近那條線。
能力之外,還有分配。
AI 公司把全社會的算力、硬件、能源和價格體系都捲進來,然後最強能力先進入政府批准的小圈子。OpenAI 一邊接受這個流程,一邊又公開說不希望它成爲常態。這種拉扯,纔是 GPT-5.6 Sol 這輪發布最值得盯的地方。
技術會繼續往前推。Mythos 今天還是天花板,明天可能就被追平。下一次天花板被打穿時,訪問權如何分配,會比跑分本身更敏感。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com








![不清楚是不是站崗站傻了,想不清楚去年發生了什麼,大事件記得[cube_捂臉哭]](https://imgheybox1.max-c.com/bbs/2026/06/28/bccafc3417454fb6e3871cef41a3b410.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)








